How does a relational database work (Part 2)
Bài trước chúng ta đã nói về B tree, và sơ qua về B+ Tree, bài viết này sẽ giới thiệu tiếp về B+ Tree và một số khái niệm về databases khác B+ Tree index Với một B+ Tree có cấu trúc: chỉ node thấp nhất (lowest nodes - hay còn gọi là lá) mới lưu trữ thông tin (vị trí của các hàng trong bảng ...
Bài trước chúng ta đã nói về B tree, và sơ qua về B+ Tree, bài viết này sẽ giới thiệu tiếp về B+ Tree và một số khái niệm về databases khác
B+ Tree index
Với một B+ Tree có cấu trúc:
- chỉ node thấp nhất (lowest nodes - hay còn gọi là lá) mới lưu trữ thông tin (vị trí của các hàng trong bảng liên quan)
- các node khác ở đây chỉ dùng để định tuyến các node bên phải trong quá trình tìm kiếm.
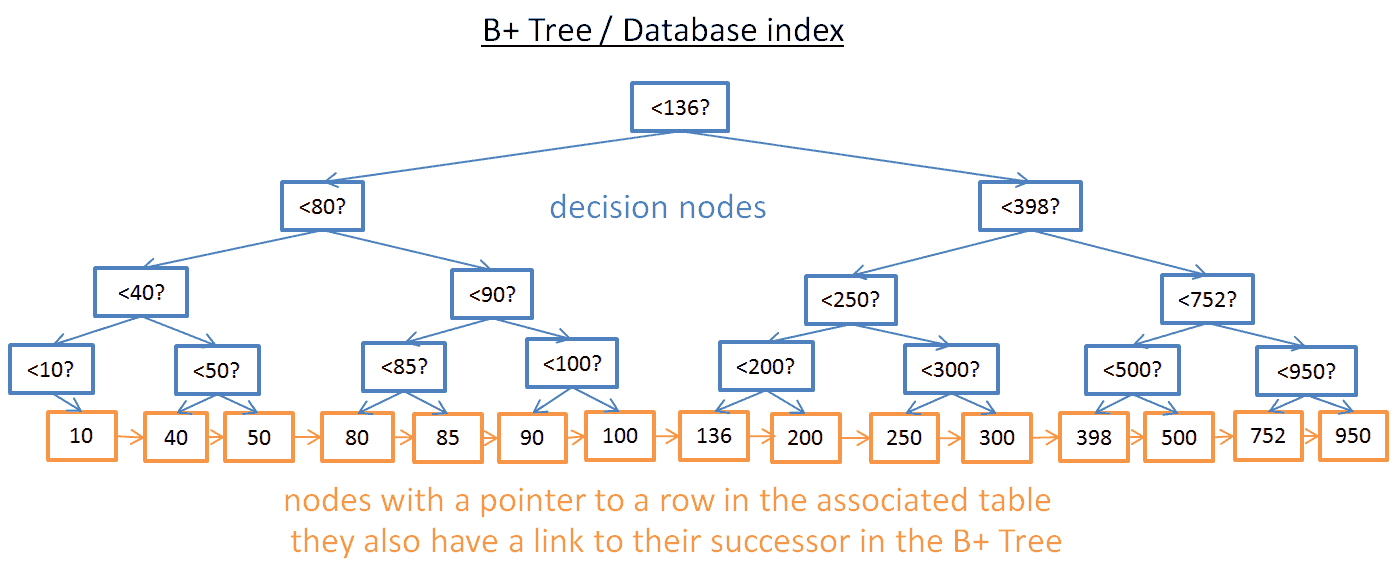
Có một lỗi trên hình kia đối với node 70, và quên không thêm vào lá 136
Như bạn đã thấy, chúng ta có thêm rất nhiều node (gấp đôi). Thật vậy bạn có thêm các nút, gọi là "các nodes quyết định"(decision nodes), nó sẽ giúp bạn tìm thấy các nút bên phải (lưu trữ các hàng trong bảng liên quan). Nhưng mà độ phức tạo của thuật toán vấn là O(log(N)). Sự khác biệt lớn nhất ở đây chính là các nút thấp nhất có liên quan đến cacs nút kế vị (successors).
