Top 10 thư viện Python tốt nhất cho Data Scientist nửa đầu năm 2019
Khi Python ngày càng nhận được nhiều sự quan tâm của cộng đồng Data Science trong những năm gần đây, tôi đã muốn tổng hợp cho các data scientists và engineers những thư viện được sử dụng nhiều nhất, dựa trên kinh nghiệm làm việc của bản thân. Và vì tất cả các thư viên đều là nguồn ...

Khi Python ngày càng nhận được nhiều sự quan tâm của cộng đồng Data Science trong những năm gần đây, tôi đã muốn tổng hợp cho các data scientists và engineers những thư viện được sử dụng nhiều nhất, dựa trên kinh nghiệm làm việc của bản thân.
Và vì tất cả các thư viên đều là nguồn mở, nên chúng tôi đã thêm các commits, số lượng các contributors và các chỉ số khác từ Github với vai trò là các chỉ số proxy thể hiện mức độ nổi tiếng của thư viện đó.
1. NumPy (Commits: 15980, Contributors: 522)
Khi bắt đầu giải quyết task về khoa học bằng Python, tập hợp phần mềm được thiết kế riêng cho scientific computing trong Python sẽ không thể không hỗ trợ SciPy Stack của Python (đừng nhầm lẫn với thư viện SciPy – là 1 phần của stack này, và cộng đồng của stack này). Tuy nhiên, stack này khá rộng, có hơn cả tá thư viện trong nó và chúng ta thì lại muốn tập trung vào các core packages (đặc biệt là những packages quan trọng nhất).
Package cơ bản nhất, khi computation stack về khoa học được xây dựng là NumPy (viết tắt của Numerical Python), cung cấp rất nhiều tính năng hữu ích cho các phần operations trong n-arrays & matrics trong Python. Thư viện này cung cấp khả năng vector hóa các vận hành về toán trong type array NumPy, giúp cải thiện hiệu suất và theo đó là tốc độ execution.
2. SciPy (Commits: 17213, Contributors: 489)
SciPy là 1 thư viện phần mềm cho engineering và khoa học. Một lần nữa bạn cần phải hiểu sự khác biệt giữa SciPy Stack và thư viện SciPy. SciPy gồm các modules cho đại số tuyến tính, optimization, tích hợp và thống kế. Chức năng chính của thư viện SciPy được xây dựng trên NumPy, và arrays của nó sẽ tận dụng tối đa NumPy. Nó mang đến rất nhiều hoạt động hữu ích liên quan đến số như tích hợp số, optimization… qua các submodules chuyên biệt. Các hàm trong tất cả các submodules của SciPy đều được document tốt.
3. Pandas (Commits: 15089, Contributors: 762)
Pandas là 1 package Python được thiết kế để làm việc với dữ liệu đơn giản, trực quan, được “gắn nhãn” và có liên hệ với nhau. Pandas là công cụ hoàn hảo để tinh chỉnh và làm sạch dữ liệu. Pandas được thiết kế hỗ trợ cho các thao tác, tập hợp và visualize dữ liệu.
