Giới thiệu về NoSQL database
Khi làm việc với database, chúng ta đã quá quen với SQLServer, MySQL, PostgreSQL, Oracle ... Điểm chung của những database này là sử dụng ngôn ngữ SQL để truy vấn dữ liệu. Nhưng có 1 dạng database khác với những đặc tính khác biệt được gọi chung dưới cái tên là NoSQL. Giờ chúng ta hãy cùng tìm hiểu ...
Khi làm việc với database, chúng ta đã quá quen với SQLServer, MySQL, PostgreSQL, Oracle ... Điểm chung của những database này là sử dụng ngôn ngữ SQL để truy vấn dữ liệu. Nhưng có 1 dạng database khác với những đặc tính khác biệt được gọi chung dưới cái tên là NoSQL. Giờ chúng ta hãy cùng tìm hiểu xem nó là cái gì, và tại sao nó lại rất phát triển và được nhiều người quan tâm đến vậy.
- NoSQL database là gì ?
- Thuật ngữ NoSQL được giới thiệu lần đầu vào năm 1998 sử dụng làm tên gọi chung cho các lightweight open source relational database (cơ sở dữ liệu quan hệ nguồn mở nhỏ) nhưng không sử dụng SQL cho truy vấn. Vào năm 2009, Eric Evans, nhân viên của Rackspace giới thiệu lại thuật ngữ NoSQL trong một hội thảo về cơ sở dữ liệu nguồn mở phân tán. Thuật ngữ NoSQL đánh dấu bước phát triển của thế hệ database mới: distributed (phân tán) + non-relational (không ràng buộc). Đây là 2 đặc tính quan trọng nhất.
- Tại sao lại cần phải có NoSQL.
- Sở dĩ người ta phát triển NoSQL suất phát từ yêu cầu cần những database có khả năng lưu trữ dữ liệu với lượng cực lớn, truy vấn dữ liệu với tốc độ cao mà không đòi hỏi quá nhiều về năng lực phần cứng cũng như tài nguyên hệ thống và tăng khả năng chịu lỗi.
- Đây là những vấn đề mà các relational database không thể giải quyết được.
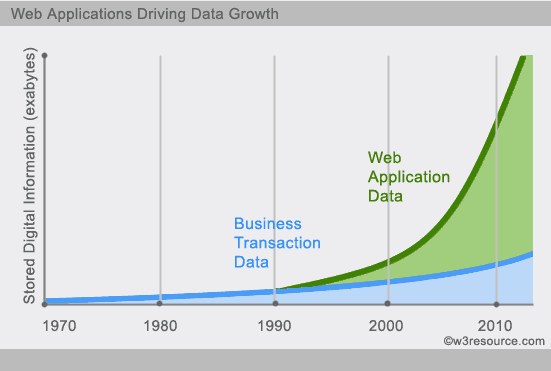
- Lượng dữ liệu mà các hệ thống cần phải xử lý giờ đây ngày 1 lớn. Ví dụ như Google, Facebook phải lưu trữ và xử lý một lượng dữ liệu cực lớn mỗi ngày .
- -
- Một số đặc điểm chung.
- High Scalability: Gần như không có một giới hạn cho dữ liệu và người dùng trên hệ thống.
- High Availability: Do chấp nhận sự trùng lặp trong lưu trữ nên nếu một node (commodity machine) nào đó bị chết cũng không ảnh hưởng tới toàn bộ hệ thống.
- Atomicity: Độc lập data state trong các operation.
- Consistency: chấp nhận tính nhất quán yếu, có thể không thấy ngay được sự thay đổi mặc dù đã cập nhật dữ liệu.
- Durability: dữ liệu có thể tồn tại trong bộ nhớ máy tính nhưng đồng thời cũng được lưu trữ lại đĩa cứng.
- Deployment Flexibility: việc bổ sung thêm/loại bỏ các node, hệ thống sẽ tự động nhận biết để lưu trữ mà không cần phải can thiệp bằng tay. Hệ thống cũng không đòi hỏi cấu hình phần cứng mạnh, đồng nhất.
- Modeling flexibility: Key-Value pairs, Hierarchical data (dữ liệu cấu trúc), Graphs.
