1-10 Trở lại với câu lệnh HAVING
Không để cho nói là nhân vật phụ nữa Câu lệnh HAVING là một trong những tính năng quan trọng của SQL. Trong "Sức mạnh của câu lệnh HAVING" cũng đã có giới thiệu một phần về sức mạnh to lớn của nó. Lần này sẽ tiếp nối và giới thiệu những thủ thuật được sử dụng ở nhiều trường hợp mang đặc tính ...
Không để cho nói là nhân vật phụ nữa Câu lệnh HAVING là một trong những tính năng quan trọng của SQL. Trong "Sức mạnh của câu lệnh HAVING" cũng đã có giới thiệu một phần về sức mạnh to lớn của nó. Lần này sẽ tiếp nối và giới thiệu những thủ thuật được sử dụng ở nhiều trường hợp mang đặc tính tên là "Điều tra tính chất của chính tập hợp" bằng câu lệnh HAVING.
Trong lúc dạy lớp về SQL thì một trở ngại lớn nhất đó chính là một lần nữa rửa đầu cho học sinh đã có trong mình những kiến thức về ngôn ngữ lập trình thủ tục được học từ trước đến nay. Tôi trong những lúc đó chỉ sử dụng một phương pháp đó chính là nhấn mạnh cách nghĩ từ quan điểm của tập hợp. --Joe Celko--
Mở đầu
Cũng như chương trước đã đề ra một vài lần thì khi học cách suy nghĩ của SQL thì bức tường lớn nhất đó chính là cách suy nghĩ của ngôn ngữ lập trình thủ tục (loop, sort, thay thế,...) mà chúng ta đã quen từ lâu. Để hiểu được bản chất của SQL thì những cách suy nghĩ mà chúng ta đã bảo thủ giữ trong người thì cần thiết phải có sự kéo ra và để nó về vị trí ban đầu. Ở đây thì Celko đã sử dụng từ unlearn để chỉ việc này. Ngay cả Celko cũng từ Fortran bắt đầu sự nghiệp làm lập trình viên, chỉ là một nhân vật bình thường cũng học từ những ngôn ngữ lập trình thủ tục như C, Algol, Pascal rồi mới trang bị kiến thức về SQL cho mình, vậy nên ông hiểu và diễn đạt những cảm nhận thực sự đó của mình ra thành từ ngữ.
Như vậy, nói thì dễ nhưng làm thì phải thế nào? Việc bỏ tay cách suy nghĩ cùng với cảm giác an định khi sử dụng lâu dài và được trang bị kiến thức từ xưa đối với ai cũng vậy, không phải là một điều đơn giản. Cùng với việc tiến hành công việc [unlearn] này một cách mềm dẻo cùng với phương pháp hiệu quả nhất theo tôi nghĩ để lý giải được cách suy nghĩ hướng tập hợp của SQL là "Học cách sử dụng của câu lệnh HAVING". Tại sao lại vậy thì câu lệnh HAVING là dấu phép tính sử dụng trong trình độ tập hợp mà không phải record nên để sử dụng thành thạo, thì gì đi chăng nữa cũng yêu cầu sự suy nghĩ trình độ tập hợp.
Như trên đã đưa ra, đây là lần 2 của [Sức mạnh của câu lệnh HAVING]. Lần này chúng ta cũng dứt khoát vẽ một vòng tròn. Mọi người đã có giấy và bút chưa?
Cách đội, điểm danh tất cả thành viên!
Có hơi đột nhiên nhưng coi như bạn đang là người được bổ nhiệm chịu trách nhiệm tiến hành tập hợp đội phòng cháy (hoặc có thể là đội phòng vệ trái đất). Như vậy nhanh chóng nhận điện yêu cầu nhận nhiệm vụ từ bộ tư lệnh!
Công việc của bạn là tìm những đội có khả năng làm việc trong hiện tại. Điều kiện có khả năng làm việc đó chính là tất cả các thành viên trong đội phải ở trong tình trạng "Đang chờ". Bảng dữ liệu để sử dụng sẽ là như dưới đây.
Teams| member | team_id | status |
|---|---|---|
| Joe | 1 | Đang chờ |
| Ken | 1 | Đang làm |
| Mike | 1 | Đang chờ |
| Karen | 2 | Đang làm |
| Kease | 2 | Nghỉ |
| John | 3 | Đang chờ |
| Hat | 3 | Đang chờ |
| Dick | 3 | Đang chờ |
| Beth | 4 | Đang chờ |
| Arent | 5 | Đang làm |
| Robert | 5 | Nghỉ |
| Kegant | 5 | Đang chờ |
Đối với dữ liệu mẫu đã cho tại đây thì đội có khả năng làm là đội 3 và đội 4. Đội 4 chỉ có một người nhưng việc phải tập hợp các thành viên thì không thay đổi. Tại đây chúng ta cùng nghĩ query để tìm ra kết quả này.