Có 2 data structure chính trong thư viện này:
“Series” — 1 chiều
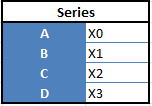
“Data Frames”, 2 chiều
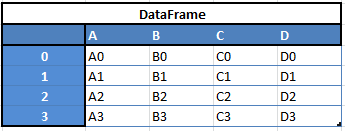
Ví dụ, khi muốn nhận Dataframe mới 2 loại structure này, bạn sẽ nhận DF bằng cách nối 1 hàng đơn với 1 DataFrame bằng cách đem tới 1 Series:
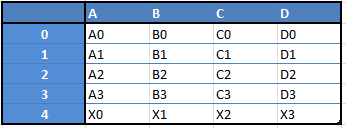
Danh sách những thứ bạn có thể làm với Pandas:
- Dễ dàng xóa và thêm cột từ DataFrame
- Chuyển data structures đến các objects DataFrame
- Xử lý các data bị mất, như NaNs
- Khả năng bhóm lại theo chức năng
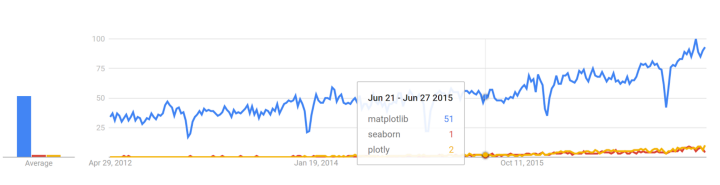
Lịch sử Google Trends
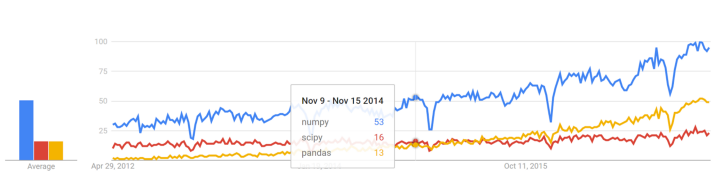
trends.google.com
Lịch sử pull requests của GitHub
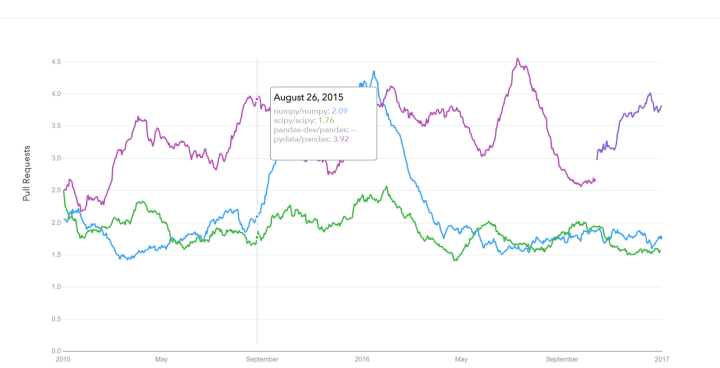
datascience.com/trends
4. Matplotlib (Commits: 21754, Contributors: 588)
Một core package của SciPy Stack và 1 thư viện Python khác được xây dựng riêng cho việc generation các visualizations mạnh mẽ, đơn giản là Matplotlib. Matplotlib là 1 phần của phần mềm giúp cho Python (cùng với sự hỗ trợ của NumPy, SciPy và Pandas) trở thành đối thủ nổi bật với các công cụ khoa học như MatLab hoặc Mathematica.
Tuy nhiên, thư viện này ở cấp độ thấp, đồng nghĩa là bạn sẽ cần phải viết nhiều code hơn để tiếp cận các cấp độ visualization cao cấp và bạn sẽ phải nỗ lực hơn so với khi sử dụng các công cụ cấp cao, tuy nhiên nỗ lực này là hoàn toàn xứng đáng.
Chỉ cần nỗ lực 1 chút, bạn có thể tạo được các visualization bất kì:
- Line plots;
- Scatter plots;
- Bar charts và Histograms;
- Pie charts;
- Stem plots;
- Contour plots;
- Quiver plots;
- Spectrograms.
Có rất nhiều công cụ để tạo nhãn, lưới, các biểu tượng/ kí hiệu/ chú giải và rất nhiều yếu tố format khác với Matplotlib. Về cơ bản, mọi thứ đều có thể custom được.
Thư viện này còn được rất nhiều platform hỗ trợ và tận dụng các GUI kít khác nhau để mô tả các visualizations kết quả. Thay đổi các IDEs (như IPython) sẽ hỗ trợ chức năng của Matplotlib.
Có vài thư viện bổ sung giúp việc visualization trở nên dễ dàng hơn.
5. Seaborn (Commits: 1699, Contributors: 71)
Seaborn hầu như tập trung vào việc visualization của các models thống kê; các visualizations như thế gồm heat maps tổng hợp dữ liệu nhưng vẫn mô tả được toàn bộ mức độ phân tán. Seaborn được phát triển dựa trên Matplotlib.
