Discover Meteor - Chương 7
Trong chương này bạn sẽ: Hiểu được cách thức hoạt động của publications và subscriptions. Học xem gói Autopublish mặc định làm gì. Tìm hiểu thêm một vài ví dụ về các mẫu publication. Publication và Subscription là một trong những khái niệm quan trọng và cơ bản của Meteor, tuy nhiên có ...
Trong chương này bạn sẽ:
- Hiểu được cách thức hoạt động của publications và subscriptions.
- Học xem gói Autopublish mặc định làm gì.
- Tìm hiểu thêm một vài ví dụ về các mẫu publication.
- Publication và Subscription là một trong những khái niệm quan trọng và cơ bản của Meteor, tuy nhiên có thể khó cho việc ghi nhớ khi bạn mới chỉ bắt đầu.
Điều này có thể dẫn đến những hiểu nhầm, ví dụ như là Meteor không an toàn, hoặc là ứng dụng viết bởi Meteor không thể làm việc được với những hệ thống nhiều dữ liệu.
Một trong những lý do mà người ta thấy rằng những khái niệm này rối loạn lúc đầu chính bởi "phép thuật" mà Meteor làm cho chúng ta. Mặc dù thứ phép thuật này về cơ bản là rất hữu dụng, nó có thể không rõ ràng về thứ thực sự diễn ra sau màn hình (như những gì phép thuật thường làm). Bởi vậy, hãy cùng cởi bỏ các lớp vỏ của phép thuật này và cố gắng hiểu rõ điều gì đang diễn ra.
Những ngày trước đây
Nhưng đầu tiên, hãy cùng chúng tôi nhìn lại những ngày ban đầu của năm 2011 khi mà Meteor vẫn còn chưa ở đó. Giả sử rằng bạn đang xây dựng một ứng dụng đơn giản với Rails. Khi người dùng bước vào trang web của bạn, phía client (ví dụ như là trình duyệt của bạn) gửi yêu cầu tới ứng dụng, thứ đang chạy trên server.
Công việc đầu tiên của ứng dụng là tìm ra xem dữ liệu bạn muốn thấy. Nó có thể là trang thứ 12 của kết quả tìm kiếm, thông tin về người dùng tên là Mary, 20 đoạn tweet gần nhất của Bob, và hơn thế nữa. Bạn có thể tưởng tượng nó như là một người nhân viên cửa hàng bán sách duyệt những gian hàng để tìm ra cuốn mà bạn đã hỏi.
Một khi dữ liệu đúng đã được chọn, công việc tiếp theo của ứng dụng là dịch những dữ liệu đó thành dạng HTML đẹp, thân thiện với con người (hoặc JSON trong trường hợp là API).
Trong phép ẩn dụ về hiệu sách, nó chính là việc bọc lại cuốn sách bạn đã mua và cho vào một cái túi đẹp. Đây là phần "View" (hiển thị), một phần trong mô hình Model-View-Controller nổi tiếng.
Cuối cùng, ứng dụng sẽ lấy đoạn mã HTML đó và gửi đến cho trình duyệt. Công việc của ứng dụng vậy là xong, và mọi thứ đã nằm ngoài bàn tay mà server có thể kiểm soát được, nó giờ chỉ có thể nghỉ ngơi với một cốc bia chẳng hạn và chờ đợi yêu cầu tiếp theo.
Phương pháp của Meteor
Hãy cùng nhau nhìn lại điều gì đã khiến Meteor trở nên đặc biệt như vậy. Như chúng ta đã thấy, điều đổi mới ở Meteor chính là trong khi ứng dụng Rails chỉ chạy trên server, thì ứng dụng Meteor lại bao gồm cả thành phần ở phía client để chạy dưới client (trình duyệt web).
Điều đó cũng giống như là nhân viên hiệu sách đó không chỉ tìm đúng cuốn sách cho bạn, mà còn theo bạn về nhà để đọc nó vào buổi tối (điều này thực sự chúng ta sẽ thán phục mặc dù nghe có vẻ hơi kinh dị).
Cấu trúc này giúp cho Meteor có thể làm được nhiều thứ hay ho, một trong những thứ đó là cái mà Meteor gọi là cơ sở dữ liệu ở mọi nơi. Nói một cách đơn giản, Meteor lấy một tập con dữ liệu của bạn và sao chép nó tới client.