Điều kiện "Tình trạng của tất cả các thành viên là "Đang chờ"" là câu lượng hoá toàn xưng nên chúng ta sử dụng NOT EXISTS để viết.
-- Biểu hiện câu toàn xưng bằng vị từ
SELECT team_id, member
FROM Teams T1
WHERE NOT EXISTS
(SELECT *
FROM Teams T2
WHERE T1.team_id = T2.team_id
AND status <> 'Đang chờ' );
Kết quả
team_id member
------- ----------
3 John
3 Hat
3 Dick
4 Beth
Tại đây thì chúng ta sử dụng biến đổi câu lượng hoá toàn xưng và lượng hoá tồn tại như sau,
Trạng thái của tất cả thành viên là đang chờ =KHông có thành viên nào không có trạng thái đang chờ
Truy vấn này có những điểm mạnh là về phần perfomance thì tốt và dữ liệu thông tin nhiều khi hiển thị những thành viên trong đội. Nhưng vì dùng 2 lần phủ định thì về mặt trực quan thì có vẻ hơi khó hiểu, thì chúng ta có cách viết dưới đây.
-- Biểu hiện câu toàn xưng bằng tập hợp: phiên bản 1
SELECT team_id
FROM Teams
GROUP BY team_id
HAVING COUNT(*) = SUM(CASE WHEN status = 'Đang chờ'
THEN 1
ELSE 0 END);
Kết quả
team_id
-------
3
4
Đây là một câu khẳng định hoàn toàn nên là một code rất dễ hiểu. Nhưng code này thực hiện như thế nào thì chúng ta cùng đi vào chi tiết để nhìn xem sao nhé. Đầu tiên bằng GROUP BY thì tập hợp Teams được chia thành phần theo đơn vị đội.
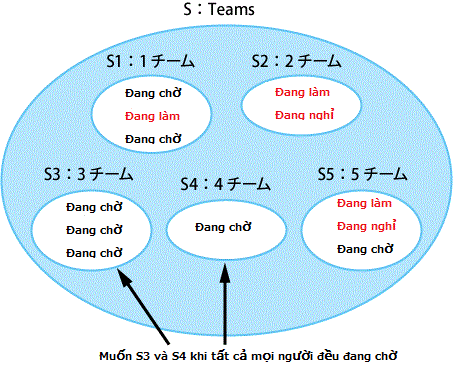
Tập hợp mong muốn là S3 và S$$ Vậy tính chất mà chỉ 2 tập hợp này có mà những tập hợp khác không có là gì? Đó chính là số dòng trạng thái là "Đang chờ" và số dòng toàn tập hợp là thống nhất. Tính chất này như bên trên thì chúng ta đã biểu hiện bằng hàm CASE nếu trạng thái là "Đang chờ" thì trả lại giá trị 1, còn không phải thì trả lại giá trị 0. Cũng như mọi người đã nhận ra, đây là ứng dụng của hàm số đặc tính.
Quả nhiên đối với tất cả các dòng thì dựa vào việc có thoả mãn điều kiện hay không mà trả lại những kết quả 0/1. Tham khảo bảng dưới,
| member | team_id | status | Kết quả trả lại |
|---|---|---|---|
| Joe | 1 | Đang chờ | 1 |
| Ken | 1 | Đang làm | 0 |
| Mike | 1 | Đang chờ | 1 |
| Karen | 2 | Đang làm | 0 |
| Kease | 2 | Nghỉ | 0 |
| John | 3 | Đang chờ | 1 |
| Hat | 3 | Đang chờ | 1 |
| Dick | 3 | Đang chờ | 1 |
| Beth | 4 | Đang chờ | 1 |
| Arent | 5 | Đang làm | 0 |
| Robert | 5 | Nghỉ | 0 |
| Kegant | 5 | Đang chờ | 1 |
Mặt khác câu lệnh HAVING cũng có thể viết như sau,
--Biểu hiện câu toàn xưng bằng tập hợp: phiên bản 2 SELECT team_id FROM Teams GROUP BY team_id HAVING MAX(status) = 'Đang chờ' AND MIN(status) = 'Đang chờ';
Bạn có hiểu ý nghĩa của truy vấn này không? Đối với một tập hợp, thì giá trị lớn nhất và giá trị nhỏ nhất của thành tố đồng nhất với nhau thì chỉ có thể chính tập hợp đó là cùng loại với nhau. Như vậy, nếu có những giá trị khác vào thì nhất định giá trị lớn nhất và giá trị nhỏ nhất sẽ lệch nhau. Hàm số cực trị sẽ sử dụng argument là index của dãy nên tại đây thì perfomance có vẻ tốt. (Đối với trường hợp như lần này mà chỉ có 3 loại giá trị thì cũng không có ý nghĩa gì nhiều lắm).
