Lộ thông tin người dùng bởi session-replay scripts
Bạn có thể biết rằng hầu hết các trang web có tập lệnh phân tích của bên thứ ba ghi lại những trang bạn truy cập và các tìm kiếm bạn thực hiện. Nhưng gần đây, ngày càng có nhiều trang web sử dụng session-replay scripts. Các tập lệnh này ghi lại các phím bấm, di chuyển chuột và hành vi cuộn cùng với ...
Bạn có thể biết rằng hầu hết các trang web có tập lệnh phân tích của bên thứ ba ghi lại những trang bạn truy cập và các tìm kiếm bạn thực hiện. Nhưng gần đây, ngày càng có nhiều trang web sử dụng session-replay scripts. Các tập lệnh này ghi lại các phím bấm, di chuyển chuột và hành vi cuộn cùng với toàn bộ nội dung của các trang mà bạn truy cập và gửi chúng tới các máy chủ của bên thứ ba. Không giống các dịch vụ phân tích thông thường cung cấp số liệu thống kê tổng hợp, các tập lệnh này dành cho việc ghi lại và phát lại các phiên duyệt riêng lẻ, như thể ai đó đang theo dõi bạn.
Mục đích của các dữ liệu được thu thập này nhằm đưa ra cách người dùng tương tác với các trang web và khám phá các trang bị hỏng hoặc khó sử dụng. Tuy nhiên mức độ thu thập dữ liệu của các dịch vụ này vượt xa sự mong đợi của người dùng [1]; văn bản được đánh vào các hình thức được thu thập trước khi người dùng gửi biểu mẫu, và các chuyển động chuột chính xác được lưu, tất cả đều không có dấu hiệu trực quan cho người dùng. Dữ liệu này không thể được kỳ vọng được giữ kín. Trên thực tế, một số công ty cho phép các nhà xuất bản kết nối rõ ràng bản ghi với thực tế của người dùng.
https://s3.amazonaws.com/ftt-uploads/wp-content/uploads/2017/11/15012417/user_replay_fullstory_demo.mp4 Video này hiển thị tính năng “co-browse” của một công ty, nơi nhà xuất bản có thể xem các tháo tác người dùng trực tuyến
Cái mà có thể sai lầm? Trong ngắn hạn, rất nhiều.
Việc thu thập nội dung trang do các kịch bản phát lại của bên thứ ba có thể gây ra các thông tin nhạy cảm như các điều kiện y tế, chi tiết thẻ tín dụng và thông tin cá nhân khác được hiển thị trên một trang để rò rỉ cho bên thứ ba trong quá trình thu thập. Điều này có thể khiến người dùng dinh phải các hành vi trộm cắp, lừa đảo trực tuyến và các hành vi không mong muốn khác. Điều này cũng đúng cho việc thu thập các đầu vào của người dùng trong quá trình thanh toán và đăng ký.
Các dịch vụ phát lại cung cấp kết hợp các công cụ chỉnh sửa thủ công và tự động cho phép nhà xuất bản loại trừ thông tin nhạy cảm khỏi các bản ghi. Tuy nhiên, để tránh sự rò rỉ, nhà xuất bản cần phải kiểm tra kỹ lưỡng tất cả các trang hiển thị hoặc chấp nhận thông tin người dùng. Đối với các trang web được tạo tự động, quy trình này sẽ liên quan đến việc kiểm tra mã phía máy chủ của ứng dụng web. Hơn nữa, quá trình này sẽ cần phải được lặp lại mỗi khi một trang web được cập nhật hoặc các ứng dụng web mà quyền lực trang web được thay đổi.
Quy trình tái bản kỹ lưỡng là yêu cầu đối với một số dịch vụ ghi âm, trong đó nghiêm cấm việc thu thập dữ liệu người dùng. Để hiểu rõ hơn về hiệu quả của các phương pháp này, chúng tôi thiết lập các trang thử nghiệm và cài đặt các kịch bản phát lại từ sáu trong số bảy công ty [3]. Từ kết quả của các thử nghiệm này, cũng như phân tích một số trang web trực tiếp, chúng tôi nêu bật bốn loại lỗ hổng dưới đây:
1. Mật khẩu được bao gồm trong bản ghi.Tất cả các dịch vụ nghiên cứu cố gắng để ngăn chặn rò rỉ mật khẩu bằng cách tự động loại bỏ các trường nhập mật khẩu từ các bản ghi. Tuy nhiên, các trường đăng nhập thân thiện với thiết bị di động sử dụng đầu vào văn bản để lưu trữ mật khẩu không được phơi bày không được quy định lại bởi quy tắc này, trừ khi nhà xuất bản thủ công thêm thẻ làm lại để loại trừ chúng. Chúng tôi đã tìm thấy ít nhất một trang web nơi mật khẩu được nhập vào biểu mẫu đăng ký đã bị tiết lộ cho SessionCam, ngay cả khi biểu mẫu chưa bao giờ được gửi đi.
2. Dữ liệu đầu vào người dùng nhạy cảm nên được chỉnh sửa một phần và không hoàn toàn.Khi người dùng tương tác với trang web, họ sẽ cung cấp dữ liệu nhạy cảm trong quá trình tạo tài khoản, trong khi thực hiện mua hàng, hoặc trong khi tìm kiếm trang web. Các tập lệnh ghi chép phiên có thể sử dụng tổ hợp phím hoặc các yếu tố nhập dữ liệu đầu vào để thu thập dữ liệu này.