6. Bokeh (Commits: 15724, Contributors: 223)
Một thư viện visualization cực hay khác là Bokeh, hướng đến các visualization tương tác. Trái ngược với thư viện trước, Bokeh hoàn toàn độc lập so với Matplotlib. Bokeh tập trung chính vào tính tương tác và nó tạo các presentations qua các hệ điều hành hiện đại theo style của Data-Driven Documents (d3.js).
7. Plotly (Commits: 2486, Contributors: 33)
Plotly là toolbox cho web để xây dựng các visualizations, APIs được xây dựng bằng vài ngôn ngữ lập trình (như Python chẳng hạn). Có rất nhiều graphics mạnh mẽ, sáng tạo trên trang plot.ly. Để sử dụng Plotly, bạn sẽ cần set up API key riêng. Các graphics sẽ được xử lý phía server và được post lên internet, tuy nhiên vẫn có cách để ngăn việc này.
Lịch sử Google Trends
trends.google.com
Lịch sử pull requests của Github
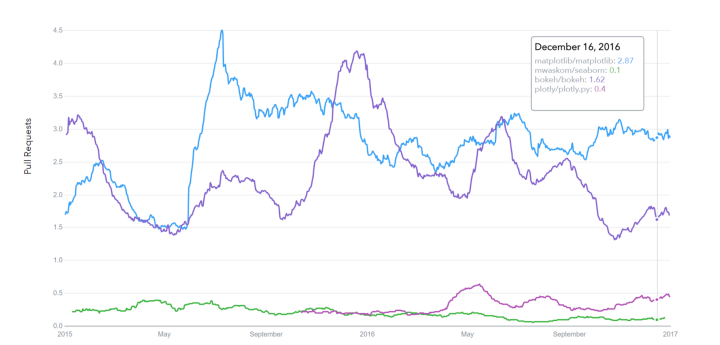
datascience.com/trends
8. SciKit-Learn (Commits: 21793, Contributors: 842)
Scikits là các packages bổ sung của SciPy Stack được thiết kế cho các chức năng chuyên biêt như xử lý ảnh và hỗ trợ Machine Learning. Riêng với mảng Machine Learning, một trong những ưu điểm nổi bật của các packages này là scikit-learn. Package được xây dựng trên nền tảng của SciPy và tận dụng các operations về toán.
Scikit-learn có giao diện đơn giản, nhất quán, exposes a concise and consistent interface to the common machine learning algorithms, hỗ trợ việc mang Machine Learning vào các hệ thống production trở nên đơn giản hơn. Thư viện này bao gồm các code chất lượng và documentation hay, dễ sử dụng, hiệu suất cao, là chuẩn mực thực tế cho xây dựng Machine Learning bằng Python.
Deep Learning — Keras / TensorFlow / Theano
Liên quan đến Deep Learning, 1 trong những thư viện nổi bật và tiện ích dành cho Python là Keras, có thể hoạt động trên nền tảng của TensorFlow hoặc Theano.
Xem chi tiết bên dưới.
9. Theano. (Commits: 25870, Contributors: 300)
Theano là package Python định dạng các arrays đa chiều tương tự như NumPy, đi kèm với các operation về toán và expressions. Thư viện này được compiled, chạy hiệu quả trên tất cả các architectures. Do đội ngũ Machine Learning của Université de Montréal, Theano được sử dụng chính cho các hoạt động liên quan đến Machine Learning.
Lưu ý là Theano tích hợp với NumPy ở mức độ operation cấp thấp. Thư viện này cũng tối ưu hóa khả năng sử dụng GPU & CPU, giúp cho hiệu năng của computation thiên về data nhanh chóng hơn.
Hiệu quả và sự ổn định cũng mang đến những kết quả chính xác hơn, dù đó là những giá trị rất nhỏ như computation của log(1+x) sẽ cho ra kết quả chính xác đối với các giá trị nhỏ nhất của x.
