Phân loại văn bản Tiếng Việt tự động - Phần 1
Xin chào các bạn, khi tôi ngồi viết bài này cũng là lúc tôi vừa nhận được một tin vui đó là bài báo của tôi với chủ đề Vietnamese News Classification based on BoW with Keywords Extraction and Neural Network được chấp nhận để trình bày trên hội nghị IES và được xuất bản bởi IEEE. Có một chút gọi ...
Xin chào các bạn, khi tôi ngồi viết bài này cũng là lúc tôi vừa nhận được một tin vui đó là bài báo của tôi với chủ đề Vietnamese News Classification based on BoW with Keywords Extraction and Neural Network được chấp nhận để trình bày trên hội nghị IES và được xuất bản bởi IEEE. Có một chút gọi là niềm vui nho nhỏ của tôi trong ngày cuối tuần này và tôi nghĩ rằng tôi nên chia sẻ điều đó cho các bạn. Chính vì thế, hôm nay tôi sẽ trình bày cho các bạn một ví dụ cơ bản nhất trong Phân loại văn bản để các bạn có thể nắm bắt được các khái niệm chính yếu, cơ bản của Xử lý ngôn ngữ tự nhiên và ứng dụng trong bài toán Phân loại văn bản tự động thế nào. OK chúng ta bắt đầu thôi.
Phân loại văn bản hay còn gọi là Text Classifcation hoặc là Text Categorizer (từ bầy giờ tôi sẽ gọi tắt là TC cho tiện) là một bài toán thuộc về lĩnh vực Xử lý ngôn ngữ tự nhiên dưới dạng văn bản (text). Tuy nhiên nó gắn liền với Machine Learning bởi vì nó có từ phân loại làm cho chúng ta nhớ đến những khái niệm cơ bản mà tôi đã đề cập trong Bài 1 của blog này. Nếu các bạn là những người mới bước chân vào lĩnh vực này thì tôi xin phép được nhắc lại một chút ở đây
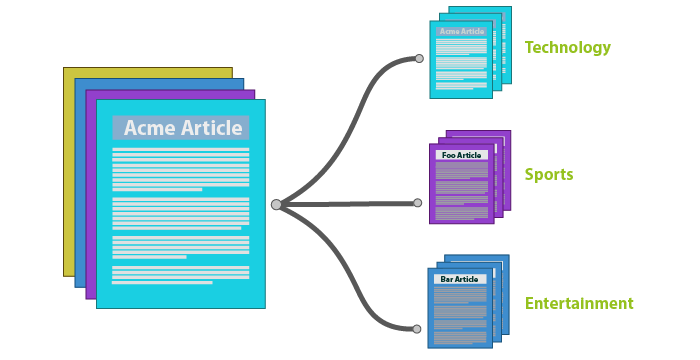
Phân loại - classification
Chúng ta có thể tưởng tượng bài toán này như sau: Cho một tập gồm nnn văn bản - document đầu vào kí hiệu
D={d1,d2,...,dn}D = left {d_1, d_2, ..., d_n ight } D={d1,d2,...,dn}
bằng các kĩ thuật xử lý nào đó chúng ta sẽ phân chúng vào một tập gồm mmm phân lớp - categories kí hiệu là
C={c1,c2,...,cm}C = left {c_1, c_2, ..., c_m ight } C={c1,c2,...,cm}
Mình họa trực quan nhất cho việc phân loại văn bản này đó chính là việc sắp xếp các tin tức trên báo vào các danh mục tương ứng như thể thao, giải trí, xã hội... như các tờ báo điện tử thường làm. Việc này có thể được thực hiện thủ công bởi các biên tập viên tuy nhiên nó rất là mất thời gian và công sức. Thay vào đó chúng ta sẽ sử dụng một số kĩ thuật học máy để tiến hành phân loại tự động các tin tức đó. Đỡ tốn công sức của các biên tập viên rất nhiều phải không. Vậy chúng ta thực hiện nó bằng cách nào thì hồi sau sẽ rõ.