Hoặc là điều kiện đối với tập hợp chuyển sang caai lệnh SELECT hiển thị hàng loạt mọi thành viên đã trong trạng thái chuẩn bị chưa, có thành viên nào thiếu không cũng là một phương pháp có hiệu quả.
--Hiển thị từng đội xem tất cả thành viên trong đội đã sẵn sàng chưa.
SELECT team_id,
CASE WHEN MAX(status) = 'Đang chờ' AND MIN(status) = 'Đang chờ'
THEN 'Tất cả mọi người sẵn sàng'
ELSE 'Đội trưởng! Đội vẫn chưa đủ' END AS status
FROM Teams
GROUP BY team_id;
Kết quả
team_id status
------- --------------------------
1 Đội trưởng! Đội vẫn chưa đủ
2 Đội trưởng! Đội vẫn chưa đủ
3 Tất cả mọi người sẵn sàng
4 Tất cả mọi người sẵn sàng
5 Đội trưởng! Đội vẫn chưa đủ
Tuy nhiên, trong trường hợp chuyển điều kiện sang SELECT thì khả năng có được tương tích hoá cao nhất theo optimize là rất thấp nên chắc chắn perfomance so với câu lênh HAVING thì chắc chắn bị rớt. Trong trường hợp này thì lượng thông tin và perfomance sẽ trở thành quan hệ trade-off.(?)
Tập hợp nhất ý và tập hợp trùng
Cũng đã nêu ra trong phép toán tập hợp trong SQL thì tập hợp được sử dụng trong cơ sở dữ liệu quan hệ là tập hợp có thể có dữ liệu trùng. Ngược lại với đó thì tập hợp có thể sử dụng trong luận tập hợp thông thường không chấp nhận tập hợp trùng, và đây gọi là "Tập hợp nhất ý" (Đây là từ ngữ của tác giả không phải là một từ mang tính chính thức).
Trong bảng lặp lại sự xuất nhập dữ liệu thì chắc chắn sẽ có phát sinh sự trùng dữ liệu. Ta hoàn toàn có thể đặt điều kiện, điều khoản trong định nghĩa bảng nhưng có những trường hợp yêu cầu của nghiệp vụ thực tế thì tự nó sẽ sinh ra những sự trùng nhau.
Ví dụ, chúng ta cùng nhìn bảng quản lý xe tải tài nguyên khai thác được như sau.
Materials|center|receive_date|material| |--------|--------| |Tokyo|2007-4-01|Thiếc| |Tokyo|2007-4-12|Bạch kim| |Tokyo|2007-5-17|Nhôm| |Tokyo|2007-5-20|Bạch kim| |Osaka|2007-4-20|Đồng| |Osaka|2007-4-22|Niken| |Osaka|2007-4-29|Chì| |Nagoya|2007-3-15|Titan| |Nagoya|2007-4-01|Hợp kim| |Nagoya|2007-4-24|Hợp kim| |Nagoya|2007-5-02|Magie| |Nagoya|2007-5-10|Titan| |Fukuoka|2007-5-10|Bạch kim| |Fukuoka|2007-5-28|Thiếc|
Về tài nguyên này thì mỗi ngày đề được ghi chép. Mỗi thời điểm thì người ta dùng nguyên liệu này để sản xuất, nhưng ở trong này thì người ta sử dụng theo như kế hoạch đã đề ra và chắc hẳn có trường hợp sẽ có trùng. Trường hợp này để tiến hành quán lý những nguyên liệu còn sót lại thì chúng ta cần thiết phải tra những điển tồn tại trùng.
Việc muốn làm ở đây là điều tra tính chất của mỗi điểm thì mỗi một thời điểm không được cấu thành như một dòng. Nó bị phân thành nhiều dòng. Có nghĩa là thực thể tên là thời điểm đó thì không phải tồn tại như một thành tố mà tồn tại như một tập hợp. Trường hợp như thế này thì chúng ta có thể cắt ra thành từng bộ phận bằng GROUP BY, chúng ta có thể cut như sau.