Điều này có hai hàm ý lớn: đầu tiên, thay vì gửi HTML code tới client, ứng dụng Meteor sẽ gửi dữ liệu thực, nguyên dạng và để cho client tự quyết định làm gì với nó dữ liệu mắc trên dây). Thứ hai, bạn sẽ có thể truy xuất và thay đổi dữ liệu đó tức thời mà không cần phải chờ một chuyến đi lại với server sự điều chỉnh ngầm).
Publishing (xuất bản)
Một cơ sở dữ liệu của ứng dụng có thể chứa tới hàng chục nghìn dữ liệu, một số trong chúng có thể là dữ liệu mật và nhạy cảm. Bởi vậy hiển nhiên là chúng ta không nên phản ánh toàn bộ dữ liệu cho client, vì lý do bảo mật và khả năng làm tăng quy mô ứng dụng.
Bởi vậy, chúng ta cần một thứ gì đó để cho Meteor biết là tập hợp con nào của dữ liệu có thể gửi tới client, và chúng ta hoàn thành điều này bằng cách dùng publication.
Hãy cùng quay lại với Microscope. Tại đây tất cả dữ liệu bài viết của chúng ta nằm trong cơ sở dữ liệu:

Mặc dù phải thú thực rằng tính năng đó không thực sự tồn tại trong Microscope, chúng ta hãy tưởng tượng rằng một vài bài viết được đánh dấu với ngôn ngữ lăng mạ. Mặc dù chúng ta muốn giữ chúng trong cơ sở dữ liệu, những bài viết này không nên được hiện hữu đối với người dùng (ví dụ như là không nên được gửi cho client).
Nhiệm vụ đầu tiên của chúng ta là nói cho Meteor biết, dữ liệu nào chúng ta thực sự muốn gửi cho client. Chúng ta sẽ bảo Meteor rằng chỉ dữ liệu không bị đánh dấu mới được xuất bản (publish):

Đây là đoạn code tương ứng, được đặt ở bên server:
// on the server
Meteor.publish('posts', function() {
return Posts.find({flagged: false});
});
Điều này đảm bảo rằng client sẽ không có cách nào truy cập đến dữ liệu bị đánh dấu. Đây chính là cách làm cho ứng dụng Meteor bảo mật: chắc chắn rằng chỉ xuất bản dữ liệu mà bạn muốn người dùng hiện tại truy cập đến.
DDP
Một cách cơ bản, bạn có thể nghĩ publication/subscription như một hệ thống đường hầm chuyển dữ liệu từ collection phía server (nguồn) tới collection phía client (đích).
Giao thức được dùng cho đường hầm đó gọi là DDP (viết tắt của Distributed Data Protocol - giao thức dữ liệu phân tán). Để học thêm về DDP, bạn có thể theo dõi bài nói chuyện này từ hội nghị thời gian thực bởi Matt DeBergalis (một trong những người sáng lập của Meteor), hoặc screencast này bởi Chris Mather, nó sẽ dẫn suy nghĩ của bạn tới khái niệm này cụ thể hơn một chút.
Subscribing (đăng theo dõi)
Mặc dù chúng ta muốn mọi bài viết không bị đánh dấu hiện hữu với client, chúng ta không thể gửi đồng loạt cả nghìn bài viết một lúc. Chúng ta cần một cách để client đặc tả xem tập hợp con dữ liệu nào họ muốn tại một thời điểm nào đó, và đó chính là nơi mà subscriptions ra mắt.