Quy trình thực hiện
Cũng giống như các bài toán Machine Learning khác thì bài toán phân loại văn bản của chúng ta cũng bao gồm hai bước chính đó là Learning và Prediction cụ thể trong hình dưới.

Bạn có thể tham khảo Blog Cái máy nó học thế nào để hiểu rõ hơn về các bước thực hiện một bài toán Machine Learning ở đây tôi sẽ giải thích rõ hơn hình vẽ trên như sau:
Phần phía trên được gọi là bước học hay chính là các chúng ta sử dụng các kĩ thuật học máy để tìm ra được một model hợp lý nhất cho bài toán của chúng ta.
Nó bao gồm một số bước như sau:
-
Cleaning data là bước làm sạch dữ liệu trước khi bắt đầu bất kì xử lý nào trên tập dữ liệu của chúng ta, nó bao gồm một số khái niệm của xử lý ngôn ngữ tự nhiên như loại bỏ Stop Words, hoặc kiểm tra chính tả chẳng hạn.
-
Words segmentation hay còn gọi là tách từ là một bước cực kì quan trọng nhất là đối với Tiếng Việt tôi sẽ trình bày cụ thể trong phần tiếp theo đây.
-
Feature Extraction chính là bước tìm ra được các tinh hoa từ tập dữ liệu ban đầu hay nói cách khác là lựa chọn cách đặc trưng tiêu biểu có tính đại diện cho tập dữ liệu để làm input cho thuật toán phân lớp
-
Training là bước mà chúng ta sử dụng các thuật toán học máy để tìm ra mô hình tốt nhất nhằm sử dụng trong bước tiếp theo
