Crawl dữ liệu từ trang amazon bằng python
Crawl dữ liệu từ các trang web hẳn là 1 khái niệm không xa lạ đối với người người lập trình web. Tuy nhiên sau hơn 2 năm làm lập trình thì tôi mới có lần đầu trải nghiệm crawl dữ liệu của mình , mà lại còn từ 1 trang web mua bán nổi tiếng là amazon. Có nhiều bạn lại hỏi làm lập trình thì crawl dữ ...
Crawl dữ liệu từ các trang web hẳn là 1 khái niệm không xa lạ đối với người người lập trình web. Tuy nhiên sau hơn 2 năm làm lập trình thì tôi mới có lần đầu trải nghiệm crawl dữ liệu của mình , mà lại còn từ 1 trang web mua bán nổi tiếng là amazon. Có nhiều bạn lại hỏi làm lập trình thì crawl dữ liệu từ trang web mua bán amazon làm cái gì? Chuyện bắt đầu từ vài tháng trước khi thằng bạn thân của tôi uống rượu say và đi xe máy đâm vào cột điện bị gãy chân, đến giờ vẫn chưa phục hồi được để đi làm. Vài ngày trước ngồi trà đá tâm sự thì có nghe nó kể về việc ngồi nhà làm drop shipping gì gì đó, tôi lên mạng search thì nó cũng khá hay, các bạn có thể đọc ở đây . Mà nỗi khổ của việc này theo như lời nó kể thì kiểm soát giá sản phẩm ở trên trang amazon rất khó, phải vào từng link sản phẩm và ghi giá lại. Nên tôi mới nghĩ đến việc tại sao không crawl dữ liệu từ trang amazon về luôn cho nhanh. Và sau 1 ngày ngồi mày mò, copy code các kiểu thì tôi đã có thể lấy được những gì từ trang web amazon mà thằng bạn tôi muốn. Bài viết sẽ hướng dẫn các bạn dùng python để crawl dữ liệu từ amazon về.
I. Cài đặt môi trường
Chúng ta sẽ cần có python và 1 vài package để tải trang web xuống và phân tích html.
- Python: các bạn có thể tải phiên bản mới nhất tại đây tại đây
- Python PIP để cài đặt các package
- Python Requests cho phép bạn gửi request http
- Python LXML để phân tích html
Nếu máy tính của bạn đã có pip, việc cài đặt lxml sẽ vô cùng đơn giản. Chỉ cần chạy lệnh sau ở trong terminal:
pip install requests lxml
II. Cách thực hiện.
Khi các bạn vào một đường link sản phẩm, ví dụ như : https://www.amazon.com/Upgraded-Dimmable-Spectrum-Adjustable-Gooseneck/dp/B07PXP7DW5
Các bạn có thể nhìn thấy các thông tin sau:
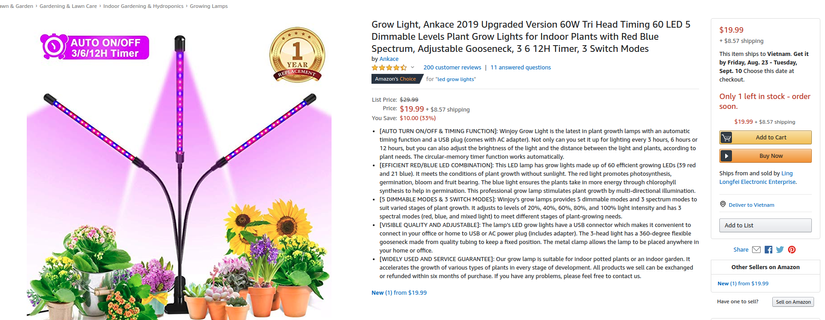
Việc của tôi đơn giản là chỉ đi lấy price và name của sản phẩm thôi. Nhưng có những url mà amazon sẽ yêu cầu các bạn phải có cookies để hiển thị giá sản phẩm. Việc lấy cookies trên trình duyệt rất đơn giản cho nên các bạn tự tìm hiểu nhé.
