Kỹ thuật scraping và crawling Web nâng cao với Scrapy và SQLAlchemy
Trong bài viết trước tôi đã giới thiệu kỹ thuật cơ bản sử dụng Scrapy và SQLAlchemy để scraping và crawling dữ liệu từ trang StackOverflow. Trong bài viết này, tôi sẽ giới thiệu một sỗ kỹ thuật nâng cao sử dụng Scrapy để scraping và crawling Web như follow link, crawl qua các trang dựa vào link ...

Trong bài viết trước tôi đã giới thiệu kỹ thuật cơ bản sử dụng Scrapy và SQLAlchemy để scraping và crawling dữ liệu từ trang StackOverflow. Trong bài viết này, tôi sẽ giới thiệu một sỗ kỹ thuật nâng cao sử dụng Scrapy để scraping và crawling Web như follow link, crawl qua các trang dựa vào link ở cuối trang, gửi request để lấy dữ liệu từ các trang view câu hỏi...
Bài viết này trình bày các kỹ thuật nâng cao với Scrapy nên bạn cần biết cách sử dụng Scrapy về cơ bản. Ngoài ra, nhiều đoạn code được tái sử dụng từ bài viết trước, nên tôi recommend bạn nên đọc qua bài viết đó nếu bạn chưa đọc.
Có nhiều cách để thực hiện việc này, chúng ta có thể mở rộng Spider đang có, gửi thêm 1 request đến trang kế tiếp bằng cách sử dụng link ở cuối trang cũ, sau đó yield một Request tới trang này, sử dụng callback tới chính hàm parse và thực hiện việc lấy dữ liệu với các trang tiếp theo giống hệt như trang ban đầu. Scrapy sẽ tự động gửi request tới link mà chúng ta chỉ định. Bạn có thể nghiên cứu thêm các thông tin khác về việc này ở tài liệu của Scrapy.
Có một cách khác, đơn giản hơn, đó là sử dụng CrawlSpider có sẵn của Scrapy. Đây là một spider phiên bản mở rộng của Spider thông thường, được thiết kế để sử dụng trong trường hợp mà chúng ta đang cần - crawl dữ liệu được phân trang.
Bây giờ, chúng ta cần xây dựng một Spider kế thừa từ CrawlSpider. Có nhiều cách để thực hiện việc này.
Sử dụng mẫu có sẵn
Scrapy có một công cụ để sinh code tự động cho các spider. Chúng ta có thể sử dụng lệnh như sau:
$ scrapy genspider stack_crawler stackoverflow.com -t crawl Created spider 'stack_crawler' using template 'crawl' in module: stack.spiders.stack_crawler
Lệnh trên sẽ thêm một spider mới trong thư mục spiders đang có. Tuy nhiên, đây không phải là cách duy nhất. Mẫu có sẵn có rất nhiều code được sinh tự động, mà như thế rất dễ khiến chúng ta lười đi. Nên tôi sẽ sửa lại spider đang có để phù hợp với nhu cầu.
Sửa lại spider đang có
Thực ra cũng rất đơn giản, chúng ta cần update class StackSpider kế thừa từ class CrawlSpider thay vì class Spider thông thường
from scrapy.spiders import CrawlSpider class StackSpider(CrawlSpider): ...
Thêm rule
Chúng ta cần thêm rule để Scrapy biết cách tìm link trang kế tiếp và request đến trang đó. Việc này cũng rất dễ dàng bằng cách thêm một regular expression vào thuộc tính rules của class:
from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class StackSpider(CrawlSpider): ... rules = ( Rule(LinkExtractor(allow=r"questions?page=[0-5]&sort=newest"), callback="parse_item", follow=True), )
Ví dụ trên, tôi chỉ scrape dữ liệu ở 5 trang. Bạn có thể điều chỉnh nó để phù hợp với nhu cầu của riêng mình.
Sau đó bạn cần đổi tên phương thức parse thành parse_item. Bây giờ, Scrapy sẽ tự động tìm link các trang kế tiếp và gửi request đến trang đó, sau đó Scrapy sẽ xử lý dữ liệu thu về bằng phương thức parse_item. Nội dung phương thức parse đã viết trước đó không cần thay đổi gì, bởi các trang cấu trúc giống hệt nhau.