Phần phía dưới chính là việc chúng ta thích làm nhất đó chính là đem đứa con thân yêu chính là model thu được sau khi learning phía trên đó, đi vào thực tế để xem nó có thực sự đủ tốt hay không. Bước này bao gồm các bước xử lý giống như phía trên, chỉ khác mỗi một điều là chúng ta không training lại mô hình nữa mà sử dụng trực tiếp model có sẵn để dự đoán đầu ra output. Tôi sẽ minh họa một số bước xử lý cụ thể và hướng dẫn bằng Python trong các phần tiếp theo đây.
Chuẩn bị tập dữ liệu
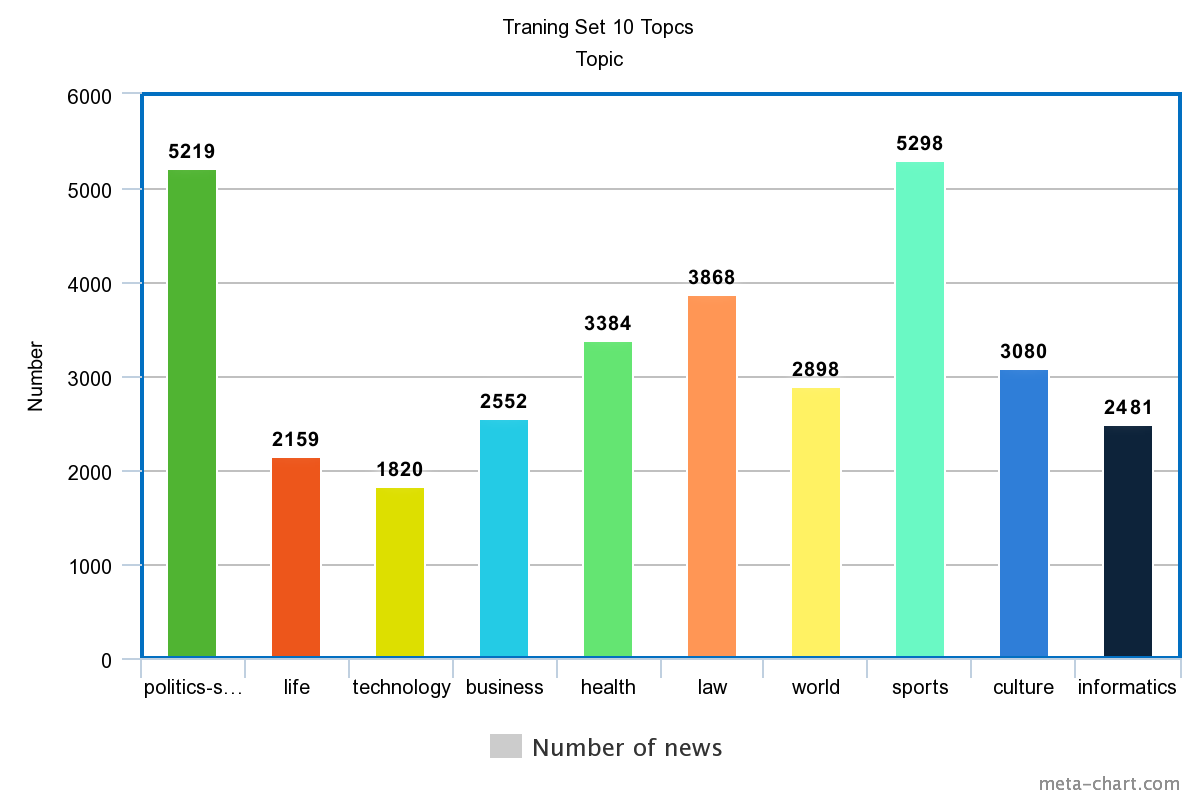
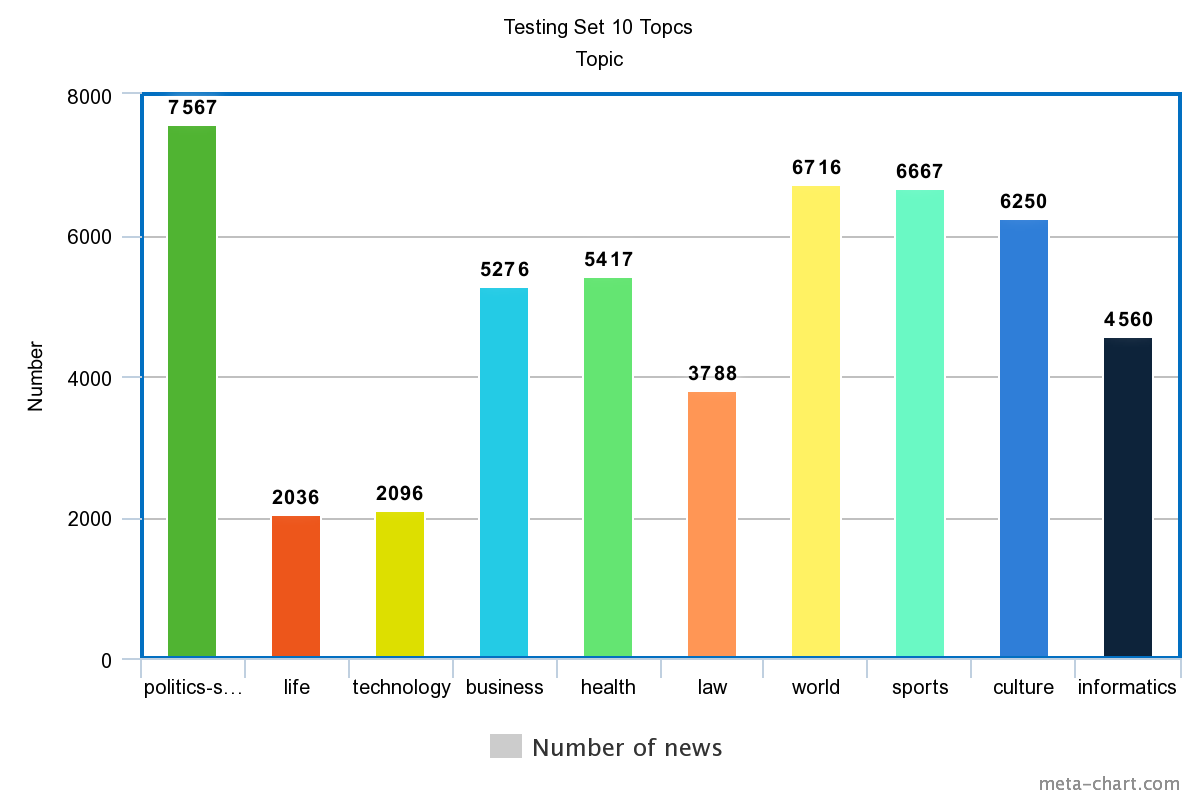
Có khá nhiều tập dữ liệu để phục vụ cho mục đích nghiên cứu của chúng ta trong lĩnh vực phân loại văn bản các bạn có thể tham khảo tại đây tuy nhiên trong bài viết này chúng ta sẽ sử dụng một tập dữ liệu dành cho Tiếng Việt được tôi custom lại từ một nghiên cứu khác. Các bạn có thể download bản Full HD không che của tập dữ liệu này tại đây chúng ta chỉ sử dụng một phần nhỏ của tập dữ liệu này với mục đích demo cho nó nhanh. Bản Full HD của tập dữ liệu bao gồm 10 Topics được phân chia thành hai tập là training và tập testing và phân bố dữ liệu được thể hiện trong hình sau
Data training
Data testing
Sau khi chúng ta đã download được dữ liệu về giải nén vào một thư mục đặt tên là data các bạn tiến hành đổi tên các thư mục chứa dữ liệu (tương ứng với các category) của bài viết thành tiếng anh cho dễ xử lý. Sau cùng nó sẽ có hình thù như sau
