Hệ thống analytic “sương sương” từ dữ liệu 30 triệu người dùng
Số là hôm qua mình mới đi nghe buổi hội thảo về AI và data của Tiki, tình cờ gặp lại đứa bạn cũng đang làm những thứ trước đây mình làm thế là ngứa nghề ngồi chém gió 1 lúc. Chém xong mới nhận ra thật ra hồi xưa mình lông bông xây dựng được hệ thống analytic cũng tốn nhiều công phu ...

Số là hôm qua mình mới đi nghe buổi hội thảo về AI và data của Tiki, tình cờ gặp lại đứa bạn cũng đang làm những thứ trước đây mình làm thế là ngứa nghề ngồi chém gió 1 lúc. Chém xong mới nhận ra thật ra hồi xưa mình lông bông xây dựng được hệ thống analytic cũng tốn nhiều công phu phết chứ đâu phải đùa. Vậy nên về mình mới quyết định viết 1 bài để lưu giữ và chia sẻ 1 chút những kinh nghiệm của mình về lĩnh vực khá khoai môn này.
First things first
Who am I, and who are you?
Người viết bài này chỉ là 1 thanh niên chân ướt chân ráo tham gia vào ngành khoa học dữ liệu, có 1 bằng cử nhân kinh tế loại xuất sắc nhưng lại không được đào tạo qua trường lớp về công nghệ thông tin 1 cách bài bản, do vậy rất nhiều cách tiếp cận có vẻ hơi ngây ngô và không quy chuẩn.
Đây không phải là một chia sẻ về thành công hoành tráng như chia sẻ của các ông lớn trong ngành công nghệ về những dữ liệu siêu lớn lên tới hàng tỉ bản ghi, hay là áp dụng những công nghệ rất bá đạo như hadoop, kafka,… mà chỉ là những chia sẻ gần hơn với giai đoạn khởi đầu. Các bạn biết rồi đó, người ta thường ít chia sẻ về giai đoạn này mà thường chỉ nói về thành công khi mọi thứ đã to đùng. Làm chúng ta, tất cả những người mới bắt đầu chỉ biết ngước lên mà ao ước.
Vậy thì bạn – người đọc đóng vai trò là 1 kẻ ngoại đạo bắt đầu hình dung về hệ thống analytic như thế nào?
Bài viết hơi dài mong các bạn kiên nhẫn
Lần thất bại đầu tiên
Yêu cầu ban đầu của đội ngũ quản trị rất đơn giản: “Xây dựng 1 hệ thống tính toán doanh thu cho các sản phẩm mà công ty đang phát hành”.
Rất đơn giản phải không? Chỉ là access vô hệ thống thanh toán, lấy log giao dịch của khách hàng rồi làm 1 vài phép toán sum, count đơn giản trên DB ra kết quả như yêu cầu. Xong.
Dù vậy nhưng với mình – 1 thanh niên vừa mới rời khỏi trường kinh tế và học PHP được 1 tháng thì nó cũng cực kỳ challenge. Bắt đầu làm quen với curl, batch processing, background job, webhook,… đủ kiểu, dựng lên 1 con MySQL chứa bảng giao dịch của khách hàng rồi đủ các thông tin liên quan tới giao dịch đấy như nạp cho ai, vào đâu, bao tiền, thời gian nào,… Dashboard sẽ là 1 cái biểu đồ doanh thu theo ngày, tuần, tháng,… thì đơn giản.
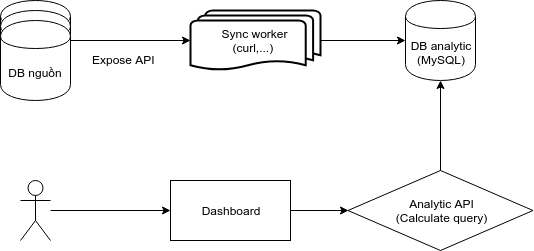
Nhưng hệ thống trên chỉ chạy được trong 4 tháng và mình buộc phải thiết kế 1 hệ thống tiếp theo để đáp ứng bài toán mới đặt ra. Tại sao vậy?