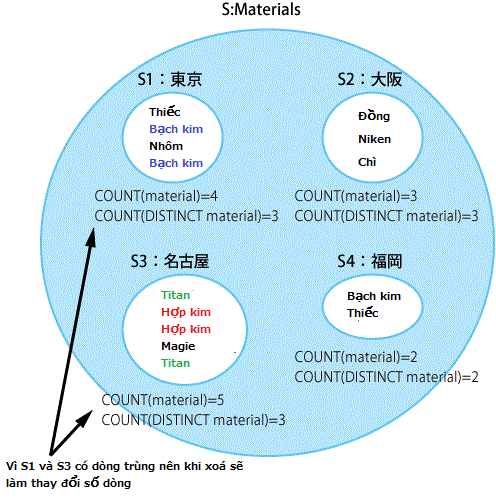
Kết quả mong muốn là điểm Tokyo với bạch kim bị trùng và Nagoya với hợp kim bị trùng. Vậy thì điều kiện mà hai tập hợp này có mà những tập hợp khác không có là gì?
Chỉ có thể điều kiện số thành tố khi đếm cả những dòng trùng và số thành tố khi không đếm những dòng trùng là khác nhau. Nếu không có dòng trùng thì kết quả của COUNT khi gắn DISTINCT thì cũng không thay đổi so với không gắn.
--Chọn những điểm có nguyên liệu trùng SELECT center FROM Materials GROUP BY center HAVING COUNT(material) <> COUNT(DISTINCT material);Kết quả
center ------ Tokyo Nagoya
Tại đây thì chúng ta vẫn chưa biết được nguyên liệu nào đang thừa nhưng nếu trao cho câu lệnh WHERE thông số thì có thể biết được địa điểm đang thừa nguyên liệu. Mặt khác, cũng giống như câu hỏi trước, nếu đưa điều kiện vào câu lệnh SELECT thì có thể biết được từng bộ phận có nguyên liệu bị trùng hay không.
SELECT center,
CASE WHEN COUNT(material) <> COUNT (DISTICT material) THEN 'Có trùng'
ELSE 'Không trùng' END AS status
FROM Materials
GROUP BY center;
center status ------ ----------- Osaka Không trùng Tokyo Có trùng Fukuoka Không trùng Nagoya Có trùng
Đây cũng là phần được luyện tập rất nhiều ở phần "Sức mạnh của câu lệnh HAVING", vậy mọi người đã quen với cách suy nghĩ chia tập hợp bộ phận của bảng ban đầu bằng GROUP BY chưa? Cho đến bây giờ thì ta đều sử dụng cách nói là "Tập hợp bộ phận", nhưng thực ra tập hợp bộ phận được tạo bằng GROUP BY có một cái tên riêng là loại (partition). Đây là khái niệm hay được sử dụng trong luận lý về tập hợp để gọi những tập hợp bộ phận khi được chia không thừa không thiếu theo một điều kiện nào đó từ một tập hợp.
Mặt khác, vấn đề này thì chúng ta có thể dùng thay thế HAVING bằng EXISTS
--Tập hợp có yếu tố trùng: dùng EXISTS
SELECT center, material
FROM Material M1
WHERE EXISTS
(SELECT *
FROM Materials M2
WHERE M1.center = M2.center
AND M1.receive_date <> M2.receive_date
AND M1.material = M2.material);
center material ------- ---------- Tokyo Bạch kim Tokyo Bạch kim Nagoya Titan Nagoya Hợp kim Nagoya Hợp kim Nagoya Titan
Tại trường hợp này chúng ta lại có thể sử dụng những ưu điểm của EXISTS là có thể hiển thị tất cả những thành tố trùng, về perfomance thì tốt. Đối ngược với đó, nếu muốn tìm kiếm nơi không có nguyên liệu trùng thì chúng ta chỉ cần thay EXISTS bằng NOT EXISTS là được.
Tìm điểm khuyết: Bản phát triển
Trong "Sức mạnh của câu lệnh HAVING" thì mọi người có nhớ là đã có giới thiệu về truy vấn tiến hành check chỗ trống trong dãy số như sau.