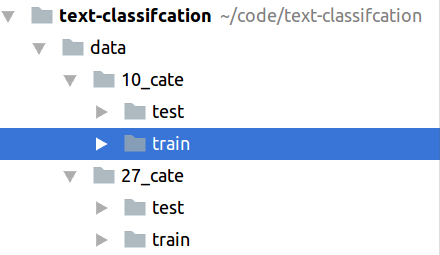
Có thể nhận thấy được lượng lớn dữ liệu này nếu xử lý hết e rằng mất khá nhiều thời gian của các bạn nên tôi chỉ sử dụng một phần nhỏ trong tập dữ liệu với mục đích minh họa cho các bạn các bước cơ bản trong bài toán Xử lý ngôn ngữ Tiếng Việt mà thôi. Chúng ta sẽ tạo một class đặt tên là DataLoader để tiến hành xử lý tập dữ liệu này.
class DataLoader(object):
def __init__(self, dataPath):
self.dataPath = dataPath
Hàm __init__ nhận đầu vào là đường dẫn đến thư mục chúng ta cần xử lý. Ở đây chính là hai thư mục training và testing của mỗi topic. Tiếp theo chúng ta sẽ viết hàm để load dữ liệu từ các file bên trong các thư mục đó. Ngắm nghía cấu trúc thư mục ta thấy như sau:
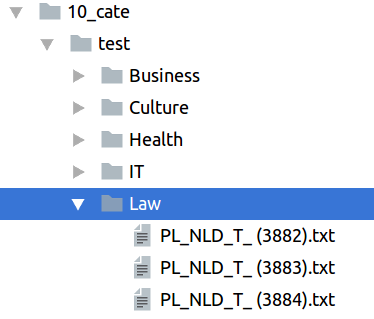
Và chúng ta cần làm là chạy vào từng thư mục con của thư mục train và test sau đó lấy nội dung của từng file ra để xử lý. Hàm đó như sau:
def __get_files(self):
folders = [self.dataPath + folder + '/' for folder in os.listdir(self.dataPath)]
class_titles = os.listdir(self.dataPath)
files = {}
for folder, title in zip(folders, class_titles):
files[title] = [folder + f for f in os.listdir(folder)]
self.files = files
Và cuối cùng để khỏi phải lặp lại các bước trên mỗi khi xử lý chúng ta sẽ dump đống dữ liệu đó ra kiểu json với định dạng:
{
'category' : 'Lifes',
'content' : 'xxx...'