MySQL không phải là một CSDL phục vụ cho quá trình analytic.. Hãy cùng xem bảng so sánh sau của mình giữa yêu cầu và khả năng của MySQL
| Tính chất | Requirement | Mysql |
|---|---|---|
| Performance | Process nhiều row 1 cách nhanh chóng | Nhanh khi get số lượng bản ghi thấp |
| Complexity | Hỗ trợ các query phức tạp cho OLAP | Hỗ trợ tốt cho OLTP |
| Data type | Hỗ trợ mạnh các data dựa trên binary (cho các thuật toán gần đúng) | Data type cơ bản |
| Operation | Write (insert) rất nhiều / Read ít nhưng nặng | Insert chậm, Read rất nhanh với read cơ bản |
Giải pháp ban đầu của mình dựa trên Mysql hoạt động ổn cho tới lúc số lượng data đạt khoảng 1 vài triệu. Khi đó các query với time-range càng dài, động tới vài chục, vài trăm ngàn row trở nên cực kỳ chậm chạp. Và đó mới chỉ là 1 phần rất nhỏ của dữ liệu, khi mình động tới dữ liệu về activity người dùng (như đăng ký đăng nhập, online,…) lớn hơn dữ liệu thanh toán vài chục tới vài trăm lần thì hoàn toàn NO HOPE.
Lần thất bại thứ 2
Lần này mình tiếp cận với 1 CSDL NoSQL là MongoDB. Con Mongo này đã và đang chứa dữ liệu khá lớn về activity người dùng (cỡ vài trăm triệu bản ghi mỗi collection) trên các hệ thống hoạt động. Do vậy mình quyết định chuyển sang dùng thử, trước mắt làm kho chứa dữ liệu lớn, sau là tiếp cận analytic theo 1 hướng hoàn toàn mới: pre-calculated.
Thiết kế của con Mongo này thì lại theo hướng de-normalized, tức là 1 document của nó chứa gần như đủ mọi thông tin về giao dịch hay activity đó. Điểm mạnh của MongoDB là:
- tốc độ insert cao
- tối ưu cho xử lý batch (bulkwrite)
- không cần schema cố định khi data thay đổi
- map-reduce function dễ dàng (với cú pháp của Javascript)
Chính vì những lý do này mà mình đã chọn Mongo là điểm đỗ tiếp theo cho hệ thống analytic của mình.
Tuy nhiên, Mongo lại bộc lộ 1 điểm yếu cũng siêu to khổng lồ khi làm việc với hệ thống analytic, chính là aggregate và count operation rất rất chậm khi query trên dữ liệu lớn. Collection của bạn có thể có hàng trăm triệu bản ghi và bạn có thể đọc 1 vài bản ghi với tốc độ cao, nhưng để đếm 1 tập con cỡ vài trăm ngàn hay triệu bản ghi từ collection đó sẽ là pain in the ass.
Vì vậy, mình phải tiếp cận việc tính toán theo cách khác. Đó là tính trước (gần như) toàn bộ dữ liệu analytic hiển trị trên dashboard. Kiểu như cứ mỗi ngày sẽ có 1 job chạy ngồi tính toán xem hôm nay có bao nhiêu user, doanh thu bao nhiêu, và lưu vào 1 collection khác những kết quả ấy. Ở đây mình tạm gọi là mẩu dữ liệu.