Với B+ Tree, nếu bạn muốn tìm kiếm giá trị từ 40 đến 100:
- Bạn chỉ cần tìm kiếm giá trị 40 (hoặc là giá trị gần nhất sau 40 nếu 40 không tồn tại)và làm giống với cây trước đó.
Sau đó tập hợp những node kế thừa của 40 bằng cách sử dụng các liên kết trực tiếp đến các node kế thừa cho đến khi đạt đến 100.
Bạn tìm thấy M nút kế thừa (kế nhiệm - successors) và cây có N nodes. Việc tìm kiếm một node cụ thể tốn log(N) như tìm kiếm với cây trước đó. Nhưng một khi bạn có được node đó, bạn lấy ra M node kế nhiệm trong M operations với liên kết đến nút kế vị của những node đó. Tìm kiếm đó chỉ mất M + log(N) operations. Hơn nữa, bạn không cần phải đọc tất cả cây để tìm kiếm (chỉ M + log(N)), nó có nghĩa là sử dụng đĩa ít hơn (less disk usage). Nếu M thấp(khoảng 200 hàng) và N lớn (khoảng 1 000 000 hàng) thì nó sẽ tạo ra một sự khác biệt lớn.
Nhưng chúng ta có một vấn đề mới. Nếu bạn thêm hoặc xóa bỏ một hàng mới trong database (tương tự như với cây liên kết B+ Tree index)
- bạn phải giữ thứ tự các nodes trong B+ tree, nếu không bạn sẽ không thể tìm thấy nodes trong mớ hỗn độn kia.
- bạn phải giữ số lượng levels thấp nhất có thể trong B+ Tree nếu không độ phức tạp từ O(log(N)) sẽ trở thành O(N).
Nghĩ một cách khác, B+ Tree cần phải tự mình sắp xếp, tự cân bằng giữa các node. Rất may điều này có thể thực hiện với các thuật toán xóa, chèn thông minh. Nhưng mà không có việc gì là miễn phí cả, nó sẽ tốn một chút chi phí cho việc này: thêm và xóa trong B+ Tree tốn một chi phí là O(log(N)). Đây là lý do vì sao một số bạn nói rằng việc sử dụng quá nhiều index không phải là một ý tưởng tốt. Thật vậy, bạn đang làm chậm lại nhanh quá trình thêm, xóa, sửa một row trong một table từ cơ sở dữ liệu bạn cần phải cập nhật các chỉ số của bảng với một là O(log(N)) cho mỗi index. Hơn nữa, bổ sung thêm index có nghĩa là khối lượng công việc nhiều hơn cho các nhà quản lý giao dịch (transaction manager - chúng ta sẽ nói đến manager này ở cuối của bài viết).
Để biết thêm chi tiết, bạn có thể xem chi tiết các bài viết về B+ Tree trên Wikipedia. Nếu bạn muốn xem thêm ví dụ về B+ Tree thực thi trên một database , bạn có thể xem bài viết này và bài này từ một core developer của MySQL. Cả 2 đều tập chung vào cách InnoDB(engine của MySQL) xử lý indexes.
Hash table
Cấu trúc dữ liệu quan trọng cuối cùng của chúng ta là bảng băm (hash table). Nó rất hữu ích khi mà chúng ra muốn tìm kiếm nhanh chóng các giá trị. Hơn nữa, hiểu được bảng băm sẽ giúp chúng ta sau này hiểu được cơ bản về việc nối cơ sở dữ liệu và được gọi là hash join. Cấu trúc database này cũng được sử dụng bở một cơ sở dữ liệu để lưu trữ một số công cụ nội bộ (internal stuff - như là bảng khóa(lock table) hoặc là vùng đệm, chúng ta sẽ thấy 2 khái niệm này sau).