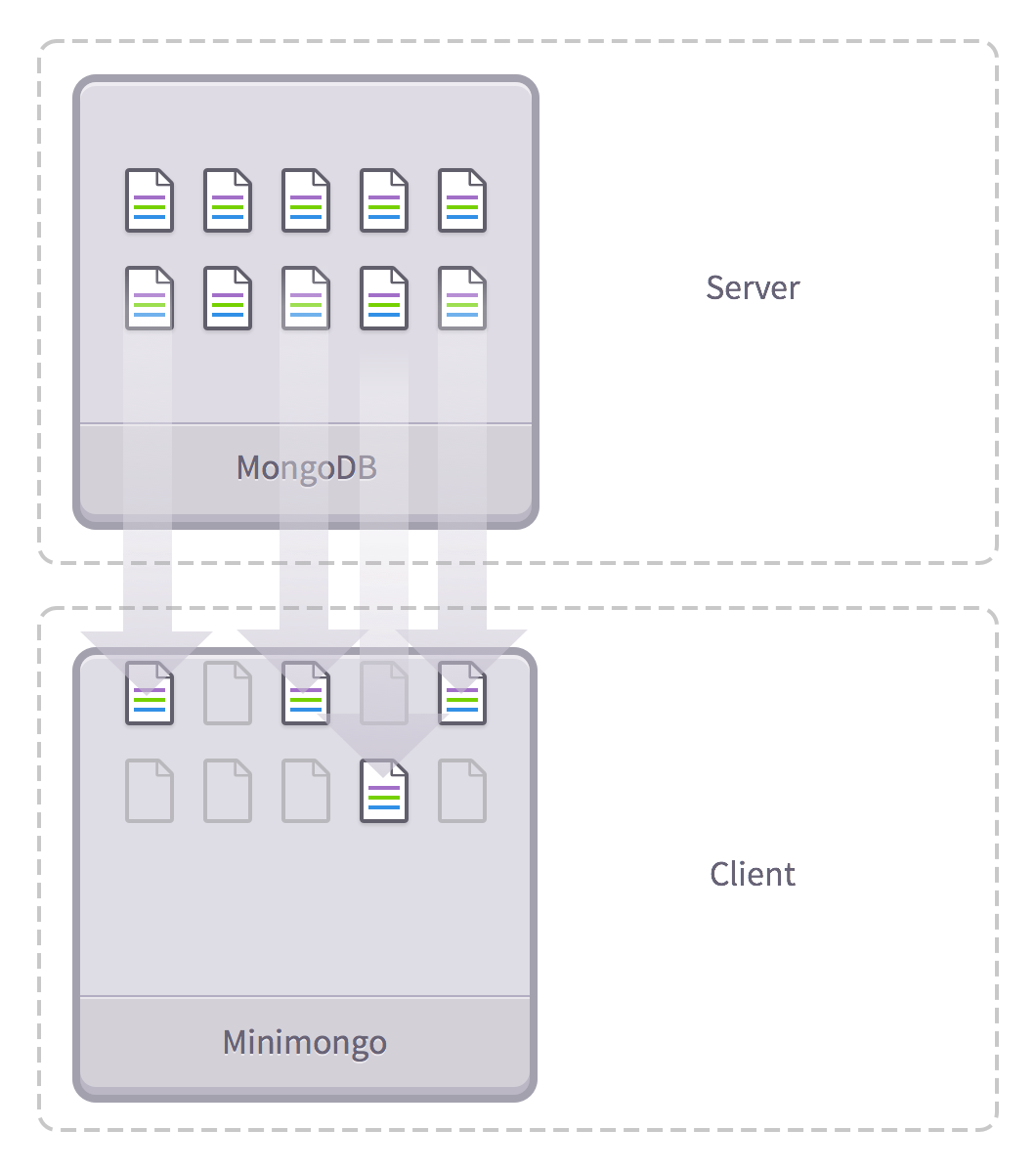
Những dữ liệu mà bạn đăng theo dõi sẽ được phản ánh tới client bởi Minimongo, cái mà chúng ta biết đến là sự cài đặt cho MongoDB của Meteor ở phía client.
Ví dụ, giả sử chúng ta đang cần tra cứu trang thông tin cá nhân của Bob Smith, và chỉ muốn hiển thị bài viết của anh ta.

Đầu tiên, chúng ta sẽ sửa chữa lại phần xuất bản để thêm vào tham số:
// on the server
Meteor.publish('posts', function(author) {
return Posts.find({flagged: false, author: author});
});
Và sau đó chúng ta sẽ định nghĩa tham số đó khi chúng ta đăng theo dõi tới bản xuất bản đó trong ứng dụng từ code phía client:
// on the client
Meteor.subscribe('posts', 'bob-smith');
Đây là cách mà bạn làm cho một ứng dụng Meteor có thể mở rộng được ở phía client: thay vì đăng theo dõi tất cả dữ liệu khả dụng, chỉ cho những phần nào mà hiện tại đang cần đến. Bằng cách này, bạn sẽ tránh việc làm bộ nhớ trình duyệt bị quá tải mặc cho dữ liệu phía server của bạn có lớn tới mức nào.
Tìm kiếm
Hiện tại bài viết của Bob trải rộng ra nhiều mục (ví dụ như: “JavaScript”, ”Ruby”, and ”Python”). Mặc dù chúng ta có thể vẫn muốn nạp tất cả bài viết của Bob vào trong bộ nhớ, nhưng chúng ta chỉ muốn hiển thị những thứ trong mục “JavaScript” ngay tại thời điểm này. Đây là lúc “finding” (tìm kiếm) xuất hiện.

