Chọn loại cơ sở dữ liệu phù hợp cho dự án của bạn – tưởng dễ mà khó!
Mọi cơ sở dữ liệu (CSDL – database) đều được tạo ra theo cách không giống nhau, mỗi loại đều có ưu và nhược điểm riêng. Thực tế cho thấy những loại database như MySQL, MongoDB đôi khi bị “lạm dụng” vì tính phổ biến của nó, bất chấp tính tương thích với dự án / nhu cầu hiện ...

Mọi cơ sở dữ liệu (CSDL – database) đều được tạo ra theo cách không giống nhau, mỗi loại đều có ưu và nhược điểm riêng. Thực tế cho thấy những loại database như MySQL, MongoDB đôi khi bị “lạm dụng” vì tính phổ biến của nó, bất chấp tính tương thích với dự án / nhu cầu hiện tại. Việc chỉnh sửa một database không phù hợp để cải thiện tính tương thích sẽ tiêu tốn nhiều thời gian, công sức và dẫn đến các lỗ hổng về bảo mật và khả năng mở rộng của toàn hệ thống. Vậy, việc chọn lựa một database phù hợp nhất cho dự án của bạn ngay từ đầu sẽ là sự lựa chọn tối ưu. Trước khi cân nhắc chọn database, mời các bạn đọc bài viết bên dưới, với nội dung gồm liệt kê các dạng database thường thấy, điểm mạnh / kém của chúng và nhất là chúng thích hợp để sử dụng cho mục đích nào.
*Bài viết sử dụng nhiều từ chuyên ngành, định nghĩa nằm ở phần cuối
1. Hệ thống cơ sở quản lí dữ liệu quan hệ – viết tắt RDBMS (Oracle, MySQL, MS Server, PostgreSQL)
Hệ thống quản lí cơ sở dữ liệu quan hệ được phát triển vào năm 1970 với nền tảng lí thuyết vững chắc và có ảnh hưởng lớn các hệ thống khác hôm nay. Tên tiếng Anh: *Relational database management system – RDBMS.
Các RDBMS lưu trữ dữ liệu với dạng “quan hệ”: các bảng với dòng và cột nơi mọi thông tin dữ liệu được lưu trữ như một giá trị của một ô cụ thể. Dữ liệu trong một RDBMS được quản lý thông qua giao thức nổi tiếng SQL – ngôn ngữ truy vấn cấu trúc. SQL là giao thức được chuẩn hoá, đem đến sự đa nhiệm và tính dễ đoán biết.
Sau một thời gian bị người dùng sử dụng sai quy cách vì tính phổ biến của nó, người sáng lập SQL là E.F Codd đã lập nên 12 quy tắc sử dụng áp dụng cho toàn bộ các hệ thống RDBMS, giúp các cơ chế này trả về đúng các dữ liệu được tìm kiếm, hạn chế việc thay đổi cấu trúc dữ liệu, đảm bảo tính thống nhất và đáng tin cậy của các hệ thống này.
Điểm mạnh
Các hệ thống RDBMS hữu dụng trong việc xử lí các dữ liệu được cấu trúc kỹ càng và hỗ trợ ACID – 4 thuộc tính quan trọng của bất kì hệ thống cơ sở dữ liệu nào:
Tính nguyên tố (Atomicity). Một giao dịch có nhiều thao tác khác biệt thì hoặc là toàn bộ các thao tác hoặc là không một thao tác nào được hoàn thành. Chẳng hạn việc chuyển tiền có thể thành công hay trục trặc vì nhiều lý do nhưng tính nguyên tố bảo đảm rằng một tài khoản sẽ không bị trừ tiền nếu như tài khoản kia chưa được cộng số tiền tương ứng.
Tính nhất quán (Consistency). Một giao dịch hoặc là sẽ tạo ra một trạng thái mới và hợp lệ cho dữ liệu, hoặc trong trường hợp có lỗi sẽ chuyển toàn bộ dữ liệu về trạng thái trước khi thực thi giao dịch.
Tính độc lập (Isolation). Một giao dịch đang thực thi và chưa được xác nhận phải bảo đảm tách biệt khỏi các giao dịch khác.
Tính bền vững (Durability). Dữ liệu được xác nhận sẽ được hệ thống lưu lại sao cho ngay cả trong trường hợp hỏng hóc hoặc có lỗi hệ thống, dữ liệu vẫn đảm bảo trong trạng thái chuẩn xác.