- Query Flexibility: Multi-Gets, Range queries (load một tập giá trị dựa vào một dãy các khóa).
- Phân loại NoSQL database. Có bốn loại chung (loại phổ biến nhất) của cơ sở dữ liệu NoSQL. Mỗi loại đều có các thuộc tính và giới hạn riêng. Không có một giải pháp duy nhất nào tốt hơn tất cả các giải pháp khác, tuy nhiên có một số cơ sở dữ liệu tốt hơn để giải quyết các vấn đề cụ thể. Để làm rõ cơ sở dữ liệu NoSQL, hãy thảo luận các loại phổ biến nhất:
a. Key-value stores. Lưu trữ kiểu key-value là kiểu lưu trữ dữ liệu NoSQL đơn giản nhất sử dụng từ một API. Chúng ta có thể nhận được giá trị cho khóa, đặt một giá trị cho một khóa, hoặc xóa một khóa từ dữ liệu. Ví dụ, giá trị là ‘blob’ được lưu trữ thì chúng ta không cần quan tâm hoặc biết những gì ở bên trong. Từ các cặp giá trị được lưu trữ luôn luôn sử dụng truy cập thông qua khóa chính và thường có hiệu năng truy cập tốt và có thể dễ dàng thu nhỏ lại. Một vài cơ sở dữ liệu key-value phổ biến là Riak, Redis(thường dùng phía server), memcached, Berkeley DB, HamsterDB, Amazon DynamoDB(mã nguồn đóng), Project Voldemort và Couchbase. Tất cả các cơ sở dữ liệu kiểu key-value đều không giống nhau, có rất nhiều điểm khác nhau giữa các sản phẩm. Ví dụ, dữ liệu của memcached không được nhất quán trong khi ngược lại với Riak. Đấy là những điểm nổi bật quan trọng khi chọn giải pháp phù hợp để sử dụng. Cụ thể hơn là khi chúng ta cần cài đặt caching cho nội dung yêu thích của người dùng, cài đặt sử dụng memcached có nghĩa là khi các nút hỏng hết dẫn tới dữ liệu bị mất và cần phải làm mới lại từ hệ thống nguồn. Tuy nhiên, nếu chúng ta lưu trữ cùng dữ liệu đó trong Riak, chúng ta không cần lo lắng về việc mất dữ liệu nhưng cần phải xem xét việc cập nhật trạng thái của dữ liệu như thế nào. Điều này là quan trọng không chỉ cho chọn cơ sở dữ liệu key-value cho hệ thống và còn quan trọng cho việc chọn cơ sở dữ liệu key-value nào.
b. Column-oriented databases (column-family). Cơ sở dữ liệu column-family lưu trữ dữ liệu trong nhiều cột trong mỗi dòng với key cho từng dòng. Column families là một nhóm các dữ liệu liên quan được truy cập cùng với nhau. Ví dụ, với khách hàng, chúng ta thường xuyên sử dụng thông tin cá nhân trong cùng một lúc chứ không phải hóa đơn của họ. Cassandra là một trong số cơ sở dữ liệu column-family phổ biến. Ngoài ra còn có một số cơ sở dữ liệu khác như HBase, Hypertable và Amazon DynamoDB. Cassandra có thể được miêu tả nhanh và khả năng mở rộng dễ dàng với các thao tác viết thông qua các cụm. Các cụm không có node master, vì thế bất kỳ việc đọc và ghi nào đểu có thể được xử lý bởi bất kỳ node nào trong cụm.