Giống như chúng ta đã làm với server, chúng ta sẽ sử dụng hàm Posts.find() để chọn ra những tập con dữ liệu:
// on the client
Template.posts.helpers({
posts: function(){
return Posts.find({author: 'bob-smith', category: 'JavaScript'});
}
});
Giờ chúng ta đã hiểu rõ được nhiệm vụ của xuất bản và đăng theo dõi, chúng ta sẽ đào sâu hơn và duyệt lại một số khuôn mẫu cài đặt.
Autopublish
Nếu bạn tạo một dự án Meteor hoàn toàn mới (ví dụ như bằng việc dùng meteor create), nó sẽ tự động dùng gói autopublish mặc định. Để bắt đầu, hãy cùng nhau xem nó thực sự làm gì.
Mục đích của autopublish là để giúp cho việc bắt đầu code với Meteor được dễ dàng, và nó làm điều đó bằng cách phản ánh tất cả dữ liệu từ server tới client, do đó thực thi công việc xuất bản và đăng theo dõi cho bạn.
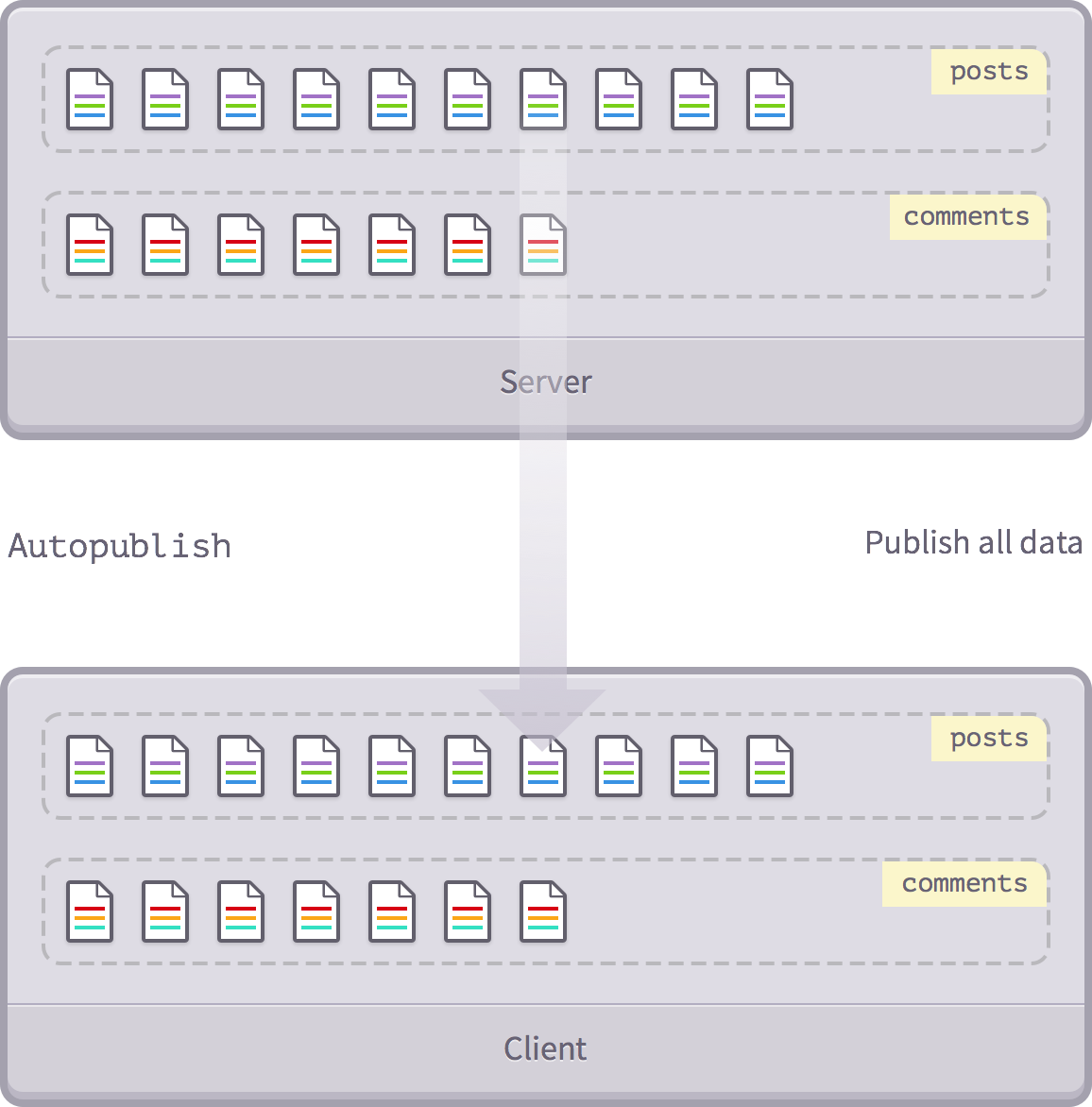
Nó hoạt động như thế nào? Giả sử bạn có một collection gọi là 'posts' ở phía server. Sau đó autopublish sẽ tự động gửi mỗi bài viết nó tìm ra được trong collection posts của Mongo sang một collection gọi là 'posts' ở phía client (giả định là đã có).
