Cách xác định bài toán trong Machine Learning
Nếu tôi hỏi khách hàng xem họ muốn gì, có lẽ họ sẽ nói rằng họ muốn có một con ngựa biết chạy nhanh hơn– Henry Ford Trong thực tế, trước khi giải bất kỳ bài toán nào, việc đầu tiên chúng ta cần làm đó là xác định vấn đề. Đặc biệt khi làm trong lĩnh vực Machine Learning (ML), nhiều ...

Nếu tôi hỏi khách hàng xem họ muốn gì, có lẽ họ sẽ nói rằng họ muốn có một con ngựa biết chạy nhanh hơn– Henry Ford
Trong thực tế, trước khi giải bất kỳ bài toán nào, việc đầu tiên chúng ta cần làm đó là xác định vấn đề. Đặc biệt khi làm trong lĩnh vực Machine Learning (ML), nhiều khi bài toán do các doanh nghiệp đặt ra khá mơ hồ và không cụ thể khiến cho quá trình xây dựng mô hình dự đoán đi đến ngõ cụt hoặc không đáp ứng được yêu cầu của khách hàng. Vậy làm thế nào để có thể xác định được bài toán hiện tại thuộc loại bài toán nào để giải quyết bằng ML? Bài viết này sẽ liệt kê các câu hỏi nghiên cứu và đưa ra bài toán cụ thể để giải bằng ML.
Mẫu dữ liệu này là A hay B?
Cat or dog
Ta có thể đưa câu hỏi nghiên cứu này sang bài toán phân loại hai lớp (two-class classification). Đây là dạng bài toán chỉ có hai câu trả lời: có hoặc không, on hay off, có hút thuốc hay không hút thuốc, đã thanh toán hay chưa thanh toán. Dưới đây là một số câu hỏi điển hình của dạng này.
- Khách hàng này sẽ gia hạn thuê bao hay không?
- Đây là ảnh một con mèo hay một con chó?
- Liệu khách hàng có click vào link này hay không?
- Liệu lốp xe này có bị vỡ trong ngàn dặm tiếp theo hay không?
- Coupon giảm 5 đô so với giảm 25% thì coupon nào thu hút nhiều khách hàng quay trở lại hơn?
Mẫu dữ liệu này là A hay B hay C hay D?
Rada signature
Ta có thể đưa câu hỏi nghiên cứu này sang bài toán phân loại đa lớp (multi-class classification). Như tên gọi của nó, ta sẽ thu được câu trả lời là một hay nhiều các khả năng: thích cái nào, người nào, bộ phận nào, công ty nào, ứng viên nào. Đa số các thuật toán multi-class classification là phiên bản mở rộng của thuật toán two-class classification. Dưới đây là một số câu hỏi điển hình.
- Có con vật nào trong bức ảnh này?
- Xác định tên máy bay thu được trên ra-da?
- Bài viết này thuộc chủ đề gì?
- Tâm trạng của tweet này là gì?
- Speaker trong bản ghi âm này là ai?
Mẫu dữ liệu này có gì lạ không?
Are these voltages normal for this season and time of day
Ta có thể đưa câu hỏi nghiên cứu này sang bài toán phát hiện sự bất thường (anomaly detection). Mục tiêu của chúng ta là nhận diện các điểm dữ liệu không bình thường. Nếu để ý kĩ, ta có thể thấy đây có vẻ như là bài toán two-class classification bởi vì câu trả lời có thể có hoặc không. Điểm khác biệt ở đây đó là two-class classification sử dụng tập dữ liệu bao gồm cả hai trường hợp có hoặc không nhưng bài toán anomaly detection thì ngược lại. Những điểm dữ liệu bất thường hiếm khi xuất hiện do đó ta không thể thu thập được ví dụ như khi nào thì thiết bị này sẽ hỏng hay gian lận trong thẻ tín dụng… Dưới đây là một số câu hỏi điển hình.
- Huyết áp như vậy có bình thường hay không?
- Tin nhắn này có bình thường hay không?
- Các thao tác thanh toán của khách hàng này có bất thường so với những lần trước đó hay không?
- Điện áp như vậy có bình thường hay không trong điều kiện khí hậu và thời điểm hiện tại?
Bao nhiêu?
Regression
Khi bạn muốn kết quả trả về là một con số thay vì là một lớp hay một loại, ta có thể đưa câu hỏi nghiên cứu này sang bài toán hồi quy (regression). Thông thường các thuật toán regression sẽ trả về câu trả lời là một giá trị thực. Kết quả sẽ gồm rất nhiều số thập phân hay thậm chí mang giá trị âm. Thông thường các giá trị âm sẽ được chuyển thành số 0 và các giá trị thập phân sẽ được làm tròn đến giá trị gần nhất. Dưới đây là một số câu hỏi điển hình.
- Nhiệt độ vào thứ ba tuần tới sẽ là bao nhiêu?
- Doanh số bán hàng quý 4 ở Bồ Đào Nha sẽ là bao nhiêu?
- Bao nhiêu kilowatts điện thu được từ trang trại gió trong 30 phút tới?
- Có bao nhiêu người theo dõi bài viết của tôi trong tuần tới?
Phân loại đa lớp dưới dạng regression