Dữ liệu được lưu trữ và truy xuất dễ dàng bằng các lệnh truy vấn SQL. Cấu trúc dữ liệu cũng có thể được mở rộng nhanh chóng, việc bổ sung thêm các dữ liệu mới cũng không ảnh hưởng tới các data có sẵn. Các RDBMS còn có khả năng cấp quyền truy xuất và chỉnh sửa thông tin cho các loại người dùng khác nhau (admin, user, khách vãng lai, etc.). Ví dụ, khách hàng có thể đăng nhập vào CSDL để kiểm tra thông tin tài khoản, nhưng chỉ các nhân viên hoặc admin mới có thể xem và thay đổi thông tin đó.
Điểm yếu
Điểm yếu lớn nhất của RDBMS là không xử lí tốt các dữ liệu phi cấu trúc. Các dữ liệu khi bị chia cắt cần được viết lại dưới dạng khác dễ đọc hơn là ở dạng bảng tính (table), và tốc độ xử lí dữ liệu cũng khá chậm. Việc thay đổi cơ sở dữ liệu dạng RDBMS cũng khá khó vì tính quy củ chặt chẽ của nó.
RDBMS tốn nhiều chi phí hơn các hệ thống cơ sở dữ liệu khác trong việc xây dựng và phát triển. Ngoài ra, cấu trúc của RDBMS làm phức tạp hoá việc nâng cấp và mở rộng máy chủ theo chiều dọc hoặc ngang (*horizontal/ vertical scalability). Việc phân mảnh (*sharding)trong khi vẫn giữ vững các tiêu chí về ACID là một thử thách lớn.
Nên dùng cơ sở dữ liệu RDBMS trong các trường hợp nào?
- Các trường hợp khi giữ vững tính toàn vẹn dữ liệu – dữ liệu không thể bị chỉnh sửa dễ dàng là tối cần thiết. Ví dụ: các ứng dụng của mảng tài chính, ứng dụng trong quốc phòng, an ninh và trong lĩnh vực thông tin sức khoẻ cá nhân.
- Các lĩnh vực tự động hoá
- Thông tin nội bộ
2. Document store (MongoDB, Couchbase)

Document store được gọi là các cơ sở dữ liệu hướng tài liệu, một thiết kế riêng biệt cho việc lưu trữ tài liệu dạng văn kiện JSON, BSON hoặc XML. Vì là cấu trúc dữ liệu không ràng buộc khác với SQL, các CSDL này không đòi hỏi người dùng tự tạo bảng nhập liệu trước khi nhập dữ liệu vào. Các tài liệu có thể chứa bất kì dữ liệu nào. CSDL dạng này có các cặp khoá – giá trị nhưng cũng có đính kèm các trị số siêu dữ liệu (*metadata) giúp việc truy vấn (*query) dễ dàng hơn.
Điểm mạnh
CSDL hướng tài liệu rất linh hoạt, có thể xử lí dữ liệu nửa cấu trúc và không cấu trúc rất tốt. Người dùng không cần quan tâm tới dạng dữ liệu khi setup, điều này tốt trong trường hợp bạn không lường trước được dạng dữ liệu nào bạn sẽ cần lưu trữ.
Người dùng có thể thiết kế một cấu trúc cho một tài liệu cụ thể mà không ảnh hưởng tới các tài liệu khác. Schema cho CSDL cũng có thể được tuỳ chỉnh mà không gây ra thời gian downtime, giúp đem đến *high availability (tính sẵn sàng cao). Thời gian ghi dữ liệu cũng rất nhanh.
Ngoài tính linh hoạt, các lập trình viên còn ưa chuộng document store bởi tính dễ dàng mở rộng theo chiều ngang của chúng. Qua trình sharding cũng dễ hiểu và dễ thao tác hơn so với CSDL quan hệ, nên document store có thể mở rộng nhanh và dễ dàng.
Điểm yếu
CSDL dạng lưu trữ tài liệu hy sinh các yếu tố ACID để đổi lấy sự linh hoạt. Ngoài ra, việc truỵ vấn chỉ có thể được thực hiện trong từng tài liệu, không thể truy vấn dữ liệu trên nhiều tài liệu khác nhau.
Nên sử dụng CSDL dạng lưu trữ tài liệu trong các trường hợp nào?