}
Và hàm đó được viết tiếp trong class DataLoader nhưng để public để có thể gọi được từ các class khác.
def get_json(self):
self.__get_files()
data = []
for topic in self.files:
rand = randint(2000, 4000)
i = 0
for file in self.files[topic]:
content = FileReader(filePath=file).content()
data.append({
'category': topic,
'content': content
})
if i == rand:
break
else:
i += 1
return data
Ở đây vì không muốn lấy hết tập dữ liệu nên tôi để một số random số lượng bài viết trong khoảng từ 2000 đến 4000 bài cho mỗi class. Bạn đọc có thể config lại theo ý muốn. Chúng ta thấy đoạn code trên có gọi đến một class khác là FileReader chúng ta sẽ phải tạo ra nó để thao tác và làm việc với File đơn giản hơn.
class FileReader(object):
def __init__(self, filePath, encoder = None):
self.filePath = filePath
self.encoder = encoder if encoder != None else 'utf-16le'
def read(self):
with open(self.filePath) as f:
s = f.read()
return s
def content(self):
s = self.read()
return s.decode(self.encoder)
Settings
Chúng ta sẽ lưu các đường dẫn cần thiết vào trong file settings.py giống như sau:
import os DIR_PATH = os.path.dirname(os.path.realpath(__file__)) DATA_TRAIN_PATH = os.path.join(DIR_PATH, 'data/10_cate/train/') DATA_TEST_PATH = os.path.join(DIR_PATH, 'data/10_cate/test/') DATA_TRAIN_JSON = os.path.join(DIR_PATH, 'data_train.json') DATA_TEST_JSON = os.path.join(DIR_PATH, 'data_test.json')
Sau khi chạy thử hàm get_json() trong class DataLoader chúng ta sẽ thu được hai file json có định dạng như trên. Bạn đọc có thể thực hiện nó trong hàm main như sau:
if __name__ == '__main__':
json_train = DataLoader(dataPath=settings.DATA_TRAIN_PATH).get_json()
FileStore(filePath=settings.DATA_TRAIN_JSON, data=json_train).store_json()
json_test = DataLoader(dataPath=settings.DATA_TEST_PATH).get_json()
FileStore(filePath=settings.DATA_TEST_JSON, data=json_test).store_json()
Sau khi đã có tập dữ liệu chúng ta tiến hành một số bước lựa chọn thuộc tính đầu vào cho bài toán phân lớp. Nó sẽ bao gồm một số bước cơ bản như sau:
Words segmentation
Hay còn gọi là tách từ là một bước quan trọng bậc nhất trong xử lý ngôn ngữ tự nhiên. Tiếng Việt không đơn giản như tiếng anh vì nó có thêm các từ ghép. Bạn hãy tưởng tượng một câu như sau:
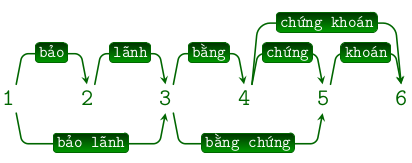
Có thể tách từ theo nhiều cách khác nhau gây ra sự nhập nhằng về mặt ngữ nghĩa. Đây là một bài toán hết sức thú vị. Tuy nhiên chúng ta có một số công cụ để thực hiện việc này mà phổ biến nhất đó là VnTokenizer bạn đọc có thể cài đặt gói thư viện hỗ trợ Python bằng cách sử dụng pip với câu lệnh sau:
pip install pyvi
Chúng ta thực hiện việc này bằng việc xây dựng một class tên là NLP
from pyvi.pyvi import ViTokenizer
class NLP(object):
def __init__(self, text = None):
self.text = text
self.__set_stopwords()
def segmentation(self):
return ViTokenizer.tokenize(self.text)
Có thể kiểm tra nó bằng câu lệnh sau:
temp = u"Chào các bạn tôi là Phạm Văn Toàn đến từ blog Tự học Machine Learning"
print NLP(text=temp).segmentation()
>>> Xin chào các bạn tôi là Phạm_Văn_Toàn đến từ blog Tự học Machine_Learning
Remove Stopwords
Hãy tưởng tượng rằng ngôn ngữ của chúng ta giống như một đống gạo bị lẫn với thóc. Việc cần làm của trích chọn đặc trưng đó chính là chọn ra các hạt gạo chất lượng tốt nhất từ đống thóc đó. Những hạt thóc đó được gọi là stop words tức là những từ không có ý nghĩa lắm đối với việc phân loại của chúng ta.

