Top-down learning path: Machine Learning for programmers
Late to the party? Yes. But is it always too late to start? Never! For last year and a half, I have seen devs around me riding on the hype train of machine learning and engage in conversation with kind of ideas which could as well get drafted to next script for Back to the future ...
Late to the party?
Yes.
But is it always too late to start?
Never!
For last year and a half, I have seen devs around me riding on the hype train of machine learning and engage in conversation with kind of ideas which could as well get drafted to next script for Back to the future remake. When they start spitting out all these jargons about models and classifiers in conversation, I start playing Marty and crook my forehead skin. So here I am, a programmer who is interested in getting into machine learning. How do I get started in machine learning?
If I crack a book on machine learning seeking an answer to this question, I get easily discouraged. They start with definitions and move on to mathematical descriptions of concepts and algorithms of ever increasing complexity.
The traditional approach will start off with the pre-requisites such as multivariate calculus, inferential statistics and linear algebra or even try to fill your head with theory on computability or computational complexity, or even deep details of algorithms and data structures. But often it doesnt adapt to programmer's learning approach which is result oriented. I wouldn't say its totally wrong as it is kind of familiar to sceanrio where one doesnt need computer science degree to become a software engineer these days. Sure, its the hardest path but the challenge is not to lose the level of intrigue you started with until the end.
I think there are two sides to machine learning.
- Practical Machine Learning: This is about querying databases, cleaning data, writing scripts to transform data and gluing algorithm and libraries together and writing custom code to squeeze reliable answers from data to satisfy difficult and ill-defined questions. It’s the mess of reality.
- Theoretical Machine Learning: This is about math and abstraction and idealized scenarios and limits and beauty and informing what is possible. It is a whole lot neater and cleaner and removed from the mess of reality.
I find the top-down approach much better suited for engineers who are keen to get their hands dirty on practical machine learning.
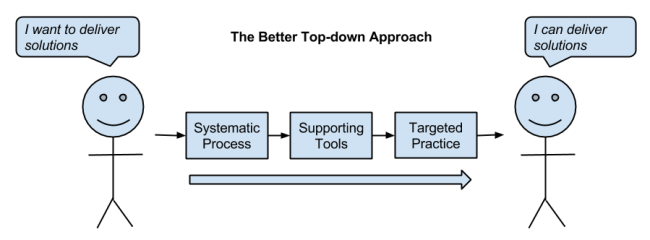
here is my findings on top-down approach that I will stick to for next six months.
Repeatable Results with a Systematic Process
A systematic approach needs to be taken when working on a machine learning problem. It's like a software project, and only good processes can make sure a high-quality result is repeatable from project to project.
- A process that will guide me from end-to-end, from problem specification to presentation or deployment of results. Like a software project, you can think you’re done, but you’re probably not. Having the end deliverable in mind from the beginning sets an unambiguous project stop condition and focuses effort.
- A process that is step-by-step so that I can always know my next goal to achieve. Not knowing what my next goal is a project killer.
- A process that guarantees solid results, e.g. better than average or good enough for the needs of the project. It is very common for projects to need good results delivered reliably with known confidence levels, not necessarily the very best accuracy possible.
- A process that is invariant to the specific tools, programming languages and algorithm fads. Tools come and go and the process must be adaptive. Given the algorithm obsession in the field, there are always new and powerful algorithms coming out of academia.
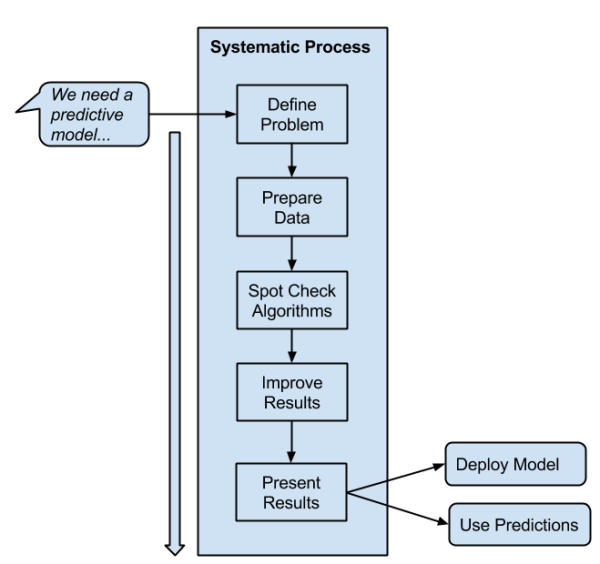
There are many great processes out there, including some older processes that you can adapt to your needs.
- Knowledge Discovery in Databases (KDD)
- CRISP-DM
- OSEMN
Mapping Right Tools onto Your Process
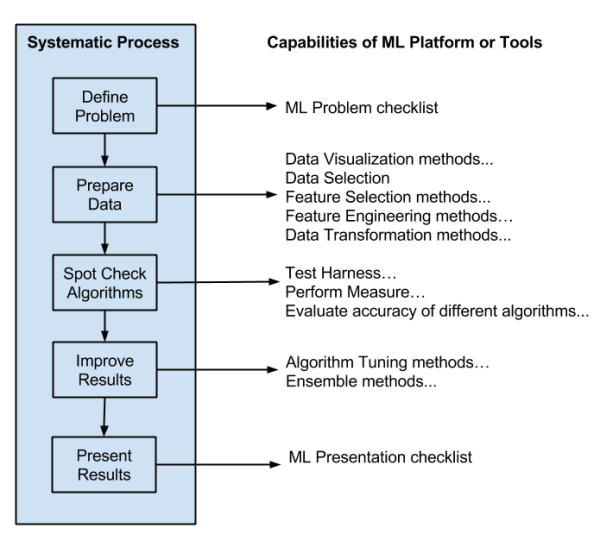
Machine learning tools and libraries change frequently, but at any single point in time I have to use something that corresponds to chosen process of delivering results. There are recommended tools as following :
- One-off predictive model: The Weka platform, because I can load a CSV, design an experiment and get the best model in no time at all without a line of programming (see the mapping below onto the process).
- Embedded predictive model: Python with scikit-learn, because I can develop the model in the same language in which it is deployed. IPython is a great way to demonstrate your pipeline and results to the broader team. A MLaaS is also an option for bigger data.
- Deep-dive model: R with the caret package, because I can quickly and automatically try a lot of state-of-the-art models and devise more and more elaborate feature selection, feature engineering and algorithm tuning experiments using the whole R platform. In reality, these three tools bleed across the three scenarios depending on the specifics of a situation.
Finally, I would like to say is, this approach is tailored for developers. Next I will document my journey on few mistakes programmers make and how to avoid them. Stricking to this process in the long run will help me grow my knowledge in Machine learning. Lets do it. (go)