Bởi vậy nếu bạn đang sử dụng autopublish, thì bạn không cần phải nghĩ về xuất bản (publication). Dữ liệu tồn tại khắp nơi, và mọi thứ rất đơn giản. Dĩ nhiên, có những vấn đề hiển nhiên với việc sao chép toàn bộ dữ liệu của database để cache trong mỗi máy người dùng.
Vì lý do này, autopublish chỉ phù hợp khi bạn mới bắt đầu, và chưa biết gì về publication.
Xuất bản toàn bộ Collections
Một khi đã xóa bỏ autopublish, bạn sẽ sớm nhận ra là dữ liệu đã bị loại bỏ khỏi client. Một cách đơn giản để mang nó trở lại là đơn giản sao chép lại những thứ mà autopublish đã làm, và xuất bản một collection trong thực thể của nó. Ví dụ:
Meteor.publish('allPosts', function(){
return Posts.find();
});
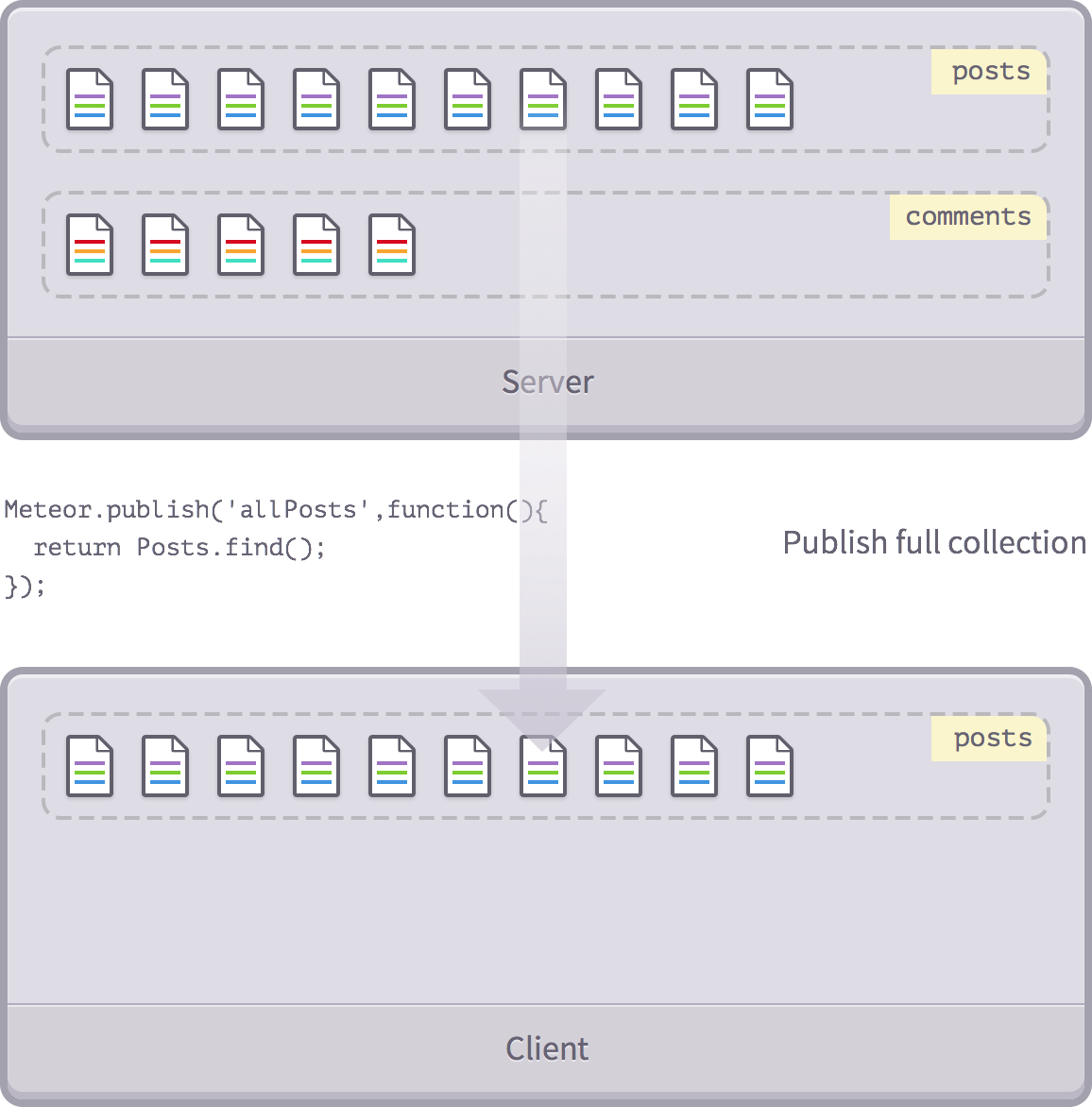
Chúng ta vẫn đang xuất bản toàn bộ dữ liệu, nhưng dù sao thì chúng ta cũng quản lý được collection nào chúng ta muốn xuất bản hay là không. Trong trường hợp này, chúng ta đang xuất bản collection Posts chứ không phải là Comments.