Tất cả các công ty được nghiên cứu đều có một số biện pháp giảm nhẹ thông qua tự động sửa đổi, tuy nhiên phạm vi bảo hiểm được cung cấp khác nhau rất nhiều bởi nhà cung cấp. UserReplay và SessionCam thay thế tất cả các đầu vào của người dùng bằng kí tự . hoặc * có độ dài tương đương, trong khi FullStory, Hotjar và Smartlook loại trừ các trường đầu vào cụ thể theo loại. Chúng tôi tóm tắt việc làm lại các lĩnh vực khác trong bảng dưới đây
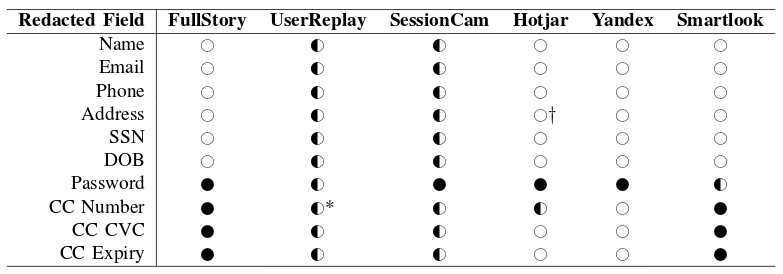
Ngoài việc thu thập dữ liệu đầu vào của người dùng, các công ty ghi âm phiên cũng thu thập nội dung trang được hiển thị. Không giống như ghi âm đầu vào của người dùng, không có công ty nào cung cấp các sửa đổi nội dung được hiển thị theo mặc định; tất cả nội dung được hiển thị trong các cuộc kiểm tra của chúng tôi đều bị rò rỉ.
Thay vào đó, các công ty ghi âm kỳ vọng các trang web tự gắn nhãn tất cả thông tin nhận dạng cá nhân được bao gồm trong trang được hiển thị. Dữ liệu người dùng nhạy cảm có một số con đường để kết thúc trong quá trình ghi âm và những rò rỉ nhỏ trên nhiều trang có thể dẫn đến sự tích tụ dữ liệu cá nhân lớn trong một lần ghi.
Đối với các bản ghi phải hoàn toàn miễn phí thông tin cá nhân, nhà phát triển ứng dụng web của trang web sẽ cần làm việc với các nhóm tiếp thị và phân tích của trang web để lặp lại các thông tin nhận dạng cá nhân từ các bản ghi khi phát hiện. Bất kỳ thay đổi nào đối với thiết kế trang web, chẳng hạn như thay đổi thuộc tính lớp của một phần tử chứa thông tin nhạy cảm hoặc quyết định đưa dữ liệu cá nhân vào một loại phần tử khác đòi hỏi phải xem lại các quy tắc về đổi mới.
4. Các dịch vụ ghi âm có thể không bảo vệ dữ liệu người dùng.Các dịch vụ ghi âm làm tăng khả năng làm lôk với các vi phạm dữ liệu vì dữ liệu cá nhân chắc chắn sẽ dẫn đến việc ghi âm. Các dịch vụ này phải xử lý dữ liệu ghi với thực tiễn bảo mật giống như một nhà xuất bản sẽ được mong đợi để xử lý dữ liệu người dùng.
Chúng tôi cung cấp một ví dụ cụ thể về cách các dịch vụ ghi âm có thể không làm như vậy. Sau khi ghi âm một đoạn hoàn chỉnh, nhà xuất bản có thể xem lại nó bằng cách sử dụng một bảng điều khiển được cung cấp bởi dịch vụ ghi âm. Bảng điều khiển của nhà xuất bản cho Yandex, Hotjar và Smartlook đều phân phối phát lại trong trang HTTP, thậm chí cho các bản ghi được thực hiện trên các trang HTTPS. Điều này cho phép man-in-the-middle tự động chèn một tập lệnh vào trang phát lại và trích xuất tất cả dữ liệu ghi âm. Tệ hơn nữa, Yandex và Hotjar cung cấp nội dung của trang nhà xuất bản qua HTTP - dữ liệu mà trước đây được bảo vệ bởi HTTPS hiện nay dễ bị giám sát mạng thụ động.
Các lỗ hổng mà chúng tôi đánh dấu ở trên là liên quan đến ghi chép toàn bộ trang. Đó không phải là để nói rằng các ví dụ cụ thể không thể được cố định - thực sự, các nhà xuất bản chúng tôi kiểm tra có thể vá lỗ hổng của họ về dữ liệu người dùng và mật khẩu. Các dịch vụ ghi âm đều có thể sử dụng HTTPS trong quá trình phát lại. Nhưng miễn là tính bảo mật của dữ liệu người dùng dựa vào các nhà xuất bản để chỉnh sửa lại các trang web của họ, những lỗ hổng tiềm ẩn này sẽ tiếp tục tồn tại.
Bài dịch còn hạn chế, các bạn có thể tham khảo bài viết gốc tại link