--Kết quả trả về là có chỗ khuyết SELECT 'Có chỗ khuyết' AS gap FROM SeqTbl HAVING COUNT(*) <> MAX(seq);
Truy vấn này thì có một điều kiện tiên quyết là dãy số phải bắt đầu từ 1. Đối với hầu hết những trường hợp thì chắc không xảy ra vấn đề gì nhưng chúng ta cùng nghĩ đến trường hợp nới lỏng điều kiện ra, không kể đến giá trị dưới cùng là gì mà chỉ muốn điều tra xem dãy số có liên tục hay không thôi thì phải làm thế nào. Có nghĩa là trong 4 trường hợp dưới đây thì đối với trường hợp 3 thì được trả về đáp án "Dãy số liên tục" và (4) thì được trả về đáp án "Có chỗ khuyết". Nếu với truy vấn trên thì vì có điều kiện tiên quyết là giá trị bắt đầu là 1 nên trong trường hợp (3) thì kết quả được trả lại sẽ là "Có chỗ khuyết".
(1) Không có chỗ khuyết (Giá trị bắt đầu = 1)
| Seq |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
(2) Có chỗ khuyết (Giá trị bắt đầu = 2)
| Seq |
|---|
| 1 |
| 2 |
| 4 |
| 5 |
| 8 |
(3) Không có chỗ khuyết (Giá trị bắt đầu <>1)
| Seq |
|---|
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
(4) Có chỗ khuyết (Giá trị bắt đầu <>1)
| Seq |
|---|
| 3 |
| 4 |
| 7 |
| 8 |
| 10 |
Cả bảng được nhìn như một tập hợp và cách suy nghĩ dùng COUNT() để đếm số thành tố trong tập hợp là không thay đổi. Đối với 4 trường hợp này thì tất cả COUNT() = 5. Và giả định nếu giữa giá trị lớn nhất và nhỏ nhất không có chỗ khuyết thì số số hạng ở giữa khoảng đó là,
Giá trị lớn nhất - Giá trị nhỏ nhất + 1
Như vậy chúng ta chỉ cần viết điều kiện so sánh như dưới đây.
--Nếu kết quả trả lại thì đó là có chỗ khuyết: chỉ điều tra tính liên tục của dãy số SELECT 'Có chỗ khuyết' AS gap FROM SeqTbl HAVING COUNT(*) <> MAX(seq) - MIN(seq) + 1 ;
Với truy vấn này thì kết quả trả về đối với (1) và (3) sẽ là "Liên tục" nên không được hiện ra. Còn với trường hợp không liên quan đến việc có hay không chỗ khuyết thì vẫn muốn trả kết quả lại thì ta có thể di chuyển điều kiện vào câu lệnh SELECT.
--Có hay không chỗ khuyết thì cũng trả lại 1 dòng kết quả
SELECT CASE WHEN COUNT(*) = 0
THEN 'Bảng rỗng'
WHEN COUNT(*) <> MAX(seq) - MIN(seq) + 1
THEN 'Có chỗ khuyết'
ELSE 'Liên tục' END AS gap
FROM SeqTbl;
Truy vấn này có thêm một chút công phu khi có cả kết quả "Bảng rỗng" như một trường hợp ngoại lệ khi bảng không có dữ liệu.(Với câu lệnh HAVING thì bảng rỗng được coi như là liên tục). Sự hiển thị được đến chi tiết như thế này chính là mị lực của hàm CASE.
Và cùng với đây, trong truy vấn tìm giá trị nhỏ nhất của chỗ khuyết thì chúng ta cũng để trường hợp ngay cả giá trị bắt đầu không phải là 1 cũng có thể đối ứng. Với truy vấn đơn giản trong ví dụ trước thì trong trường hợp (4) thì cũng có thể trả lại kết quả khuyết là 5. 1 và 2 vốn từ đầu không tồn tại trong bảng nên sẽ không tiến hành check sự tồn tại của những số này.
-- Tìm giá trị nhỏ nhất của chỗ khuyết: Trường hợp không có 1 trong bảng thì vẫn trả lại 1
SELECT CASE WHEN COUNT(*) = 0 OR MIN(seq) > 1 -- Trường hợp giá trị dưới không phải 1 -> Trả lại 1
THEN 1
ELSE (SELECT MIN(seq +1) -- Trường hợp giá trị dưới là 1 -> trả lại giá trị min của chỗ khuyết
FROM SeqTbl S1
WHERE NOT EXISTS
(SELECT *
FROM SeqTbl S2
WHERE S2.seq = S1.seq + 1))
END
FROM SeqTbl;
Truy vấn sử dụng lần trước được sử dụng như scala subquery và trở thành giá trị đầu vào của hàm CASE. Với điều kiện COUNT(*) = 0 thì bảng là rỗng. Sau đó chúng ta có đổi NOT IN thành NOT EXISTS, đây chính là perfomance tool cho đối sách đối với NULL. Đặc biệt nếu dãy seq có index thì sử dụng NOT EXISTS sẽ có thể cải thiện khá nhiều. Truy vấn nà sẽ trả lại kết quả như dưới đây.