- Dữ liệu phi cấu trúc hoặc không có cấu trúc
- Quản lý nội dung
- Phân tích dữ liệu chuyên sâu
- Tạo mẫu nhanh
3. CSDL dạng khoá – giá trị (Redis, Memcached)
Key-value stores là kiểu lưu trữ đơn giản nhất trong các loại CSDL NoSQL đồng thời nó cũng là kiểu lưu trữ cho tất cả các HQT CSDL NoSQL. Thông thường, các HQT CSDL Key-value lưu trữ dữ liệu dưới dạng key (là một chuỗi duy nhất) liên kết với value có thể ở dạngchuỗi văn bản đơn giản hoặc các tập, danh sách dữ liệu phức tạp hơn. Quá trình tìm kiếm dữ liệu thường sẽ được thực hiện thông qua key, điều này dẫn đến sự hạn chế về độ chính xác.
CDSL chìa khoá – giá trị là một dạng CSDL phi quan hệ nơi mà mỗi giá trị được gán cho một key (chìa khoá) nhất định, còn được biết đến như associative array – mảng liên tưởng.
Một “key” là một định danh độc nhất được gán cho một giá trị. Keys có thể là bất cứ thứ gì cho phép bởi DBMS. Trong Redis, keys có thể là một hàm nhị phân lên tới 512MB
“Giá trị” có thể được lưu trữ dưới dạng blob (Là kiểu dữ liệu của một cột trong bảng RDBMS, có thể lưu ảnh lớn hoặc dữ liệu văn bảng như những thuộc tính.) và không cần schema định sẵn.. Các gía trị này có thể được gán bất cứ loại giá trị nào:
- Số
- Chuỗi giá trị
- Bộ đếm
- JSON, XML, HTML, PHP,
- Nhị phân
- Hình ảnh
- Video ngắn
- Danh sách
Điểm mạnh
Dạng CSDL này có rất nhiều lợi thế. Nó rất linh hoạt và có thể xử lí nhiều loại dữ liệu một cách nhanh chóng. Các chìa khoá được dùng để truy xuất thẳng tới các giá trị tìm kiếm, mà không cần thông qua quá trình index (quá trình tìm kiếm dữ liệu và đánh giá độ chính xác của dữ liệu đó của hệ thống CSDL), giúp quá trình tìm kiếm diễn ra nhanh chóng. Tính linh động cũng là một điểm mạnh của CSDL dạng này: lưu trữ key – value có thể được chuyển từ hệ thống này sang hệ thống khác mà không cần code lại. Cuối cùng, CSDL key – value có thể mở rộng theo chiều ngang dễ dàng và chi phí vận hành thấp.
Điểm yếu
Tính linh hoạt của CSDL dạng key – value bị đánh đổi bởi tính chính xác. Hầu như rất khó để truy xuất giá trị chính xác từ CSDL dạng này vì dữ liệu được lưu trữ theo blob, nên kết quả trả về hầu như đều theo blob. Điều này gây ra khó khan khi báo cáo số liệu hoặc cần chỉnh sửa một phần của các giá trị. Cuối cùng, không phải objects nào cũng có thể được cấu hình thành cặp chìa khoá – giá trị được.
Nên dùng CSDL key – value cho các trường hợp nào?
- Khuyến nghị các sản phẩm / thông tin tương tự
- Thông tin và thiết lập người dùng
- Dữ liệu phi cấu trúc như review sản phẩm, bình luận của blog
- Quản lý session trên diện rộng
- Dữ liệu được truy xuất thường xuyên nhưng không thường xuyên được cập nhật
4. Mô hình wide – column (Cassandra, HBase)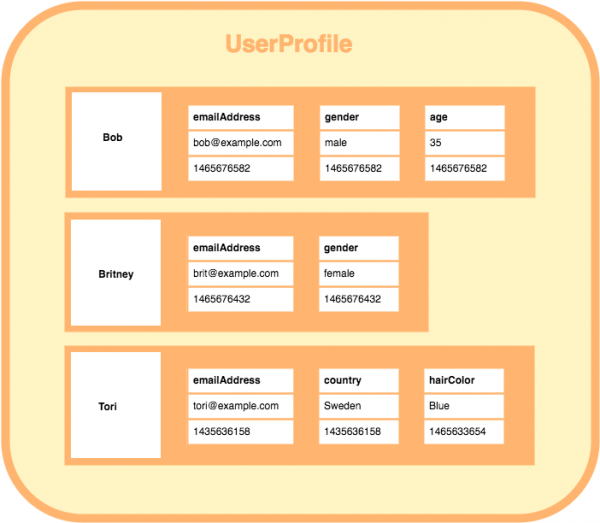
Mô hình wide – column là một dạng lưu CSDL phi quan hệ lưu trữ theo dạng cột. Mô hình này có vài điểm tương đồng với mô hình key – value nhưng cũng có vài tính chất của dạng CSDL quan hệ.