Bảng băm là cấu trúc dữ liệu có thể tìm kiếm nhanh một phần tử với key của nó. Để xây dựng một bảng băm ta cần phải xác đinh:
- một chìa khóa(key) cho mỗi thành phần (element)
- một hàm băm cho các khóa. Phương thức tính toán băm keys cho ta địa chỉ của các thành phần(hay còn gọi là buckets)
- Một chức năng so sách các keys. Sau khi tìm kiếm ra đúng bucket chứa thành phần đó, bạn phải tìm kiếm phần tử đó bên trong bucket này sử dụng thật toán so sánh này.
Một ví dụ đơn giản:
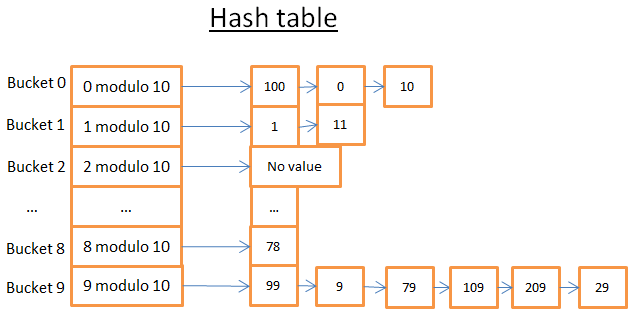
Bảng băm trên có 10 buckets. Hash function (hàm băm) mà tôi sử dụng ở đây modulo 10 của các khóa (keys). Nói cách khác tôi chỉ giữ số cuối cùng của khóa của phần tử (element) để tìm bucket của nó:
- nếu các chữ số cuối cùng là 0 thì phần tử đó sẽ nằm trong bucket 0
- nếu các chữ số cuối cùng là 1 thì phần tử đó sẽ nằm trong bucket 1
- nếu các chữ số cuối cùng là 2 thì phần tử đó sẽ nằm trong bucket 2
- ...
Chức năng so sánh tôi sử dụng ở đây đơn giản là sự so sánh giữa 2 số nguyên.
Ví dụ bạn muốn tìm phần tử 78
Bảng băm tính mã băm (hash code) cho 78 là 8 => Nó sẽ nằm xong bucket số 8, và phần tử đầu tiên tìm thấy trong bucket 8 là 78 => bạn tìm được 78 cho mình.
Tìm kiếm này chỉ tốn của bạn 2 operations (1 cho việc tính toán giá trị băm (hash value) và một cho việc tìm kiếm phần tử trong bucket tính được trên kia).
Bây giờ chúng ta thử tìm kiếm với giá trị tiếp theo là 59:
- bảng băm tính mã băm cho 59 là 9
- tìm kiếm trong bucket số 9 và thấy phần tử đầu tiên là 99 và 99 != 59 => 99 không phải là phần tử mà chúng ta đang tìm kiếm
- sử dụng logic như trên, tìm kiếm đối với phần tử thứ 2 (9), phần tử thứ 3 là (79),...., phần tử cuối cùng là 29
- Phần tử mà chúng ta tìm kiếm không tồn tại
- Tìm kiếm này tốn của chúng ta 7 operations
** Một bảng băm tốt ** Như bạn đã thấy, phụ thuộc vào giá trị mà bạn tìm kiếm, mà chi phí phải bỏ ra là không giống nhau.
Nếu bây giờ tôi thay đổi hàm băm (hash function) thành modulo 1 000 000 của khóa (như chúng ta đang nói về 6 chữ số cuối cùng), thì tìm kiếm lần thứ 2 chỉ tốn 1 operation bởi vì chúng ta không có phần tử nào trong bucket 000059. Yếu tố quyết định có phải là một bảng băm tốt hay không phụ thuộc vào việc bạn có tìm được một hàm băm tốt hay không (a good hash function), nó sẽ tạo ra các buckets chứa được một lượng nhỏ các elements.