Xuất bản một phần Collection
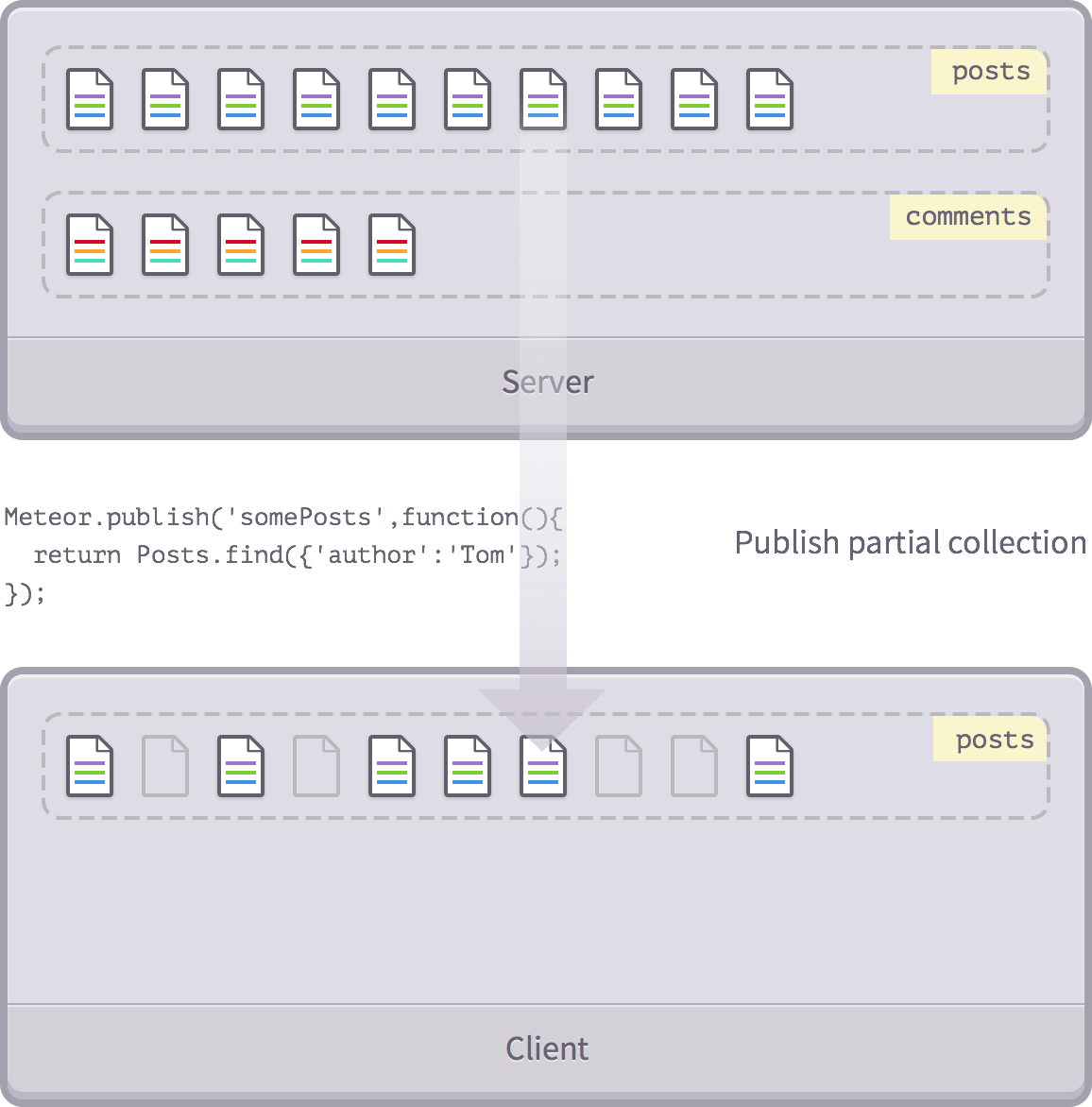
Cấp độ tiếp theo là xuất bản chỉ một phần của collection. Ví dụ như chúng ta chỉ muốn bài viết thuộc về một người dùng cụ thể:
Meteor.publish('somePosts', function(){
return Posts.find({'author':'Tom'});
});
Phía sau màn hình
Nếu bạn đã đọc về (tài liệu publication Meteor), có lẽ bạn đã bị làm quá sức bằng việc nói về sử dụng added() và ready() để thiết lập tính năng cho bản ghi phía client, và đã chiến đấu để tạo hình nó với ứng dụng Meteor mà bạn chưa từng nhìn thấy những method đó bao giờ.
Lý do là Meteor cung cấp một tiện ích rất quan trọng: method _publishCursor(). Bạn cũng chưa từng thấy nó bao giờ? Có lẽ không trực tiếp, nhưng nếu bạn trả về một con trỏ (ví dụ như Posts.find({'author':'Tom'})) trong hàm publish, nó chính là cái mà Meteor đang sử dụng.
Khi Meteor đã nhìn thấy publication của somePosts được trả về con trỏ, nó gọi tới _publishCursor() để -- như bạn đã đoán -- xuất bản con trỏ đó một cách tự động.
Đây là những gì _publishCursor() đã làm:
- Kiểm tra collection phía server
- Lấy toàn bộ dữ liệu phù hợp từ con trỏ và gửi tới collection có cùng tên ở phía client. (Dùng hàm .added() để làm điều đó).
- Mỗi khi có một dữ liệu mới được thêm vào, xóa bỏ hoặc thay đổi, nó gửi những thay đổi này tới collection phía client. (dùng .observe() với con trỏ và .added(), .changed() và removed() để làm điều này).
Như ví dụ ở trên, chúng ta có thể chắc chắn rằng người dùng chỉ có những bài viết mà họ quan tâm đến (bài viết được tạo bởi Tom) hiện hữu với họ trong cache của client.
Xuất bản một phần thuộc tính
Chúng ta vừa thấy làm thế nào để xuất bản một vài bài viết, nhưng chúng ta có thể cắt mỏng hơn nữa! Hãy cùng xem làm thế nào để chỉ publish một vài thuộc tính đặc biệt.