Mô hình wide – column dựa trên khái niệm keyspace thay vì schema. Một keyspace bao gồm nhiều cụm column (tương tự như table nhưng linh hoạt hơn về cấu trúc), mỗi cụm bao gồm nhiều hàng và nhiều cột riêng biệt. Mỗi hàng không cần phải có số lượng hoặc loại cột. Một timestamp quyết định phiên bản gần nhất của data.
Điểm mạnh
Loại CSDL này có cả lợi ích của CSDL quan hệ và phi quan hệ, có thể xử lí dữ liệu cấu trúc và phi cấu trúc, đồng thời cũng dễ dàng nâng cấp. So với CSDL quan hệ, khả năng mở rộng theo chiều ngang cũng dễ dàng và nhanh chóng hơn.
CSDL dạng cột có khả năng nén tốt hơn CSDL dạng dòng. Đồng thời, data set lớn có thể dễ dàng duyệt hơn. Mô hình wide – column có khả năng xử lí tốt các yêu cầu truy xuất tập trung.
Điểm yếu
CSDL dạng cột dễ dàng update theo cụm, bù lại việc upload và update số liệu cá nhân rất khó. Cộng thêm thực tế là mô hình wide – column chậm hơn so với CSDL quan hệ khi xử lí các giao dịch.
Nên sử dụng mô hình wide – column cho trong trường hợp nào?
- Xử lí các dữ liệu lớn (big data) khi tốc độ cần thiết
- Lưu trữ dữ liệu big data
- Các project có quy mô lớn
CSDL dạng bộ máy tìm kiếm (Elasticsearch)
Elasticsearch về cốt lõi là một bộ máy tìm kiếm và không hoàn toàn là là CSDL chuyên biệt như các loại trên, nhưng ngày càng được giới developers tận dụng để giảm thiểu độ lag khi tìm kiếm thông tin. Elasticsearch được xem như một CSDL dạng phi quan hệ, dựa trên nền tảng lưu trữ dữ liệu dạng văn kiện, thiết kế chuyên biệt để tối ưa hoá lưu trữ và trao đổi dữ liệu nhanh chóng.
Điểm mạnh
Elasticsearch có khả năng mở rộng cao, với schema linh hoạt và tốc độ trả về thông số lưu trữ nhanh, hỗ trợ khả năng tìm kiếm nâng cao: tìm kiếm full text, khuyến nghị các kết quả tìm kiếm, và hỗ trợ các thông tin tìm kiếm phức tạp.
Một trong số những tính năng thú vị của Elasticsearch đó là “stemming”. Stemming là từ để chỉ kỹ thuật dùng để biến đổi 1 từ về dạng gốc (được gọi là stem hoặc root form) bằng cách đơn giản là loại bỏ 1 số ký tự nằm ở cuối được xem như biến thể của từ. Ví dụ: các từ như walked, walking, walks, bằng cách bỏ đi -ed, -ing hoặc -s, chúng ta sẽ được từ nguyên gốc là walk. Một ví dụ khác trong ngày tìm kiếm việc làm, một user có thể search cụm từ “paying jobs” cũng có thể sẽ tìm ra các kết quả có liên quan tới từ “paid” và “pay”. Tính năng này hiện tại hữu dụng với các ngôn ngữ phổ biến như tiếng Anh, nhưng có khả năng áp dụng cao với các ngôn ngữ khác như tiếng Việt tuy nhiên đòi hỏi độ tuỳ chỉnh cao.
Điểm yếu
Elasticsearch được sử dụng với hình thức thay thế hoặc bổ trợ cho CSDL có sẵn hơn là độc lập. Elasticsearch còn có nhược điểm là độ ổn định và bảo mật kém, không có giao thứcxác định và xác nhận danh tính của một khách truy cập hoặc điều khiển đăng nhập. Ngoài ra, Elasticsearch không hỗ trợ thanh toán.
