9GAG: Sử dụng Python lấy dữ liệu ảnh GIF
Mở đầu Hồi đầu tiên bắt đầu tìm hiểu Python, đó là việc sử dụng nó để scraping dữ liệu từ những trang web khác nhưng bị em Python tán tính mạnh quá cho nên cũng tập tành đi chơi đêm với em ấy. Và giờ thì em cũng chính thức để em ấy thành cô vợ cả và rất nhiều cô vợ hai. Trong phần hướng dẫn này ...
Mở đầu
Hồi đầu tiên bắt đầu tìm hiểu Python, đó là việc sử dụng nó để scraping dữ liệu từ những trang web khác nhưng bị em Python tán tính mạnh quá cho nên cũng tập tành đi chơi đêm với em ấy. Và giờ thì em cũng chính thức để em ấy thành cô vợ cả và rất nhiều cô vợ hai.
Trong phần hướng dẫn này thì em sẽ làm một ví dụ nhỏ sử dụng Python để lấy dữ liệu ảnh GIF trên trang 9GAG. Tại cứ rảnh là em lên trang này coi mấy cái ảnh GIF giải trí. Nên tại sao ta không thử phân tích dữ liệu của nó và viết một tool tự động lấy về cài mới nhất khi có.
Những module sẽ sử dụng lần này:
- Requests - [http://docs.python-requests.org/en/master/]
- Beautiful Soup - [http://www.crummy.com/software/BeautifulSoup/bs4/doc/]
Phân tích
Địa chỉ url mình sẽ lấy dữ liệu ở đây là 9GAG. Khi vào trình trang, bật trình debug trang web lên bạn để ý bạn sẽ thấy mỗi bài đăng gif tương ứng với 1 article. Trong mỗi article này sẽ có nội dung tương ứng như (tiêu đề, địa chỉ url, ảnh đại diện, đường dẫn file mp4, wbm). Ở trang 9gag này thì ảnh gif được chuyển đổi thành 1 file mp4 ngắn hoặc là file có định dạng wbm (muốn biết chuẩn này là gì anh em có thể gg để tìm hiểu tiếp nhé)
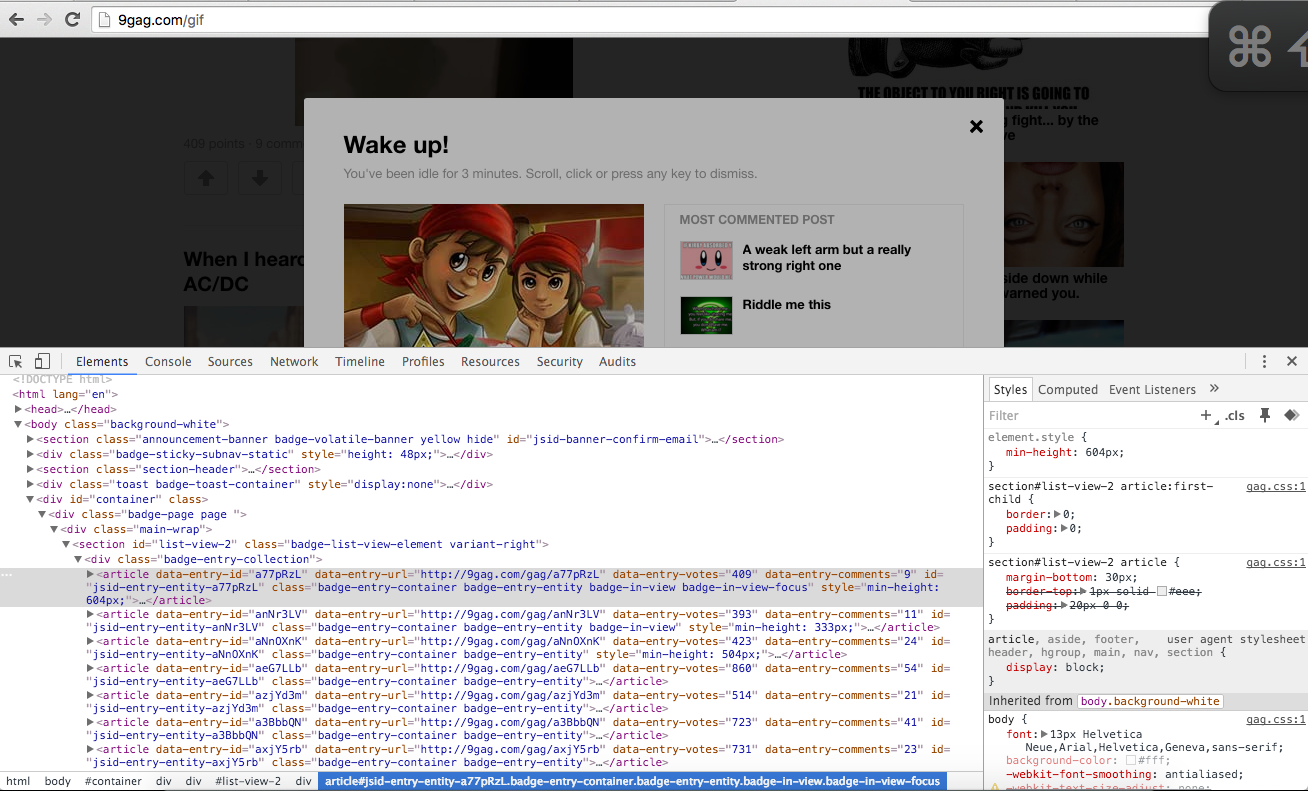
Viết code
Phần thú vị nhất đây rồi. Ở đây mình sẽ chia làm hai bước. Đầu tiên chúng ta sẽ gọi đến trang để lấy về đống bầy nhầy HTML.