Trong ví dụ của tôi, để tìm được một hàm băm tốt là rất dễ. Nhưng đó chỉ là một ví dụ đơn giản thôi, tìm được một hàm băm tốt là rất khó khi khóa là:
- 1 String (như tên của một người)
- 2 String (như là tên và họ của một người)
- 2 String và 1 Date (như là họ, tên, và ngày sinh của một người)
** Với một hàm băm tốt, việc tìm kiếm trong bảng băm sẽ chỉ là O(1)**
** Array với Hash table ** Tại sao lại không sử dụng array?
Bạn đang hỏi một câu hỏi rất hay. Dưới dây là những nguyên nhân giải đáp thắc mắc của bạn:
- một bảng băm có thể lưu được một nửa vào bộ nhớ, phần còn lại có thể lưu trữ ở trên ổ đĩa
- với một array, bạn phải sử dụng một không gian tiếp giáp (a contiguous space) trong bộ nhớ. Nếu bạn tải một table lớn nó là rất khó khăn để có đủ không gian tiếp giáp.
- Với một bảng băm, bạn có thể chọn khóa mà bạn muốn (ví dụ tên nước và tên của một người).
Để biết thêm thông tin chi tiết, bạn có thể đọc bài viết của tôi trên Java HashMap nó là một cách làm sao để thực thi một bảng băm hiệu quả, bạn cũng không cần biết Java để hiểu được định nghĩa trong bài viết đó.
Global overview
Chúng ta đã thấy được những thành phần cơ bản trong một cơ sở dữ liệu. Bây giờ chúng ta cần quay lại để xem tổng thể bức tranh về database như thế nào.
Một database là một bộ sưu tập các thông tin mà chúng ta có thể dễ dàng truy cập và sửa đổi. Nhưng một tập các file đơn giản có thể làm được điều tương tự như vậy? Trên thực tế, xét về database đơn giản nhất như là SQLite không có gì nhiều hơn là các tập tin. Nhưng mà SQLite là một tập các files được gia công tốt (a well-crafted bunch of files) bởi vì nó cho phép bạn:
- sử dụng giao dịch (transactions) để đảm bảo dữ liệu được an toàn và mạch lạc.
- thực thi dữ liệu nhanh chóng ngay cả khi bạn đang đối phó với hàng triệu data
Đơn giản hơn nữa, một database có thể được nhìn thấy theo mô hình dưới đây:
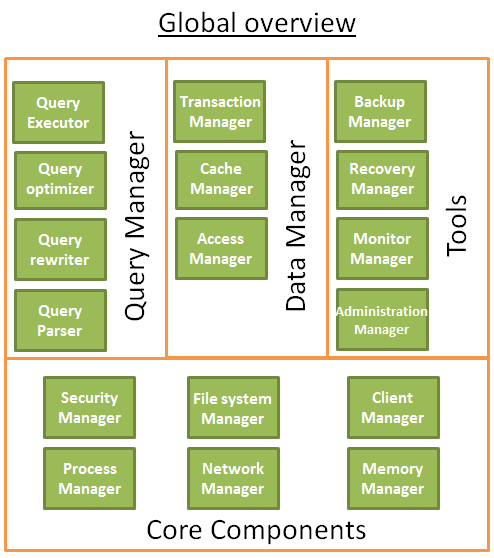 Bài viết sẽ không tập chung nhiều vào cách thức tổ chức cơ sở dữ liệu mà sẽ đi vào các thành phần trong cơ sở dữ liệu, nó tương tác với nhau như thế nào.
Bài viết sẽ không tập chung nhiều vào cách thức tổ chức cơ sở dữ liệu mà sẽ đi vào các thành phần trong cơ sở dữ liệu, nó tương tác với nhau như thế nào.
