Giải thích 8 thuật toán machine learning Python trong 8 phút
Machinelearning là từ khóa được nhắc đến rất nhiều trong thời gian qua. Tuy nhiên, vẫn còn những hiểu lầm về thuật ngữ này. Biểu đồ bên dưới minh họa khá rõ ràng sự quan tâm của mọi người tới Machine learning, dựa theo phân tích của Google Trend. Tuy nhiên, mục đích của bài viết ...

Machinelearning là từ khóa được nhắc đến rất nhiều trong thời gian qua. Tuy nhiên, vẫn còn những hiểu lầm về thuật ngữ này. Biểu đồ bên dưới minh họa khá rõ ràng sự quan tâm của mọi người tới Machine learning, dựa theo phân tích của Google Trend.
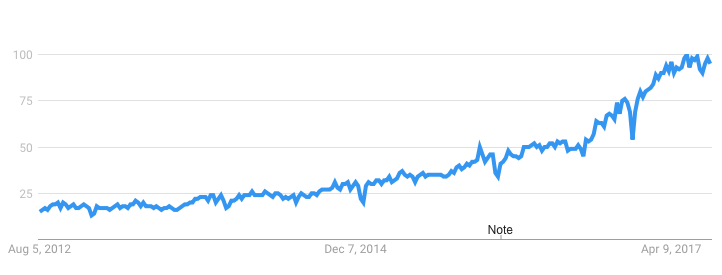
Tuy nhiên, mục đích của bài viết này không chỉ phản ánh sự phổ biến của machine learning. Bài viết này là để giải thích và thực hiện các thuật toán machine learning liên quan một cách rõ ràng và súc tích. Hy vong bài viết cung cấp cho các bạn hiểu thêm về các thuật toán, hoặc ít nhất nó cũng giúp bạn biết phải bắt đầu code từ đâu.
Trong bài viết này tôi sẽ giới thiệt tổng cộng tám thuật toán Machine Learning. Bạn có thể đọc tuần tự từng thuật toán hoặc bỏ qua một số thuật toán nếu bạn đã biết :
Linear regression (Hồi quy tuyến tính)
Logistic regression (Hồi quy logistic)
Decision trees
Support vector machines
K-nearest neighbors
Random forests
Để khiến cho mọi thứ trở nên dễ dàng hơn, tôi đã sử dụng Python 3.5.2. Dưới đây là những Package mà tôi đã Import trước vào bài tập. Tôi cũng sử dụng bộ dữ liệu mẫu được lấy từ bộ dữ liệu Diabetes và Iris trong UCI Machine Learning Repository. Cuối cùng, nếu bạn muốn bỏ qua tất cả những điều này và chỉ muốn thấy code, hãy cảm ơn Github.
|
1 2 3 4 5 6 7 |
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns %matplotlib inline |
1. Hồi quy tuyến tính
Đây có lẽ là thuật toán machine phổ biến nhất hiện nay và thường bị đánh giá thấp nhất. Nhiều nhà khoa học dữ liệu quên rằng điều đơn nhất luôn luôn lựa chọn tốt nhất khi thực hiện.
Hồi quy tuyến tính là một thuật toán supervised dự đoán một kết quả dựa trên các tính năng liên tục. Nó linh hoạt theo nghĩa nó có thể chạy trên một biến duy nhất (hồi qui tuyến tính đơn giản) hoặc trên nhiều tính năng (hồi quy đa tuyến tính nhiều). Nó hoạt động bằng cách gán giá trị tối ưu cho các biến để tạo ra một đường thẳng (ax + b) sẽ được sử dụng để dự đoán một đầu ra. Xem video dưới đây để có lời giải thích kỹ lưỡng hơn.
Bây giờ bạn đã nắm bắt các khái niệm đằng sau hồi quy tuyến tính, hãy tiếp tục và thực hiện nó bằng Python.
