Giới thiệu về HTTP (Phần 1)
Đây là bài hướng dẫn về HTTP, giao thức không trạng thái nằm bên dưới tất cả các trang web được dịch từ cuốn sách Introduction to HTTP xuất bản online bởi Launch School. Hướng dẫn này sẽ giúp người mới bắt đầu tìm hiểu cách thức hoạt động của các ứng dụng web và hiểu tại sao việc xây dựng các ứng ...
Đây là bài hướng dẫn về HTTP, giao thức không trạng thái nằm bên dưới tất cả các trang web được dịch từ cuốn sách Introduction to HTTP xuất bản online bởi Launch School. Hướng dẫn này sẽ giúp người mới bắt đầu tìm hiểu cách thức hoạt động của các ứng dụng web và hiểu tại sao việc xây dựng các ứng dụng web mạnh mẽ và bảo mật lại rất khó khăn.
Giới thiệu
Bắt đầu
Nếu bạn giống hầu hết mọi người, sử dụng Internet trong một thời gian dài - và thường xuyên gõ các địa chỉ URL ở đầu trình duyệt của bạn, bắt đầu bằng các chữ cái H,T,T,P, tiếp theo là dấu hai chấm, dấu gạch chéo, dấu gạch chéo, w,w,w rồi tên miền, hết lần này đến lần khác, nhưng chưa bao giờ biết hoặc quan tâm để biết về nó.
HTTP là cốt lõi của trang web, và cũng là cốt lõi của các ứng dụng web động. Hiểu HTTP là trung tâm để hiểu cách các ứng dụng web hiện đại hoạt động và cách chúng được xây dựng. Hướng dẫn này sẽ trình bày một số khái niệm cơ bản về HTTP và bạn sẽ hiểu rõ hơn về cách ứng dụng web và web hoạt động.
Hướng dẫn này dành cho ai?
Hướng dẫn này hướng tới những người đã từng sử dụng Internet trong một thời gian, nhưng chưa bao giờ xây dựng các ứng dụng web động trước đây. Và cho những người quan tâm đến làm thế nào mà các ứng dụng web làm việc, làm kiến thức nền tảng để học thêm các khái niệm phát triển ứng dụng web nâng cao.
Làm thế nào để đọc hướng dẫn này?
Hầu hết hướng dẫn này được đọc theo định hướng, chủ yếu là các khái niệm. Tuy nhiên, hãy dành thời gian để thực hành qua các ví dụ. Không có cách nào tốt hơn để thực sự hiểu một chủ đề hơn là làm.
Kiến thức nền tảng
Tổng quan và Lịch sử tóm tắt
Khi bạn nhập URL vào thanh địa chỉ của trình duyệt web, bạn sẽ thấy trang web được hiển thị trong trình duyệt của mình. Khi bạn nhấp vào liên kết hoặc gửi biểu mẫu, trình duyệt của bạn có thể hiển thị trang tiếp theo hoặc hiển thị lỗi trong biểu mẫu của bạn để bạn có thể sửa chúng và gửi lại. Trình duyệt của bạn là interface hoặc window, thông qua đó bạn tương tác với web trên toàn thế giới.
Dưới trình duyệt của bạn là một tập hợp các tập tin HTML, CSS, Javascript, videos, images, vv - mà làm cho các trang web hiển thị. Tất cả các tệp này được gửi từ server (máy chủ) đến trình duyệt của bạn, client (máy khách), bằng giao thức ứng dụng có tên HTTP (đây là lý do tại sao URL trong thanh địa chỉ trình duyệt của bạn bắt đầu bằng http://).
HTTP, hoặc Hypertext Transfer Protocol, được phát minh bởi Tim Berners-Lee năm 1980. Nó là một hệ thống các quy tắc, một giao thức, phục vụ như một liên kết giữa các ứng dụng và việc chuyển các tài liệu hypertext (siêu văn bản). Nói khác đi, đó là một thông điệp, về các máy giao tiếp với nhau. HTTP là một mô hình đơn giản, nơi một máy khách thực hiện một request (yêu cầu) tới một máy chủ và chờ response (phản hồi).