Ta sẽ có:
cookies = { ... }
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36'
}
Chúng ta sẽ tải trang html về, đầu tiên cần request lên trang web để trang web trả về response
response = requests.get(url, headers=headers, verify=False, cookies=cookies)
url ở đây chính là https://www.amazon.com/Upgraded-Dimmable-Spectrum-Adjustable-Gooseneck/dp/B07PXP7DW5. Và sau đó content của response chính là trang html mà các bạn cần lấy. Chúng ta sẽ phải biết được thuộc tính name và price của product sẽ hiển thị trên trang html đó như thế nào. Cách đơn giản nhất là kiểm tra ở trên trình duyệt.

Như vậy giá sản phẩm sẽ có id là priceblock_ourprice
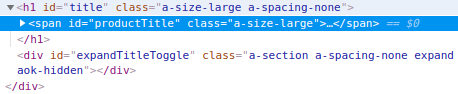
Tên của sản phẩm sẽ nằm trong thẻ h1 có id là title
Ta cần viết 1 hàm để lấy các giá trị trên sau khi tải được trang html từ url về:
from lxml import html
import csv
import os
import requests
from exceptions import ValueError
from time import sleep
from random import randint
def parse(url):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36'
}
try:
# Retrying for failed requests
for i in range(20):
# Generating random delays
sleep(randint(1,3))
# Adding verify=False to avold ssl related issues
cookies = { // cookies trên máy các bạn }
response = requests.get(url, headers=headers, verify=False, cookies=cookies)
if response.status_code == 200:
doc = html.fromstring(response.content)
XPATH_NAME = '//h1[@id="title"]//text()'
XPATH_PRICE = '//span[contains(@id,"priceblock_ourprice")]/text()'
RAW_NAME = doc.xpath(XPATH_NAME)
RAW_PRICE = doc.xpath(XPATH_PRICE)
NAME = ' '.join('.join(RAW_NAME).split()) if RAW_NAME else None
PRICE = ' '.join('.join(RAW_PRICE).split()).strip() if RAW_SALE_PRICE else None
data = {
'NAME': NAME,
'PRICE': PRICE,
'URL': url,
}
return data
elif response.status_code==404:
break
except Exception as e:
print e
Sau khi lấy được data về, ta có thể lưu chúng vào file csv, chẳng hạn như tôi có 2 url cần lấy giá và tên sản phẩm về thì đoạn code thực hiện sẽ như sau:
def ReadUrl():
UrlList = ['https://www.amazon.com/Upgraded-Dimmable-Spectrum-Adjustable-Gooseneck/dp/B07PXP7DW5', 'https://www.amazon.com/Autel-MS906-Automotive-Diagnostic-Adaptations/dp/B01CQNNBA4?ref_=Oct_DLandingS_PC_b8ca5425_2&smid=A3MNQOSQ336D3K']
extracted_data = []
for i in UrlList:
print "Processing: " + i
# Calling the parser
parsed_data = parse(i)
if parsed_data:
extracted_data.append(parsed_data)
# Writing scraped data to csv file
with open('scraped_data.csv', 'w') as csvfile:
fieldnames = ['NAME','PRICE','URL']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
for data in extracted_data:
writer.writerow(data)
if __name__ == "__main__":
ReadUrl()
Các bạn lưu tên file là product_amazon.py và chạy python product_amazon.py để thấy kết quả nhé
Đây là ví dụ đơn giản để lấy 1 vài dữ liệu của sản phẩm trên amazon bằng ngôn ngữ python. Có rất nhiều cách để crawl dữ liệu về. Hi vọng bài viết sẽ có ích cho các bạn, đặc biệt là các bạn đang làm nghề tay trái là drop shipping. Cảm ơn các bạn đã đọc bài viết của mình !