Bắt đầu
|
1 2 3 4 5 6 |
from sklearn import linear_model df = pd.read_csv(‘linear_regression_df.csv’) df.columns = [‘X’, ‘Y’] df.head() |
Hình dung
|
1 2 3 4 5 6 7 |
sns.set_context(“notebook”, font_scale=1.1) sns.set_style(“ticks”) sns.lmplot(‘X’,’Y’, data=df) plt.ylabel(‘Response’) plt.xlabel(‘Explanatory’) |
Thực hiện
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
linear = linear_model.LinearRegression() trainX = np.asarray(df.X[20:len(df.X)]).reshape(-1, 1) trainY = np.asarray(df.Y[20:len(df.Y)]).reshape(-1, 1) testX = np.asarray(df.X[:20]).reshape(-1, 1) testY = np.asarray(df.Y[:20]).reshape(-1, 1) linear.fit(trainX, trainY) linear.score(trainX, trainY) print(‘Coefficient: n’, linear.coef_) print(‘Intercept: n’, linear.intercept_) print(‘R² Value: n’, linear.score(trainX, trainY)) predicted = linear.predict(testX) |
2. Hồi quy logistic
Hồi quy logistic là một thuật toán phân loại giám sát vì thế rất hữu ích cho việc tính toán các giá trị rời rạc. Nó thường được sử dụng để dự đoán xác suất của một sự kiện sử dụng chức năng logistic để có được một đầu ra giữa 0 và 1.
Lần đầu tiên tiếp xúc với hồi quy Logistic, tôi đã không bị ấn tượng nhiều với nó, vì vậy tôi đã không chú ý nhiều đến nó. Và sau này, tôi nhận ra mình đã sai lầm. Hồi quy logistic được sử dụng trong nhiều thuật toán machine learning quan trọng như neural networks . Xem video để hiểu rõ thêm.
Bây giờ bạn đã có một nắm bắt được các khái niệm đằng sau hồi quy logistic, chúng ta hãy thực hiện nó bằng Python.
Bắt đầu
|
1 2 3 4 5 6 |
from sklearn.linear_model import LogisticRegression df = pd.read_csv(‘logistic_regression_df.csv’) df.columns = [‘X’, ‘Y’] df.head() |
Hình dung
|
1 2 3 4 5 6 7 8 9 10 |
logistic = LogisticRegression() X = (np.asarray(df.X)).reshape(-1, 1) Y = (np.asarray(df.Y)).ravel() logistic.fit(X, Y) logistic.score(X, Y) print(‘Coefficient: n’, logistic.coef_) print(‘Intercept: n’, logistic.intercept_) print(‘R² Value: n’, logistic.score(X, Y)) |
3. Decision trees
Decision trees là một hình thức học hỏi có giám sát được sử dụng cho mục đích phân loại và hồi quy. Theo kinh nghiệm của tôi, chúng thường được sử dụng cho các mục đích phân loại. Trong thuật toán này, chúng ta chia “population” thành hai hoặc các nhóm tập hợp. Điều này được thực hiện dựa trên các biến thuộc tính quan trọng nhất / các biến độc lập để phân loại các groups có thể được. Thông thường, các thuộc tính quan trọng nhất trong quy trình sẽ gần với gốc của cây.
Decision tree đang ngày càng trở nên phổ biến và có thể xem như là một thuật toán mạnh mẽ cho tất cả các khoa học dữ liệu, đặc biệt là khi kết hợp với các kỹ thuật như random forests, boosting, và bagging . Xem video dưới đây để xem sâu hơn về chức năng cơ bản của decision trees.