Chính vì thế nên cần phải loại bỏ nó trước khi xử lý dữ liệu. Trong Tiếng Việt chúng ta cần định nghĩa một danh sách các stopwords tùy thuộc vào lĩnh vực mà chúng ta cần xử lý văn bản. Tức là với xử lý tin tức báo chí sẽ có một tập stopwords khác với xử lý bài báo khoa học.
Thực hiện điều này với Python bằng hàm get_words() như sau:
class NLP(object):
def __set_stopwords(self):
self.stopwords = FileReader(settings.STOP_WORDS).read_stopwords()
def split_words(self):
text = self.segmentation()
try:
return [x.strip(settings.SPECIAL_CHARACTER).lower() for x in text.split()]
except TypeError:
return []
def get_words_feature(self):
split_words = self.split_words()
return [word for word in split_words if word.encode('utf-8') not in self.stopwords]
trong đó chúng ta định nghĩa một tập các kí tự đặc biệt loại bỏ khi tách từ trong file settings.py như sau:
SPECIAL_CHARACTER = '0123456789%@$.,=+-!;/()*"&^:#| '
Xây dựng từ điển các từ
Hãy tưởng tượng chúng ta cần biến tất cả các từ của trong văn bản của chúng ta thành dạng biểu diễn số. Cách đơn giản nhất mà chúng ta có thể làm đó chính là xây dựng một bộ từ điển rồi sau đó thay thế từ đó bằng thứ tự xuất hiện trong từ điển.

Để làm được việc này chúng ta sử dụng một thư viện rất nổi tiếng cho Xử lý ngôn ngữ tự nhiên trên Python đó chính là gensim
Đầu tiên chúng ta cần config tên file để lưu từ điển trong file settings.py
DICTIONARY_PATH = 'dictionary.txt'
Sau đó chúng ta sẽ viết hàm lưu từ điển sử dụng thư viện gensim
class FileStore(object):
def __init__(self, filePath, data = None):
self.filePath = filePath
self.data = data
def store_dictionary(self, dict_words):
dictionary = corpora.Dictionary(dict_words)
dictionary.filter_extremes(no_below=20, no_above=0.3)
dictionary.save_as_text(self.filePath)
Tiếp theo chúng ta tiến hành xây dựng từ điển chứa tất cả các từ trong tập dữ liệu của chúng ta sau khi đã tiến hành tách từ và loại bỏ stopwords
class FeatureExtraction(object):
def __init__(self, data):
self.data = data
def __build_dictionary(self):
print 'Building dictionary'
dict_words = []
i = 0
for text in self.data:
i += 1
print "Step {} / {}".format(i, len(self.data))
words = NLP(text = text['content']).get_words_feature()
dict_words.append(words)
FileStore(filePath=settings.DICTIONARY_PATH).store_dictionary(dict_words)
def __load_dictionary(self):
if os.path.exists(settings.DICTIONARY_PATH) == False:
self.__build_dictionary()
self.dictionary = FileReader(settings.DICTIONARY_PATH).load_dictionary()
Khởi tạo vector thuộc tính với Bag of Word
Hãy tưởng tượng bạn đang có một loạt các túi đựng từ mỗi túi tượng trưng cho một từ trong từ điển mà chúng ta vừa tạo ra. Tư tưởng chính của Bag of Word này là:
Chạy từ đầu đến cuối văn bản, gặp từ nào thì ném nó vào túi tương ứng
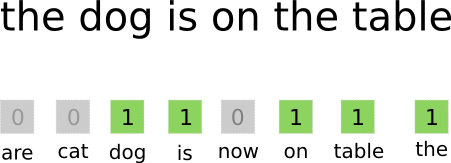
Cuối cùng chúng ta sẽ thu được vector thuộc tính. Đây là một vecto kiểu dày đặc tương ứng với Dense Layer trong Neural Network mà tôi sẽ trình bày với các bạn trong một dịp khác. Từ đây chúng ta tiến hành khởi tạo vector thuộc tính cho từng file trong tập dữ liệu. Mỗi vector sẽ có độ dài chính bằng số từ trong từ điển. Chúng ta thực hiện nó với đoạn code sau:
class FeatureExtraction(object):
def __build_dataset(self):
self.features = []
self.labels = []
i = 0
for d in self.data:
i += 1
print "Step {} / {}".format(i, len(self.data))
self.features.append(self.get_dense(d['content']))
self.labels.append(d['category'])
def get_dense(self, text):
self.__load_dictionary()
words = NLP(text).get_words_feature()
# Bag of words
vec = self.dictionary.doc2bow(words)
dense = list(matutils.corpus2dense([vec], num_terms=len(self.dictionary)).T[0])
return dense
def get_data_and_label(self):
self.__build_dataset()
return self.features, self.labels
Sau khi đã có được vector thuộc tính sử dụng phương pháp Bag of Word chúng ta sẽ tiến hành phân loại văn bản. Chúng ta sẽ sử dụng một thuật toán đã được giới thiệu trong Blog #2 áp dụng cho bài toán phân loại hoa đó chính là LinearSVC chúng ta có thể sử dụng bất kì thuật toán nào khác để phân lớp.