- Case (1): 6(Vì không có chỗ khuyết nên sẽ là số sau giá trị lớn nhất là 5)
- Case (2): 3(Giá trị nhỏ nhất của chỗ khuyết)
- Case (3): 1(Vì bảng không có 1)
- Case (4): 1(Vì bảng không có 1)
Trong ngôn ngữ lập trình thủ tục thì chúng ta sẽ tiến hành trên đơn vị câu bằng IF hay CASE. Tuy nhiên, trong SQL thì đó là những truy vấn với đăc chưng là tiến hành trên đơn vị hàm số. Đây chính là điểm mà SQL gần với ngôn ngữ lập trình kiểu hàm số.
Xác lập điều kiện chi tiết cho tập hợp
Cuối cùng, chúng ta cùng luyện tập thêm một chút về phương pháp tạo hàm số đặc tính bằng hàm CASE. Nếu có thể sử dụng thành thạo kĩ thuật này thì với điều kiện phức tạp như thế nào thì chúng ta cũng có thể đối ứng được. (Đây không phải nói quá mà là sự thật).
Chúng ta lấy một bảng có kết quả thi của học sinh làm ví dụ như sau.
TestResults|student_id| class |sex|score| |--------|--------| |001|A|Nam|100| |002|A|Nữ|100| |003|A|Nữ|49| |004|A|Nam|30| |005|B|Nữ|100| |006|B|Nam|92| |007|B|Nam|80| |008|B|Nam|80| |009|B|Nữ|10| |010|C|Nam|92| |011|C|Nam|80| |012|C|Nữ|21| |013|D|Nữ|100| |014|D|Nữ|0| |015|D|Nữ|0|
Hãy sử dụng bảng này để giải những câu dưới đây. Lần này từ phía tôi sẽ không vẽ hình Ben nữa, mọi người hãy tự mình sẽ những hình tròn đó.
Chúng ta sẽ bắt đầu nhẹ nhàng.
Câu 1: Hãy chọn những lớp học có 75% học sinh trên 80 điểm
Về tổng số học sinh trong lớp thì ta có thể biết bằng COUNT(*). Những học sinh có điểm trên 80 thì ta có thể dùng hàm số đặc tính để đếm. Như vậy, kết quả là
SELECT class
FROM TestResults
GROUP BY class
HAVING COUNT(*) * 0.75
<= SUM(CASE WHEN score >= 80
THEN 1
ELSE 0 END) ;
Kết quả
class
-----
B
Câu 2: Hãy chọn lớp trong những học sinh có điểm trên 50 thì số học sinh nam nhiều hơn số học sinh nữ
Lần này chúng ta sẽ sử dung hàm số đặc tính đối với cả 2 điều kiện.
SELECT class
FROM TestResults
GROUP BY class
HAVING SUM(CASE WHEN score >= 50 AND sex = 'Nam'
THEN 1
ELSE 0 END)
> SUM(CASE WHEN score >= 50 AND sex = 'Nữ'
THEN 1
ELSE 0 END) ;
Kết quả
class
-----
B
C
Và đây sẽ là câu hỏi cuối. Trong câu hỏi này thì có một chút thủ thuật, mọi người có thể nhận ra không đây.
Câu 3: Chọn lớp có điểm trung bình của nữ lớn hơn điểm trung bình của nam
Đối với dòng chảy cho đến bây giờ thì chắc chắn sẽ không ít người nghĩ đến truy vấn như sau.
--Truy vấn so sánh điểm trung bình của nam và nữ trong lớp. Phiên bản 1: Đối với tập hợp rỗng thì trả lại kết quả 0
SELECT class
FROM TestResults
GROUP BY class
HAVING AVG(CASE WHEN sex = 'Nam'
THEN score
ELSE 0 END)
< AVG(CASE WHEN sex = 'Nữ'
THEN score
ELSE 0 END) ;
Kết quả
class
-----
A
D
Tại điểm chọn lớp A thì không có nghi vấn nào cả. Điểm trung bình của nam là (100+30)/2 = 65, điểm bình quân của nữ là (100+49)/2 = 74.5, rõ ràng điểm bình quân của nữ cao hơn của nam. Vấn đề là lớp D.