1. Lấy về đống bầy nhầy
from bs4 import BeautifulSoup import requests def get_home_page(): try: body = requests.get('http://9gag.com/gif') if body.status_code == 200: html = BeautifulSoup(body.text) articles = html.find_all('article') return articles except: print("Fuck Error!") return False
Giờ là phần giải thích cho anh em đoạn code trên nó xử lý thế nào nhé. Đầu tiên sẽ là module (requests).
body = requests.get('http://9gag.com/gif')
Ta sẽ gửi request get đến url của trang 9gag để nhận về dữ liệu thuần HTML.
if body.status_code == 200: html = BeautifulSoup(body.text)
Tiếp đến để kiểm tra xem request trả về có thành công hay không, ta sẽ kiểm tra trạng thái hay tên tiêng anh là status (đọc sờ ta tút). Nếu status == 200. Tức là ta đã lấy về cái đống bầy nhầy rồi. Bây giờ anh em để ý cái bước phân tích bên trên mình có nói qua nha. Giờ là lúc mình sử dụng nó nè.
html = BeautifulSoup(body.text)
articles = html.find_all('article')
Ta sử dụng module Beautiful Soup để có thể lọc ra các đối tượng Html mà mình cần. Load html vào beautiful soup html = BeautifulSoup(body.text) sau đó ta lọc ra các ảnh gif (mỗi ảnh gif tương ứng với 1 article). Câu lệnh này articles = html.find_all('article') sẽ trả về một mảng các article.
2. Xử lý triệt để đống bầy nhầy
Phần này sẽ là phần quan trọng nhất giúp mọi người lấy ra được những thông tin cần thiết nhé. Có được mảng các article rồi, ta sẽ truyền mảng đó vào hàm sau để lấy ra các thông tin cần thiết.
def parse_data(origin_data): # Mảng lưu dữ liệu đã xử lý thành công list_parse_data = [] for value in origin_data: # Tạo một object để lưu lại thông tin ta trích xuất obj_save = { 'name': ', 'slug': ', 'webm': ', 'mp4': ', 'image': ', } html = BeautifulSoup(str(value)) try: obj_save['name'] = html.find('h2', {'class': 'badge-item-title'}).text.strip() obj_save['image'] = html.find('img', {'class': 'badge-item-img'}).attrs['src'].strip() sources = html.find_all('source') for source in sources: src = source.attrs['src'] if 'mp4' in src: obj_save['mp4'] = src elif 'webm' in src: obj_save['webm'] = src list_parse_data.append(source) except: print('Some parse data error: ') return list_parse_data
Chúng ta sẽ for lần lượt các phần tử trong mảng article. Tiếp tục truyền vào Beautiful Soup để phân tích ra thẻ image, tiêu đề (h2) và slug của ảnh gif.
Tiếp đến chúng ta sẽ tìm tất cả thẻ source và lấy ra thuộc tính src để lấy ra đường dẫn mp4 và webm. Sau đó lưu đối tượng vào mảng và trả về khi xử lý hoàn tất.
Thực tiễn
Bạn đã thực sự hiểu cách làm việc của đoạn code trên. Nếu chưa hiểu, bạn có thể ngẫm thêm