Van
Đôi khi câu hỏi nghiên cứu liên quan đến multi-class classification phù hợp hơn khi kết hợp với regression. Ví dụ ta thường gặp câu hỏi sau “Bài viết nào thu hút độc giả này nhiều nhất?”. Ta có thể chuyển sang câu hỏi tương tự “Mức độ hứng thú của độc giả đối với từng bài viết này là bao nhiêu?” bằng cách cho điểm từng bài viết, ta sẽ chọn ra bài viết có điểm đánh giá cao nhất để gợi ý cho độc giả. Dưới đây là một số câu hỏi điển hình.
- “Xe tải nào trong hạm đội này cần sửa chữa nhiều nhất?” hay “Tình trạng mỗi xe tải hiện tại ra sao để kịp thời sửa chữa?”
- “Đâu là 5% số khách hàng có xu hướng chuyển sang đối thủ cạnh tranh trong năm tới?” hay “Xác suất từng khách hàng hiện tại muốn chuyển sang đối thủ cạnh tranh trong năm tới là bao nhiêu?”
Phân loại hai lớp dưới dạng regression

Slot machine
Không có gì đáng ngạc nhiên khi bài toán two-class classification có thể kết hợp với regression. Thật ra, bản chất một số thuật toán two-class classification đều kết hợp với regression. Bài toán này áp dụng cho các trường hợp như biến cố này có thể xảy ra cũng có thể không xảy ra, mẫu dữ liệu này vừa xuất hiện thành phần A và thành phần B. Các câu hỏi dạng này thường bắt đầu với “Xác suất… là bao nhiêu” hay “Tỉ lệ… là bao nhiêu”.
Có thể mọi người đã nhận ra các bài toán two-class classification, multi-class classification, anomaly detection, và regression đều có hướng tiếp cận chung là huấn luyện có giám sát (supervised learning). Hướng tiếp cận này cần tập dữ liệu huấn luyện (training set) có gán nhãn (labeled). Sau đó, mô hình dự đoán sẽ gán giá trị xác suất cho mẫu dữ liệu cần dự đoán thuộc về lớp nào (tiến trình này gọi là scoring). Dưới đây là một số câu hỏi điển hình.
- Xác suất người dùng sẽ click vào link quảng cáo này là bao nhiêu?
- Tỉ lệ thắng khi kéo máy đánh bạc này là bao nhiêu?
- Xác suất nhân viên này là mối đe doạ an ninh ngầm trong công ty là bao nhiêu?
- Tỉ lệ các chuyến bay xuất phát đúng giờ là bao nhiêu?
Dữ liệu được tổ chức như thế nào?