** Các thành phần cốt lõi: **
- ** The process manager **: Rất nhiều database có một hồ (a pool) của processes/threads cần phải quản lý. Hơn nữa để đạt được đến nano giây, nhiều cơ sở dữ liệu hiện đại sử dụng luồng (thread) riêng của họ thay vì sử dụng của hệ điều hành (Operating System threads)
- ** The network manager **: Mạng I/O là một vấn đề lớn đặc biệt là đối với cơ sở dữ liệu phân tán (distribuited databases). Đó là lý do vì sao một số databases lại có quản lý riêng của họ.
- ** File system manager **: Disk I/O là nút cổ chai (mối thắt nút - bottleneck) đầu tiên của một database. Việc có một người quản lý mà hoàn toàn sẽ xử lý (handle) các tập tin của hệ thống hoặc thậm chí thay thế đó là một điều rất quan trọng.
- ** The memory manager **: Để tránh tình trạng lỗi khi nhập/xuất dữ liệu vào đĩa (disk I/O penalty) cần một lượng lớn Ram. Nhưng nếu bạn giữ (handle) một lượng lớn bộ nhớ, bạn cần một quản lý bộ nhớ thật tốt. Đặc biệt trong trường hợp bạn cần phải thực hiện nhiều queries sử dụng bộ nhớ trong cùng một lúc.
- ** Security manager **: Quản lý việc xác thực và quyền hạn của người sử dụng.
- ** Client manager **: quản lý kết nối các khách hàng
- ...
** Các công cụ hỗ trợ **:
- ** Backup manager **: Lưu trữ và khôi phục dữ liệu
- ** Recovery manager **: Restarting dữ liệu về trạng thái gần nhất sau khi bị crash
- ** Monitor manager **: logging các hoạt động của cơ sở dữ liệu và cung cấp công cụ để giám sát (monitor) một cơ sở dữ liệu
- ** Administration manager **: để lưu trữ dữ liệu (như tên tuổi và cấu trúc của bảng) và cung cấp các công cụ để quản lý database, schemas, table....
- ...
** Quản lý truy vấn **:
- ** Query parser **: kiểm tra nếu một query hợp lệ.
- ** Query rewriter **: tối ưu trước (pre-optimize) một query
- ** Query optimizer **: Tối ưu một query
- ** Query executor **: hoàn thành và thực thi một query
** Quản lý dữ liệu **:
- ** Transaction manager **: xử lý các giao dịch (transaction) từ database
- ** Cache manager **: đẩy data vào bộ nhớ trước khi sử dụng chúng và đẩy data vào bộ nhớ trước khi lưu chúng vào ổ đĩa.
- ** Data access manager **: truy cập dữ liệu trên đĩa
Phần còn lại của bài viết này tôi sẽ tập chung vào việc làm thế nào một database quản lý một query thông qua quy trình sau:
- the client manager
- the query manager
- the database manager(tôi cũng sẽ thêm phần the recovery manager vào trong phần này)
** Client manager **
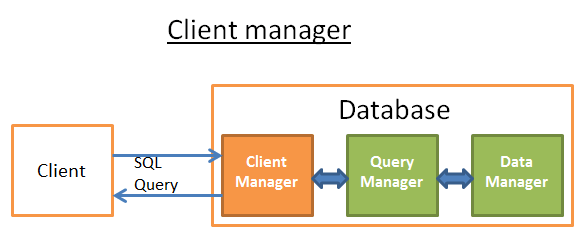
Quản lý khách hàng (the client manager) là phần xử lý các thông tin liên lạc với client. Client có thể là web server hoặc một người dùng cuối hoặc là một application. Quản lý khách hàng cung cấp cho ta những cách khác nhau để truy cập và cơ sở dữ liệu thông qua một tập các APIs nổi tiếng như: JSBC, ODBC, OLE-DB ...