Tại sao phải đổi tên phương thức parse thành parse_item? Bởi vì CrawlSpider đã có sẵn phương thức parse để thực hiện một số thao tác của nó, nếu bạn sử dụng phương thức parse nó sẽ ghi đè lên phương thức của CrawlSpider, khi đó, CrawlSpider không hoạt động đúng như thiết kế mà chỉ hoạt động như một Spider thông thường mà thôi.
Thêm thời gian chờ
Có một điểm cần lưu ý, đó là bạn sẽ tăng áp lực phục vụ lên trang Web bạn đang muốn scrape bằng cách gửi request liên tục. Chúng ta không nên làm vậy. Vì vậy, chúng ta cần thiết lập thời gian chờ khi download xong một trang. Việc này thực hiện rất dễ dàng bằng cách thêm dòng sau vào settings.py
DOWNLOAD_DELAY = 5
Thiết lập trên sẽ cho Scrapy khoảng thời gian chờ là 5 giây trước khi thực hiện request đến trang tiếp theo. Bạn có thể thay đổi cho phù hợp, tuy nhiên điều này rất quan trọng, bởi chúng ta không nên DDoS các dịch vụ như vậy (mặc dù khó thành công). Nếu bạn cố tình request liên tục đến trang StackOverflow, hãy cẩn thận vì bạn có thể bị ban IP.
Bây giờ, giả sử chúng ta muốn scrape thêm cả nội dung câu hỏi thay vì chỉ tiêu đề và URL. Điều này cũng không khó, bởi Scrapy hỗ trợ chúng ta rất tốt.
Cách làm có thể mô tả ngắn gọn như sau: Từ trang danh sách các câu hỏi, chúng ta sẽ lấy được URL của chúng. Với mỗi URL này, chúng ta sẽ gửi một request đến nó và sẽ yield dữ liệu thu được khi xử lý những request này.
Thêm trường content cho StackItem
Để chứa được nội dung câu hỏi, thì đối tượng StackItem phải có trường tương ứng, chúng ta sẽ thêm trường này.
class StackItem(scrapy.Item): ... content = scrapy.Field()
Lấy URL của câu hỏi và gửi request
Bây giờ, từ trang danh sách câu hỏi, chúng ta không lấy tiêu đề của câu hỏi nữa. Chúng ta chỉ lấy URL của chúng và gửi request đến những URL này và yield dữ liệu thu được.
def parse_item(self, response): questions = response.xpath('//div[@class="summary"]/h3') for question in questions: question_location = question.xpath( 'a[@class="question-hyperlink"]/@href').extract()[0] full_url = response.urljoin(question_location) yield scrapy.Request(full_url, callback=self.parse_question)
Như vậy, với mỗi request đến từng câu hỏi, chúng ta sử dụng callback tới phương thức parse_question để xử lý dữ liệu. Trong phương thức này, chúng ta sẽ phân tích và tách ra những thông tin chúng ta cần.
Phương thức parse_question
Trong bài viết trước, tôi đã hướng dẫn cách sử dụng XPath selector để chọn lọc ra các thông tin cần thiết. Tuy nhiên, XPath có một nhược điểm, đó nếu đối tượng có nhiều thành phần con trong nó thì rất khó để trích xuất dữ liệu. Trong thường hợp này, chúng ta có thể sử dụng CSS selector.
Nếu là một người lập trình Web thì chắc chắn bạn sẽ không xa lạ gì với CSS selector. Tuy nhiên, bạn có thể tham khảo thêm về selector của Scrapy để biết cách sử dụng sao cho đúng. Vì selector dùng trong các file CSS có chút khác biệt nhỏ với selector của Scrapy.
Bạn có thể sử dụng Chrome để hộ trợ làm việc với CSS selector. Cách làm cũng tương tự như với XPath.