Giao thức HTTP đã trải qua một số thay đổi từ khi được phát minh. Giao thức bắt đầu ở dạng đơn giản nhất của nó chỉ trả về các trang HTML. Năm 1991, phiên bản tài liệu đầu tiên HTTP/0.9 được phát hành. Vào năm 1992, HTTP/1.0 được phát hành với khả năng truyền các loại tệp khác nhau như tài liệu CSS, video, tập lệnh và hình ảnh. Năm 1995 phiên bản HTTP/1.1 được phát hành, giới thiệu khả năng tái sử dụng các kết nối được thiết lập cho các yêu cầu tiếp theo. Các cải tiến khác được hiện cho HTTP/1.1 vào năm 1999 đã dẫn đến những gì chúng ta thấy ngày nay. Tại thời điểm của bài hướng dẫn này, HTTP/2 đang trong giai đoạn phát triển.
Các hoạt động của Internet
Internet bao gồm hàng triệu mạng được kết nối với nhau, cho phép tất cả các loại máy tính và thiết bị giao tiếp với nhau. Theo quy ước, tất cả các thiết bị tham gia vào mạng đều được cung cấp các nhãn duy nhất. Thuật ngữ chung cho loại nhãn này là Internet Protocol Address hoặc IP Address. Địa chỉ IP có port numbers (số cổng) bổ sung thêm chi tiết về cách giao tiếp. Địa chỉ IP được biểu diễn dưới dạng:
192.168.0.1
Khi cần số cổng, địa chỉ được chỉ định là:
192.168.0.1:3000
trong đó 192.168.0.1 là địa chỉ IP và 3000 là số cổng. Địa chỉ IP đóng vai trò là số nhận dạng cho thiết bị hoặc máy chủ và có thể chứa hàng trăm hoặc hàng nghìn cổng, mỗi cổng được sử dụng cho mục đích giao tiếp khác nhau cho thiết bị hoặc máy chủ đó.
Khi nói đến Internet rộng hơn, giao tiếp hiệu quả bắt đầu khi mỗi thiết bị có địa chỉ IP công cộng được cung cấp bởi Nhà cung cấp dịch vụ Internet. Nhưng còn một địa chỉ như http://www.google.com thì sao? Làm cách nào để máy tính của bạn biết địa chỉ IP được ánh xạ tới? Khi chúng ta muốn kết nối với trang chính của Google, chúng ta không gõ vào địa chỉ IP, chúng ta gõ vào URL của nó.
Ánh xạ từ URL đến địa chỉ IP được xử lý bởi Domain Naming System (Hệ thống tên miền) hoặc DNS. DNS là một cơ sở dữ liệu phân tán dịch các tên miền như http://www.google.com sang địa chỉ IP và ánh xạ yêu cầu tới một máy chủ từ xa. Vì vậy, một địa chỉ như http://www.google.com có thể được phân giải thành địa chỉ IP 197.251.230.45. Nhân tiện, bạn cũng có thể truy cập trang chính của Google bằng cách nhập địa chỉ IP vào thanh địa chỉ của trình duyệt.
Tuy nhiên, hầu hết mọi người muốn sử dụng một địa chỉ thân thiện với người dùng như http://www.google.com, thay vì ghi nhớ một số chữ số. Cơ sở dữ liệu DNS được lưu trữ trên các máy tính được gọi là DNS Servers. Một mạng lưới rộng lớn trên toàn thế giới về các máy chủ DNS được phân cấp theo thứ bậc và không có máy chủ DNS nào chứa toàn bộ cơ sở dữ liệu. Khi một máy chủ DNS không chứa tên miền được yêu cầu, nó sẽ gửi yêu cầu đến một máy chủ DNS khác trên hệ thống phân cấp. Cuối cùng, địa chỉ sẽ được tìm thấy trong cơ sở dữ liệu DNS trên một máy chủ DNS cụ thể và địa chỉ IP tương ứng sẽ được sử dụng để nhận yêu cầu.