class Classifier(object):
def __init__(self, features_train = None, labels_train = None, features_test = None, labels_test = None, estimator = LinearSVC(random_state=0)):
self.features_train = features_train
self.features_test = features_test
self.labels_train = labels_train
self.labels_test = labels_test
self.estimator = estimator
def training(self):
self.estimator.fit(self.features_train, self.labels_train)
self.__training_result()
def save_model(self, filePath):
FileStore(filePath=filePath).save_pickle(obj=est)
def __training_result(self):
y_true, y_pred = self.labels_test, self.estimator.predict(self.features_test)
print(classification_report(y_true, y_pred))
Trong đoạn code trên chúng ta thấy được hàm __training_result cho kết quả của việc phân lớp. Chúng ta sẽ đánh giá trên hai tập dữ liệu là training và testing. Trong hàm main chúng ta gọi lớp Classifier này như sau:
if __name__ == '__main__':
train_loader = FileReader(filePath=settings.DATA_TRAIN_JSON)
test_loader = FileReader(filePath=settings.DATA_TEST_JSON)
data_train = train_loader.read_json()
data_test = test_loader.read_json()
features_train, labels_train = FeatureExtraction(data=data_train).get_data_and_label()
features_test, labels_test = FeatureExtraction(data=data_test).get_data_and_label()
est = Classifier(features_train=features_train, features_test=features_test, labels_train=labels_train, labels_test=labels_test)
est.training()
est.save_model(filePath='trained_model/linear_svc_model.pk')
Sau khi chạy với dữ liệu khoảng 1300 cho tập training và 1400 cho tập testing cho kết quả không được khả quan cho lắm chỉ khoảng 61%
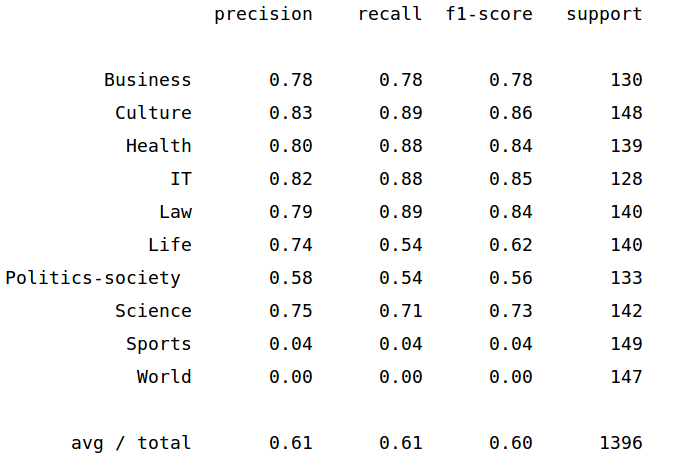
trong khi đó trong bài báo của tôi cho kết quả chính xác lên đến 99.96%
Các bạn có thể xem toàn bộ source code của bài viết tại đây
Blog Tự học Machine Learning