c. Graph databases Kiểu đồ thị này cho phép bạn lưu trữ các thực thể và quan hệ giữa các thực thể. Các đối tượng này còn được gọi là các nút, trong đó có các thuộc tính. Mỗi nút là một thể hiện của một đối tượng trong ứng dụng. Quan hệ được gọi là các cạnh, có thể có các thuộc tính. Cạnh có ý nghĩa định hướng; các nút được tổ chức bởi các mối quan hệ. Các tổ chức của đồ thị cho phép các dữ liệu được lưu trữ một lần và được giải thích theo nhiều cách khác nhau dựa trên các mối quan hệ. Thông thường, khi chúng ta lưu trữ một cấu trúc đồ thị giống như trong RDBMS, nó là một loại duy nhất của mối quan hệ. Việc tăng thêm một mối quan hệ có nghĩa là rất nhiều thay đổi sơ đồ và di chuyển dữ liệu, mà không phải là trường hợp khó khi chúng ta đang sử dụng cơ sở dữ liệu đồ thị. Trong cơ sở dữ liệu đồ thị, băng qua các thành phần tham gia hoặc các mối quan hệ là rất nhanh. Các mối quan hệ giữa các node không được tính vào thời gian truy vấn nhưng thực sự tồn tại như là một mối quan hệ. Đi qua các mối quan hệ là nhanh hơn so với tính toán cho mỗi truy vấn. Có rất nhiều cơ sở dữ liệu đồ thị có sẵn, chẳng hạn như Neo4J, Infinite Graph, OrientDB, hoặc FlockDB (đó là một trường hợp đặc biệt: một cơ sở dữ liệu đồ thị mà chỉ hỗ trợ các mối quan hệ duy nhất chuyên sâu hoặc danh sách kề, nơi mà bạn không thể đi qua nhiều hơn một mức độ sâu sắc đối với các mối quan hệ ).
d. Document Oriented databases Tài liệu là nguyên lý chính của cơ sở dữ liệu kiểu dữ liệu. Dữ liệu lưu trữ và lấy ra là các tài liệu với định dạng XML, JSON, BSON,… Tài liệu miêu tả chính nó, kế thừa từ cấu trúc dữ liệu cây. Có thể nói cơ sở dữ liệu tài liệu là 1 phần của key-value. Cơ sở dữ liệu kiểu tài liệu như MongoDB cung cấp ngôn ngữ truy vấn đa dạng và cúc trúc như là cơ sở dữ liệu như đánh index,… Một số cơ sở dữ liệu tài liệu phổ biến mà chúng ta hay gặp là MongoDB, CouchDB, Terastore, OrientDB, RavenDB.
- So sánh giữa RDBMS (Relational database management system) và NoSQL. RDBMS
- Dữ liệu có cấu trúc và tổ chức
- Sử dụng ngôn ngữ SQL để truy vấn dữ liệu
- Dữ liệu và các mối quan hệ của nó được lưu trữ trong các bảng riêng biệt.
- Có tính chặt chẽ
NoSQL
- Không sử dụng SQL
- Không khai báo ngôn ngữ truy vấn dữ liệu
- Không định nghĩa schema
- Có 1 số nhóm dạng: Key-Value pair storage, Column Store, Document Store, Graph databases
- Dữ liệu phi cấu trúc và không thể đoán trước
- Ưu tiên cho hiệu năng cao, tính sẵn sàng cao và khả năng mở rộng
- Thống kê tỉ lệ sử dụng của NoSQL.
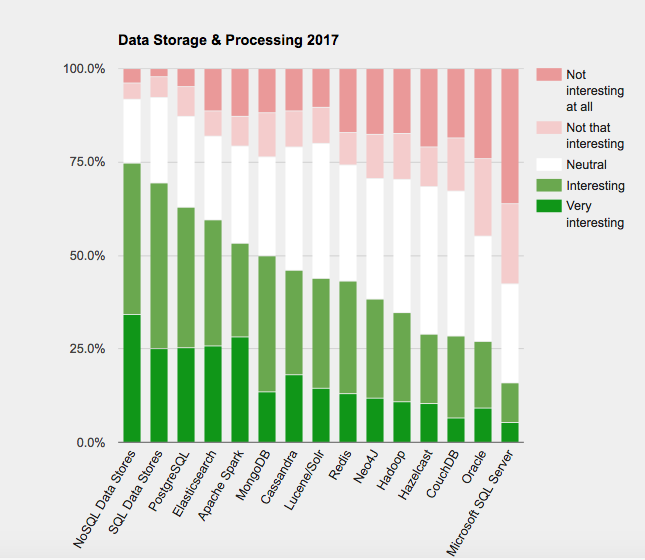 Trích nguồn: https://jaxenter.com/top-databases-2017-132912.html
Trích nguồn: https://jaxenter.com/top-databases-2017-132912.html