Điều chính bạn phải hiểu là khi trình duyệt của bạn đưa ra yêu cầu, nó chỉ đơn giản là gửi một số văn bản đến một địa chỉ IP. Vì máy khách (trình duyệt web) và máy chủ (nơi nhận yêu cầu) sử dụng chung giao thức HTTP, máy chủ có thể tách các yêu cầu, hiểu các thành phần của nó và gửi phản hồi về trình duyệt web. Trình duyệt web sau đó sẽ xử lý các chuỗi phản hồi thành nội dung mà bạn có thể hiểu được. Điều hướng đến các trang web như Facebook, Twitter, Google có nghĩa là bạn đã sử dụng HTTP, tất cả các yêu cầu thành phần được đóng gói thành một yêu cầu. Các thành phần khác nhau của Internet trông giống như sau
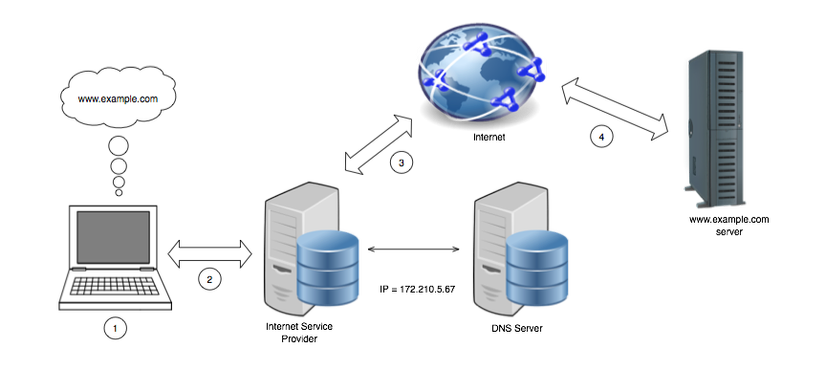
Clients và Servers
Ứng dụng khách phổ biến nhất là Web Browser mà bạn sử dụng hàng ngày như Internet Explorer, Firefox, Safari và Chrome, bao gồm cả các phiên bản dành cho thiết bị di động. Trình duyệt web làm nhiệm vụ phát đi các yêu cầu HTTP và xử lý phản hồi HTTP theo cách thân thiện với người dùng trên màn hình của bạn. Trình duyệt web không phải là các Client duy nhất, vì có nhiều công cụ và ứng dụng cũng có thể phát đi các yêu cầu HTTP.
Nội dung bạn đang yêu cầu nằm trên máy tính từ xa được gọi là máy chủ. Công việc của máy chủ là xử lý các yêu cầu gửi đến và đưa ra các phản hồi. Thông thường, các phản hồi chứa dữ liệu có liên quan như được chỉ định trong yêu cầu.

Resources
Resources (tài nguyên) là một thuật ngữ chung cho những thứ bạn tương tác trên Internet thông qua một URL. Bao gồm hình ảnh, video, trang web và các tệp khác. Tài nguyên không bị giới hạn đối với tệp và trang web. Tài nguyên cũng có thể ở dạng phần mềm cho phép bạn giao dịch cổ phiếu hoặc trò chơi điện tử. Không có giới hạn về số lượng tài nguyên có sẵn trên Internet.

Statelessness
Một giao thức được cho là stateless (không trạng thái) khi nó được thiết kế theo cách mà mỗi cặp request/response hoàn toàn độc lập với trước đó. Trong bối cảnh của HTTP, nó có nghĩa là máy chủ không lưu thông tin hoặc trạng thái, giữa các yêu cầu. Kết quả là, khi một yêu cầu phá vỡ trên đường đến máy chủ, không có phần nào của hệ thống phải làm bất kỳ việc dọn dẹp nào. Cả hai lý do này làm cho HTTP trở thành một giao thức đàn hồi, cũng như một giao thức khó khăn để xây dựng các ứng dụng kiểu stateful (server lưu dữ liệu của client sau mỗi lần request). Điều này khiến các nhà phát triển web phải làm việc chăm chỉ để mô phỏng trải nghiệm stateful trong các ứng dụng web.