Nên dùng các bộ máy tìm kiếm Elastisearch cho các trường hợp sau:
- Cung cấp các thông tin phụ hỗ trợ việc ra quyết định khi tìm kiếm dữ liệu
- Lưu file tạm
Bài viết có sử dụng các từ ngữ chuyên ngành quản lý cơ sở dữ liệu như:
- Database là một tập hợp liên kết các dữ liệu, thường đủ lớn để lưu trên một thiết bị lưu trữ như đĩa hay băng. Dữ liệu này được duy trì dưới dạng một tập hợp các tập tin trong hệ điều hành hay được lưu trữ trong các hệ quản trị cơ sở dữ liệu.
- Schema là thuật ngữ để chỉ định nghĩa về cấu trúc dữ liệu. Từ điển Websters định nghĩa schema là “phác thảo hoặc hình dung khái quát dễ hiểu về một khái niệm nào đó; ví dụ, 5 dấu chấm là schema của số 5”.
- Stemming là kỹ thuật dùng để biến đổi 1 từ về dạng gốc (được gọi là stem hoặc root form) bằng cách cực kỳ đơn giản là loại bỏ 1 số ký tự nằm ở cuối từ mà nó nghĩ rằng là biến thể của từ.
- Key – value chỉ các CSDL key-value lưu trữ dữ liệu dưới dạng key – chìa khoá (một chuỗi duy nhất) liên kết với value – giá trị có thể ở dạng chuỗi văn bản đơn giản hoặc các tập, danh sách dữ liệu phức tạp hơn.
- Relational database còn được biết đến như Relational Database Management System (Hệ thống quản lý cơ sở dữ liệu quan hệ) Trong RDBMS, dữ liệu được biểu diễn bởi các hàng. Relational Database là cơ sở dữ liệu được sử dụng phổ biến nhất. Nó chứa các bảng và mỗi bảng có Primary Key riêng. Bởi vì các bảng này được tổ chức chặt chẽ nên việc truy cập dữ liệu trở nên dễ dàng hơn trong RDBMS.
- Nonrelational database chỉ những cơ sở dữ liệu không dùng mô hình dữ liệu quan hệ để quản lý dữ liệu trong lĩnh vực phần mềm, còn gọi là CSDL không ràng buộc.
- High scalability nghĩa là “Khả năng mở rộng cao“. Ở đây chỉ khả năng của hệ thống máy chủ, hạ tầng mạng, băng thông có thể nâng cấp, chịu tải lớn, mở rộng nhanh chóng khi có nhu cầu.
- Sharding là một tiến trình lưu giữ các bản ghi dữ liệu qua nhiều thiết bị để đáp ứng yêu cầu về sự gia tăng dữ liệu. Khi kích cỡ của dữ liệu tăng lên, một thiết bị đơn (1 database hay 1 bảng) không thể đủ để lưu giữ dữ liệu. Sharding giải quyết vấn đề này với việc mở rộng phạm vi theo bề ngang (horizontal scaling). Với Sharding, bạn bổ sung thêm nhiều thiết bị để hỗ trợ cho việc gia tăng dữ liệu và các yêu cầu của các hoạt động đọc và ghi.
- Horizontal/ vertical scaling theo thứ tự là nâng cấp mở rộng theo chiều ngang, tức là nâng số máy chủ, ngược lại vertical scaling là nâng cấp dọc, là bổ sung thêm tài nguyên như CPU, RAM vào máy chủ có sẵn.
- Metadata là dạng định nghĩa dữ liệu như: bảng, cột, một báo cáo, các luật doanh nghiệp hay những quy tắc biến đổi. Metadata bao quát tất cả các phương diện của kho dữ liệu.
- Query có nghĩa là truy vấn. Đây thực chất là một câu lệnh SQL được xây dùng để tổng hợp dữ liệu từ các bảng nguồn. Có nhiều loại query khác nhau như crosstab, action, union và data – definition.
Hy vọng bài viết sẽ giúp các bạn có cái nhìn tổng thể về các loại CSDL và các trường hợp thích hợp để sử dụng chúng!
(Bài viết có tham khảo thông tin từ các nguồn: Vietjack, vngeek, kipalog và Wikipedia)
Techtalk Via KDATA.VN