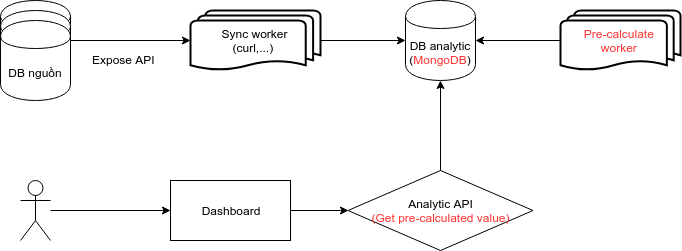
Phần màu đỏ là những thay đổi lớn mà mình tạo ra so với version trước
Cách thiết kế này cũng tồn tại được cỡ 2 tháng, sau đó nó nhanh chóng bộc lộ nhiều khuyết điểm mà hệ thống không thể đáp ứng được:
- Scope của mẩu dữ liệu: Bạn sẽ tính trước giá trị theo phút, giờ, ngày hay tuần? Hay là tất cả? Việc bạn chọn độ lớn hay là cái scope của mẩu dữ liệu sẽ ảnh hưởng tới việc bạn query trên những scope to hơn. Ví dụ bạn chọn tính theo phút, vậy thì giờ sẽ lấy tổng của 60 phút,… cứ thế
- Mẩu dữ liệu được phản ánh bởi nhiều khía cạnh khác nhau và rất khó cho việc tính trước. Ví dụ bạn phải tính trước doanh thu hàng giờ theo từng kênh, từng sản phẩm, từng gói, từng phương thức,…. vân vân và mây mây. Tính trước hết cái đống này sẽ làm bạn điên đầu.
- Nhiều mẩu dữ liệu không có tính chất cộng. Tức là bạn không thể cộng các mẩu dữ liệu với scope nhỏ để tạo thành mẩu dữ liệu scope lớn được. Ví dụ bạn không thể tính DAU bằng cách cộng số lượng user active hàng giờ được. Vì vậy bạn phải tính trước toàn bộ.
- Không hỗ trợ custom query: Việc tính trước sẽ triệt tiêu hầu hết khả năng tạo ra một báo cáo được custom. Nếu 1 ngày bộ phận marketing muốn thống kê 1 con số hơi hơi nhiều khía cạnh thôi là bạn sẽ phải ngồi tính bằng tay. Không thể tính trước cho những trường hợp này được.
Vì vậy, mình tiếp tục phát triển lên bằng việc đập đi làm lại toàn bộ với kiến trúc thứ 3.
Kiến trúc hoàn chỉnh
Lần này mình có tìm hiểu một cách chi tiết và bài bản hơn. Về việc xây dựng các thành phần của hệ thống ra sao hay chức năng của mỗi thành phần như nào. Nhờ có 6 tháng đau thương từ version 1 và 2 mà mình có thể có kha khá kinh nghiệm khi bắt đầu lại này.
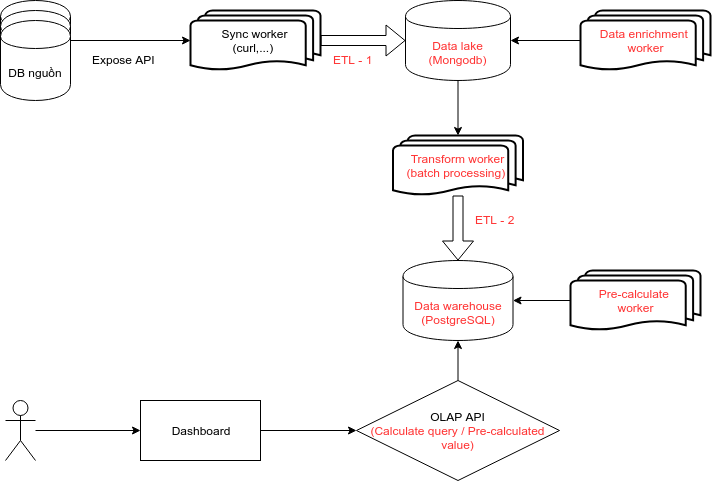
Giải thích về mô hình 1 chút.
- Dữ liệu được sync worker lấy về qua quá trình ETL – 1 sẽ được xử lý về tính đúng đắn, data type, field rác,… Đây là quá trình tiền xử lý tăng tính đúng đắn của dữ liệu phục vụ cho việc lưu trữ tập trung.