Ví dụ, khi bạn truy cập Facebook, và đăng nhập, bạn sẽ thấy trang Facebook của mình. Đó là một chu trình request/response hoàn chỉnh. Sau đó, bạn nhấp vào hình ảnh - một chu trình request/response khác - nhưng bạn không muốn đăng xuất sau hành động đó. Làm thế nào để ứng dụng duy trì trạng thái đăng nhập của bạn? Làm thế nào để Facebook biết request này đến từ bạn và làm cách nào để phân biệt dữ liệu của bạn so với người dùng nào khác? Có những kỹ thuật mà các nhà phát triển web sử dụng để làm cho nó có vẻ như ứng dụng là stateful, nhưng những thủ thuật đó nằm ngoài phạm vi của hướng dẫn này. Ý tưởng quan trọng cần nhớ là mặc dù bạn có thể cảm thấy ứng dụng là stateful, bên dưới nó, web được xây dựng dựa trên HTTP, một giao thức không trạng thái. Đó là những gì làm cho web trở nên đàn hồi và phân tán và khó kiểm soát, cũng như làm cho nó trở nên khó khăn để bảo mật.
URL là gì?
Giới thiệu
Khi bạn cần tìm nhà của ai đó, bạn cần địa chỉ nhà của họ. Nếu bạn muốn gọi cho bạn của mình, bạn cần số điện thoại của bạn mình. Nếu không có những thông tin đó, việc tìm kiếm ngôi nhà hoặc gọi điện cho bạn bè của bạn là không thể. Hơn nữa, nếu bạn được cung cấp một địa chỉ hoặc số điện thoại, bạn có thể ngay lập tức nói với một người khác, do tính đồng nhất về cách địa chỉ trông giống như một số điện thoại.
Có một khái niệm tương tự cho việc tìm kiếm và truy cập các máy chủ trên Internet. Khi bạn muốn đi đến trang trò chơi của Facebook, bạn bắt đầu bằng cách chạy trình duyệt web và điều hướng đến http://www.facebook.com/games. Trình duyệt web thực hiện yêu cầu HTTP đến địa chỉ này dẫn đến tài nguyên được trả lại cho trình duyệt của bạn. Địa chỉ bạn đã nhập, https://www.facebook.com/games được gọi là Uniform Resource Locator (Trình định vị tài nguyên thống nhất) hoặc URL. URL giống như địa chỉ hoặc số điện thoại bạn cần để truy cập hoặc liên lạc với bạn bè của bạn. URL là phần được sử dụng thường xuyên nhất của khái niệm chung về Uniform Resource Identifier (Mã định danh tài nguyên thống nhất) hoặc URI, xác định cách thức đặt tài nguyên. Phần này xem xét URL là gì, các thành phần của nó và ý nghĩa của nó đối với bạn với tư cách là nhà phát triển web.
Các thành phần URL
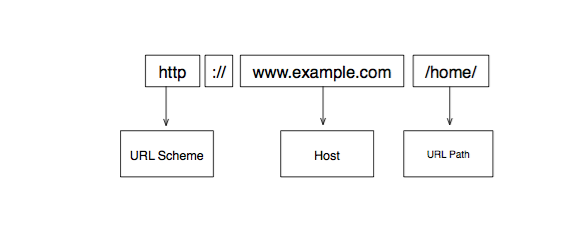
Khi bạn thấy URL, chẳng hạn như http://www.example.com:88/home?item=book, URL này bao gồm một số thành phần. Có thể chia URL này thành 5 phần:
- http: scheme - Nó luôn xuất hiện trước dấu hai chấm và hai dấu gạch chéo và báo cho ứng dụng web cách truy cập tài nguyên. Trong trường hợp này, nó yêu cầu máy khách web sử dụng Giao thức Hypertext Transfer Protocol (Truyền siêu văn bản) hoặc HTTP để thực hiện một yêu cầu. Các lược đồ URL phổ biến khác là ftp, mailto hoặc git.
- www.example.com: host - cho client biết nơi tài nguyên được lưu trữ hoặc định vị.
- :88: port - chỉ được yêu cầu nếu bạn muốn sử dụng một cổng khác với cổng mặc định.
- /home/: path - cho thấy tài nguyên đang được yêu cầu. Phần này của URL là tùy chọn.
- ?item=book: query string - được tạo thành từ các query parameters. Nó được sử dụng để gửi dữ liệu đến máy chủ. Phần này của URL cũng là tùy chọn.
Đôi khi, đường dẫn có thể trỏ đến một tài nguyên cụ thể trên máy chủ lưu trữ. Ví dụ: www.example.com/home/index.html trỏ đến tệp HTML nằm trên máy chủ example.com.