Như lúc trước, chúng ta dùng find() để trả về một con trỏ, nhưng lần này chúng ta thêm vào những trường cụ thể:
Meteor.publish('allPosts', function(){
return Posts.find({}, {fields: {
date: false
}});
});
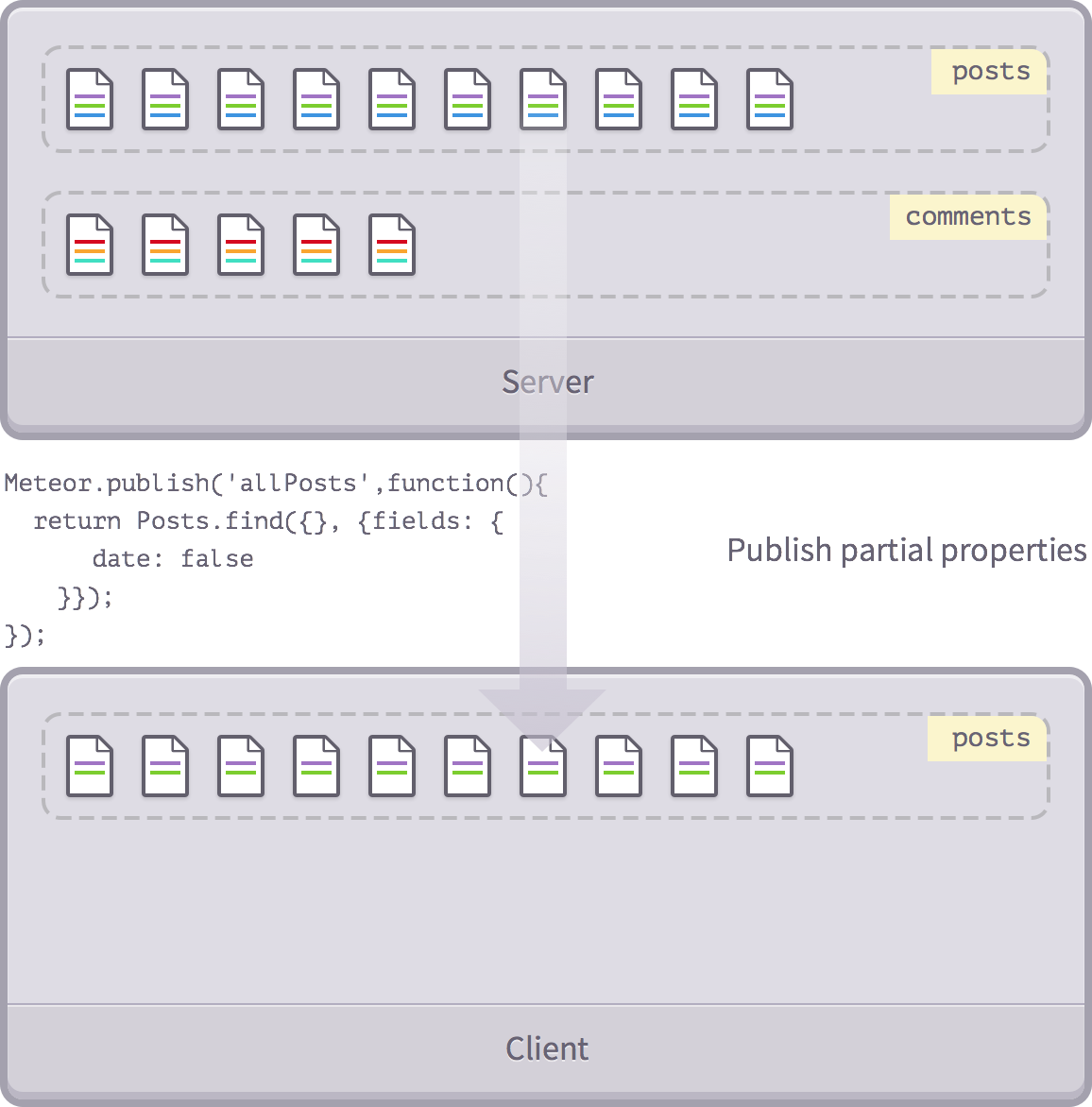
Dĩ nhiên, chúng ta có thể kết nối cả hai kỹ thuật. Ví dụ, nếu bạn muốn trả về tất cả bài viết bởi Tom trong khi để mặc những dữ liệu còn lại, chúng ta sẽ viết:
Meteor.publish('allPosts', function(){
return Posts.find({'author':'Tom'}, {fields: {
date: false
}});
});
Kết luận
Chúng ta vừa tìm hiểu về publish từng thuộc tính trong tất cả dữ liệu của mỗi collection (với autopublish) để xuất bản chỉ một vài thuộc tính hoặc một vài dữ liệu của một vài collection.
Nó bao trùm phần cơ bản về những gì bạn có thể làm được với publication của Meteor, và những kỹ thuật đơn giản này có thể đảm bảo cho phần lớn các use case.
Đôi khi, bạn cũng cần phải đi xa hơn bằng cách kết hợp, liên kết, hoặc hợp nhất các collection. Chúng ta sẽ tìm hiểu về điều đó trong chương tiếp theo!