Có thể nhìn rõ trong bảng trên, lớp D chỉ toàn là nữ. Với câu trả lời ở trên thì với trường hợp nam, hàm CASE chỉ định [ELSE 0] nên điểm bình quân của nam trong lớp sẽ là 0. Chính vì vậy, với lớp D có điểm bình quân của nữ là 33.33, [0<33,33] nên mới được chọn.
Trường hợp này thì như thế này có vẻ không sao. Nhưng như số 013 với điểm là 0 thì làm thế nào? Trong trường hợp này thì điểm trung bình của nữ là 0 và lớp D sẽ không được chọn.
Tuy nhiên, mặc dù cùng là 0 nhưng ý nghĩa của 2 bên là khác nhau hoàn toàn. Là điểm trung bình của nữ và là số 0 để chỉ điểm trung bình không thể tính được của nam. Thực ra đối với tập hợp rỗng thì điểm trung bình phải để là [Chưa định nghĩa] mới đúng. Cũng giống như sự chưa định nghĩa với kết quả trong phép chia 0 vậy.
Trong SQL thông thường thì hàm số AVG trong trường hợp tập hợp rỗng thì sẽ trả lại kết quả NULL.(Mặc dù cũng có vấn đề khi để NULL vào làm kết quả chưa định nghĩa nhưng lần này chúng ta không đi sâu đến vậy). Đây chính là truy vấn sau khi chỉnh sửa điểm này.
--Truy vấn so sánh điểm trung bình của nam và nữ trong lớp. Phiên bản 1: Đối với tập hợp rỗng thì trả lại kết quả NULL
SELECT class
FROM TestResults
GROUP BY class
HAVING AVG(CASE WHEN sex = 'Nam'
THEN score
ELSE NULL END)
< AVG(CASE WHEN sex = 'Nữ'
THEN score
ELSE NULL END);
Lần này thì điểm bình quân của nam trong lớp D sẽ là NULL. Như vậy điểm trung bình của nữ lớp D không có đối tượng so sánh và sẽ nằm ngoài vùng đối tượng. Như vậy cũng giống như những thao tác của hàm AVG làm việc thông thường.
Nếu nói lật lại sự điều tra tính chất của tập hợp, có nghĩa là ta làm ngơ với những đặc tính của từng thành tố. Ví dụ lần này cũng vậy, việc mà chúng ta suy nghĩ đó chính là hướng đến đặc trưng của lớp mang tính đoàn thể chứ không điều tra thông tin từng cá nhân học sinh ai có những điểm nào.
Đây chính là cách nghĩ hướng đoàn thể mà đảm bảo sự giấu tên của những nhân viên cấu thành nên. Đây chính là luận phương pháp trong thống kê học. Những năm gần đây thì phân tích thống kê sử dụng cơ sở dữ liệu quan hệ (đặc biệt là Mỹ) đang rất thịnh hành. Và nếu nghĩ về tính hợp hoá của thống kê và tính hướng tập hợp của SQL thì đây không phải là điều kì lạ. Cách sử dụng cơ sở dữ liệu như một tool trong phân tích thống kê chắc hẳn sau này sẽ còn mở rộng hơn ở Nhật.
Tóm tắt
Tại chương này chúng ta đã tiến lên nhìn sau hơn một chút về phương pháp ứng dụng của câu lệnh HAVING. Mọi người đã quen hơn với việc sử dụng câu lệnh HAVING (hay câu lệnh GROUP BY) chưa?
Nếu nói ngắn gọn về một điểm khi sử dụng câu lệnh HAVING thì đó chính là hãy chú ý để nhìn mọi thứ như một tập hợp. Trong những ví dụ cho đến bây giờ thì đã có rất những thực thế với nhiều hình dạng, nhiều chúng loại được đưa ra như tập hợp. Có những thứ dễ hình dung như một tập hợp phức số ngay từ như dãy số, lớp ở trường hay đội, nhưng cũng có những thứ có thể dễ dàng nghĩ nó như một thành tố nguyên tử cũng là tập hợp như cửa hàng, điểm sản xuất.
Với ý nghĩa này thì theo như điều kiện để là một tập hợp thì không liên quan trong thực tế thì thực thể này tồn tại như thế nào. Điều kiện chỉ là chúng được thể hiện trên bảng như thế nào. Có những thực thế lúc này thì nó là thành tố còn lúc khác thì nó là một tập hợp.