Giờ bạn đã biết cách nó hoạt động, đã đến lúc thực hiện nó bằng python
Bắt đầu
|
1 2 3 4 5 6 |
from sklearn import tree df = pd.read_csv(‘iris_df.csv’) df.columns = [‘X1’, ‘X2’, ‘X3’, ‘X4’, ‘Y’] df.head() |
Hình dung
|
1 2 3 4 5 6 7 8 9 |
from sklearn.externals.six import StringIO from IPython.display import Image import pydotplus as pydot dot_data = StringIO() tree.export_graphviz(decision, out_file=dot_data) graph = pydot.graph_from_dot_data(dot_data.getvalue()) Image(graph.create_png()) |
Thực hiện
|
1 2 3 4 5 6 7 8 9 |
from sklearn.cross_validation import train_test_split decision = tree.DecisionTreeClassifier(criterion=’gini’) X = df.values[:, 0:4] Y = df.values[:, 4] trainX, testX, trainY, testY = train_test_split( X, Y, test_size = 0.3) decision.fit(trainX, trainY) print(‘Accuracy: n’, decision.score(testX, testY)) |
4. Support vector machines
Support vector machines (SVM) là một thuật toán phân loại có giám sát nổi tiếng tạo ra một đường phân chia giữa các loại dữ liệu khác nhau. Cách tính véc tơ này, hiểu theo cách đơn giản nhất, bằng cách tối ưu hóa để điểm gần nhất trong mỗi nhóm sẽ cách nhau xa nhất.
Vectơ này, mặc định, thường là đường tuyến tính. Tuy nhiên, điều này không phải lúc nào cũng đúng. Có rất nhiều điều cần nói về SVM, vì vậy hãy nhớ xem video hướng dẫn dưới đây.
Bây giờ bạn đã biết về SVMs, hãy bắt tay vào việc làm nó với Python
Bắt đầu
|
1 2 3 4 5 6 7 |
from sklearn import svm df = pd.read_csv(‘iris_df.csv’) df.columns = [‘X4’, ‘X3’, ‘X1’, ‘X2’, ‘Y’] df = df.drop([‘X4’, ‘X3’], 1) df.head() |
Hình dung
|
1 2 3 4 5 6 7 |
sns.set_context(“notebook”, font_scale=1.1) sns.set_style(“ticks”) sns.lmplot(‘X1’,’X2', scatter=True, fit_reg=False, data=df, hue=’Y’) plt.ylabel(‘X2’) plt.xlabel(‘X1’) |
Thực hiện
|
1 2 3 4 5 6 7 8 9 10 |
from sklearn.cross_validation import train_test_split support = svm.SVC() X = df.values[:, 0:2] Y = df.values[:, 2] trainX, testX, trainY, testY = train_test_split( X, Y, test_size = 0.3) support.fit(trainX, trainY) print(‘Accuracy: n’, support.score(testX, testY)) pred = support.predict(testX) |
5. K-nearest neighbors
K-nearest neighbors (KNN) là một thuật toán phân loại có giám sát. Thuật toán dựa vào các tâm điểm khác nhau và so sánh khoảng cách sử dụng một số chức năng (thường là Euclidean). Sau đó, nó phân tích các kết quả và chỉ định mỗi điểm tối ưu nhất trong mỗi nhóm, để xác định điểm gần nhất với nó. Hãy xem video dưới đây để biết thêm về những gì đang diễn ra đằng sau thuật toán KNN.
Bây giờ bạn đã có một số khái niệm đằng sau thuật toán KNN, chúng ta hãy thực hiện nó bằng Python.
Bắt đầu
|
1 2 3 4 5 6 7 |
from sklearn.neighbors import KNeighborsClassifier df = pd.read_csv(‘iris_df.csv’) df.columns = [‘X1’, ‘X2’, ‘X3’, ‘X4’, ‘Y’] df = df.drop([‘X4’, ‘X3’], 1) df.head() |
Hình dung
|
1 2 3 4 5 6 7 |
sns.set_context(“notebook”, font_scale=1.1) sns.set_style(“ticks”) sns.lmplot(‘X1’,’X2', scatter=True, fit_reg=False, data=df, hue=’Y’) plt.ylabel(‘X2’) plt.xlabel(‘X1’) |
Thực hiện