Constellations
Câu hỏi liên quan đến cách tổ chức của dữ liệu thuộc hướng tiếp cận huấn luyện không giám sát (unsupervised learning). Có nhiều kĩ thuật khác nhau tương tác và chuyển đổi cấu trúc của dữ liệu hiện tại. Một trong số đó là gom nhóm (clustering) hay còn có các tên gọi khác như chunking, grouping, bunching, hay segmentation.
Nếu supervised learning cố gắng phân loại các hành tinh trong số các vì sao thì clustering cố gắng gom cụm để tạo ra các chòm sao. Clustering cố gắng phân chia dữ liệu thành các khối dễ quan sát để người phân tích dễ dàng diễn giải tính chất của các thành viên trong nhóm. Dưới đây là một số câu hỏi điển hình.
- Những người mua sắm nào có cùng gu sản phẩm?
- Những người xem nào có cùng sở thích về một thể loại phim?
- Những mẫu máy in nào có cùng chi tiết dễ bị hư hỏng?
- Có cách nào phân chia văn bản thành năm thể loại khác nhau?
Có cách nào giảm tải tính toán nhưng vẫn giữ được độ chính xác?
GPA
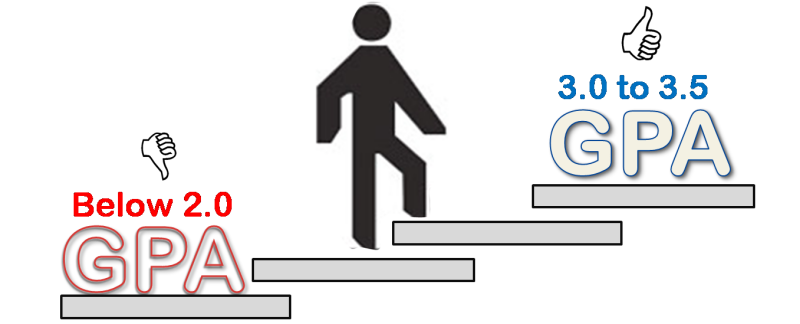
Một kĩ thuật khác cùng hướng tiếp cận unsupervised learning đó là giảm số chiều (dimensionality reduction). Dimensionality reduction là một cách để đơn giản hóa dữ liệu, giúp dữ liệu dễ trao đổi, tính toán nhanh hơn, và dễ lưu trữ hơn.
Về mặt ý tưởng, dimensionality reduction nhằm mô tả dữ liệu ngắn gọn hơn. Ví dụ như điểm GPA. Để đánh giá một sinh viên trong quá trình học, ta cần biết hàng chục lớp học sinh viên đó đã tham gia, hàng trăm bài kiểm tra và hàng ngàn bài tập mà sinh viên đó đã làm. Mỗi bài kiểm tra sẽ cho biết sinh viên này hiểu được nội dung bài giảng đến đâu. Nhưng đối với nhà tuyển dụng việc đọc hết các điểm số này là quá sức. May mắn thay, ta có thể tổng hợp điểm số lại bằng cách lấy trung bình. Ta không cần quan tâm đến hàng đống điểm số vừa rồi mà chỉ cần quan sát điểm GPA để đánh giá lực học của sinh viên đó. Dưới đây là các câu hỏi điển hình.
- Các nhóm cảm biến nào của động cơ phản lực có xu hướng đối chọi nhau?
- Điểm chung của những CEO thành công là gì?
- Nguyên lý chung của sự thay đổi giá xăng dầu trên khắp nước Mỹ là gì?
- Những nhóm từ nào có xu hướng xuất hiện cùng với nhau trong tập văn bản này? (Các chủ đề được đề cập là gì?)
Nếu mục tiêu của bạn là tóm tắt và đơn giản hóa tập các dữ liệu, dimensionality reduction và clustering là hai công cụ mà bạn nên dùng.
Tôi nên làm gì bây giờ?

Auto adjust temperature
Nhóm thứ ba trong các hướng tiếp cận của ML tập trung vào hành động là chủ yếu. Những thuật toán này gọi là huấn luyện tăng cường (reinforcement learning). Thay vì thuật toán regression chỉ dự đoán nhiệt độ có thể cao đến 36 độ vào ngày mai thì reinforcement learning sẽ thực hiện bước tiếp theo đó là đưa ra hành động cụ thể ví dụ như làm lạnh trước tầng trên cùng của tòa nhà văn phòng mặc dù nhiệt độ ngày hôm nay vẫn mát mẻ.
Các thuật toán RL ban đầu được lấy cảm hứng từ cách mà não loài chuột và loài người phản ứng lại với hình phạt và phần thưởng. Chúng có xu hướng cố gắng hành động thật nhiều để đạt được phần thưởng cao nhất. Ta cần cung cấp trước tập các hành động có thể có đồng thời cần phản hồi lại sau mỗi hành động để chúng biết được đâu là hành động tốt, xấu hay bình thường.
Các thuật toán RL thích hợp cho các hệ thống tự động đưa ra nhiều quyết định nhỏ mà không có sự hướng dẫn của con người. Thang máy, máy sưởi, máy lạnh và hệ thống chiếu sáng là những ví dụ điển hình. RL ban đầu được phát triển để điều khiển robot, vì vậy bất cứ thứ gì cần di chuyển tự động, từ máy bay do thám đến máy hút bụi tự động đều có thể áp dụng vào. Dưới đây là những câu hỏi điển hình.
- Tôi nên đặt quảng cáo ở đâu trên trang web để người xem có xu hướng click vào nhiều nhất?
- Tôi nên điều chỉnh nhiệt độ phòng lên, xuống, hay giữ nguyên?
- Tôi nên hút bụi phòng khách một lần nữa hay đem máy đi cắm sạc?
- Tôi nên mua bao nhiêu cổ phiếu của chứng khoán này ngay bây giờ?
- Tôi nên tiếp tục giữ nguyên tốc độ, thắng lại, hay tăng tốc khi thấy đèn tín hiệu vàng?
RL thường đòi hỏi nỗ lực nhiều hơn so với các loại thuật toán khác vì nó được tích hợp quá chặt chẽ với các phần còn lại của hệ thống. Ngược lại, đây là thuật toán có thể bắt đầu làm việc mà không cần bất kỳ dữ liệu nào ban đầu. Chúng thu thập dữ liệu khi bắt đầu chạy mô hình, và học thông qua thử và sai.
Nguồn tham khảo:
- Data Science for Beginners video 1: The 5 questions data science answers