Nó cũng có thể cung cấp các APIs độc quyền dùng truy cập database
Khi bạn kết nối đến database:
- Người quản lý sẽ kiểm tra tính xác thực của bạn (tên đăng nhập và mật khẩu của bạn) sau đó sẽ kiểm tra quyền truy cập của bạn để sử được database. Những quyền truy cập được thiết lập bởi DBA của bạn.
- Sau đó nó sẽ kiểm tra nếu có một process (hoặc thread) sẵn sàng để quản lý truy vấn của bạn.
- Nó cũng kiểm tra nếu database đang không quá tải
- Nó có thể đợi một vài giây để có thể nhận được resources trả về. Nếu sự đợi chờ đạt đến một thời điểm nào đó (hay còn gọi là khoảng thời gian timeout), thì nó sẽ đóng kết nối đó và trả về một thông báo lỗi.
- Sau đó nó gửi query của bạn cho query manager(quản lý truy vấn) và query của bạn sẽ được thực thi.
- Trong khi thực thi query thì không phải là đến khi có kết quả mới trả về hoặc lúc chưa có gì thì chưa trả về (is not an "all or nothing" things), mà ngay khi nó có dữ liệu từ query manager nó sẽ lưu các phần kết quả vào bộ nhớ đệm và bắt đầu gửi trả lại chúng cho bạn.
- Trong trường hợp có lỗi xảy ra, nó sẽ dừng kết nối và đưa cho bạn một lời giải thích và giải phóng tài nguyên.
** Query manager **
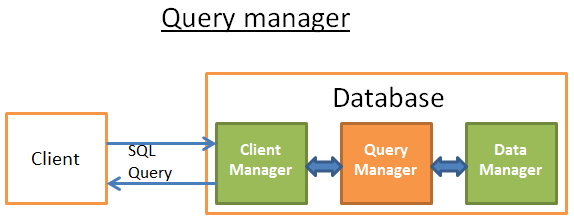
Phần này chính là nới mà năng lượng (power) của một database sống. Trong phần này, một truy vấn ngược bằng văn bản sẽ được chuyển đổi bằng một mã thực thi nhanh. Các mã sau đó được thực thi và kết quả được trả về cho client manager. Nó sẽ trả qua một số bước sau:
- query sẽ được phân tích nếu như nó hợp lệ
- sau đó nó sẽ viết lại và xóa một số operations không cần thiết và thêm một số yếu tố tiền tối ưu hóa (pre-optimizations).
- sau đó nó sẽ tối ưu hóa query để cải thiện hiệu năng và chuyển đổi thực thi và truy cập dữ liệu
- sau đó kế hoạch được biên dịch (compiled)
- cuối cùng nó được thực thi.
Trong phần này sẽ không nói nhiều về 2 điểm cuối cùng vì nó không quan trọng lắm.
** Query parser (phân tích query) ** Mỗi câu lệnh SQL được gửi đến để phân tích, nơi nó sẽ được kiểm tra cú pháp (syntax) xem có đúng không. Nếu bạn gửi đến một query có lỗi, parser sẽ loại bỏ query của bạn. Ví dụ: nếu bạn viết "SELCT..." thay vì "SELECT..." thì câu chuyện sẽ kết thúc tại đây.
Không những kiểm tra cú pháp, mà nó còn kiểm tra các keywords được sử dụng có đúng thứ tự không. Ví dụ, nếu bạn dùng từ khóa WHERE trước từ khóa SELECT câu lệnh của bạn sẽ bị loại bỏ.
Sau đó các bảng và các trường được sử dụng trong query sẽ được phân tích. Bộ phân tích cú pháp (The parser) sử dụng các siêu dữ liệu (metadata) của cơ sở dữ liệu để kiểm tra:
- Xem tables có tồn tại
- Các trường (fields) của tables có tồn tại
- Các operations sử dụng cho các loại dữ liệu trong bảng có phù hợp không (ví dụ: bạn không thể so sánh một số nguyên với một String được, bạn cũng không thể sử dụng một hàm substring() cho một số nguyên)
Sau đó, nó sẽ kiểm tra xem bạn có quyền truy cập để đọc (hay viết) vào table có trong query đó không. Một lần nữa, những quyền truy cập vào các bảng đó được thiết lập bởi DBA của bạn.