10. TensorFlow. (Commits: 16785, Contributors: 795)

Do các developer của Google phát triển, TensorFlow là thư viện nguồn mở của graphs computations thuộc luồng dữ liệu, thích hợp với Machine Learning. TensorFlow đáp ứng các requirement cao cấp trong môi trường Google để train Neural Networks và thư viện kế nhiệm của DistBelief – 1 hệ thống Machine Learning dựa trên Neural Networks. Tuy nhiên, TensorFlow không chỉ sử dụng cho mục đích khoa học trong Google mà có thể áp dụng trong các dự án thực tế.
Tính năng quan trọng của TensorFlow is hệ thống nút đa layer, cho phép huấn luyện các neural networks trên datasets lớn 1 cách nhanh chóng, hỗ trợ khả năng nhận diện giọng nói và định vị vật thể trong ảnh của Google.
Tóm lại,
Trên đây là những thư viện được rất nhiều data scientist và engineers đánh giá cao. Bên dưới là biểu đồ chi tiết về hoạt động trên Github của mỗi thư viện:
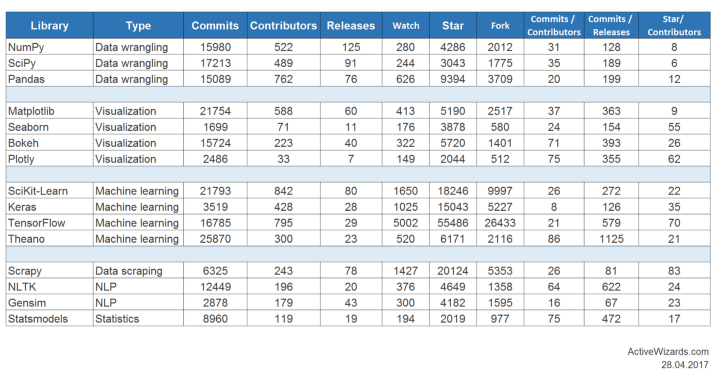
Dĩ nhiên, danh sách này vẫn chưa hoàn thiện và còn rất nhiều thư viện, framewoks đáng lưu ý khác. Chẳng hạn như các packages khác nhau của SciKit tập trung vào các domains riêng biệt như SciKit-Image làm việc với hình ảnh.

Hội nghị VIETNAM CLOUD & DATACENTER 2019CONVENTION sẽ chính thức diễn ra vào tháng Hai năm 2019 tại toà nhà InterContinental Hà Nội. Là điểm dừng thứ 2 – ngay sau Hội nghị tại Seoul, Hàn Quốc – trong chuỗi Hội nghị Công nghệ Cloud & Datacenter trong khu vực Đông Nam Á, tiếp nối thành công của Hội nghị gần nhất diễn ra tại Malaysia vào tháng 11 vừa qua, giờ đây điểm sáng đã nhường lại cho Việt Nam.
Ước tính sẽ thu hút đến hơn 300 chuyên gia và “lão làng” ngành Cloud và Data Center tại Việt Nam và trong khu vực Đông Nam Á.
* Đơn vị tổ chức: WMedia
* Thời gian: Ngày 21 Tháng Hai năm 2019, 8AM – 4PM
* Địa điểm: InterContinental Hanoi Landmark 72, Toà nhà Keangnam Hanoi Landmark Tower, Lô E6, Cầu Giấy, Mễ Trì, Từ Liêm, Hà Nội
Đừng bỏ lỡ cơ hội nắm bắt xu hướng mới về hybrid cloud, tối ưu hoá data center và xây dựng nên một cơ sở hạ tầng IT linh hoạt và dễ tận dụng tối ưu, lần đầu tiên tại Việt Nam! Hãy đăng kí ngay hôm nay để giữ lấy tấm vé tham dự Hội nghị Công nghệ hàng đầu Đông Nam Á này & Hoàn toàn MIỄN PHÍ!