- Data lake (MongoDB): là nơi tập trung dữ liệu từ các nguồn khác nhau. Với tính chất format thường xuyên cập nhật, cần insert số lượng lớn với tốc độ cao, dữ liệu không có cấu trúc rõ ràng hoặc cấu trúc phức tạp, lưu trữ số lượng lớn,… thì MongoDB là lựa chọn ổn thỏa và phù hợp nhất với nguồn lực của mình tại thời điểm đó.
- Dữ liệu trong data lake được làm giàu bằng Data enrichment worker. Đây là bước xử lý tiếp theo nhằm tổng hợp lại các mảnh thông tin rời rạc để cho ra những thông tin đa chiều hơn. Ví dụ thông tin về giao dịch sẽ được bổ sung các thông tin về thiết bị, phiên đăng nhập,… từ dữ liệu của các nguồn khác.
- Tiếp theo Transform worker sẽ thực hiện quá trình ETL – 2 để đẩy dữ liệu vào data warehouse. Trong quá trình này, dữ liệu sẽ được xử lý cho phù hợp với kiến trúc của data warehouse, bao gồm việc clean and clear, convert data type, restructure,… Quá trình ETL – 2 này có sự tham gia rất lớn của các stored procedure trong PostgreSQL để phục vụ batch processing và bổ trợ cho kiến trúc Slowly Changing Dimension trong Data warehouse.
- Data warehouse (PostgreSQL): là nơi lưu trữ dữ liệu với nhu cầu được xác định sẵn. Tức là có nhiều dữ liệu sẽ chỉ dừng ở data lake mà thôi. Chỉ những dữ liệu mình đã phát sinh nhu cầu và có kiến trúc được xây dựng mới được đẩy vào data warehouse. PostgreSQL là 1 lựa chọn sáng giá cho database analytic khi mà hỗ trợ rất nhiều query và các kiểu dữ liệu phức tạp. Materialized view, window function hay hyperloglog extension là những feature hỗ trợ cực kỳ đáng giá cho hệ thống analytic của mình.
| Tính chất | Requirement | Postgresql |
|---|---|---|
| Performance | Process nhiều row 1 cách nhanh chóng | Xử lý vài triệu row 1 query là bt |
| Complexity | Hỗ trợ các query phức tạp cho OLAP | Window function, Materialized view, Multiple type index |
| Data type | Hỗ trợ mạnh các data dựa trên binary (cho các thuật toán gần đúng) | Hyperloglog, JSON, JSONB |
| Operation | Write (insert) rất nhiều / Read ít nhưng nặng | Insert nhanh, query phức tạp tối ưu |
- 1 số dữ liệu trong data warehouse sẽ được pre-calculate bằng Pre-calculate worker. Chiến lược này được mình áp dụng đối với 1 số loại kết quả cần tính toán phức tạp như retension, churn,… mà nếu query trực tiếp sẽ rất mất thời gian và làm gánh nặng hệ thống.
- OLAP API bản chất đóng vai trò 1 query-builder để truy vấn dữ liệu từ data warehouse. Phần này mình xây dựng sao cho người dùng trên dashboard có thể tùy biến một cách tối đa (trong các option cho trước) những yêu cầu của mình. Do vậy hệ thống này tới nay đã phục vụ được rất nhiều các nhu cầu từ đơn giản tới phức tạp của các team trong quá trình vận hành sản phẩm.