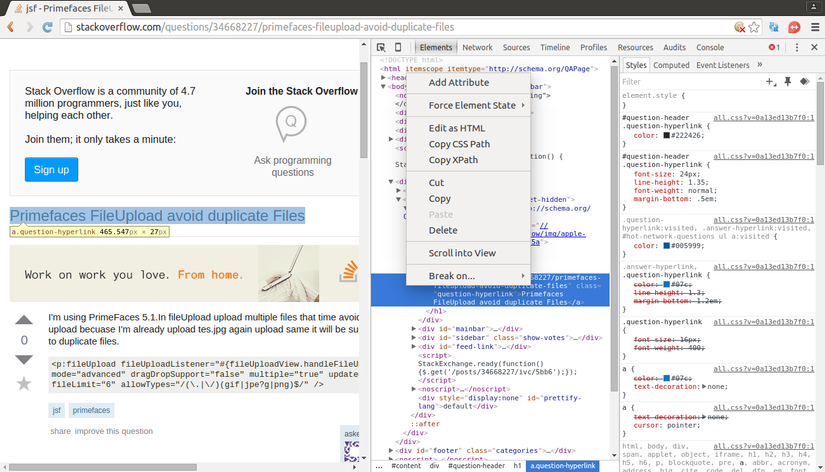
Bây giờ, từ dữ liệu thu được, chúng ta cần trích xuất ra các thông tin như URL của câu hỏi, tiêu đề và nội dung câu hỏi đó.
def parse_question(self, response): item = StackItem() item["title"] = response.css( "#question-header h1 a::text").extract()[0] item["url"] = response.url item["content"] = response.css( ".question .post-text").extract()[0] yield item
Trong phương thức parse_question này, nếu muốn bạn vẫn có thể gửi request đến một trang khác nữa nếu bạn lấy được link từ trang này. Đây là một công cụ rất tiện ích của Scrapy cho phép chúng ta có thể follow các link dẫn từ hết trang này đến trang khác.
Còn một việc cần làm nữa là lưu dữ liệu thu được. Lúc trước chúng ta chỉ lưu URL và tiêu đề của câu hỏi, bây giờ chúng ta cần thêm 1 trường lưu nội dung câu hỏi đó.
_stack_items = Table("questions", _metadata, Column("id", Integer, primary_key=True), Column("url", Text), Column("title", Text), Column("content", Text))
Lưu ý rằng, việc này chỉ có tác dụng khai báo với SQLAlchemy biết rằng chúng ta sẽ lưu thêm 1 trường content nữa. Mặc dù piplines đã được thiết kế để tạo bảng nếu bảng đó chưa tồn tại, nhưng nếu bảng đã tồn tại rồi thì nó sẽ không thay đổi cấu trúc nữa. Bảng lần trước chỉ có 2 trường là url và title. Bạn sẽ phải thêm trường content bằng tay vào bảng này, hoặc bạn có thể xóa bảng đi để piplines tạo bảng mới cho bạn.
Bây giờ, dữ liệu chúng ta thu được là rất lớn, vì scrape trên 5 trang. Nên mỗi lần scrape có thể sẽ có những dữ liệu bị lặp lại. Nên khi lưu vào cơ sở dữ liệu, chúng ta cần kiểm tra xem dữ liệu đã được ghi trong bảng chưa. Nếu đã có dữ liệu rồi thì không cần thêm bản ghi mới nữa.
def process_item(self, item, spider): is_valid = True for data in item: if not data: is_valid = False raise DropItem("Missing %s!" % data) if is_valid: q = select([self.stack_items]).where(self.stack_items.c.title == item['title']) existence = list(self.connection.execute(q)) if existence: raise DropItem("Item existed") else: ins_query = self.stack_items.insert().values( url=item["url"], title=item["title"], content=item["content"] ) self.connection.execute(ins_query) return item
Bạn có thể test công cụ sau khi thay đổi
$ scrapy crawl stack
Và kết quả là dữ liệu đã được thu về rất đầy đủ.

Bạn có thể tham khảo mã nguồn ở ví dụ của tôi trên Github. Hoặc bạn có thể tự xây dựng công cụ cho mình. Scrapy là một thư viện rất tuyệt vời, và nó cung cấp tất cả những công cụ chúng ta cần để thực hiện việc scrape và crawl dữ liệu.
Bài viết gốc: https://manhhomienbienthuy.bitbucket.io/2016/Jan/11/advanced-web-scraping-and-crawling-with-scrapy-and-sqlalchemy.html (đã xin phép tác giả