Đôi khi, có thể bao gồm số cổng mà máy chủ sử dụng để nghe các yêu cầu HTTP. URL dưới dạng: http://localhost:3000/profile đang sử dụng số cổng 3000 để nghe các yêu cầu HTTP. Số cổng mặc định cho HTTP là cổng 80. Mặc dù số cổng này không phải lúc nào cũng được chỉ định, nhưng nó được giả định là một phần của mỗi URL. Trừ khi một cổng khác được chỉ định, cổng 80 sẽ được sử dụng theo mặc định trong các yêu cầu HTTP bình thường.
Query Strings/Parameters
Một URL đơn giản với chuỗi truy vấn có thể trông giống như sau:
http://www.example.com?search=ruby&results=10
| Thành phần chuỗi truy vấn | Miêu tả |
|---|---|
| ? | Đây là ký tự dành riêng đánh dấu sự bắt đầu chuỗi truy vấn |
| search = ruby | Đây là cặp name/value parameter. |
| & | Đây là ký tự dành riêng, được sử dụng khi thêm nhiều tham số vào chuỗi truy vấn. |
| results=10 | Đây cũng là cặp name/value parameter. |
Bây giờ chúng ta hãy xem một ví dụ. Giả sử có URL sau:
http://www.phoneshop.com?product=iphone&size=32gb&color=white
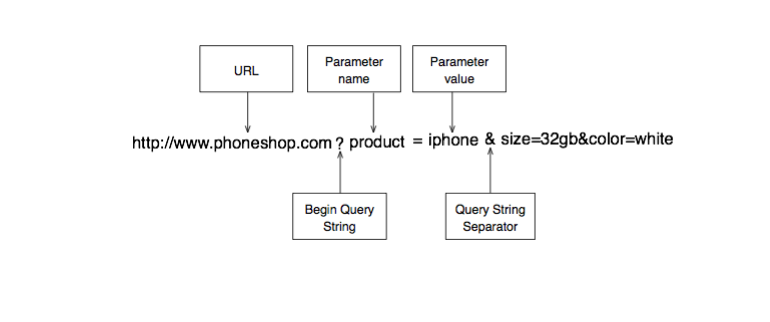 Trong ví dụ trên, các cặp name/value theo hình thức product=iphone, size=32gb và color=white được truyền đến máy chủ từ URL. Điều này yêu cầu www.phoneshop.com máy chủ thu hẹp trên một sản phẩm iphone, kích thước 32gb và màu sắc white. Cách máy chủ sử dụng các tham số này là tùy thuộc vào ứng dụng phía máy chủ.
Trong ví dụ trên, các cặp name/value theo hình thức product=iphone, size=32gb và color=white được truyền đến máy chủ từ URL. Điều này yêu cầu www.phoneshop.com máy chủ thu hẹp trên một sản phẩm iphone, kích thước 32gb và màu sắc white. Cách máy chủ sử dụng các tham số này là tùy thuộc vào ứng dụng phía máy chủ.
Một nơi phổ biến khác mà bạn có thể đã thấy các tham số truy vấn đang hoạt động là khi bạn thực hiện tìm kiếm trong bất kỳ công cụ tìm kiếm hiện đại nào. Vì chuỗi truy vấn được chuyển qua URL, chúng chỉ được sử dụng trong các yêu cầu HTTP GET. Chúng ta sẽ nói về các yêu cầu HTTP khác nhau sau này trong hướng dẫn, bây giờ chỉ biết rằng bất cứ khi nào bạn nhập vào một URL vào thanh địa chỉ của trình duyệt, bạn đang phát các yêu cầu HTTP GET. Hầu hết các liên kết cũng là các yêu cầu HTTP GET, mặc dù có một số ngoại lệ nhỏ.