Một số kinh nghiệm rút ra
Duplicated data: Dữ liệu trong data warehouse được tổ chức thành các data mart, tức là các cụm dữ liệu có kiến trúc được xây dựng cho 1 bài toán cụ thể, ví dụ bài toán tính doanh thu, chăm sóc khách hàng vip,… Như vậy là thay vì bạn có 1 số bảng chứa toàn bộ dữ liệu về 1 vấn đề nào đó, bạn lại có tới cả chục cụm bảng chứa dữ liệu cùng về vấn đề đó nhưng được thiết kế khác nhau. Tư duy này khác với việc bạn xây dựng 1 ứng dụng thông thường là giảm thiểu duplicated data.. Với data-warehouse thì duplicated data là chuyện phải làm để tối ưu hóa performance và đáp ứng mục đích sử dụng.
Normalized or Denormalized là bài toán thường xuyên phải giải với data warehouse, và không có 1 công thức nào áp dụng dc luôn cho vấn đề này. Tất cả phụ thuộc vào thực tế bạn test với performance. Star-schema hay snow-flake hay all-in-one cũng vậy.
Index or no-index là bài toán tiếp theo bạn phải chú ý khi làm việc với data analytic. Bởi vì 1 query của bạn thường xuyên xử lý hàng triệu record. Và có những trường hợp scan-all table còn nhanh hơn index. Những lúc thế này, mình thật sự thích tool explain của PostgreSQL. Nó cực kỳ chi tiết từng step mà Database đã làm để ra kết quả. Bạn có thể tham khảo thêm tool visual explain ở đây
Self-explained ID là chiến thuật xây dựng các bảng fact và dimension dựa trên những ID tự mang ý nghĩa. Nghĩa là thay vì bạn phát minh ra 1 con số vô nghĩa nào đó mà phải join giữa fact và dimension thì bạn sử dụng 1 cái gì đó khác có thể đại diện và tính toán ngay được. Một ví dụ rất cụ thể là ID cho date dimension. Vì rất nhiều operation dựa trên cái ID này sẽ nhanh hơn rất nhiều so với bạn join vào date dimension. Và ngược lại =))). Tất cả là phụ thuộc ở đầu óc tối ưu của bạn. Hãy làm bạn với câu lệnh explain nhiều nhất có thể.
Big job or small job. Đây là chuyện bạn phải đối mặt khi xử lý dữ liệu lớn vào data lake hay data warehouse. Có người chọn việc setup 1 big job làm tất cả chạy nửa tiếng 1 lần, nhưng mình khuyên các bạn nên xé lẻ job của mình ra hết mức có thể để có thể tận dụng lợi thế về xử lý parallel. Xé lẻ ở đây có cả việc bạn chia job cả theo chiều dọc và theo chiều ngang. Chiều dọc là break job 3 bước thành job 1 bước. Chiều ngang là break job xử lý 10000 thành 10 job xử lý 1000. Nhưng nhớ là chỉ chia nhỏ vừa phải để còn tận dụng được batch processing của các DB nhé.
Fast or correct là bài toán về việc bạn đánh đổi giữa sự đúng đắn của kết quả và tốc độ trả về. Hãy cứ tin mình là đôi khi 1 con số chính xác không phải là thứ mà người sử dụng dữ liệu muốn mà là làm cách nào có con số đó thật nhanh. Tập làm quen với các thuật toán về tính toán gần đúng như hyperloglog là bước đệm để bạn có 1 hệ thống fast enough.
Tổng kết
Vậy là mình đã giới thiệu xong cho các bạn về kiến trúc hệ thống analytic mà mình đã xây dựng. Cho tới nay thì hệ thống này đã và đang đáp ứng dữ liệu của hơn 30 triệu người dùng, với nguồn cung dữ liệu từ gần 10 hệ thống hoạt động khác nhau, hàng triệu record data sinh ra 1 ngày và hệ thống dashboard với khoảng 30 loại metric báo cáo phục vụ cho các team vận hành, marketing, kế toán, BOD,… có độ trễ dữ liệu dưới 10 phút và query phần lớn dưới 3s.
Nếu các bạn có câu hỏi gì (mà mình có thể trả lời được) thì cứ mạnh dạn comment nhé. Cám ơn các bạn đã quan tâm theo dõi.
TopDev via Viblo