Nếu mỗi một thực thể được chia theo một dòng thì thực thế đó được dùng như một thành tố trong tập hợp. Nên khi xác lập điều kiện thì cũng không cần phải suy nghĩ gì mà dùng WHERE là được. Mặt khác, nếu mỗi một thực thể lại được chia nhiều dòng thì đó chính là bằng chứng để được sử dụng như một tập hợp. Như vậy chính là sự ra trận của HAVING.
Cuối cùng sẽ là tóm tắt về những điều kiện mang tính đại diện để tra những tính chất của tập hợp. Những điều kiện này có thể dùng cho HAVING, SELECT hay CASE cũng được.
Danh sách cách dùng điều kiện để tra những tính chất của tập hợp|#|Công thức điều kiện|Ý nghĩa| |--------|--------| |1|COUNT(DISTINCT col) = COUNT (col)|Giá trị của col là đồng nhất| |2|COUNT() = COUNT(col)|Tại col không có NULL| |3|COUNT() = MAX(col)|Col là dãy số liên tục không có chỗ khuyết(Giá trị bắt đầu là 1)| |4|COUNT(*) = MAX(col) - MIN(col) + 1|col là dãy số liên tuc không có chỗ khuyết (giá trị bắt đầu khác 1)| |5|MIN(col) = MAX(col)|Col chỉ mang một giá trị hoặc là NULL| |6|MIN(col)*MAX(col) > 0|Dấu của tất cả col_x là giống nhau| |7|MIN(col)*MAX(col) < 0|Dấu giá trị lớn nhất là dương, dấu giá trị nhỏ nhất là âm| |8|MIN(ABS(col)) = 0|Trong col chứa ít nhất 1 giá trị 0| |9|MIN(col - hằng số) = -MAX(col - hằng số)|Giá trị lớn nhất và nhỏ nhất của col cách đều một hằng số nào đó|
Số 1, 4, 5 là những công thức được sử dụng trong lần này. Số 2, 3 chắc hẳn đã được sử dụng trong "Sức mạnh của câu lệnh HAVING". Mặt khác đây không chỉ ngoài những điều kiện gọn gàng như thế này mà nếu biểu hiện hàm số đặc tính bằng hàm CASE thì kể cả điều kiện phức tạp như thế nào đi chăng nữa thì cũng có thể biểu diễn được.
VÀ đây chính là những điểm chính là phần này.
- Khi thiết lập điều kiện tìm kiến bằng SQL thì điều cơ bản là thực thể làm đối tượng tìm kiếm là tập hợp hay thành tố của tập hợp.
- Đối với thực thể mà mỗi thực thể là một dòng -> Vì là thành tố nên sử dụng WHERE
- Đối với thực thể mà mỗi thực thể là phức hợp nhiều dòng -> Vì là tập hợp nên sử dụng HAVING
- Bằng việc sử dụng những hàm số tập hợp (nhất là hàm số cực trị) trong câu lệnh HAVING thì có thể thiết lập nhiều điều kiện với một tập hợp.
- Nếu biểu hiện hàm số đặc tính trong hàm CASE thì ngay cả điều kiện phức tạp như thế nào cũng có thể thiết lập.
- Câu lệnh HAVING thật tuyệt vời.
Dưới đây chính là tài liệu tham khảo của phần này.
-
Joe Celko 『SQLパズル 第2版』 Về check chỗ khuyết của dãy số có thể tham khảo trong "Puzzle 57 Tìm chỗ khuyết - Version 1". Celko khi tìm giá trị nhỏ nhất của chỗ khuyết thì sử dụng NOT IN, nhưng lần này để làm đối sách đối với NULL và cũng là perfomance tool thì đã đổi thành NOT EXISTS. Mặt khác, kĩ thuật tạo hàm số đặc tính của hàm CASE có thể tham khảo "Puzzle 11 Nhờ công việc".
-
DBAzine.com 『Thinking in Aggregates』 Joe Celko、2005年9月 www.dbzine.com/ofinterest/oi-articles/celko18 Có những bài nói để lý giải khái niệm hướng tập hợp của SQL sử dụng câu lệnh HAVING. Người viết quyển sách này cúng chịu một ảnh hưởng lớn từ đây. Những điều kiện viết ở phần "Cuối cùng" cũng là phần có chút biến đổi từ đây. Những từ ngữ trên đầu của Celko được trích dẫ cũng là những từ ngữ lấy từ bài viết này.
-
物理のかぎしっぽ 『類別』 2006年4月 Có những giải thích đơn giản về những khái niệm có liên quan đến vật lý, cũng có khái niệm về partical và những khái niệm liên quan.