Trong suốt quá trình phân tích, câu lệnh SQL được chuyển đổi thành một đại diện nội bộ(internal representation) (thường là một cây)
Nếu mọi thứ đều ok, thì cái đại diện nội bộ đó sẽ được gửi cho query rewriter (viết lại câu lệnh)
** Query Rewriter (viết lại câu lệnh)** Trong bước này, chúng ta có một đại diện nội bộ của một query. Nhiệm vụ của rewriter này sẽ là:
- tiền tối ưu hóa truy vấn
- loại bỏ những hoạt động (operations) không cần thiết trong query
- giúp bộ tối ưu hóa tìm ra được giải pháp tốt nhất có thể
Rewriter sẽ thực thi một danh sách các nguyên tắc trên query của bạn. Nếu query phù hợp với một mẫu nào đó của các nguyên tắc, nguyên tắc đó được chấp nhận và query đó được viết lại. Dưới đây là một danh sách không đầy đủ (optional) của các nguyên tắc:
- ** View merging **: Nếu bạn đang sử dụng một cái nhìn (a view) trong truy vấn của bạn, cái nhìn đó (the view) được biến đổi với các mã SQL của view đó.
- ** Subquery flattening **: Việc có truy vấn con rất khó để tối ưu hóa nó, vì thế rewriter sẽ cố gắng sửa đổi một truy vấn với truy vấn con để loại bỏ truy vấn con đó.
Ví dụ:
SELECT PERSON.* FROM PERSON WHERE PERSON.person_key IN (SELECT MAILS.person_key FROM MAILS WHERE MAILS.mail LIKE 'christophe%'); Will be replaced by SELECT PERSON.* FROM PERSON, MAILS WHERE PERSON.person_key = MAILS.person_key and MAILS.mail LIKE 'christophe%';
- ** Removal of unnecessary operators (xóa bỏ những operators không cần thiết)**: Ví dụ nếu chúng ta sử dụng DISTINCT trong khi bạn có một ràng buộc về UNIQUE có nghĩa là luôn để dữ liêu trong trạng thái là duy nhất, thì từ khóa DISTINCT sẽ được xóa bỏ.
- ** Redundant join elimination (bỏ những join bị dư thừa)**: nếu bạn có 2 điều kiện join(join condition) giống nhau, vì một join condition được giấu ở view, hoặc bởi một quá trình chuyển đổi chúng có một join vô dụng, không cần thiết, => nó sẽ được loại bỏ.
- ** Constant arithmetic evaluation (đánh giá(thẩm định) hằng số số học)**: Nếu bạn viết gì đó mà cần đến sự tính toán, sau đó nó sẽ được tính toán một lần trong thời gian viết lại. Ví dụ WHERE AGE > 10 + 2 sẽ được chuyển đổi thành WHERE AGE > 12 và TODATE("some date") sẽ được chuyển đổi thành ngày tháng với định dạng datetime.
- ** (Advanced) Partition Pruning ((nâng cao) phân vùng tạo hình)**: Nếu bạn đang sử dụng phân vùng bảng, rewriter có thể tìm thấy các phân vùng bạn sử dụng.
- ** (Advanced) Custom rules (chỉnh rules)**: Nếu bạn điều chỉnh một số nguyên tắc để chỉnh sửa lại query (giống như là chính sách Oracle) sau đó rewriter sẽ thực thi những rules đó.
Query được viết lại sau đó sẽ gửi đến query optimizer nơi bắt đầu của nhiều điều thú vị.
Những điều thú vị đó sẽ được giải đáp trong phần tiếp theo.