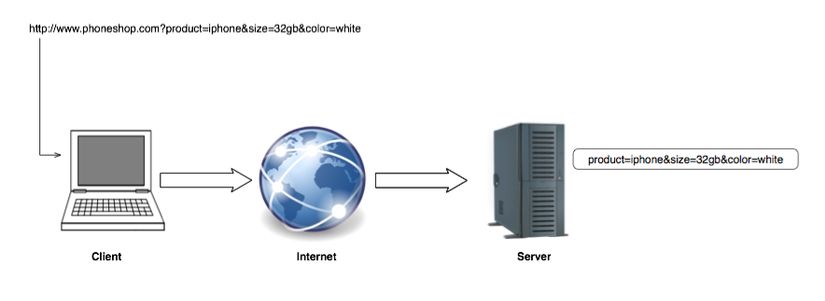
Các query strings là một cách tuyệt vời để truyền thông tin yêu cầu tới máy chủ, tuy nhiên, có một số giới hạn đối với việc sử dụng các chuỗi truy vấn:
- Query strings có độ dài tối đa. Do đó, nếu bạn có nhiều dữ liệu để truyền, bạn sẽ không thể làm như vậy với các query strings.
- Cặp name/value được sử dụng trong query strings được hiển thị trong URL. Vì vậy, không nên sử dụng các thông tin nhạy cảm như tên người dùng hoặc mật khẩu cho máy chủ theo cách này.
- Space và các ký tự đặc biệt như & không thể được sử dụng với chuỗi truy vấn. Chúng phải được mã hóa URL, chúng ta sẽ nói ở phần tiếp theo.
URL Encoding
Mặc định, URL được thiết kế để chỉ chấp nhận các ký tự nhất định trong bộ ký tự ASCII. Do đó, các ký tự không an toàn hoặc reserved không được bao gồm trong bộ này, chúng phải được chuyển đổi hoặc mã hóa để phù hợp với định dạng này. Mã hóa URL phục vụ mục đích thay thế các ký tự không phù hợp này bằng một % ký hiệu theo sau là hai chữ số thập lục phân đại diện cho mã ASCII của ký tự.
Dưới đây là một số ký tự được mã hóa phổ biến và URL mẫu:
| Ký tự | Mã ASCII | URL ví dụ |
|---|---|---|
| Space | 20 | http://www.thedesignshop.com/shops/tommy hilfiger.html |
| ! | 21 | http://www.thedesignshop.com/moredesigns!.html |
| + | 2B | http://www.thedesignshop.com/shops/spencer%2B.html |
| # | 23 | http://www.thedesignshop.com/%23somequotes%23.html |
Các ký tự phải được mã hóa nếu:
- Chúng không có ký tự tương ứng trong bộ ký tự ASCII.
- Việc sử dụng ký tự không an toàn. Ví dụ % là không an toàn vì nó được sử dụng để mã hóa các ký tự khác.
- Ký tự được dành riêng cho việc sử dụng đặc biệt trong lược đồ URL. Một số ký tự được dành riêng cho một ý nghĩa đặc biệt; sự hiện diện của chúng trong một URL phục vụ một mục đích cụ thể. Như /, ?, :, @ và & tất cả đều phải được mã hóa.
Ví dụ: & được dành riêng để sử dụng làm dấu phân tách chuỗi truy vấn. : cũng được dành riêng để phân định các thành phần host/port và user/password.
Chuẩn bị
Với những kiến thức cơ bản về HTTP, chúng ta hãy làm quen với các công cụ mà chúng ta sẽ sử dụng trong hướng dẫn này để tìm hiểu cách thức hoạt động của HTTP. Bạn có thể sử dụng bất kể công cụ nào mà bạn cảm thấy thoải mái và bắt đầu!
Các công cụ HTTP giao diện đồ họa
Có rất nhiều công cụ giúp bạn thao tác với HTTP như Paw 3, Insomnia, Postman; đã số chúng đều miễn phí và hoạt động trên OS X, Windows và Ubuntu. Hướng dẫn này sử dụng Postman vì nó được sử dụng bởi hầu hết các nhà phát triển web.
Các công cụ HTTP giao diện dòng lệnh
curl là một công cụ dòng lệnh miễn phí được sử dụng để phát đi các yêu cầu HTTP.
Nó hoạt động trên OS X và hầu hết các bản phân phối GNU/Linux. Bạn có thể đơn giản gọi nó trên dòng lệnh như sau:
$ curl www.usa.gov
Kết thúc (Phần 1)
Phần tiếp theo sẽ giới thiệu về :
- Making Request
- Processing Responses
- Stateful Web Application
- Security
Cảm ơn bạn đã theo dõi bài viết. Hẹn gặp lại bạn ở Phần 2 của bài hướng dẫn!
