Feature Engineering (Phần 4): Phương pháp xử lý truyền thống với dữ liệu dạng văn bản (Text Data)
Xin chào mọi người, trong phần trước của series mình đã giới thiệu với mọi người một số phương pháp xử lý với dữ liệu dạng phân loại (Categorical Data) . Trong phần tiếp theo này chúng ta sẽ tiếp tục với series Understanding Feature Engineering của Dipanjan (DJ) Sarkar để tìm hiểu về một số phương ...
Xin chào mọi người, trong phần trước của series mình đã giới thiệu với mọi người một số phương pháp xử lý với dữ liệu dạng phân loại (Categorical Data). Trong phần tiếp theo này chúng ta sẽ tiếp tục với series Understanding Feature Engineering của Dipanjan (DJ) Sarkar để tìm hiểu về một số phương pháp xử lý truyền thống với dạng dữ liệu văn bản (Text Data).
Giới thiệu
Trong hai phần trước chúng ta đã đề cập đến các phương pháp xử lý cho 2 dạng dữ liệu có cấu trúc là: dữ liệu dạng số liên tục (continuous numeric data) và dữ liệu dạng phân loại (categorical data). Trong phân tiếp theo này, chúng ta sẽ xem xét cách làm việc với dữ liệu dạng văn bản, đây chắc chắn là một trong những dạng dữ liệu phi cấu trúc phong phú nhất mà bạn sẽ thường xuyên gặp phải. Dữ liệu văn bản thường bao gồm các tài liệu, có thể là dạng các từ, câu, thậm chí là các đoạn văn bản dài ngắn khác nhau. Dữ liệu dạng văn bản là dạng dữ liệu phi cấu trúc (không có các cột được định nghĩa rõ ràng) và các dữ liệu dạng văn bản thường rất nhiễu khiến các phương pháp học máy khó có thể làm việc trực tiếp trên dữ liệu thô. Do đó, trong bài viết này, chúng ta sẽ tiếp cận thực tes để tìm hiểu một số phương pháp phổ biến và hiệu quả để trích xuất các đặc trưng có ý nghĩa từ dữ liệu dạng văn bản. Những đặc trưng này sau đó có thể sử dụng trong việc xây dựng mô hình học máy hoặc mô hình học sâu một cách dễ dàng.
Sự cần thiết
Như chúng ta đã biết, feature engineering được gọi là các công thức bí mật để tạo ra các mô hình học máy hiệu suất cao hơn và tốt hơn. Chỉ cần có một đặc trựng tuyệt vời là bạn có thể dành được chiến thắng trong các challenge của Kaggle. Tầm quan trọng của các kỹ thuật xử lý dữ liệu thậm chí còn quan trọng hơn đối với dữ liệu dạng văn bản, bởi vì như đã nhắc đến ở trên, dữ liệu dạng văn bản là dữ liệu không có cấu trúc và các thuật toán học máy hầu như không thể làm việc được với dữ liệu thô, bởi vậy chúng ta cần chuyển đổi văn bản thành các dạng biểu diễn số học mà thuật toán học máy có thể hiểu được. Ngay cả với sự ra đời của các kỹ thuật xử lý tự động thì bạn vẫn cần hiểu các khái niệm cốt lõi đằng sau các kỹ thuật trước khi áp dụng chúng trong các mô hình black box. Hay luôn nhớ rằng, nếu bạn được tặng một hộp công cụ để sửa chữa nhà cửa, bạn nên biết khi nào nên sử dụng máy khoan và khi nào nên sử dụng búa!
Dữ liệu dạng văn bản là gì
Trước tiên, chúng ta cần phải có một ý tưởng hợp lý và dữ liệu dạng văn bản. Hãy nhớ rằng bạn luôn có thể có dữ liệu dạng văn bản ở dạng thuộc tính dữ liệu có cấu trúc, thường là văn bản ở dạng những đặc trưng của dữ liệu dạng phân loại (Categorical Data).

Tuy nhiên, trong trường hợp này chúng ta đang nói về văn bản tự do dưới dạng từ, cụm từ, câu hoặc toàn bộ đoạn văn. Về cơ bản, chúng ta có một số cấu trục cú pháp như từ tạo ra cụm từ, cụm từ tạo thành câu, câu tạo thành đoạn văn. Tuy nhiện, không có cấu trúc vốn có nào cho dữ liệu dạng văn bản vì bạn có thể có nhiều từ có thể khác nhau giữa các đoạn dữ liệu và mỗi câu cũng sẽ có độ dài thay đổi. Và bài viết này chính là một ví dụ cho dữ liệu dạng văn bản.
Feature Engineering cho dữ liệu dạng văn bản
Bây giờ, chúng ta hãy cùng xem xét một số phương pháp phổ biến và hiệu quả để xử lý dữ liệu dạng văn bản và trích xuất các đặc trưng có ý nghĩa để có thể sử dụng trong các thuật toán học máy. Xin lưu ý rằng, bạn có thể tìm thấy tất cả source code trong bài viết này từ Github của tác giả. Đầu tiên, chúng ta cùng thực hiện một số bước chuẩn bị cơ bản.
import pandas as pd import numpy as np import re import nltk import matplotlib.pyplot as plt pd.options.display.max_colawidth = 200 %matplotlib inline
Tiếp theo chúng ta hãy lấy một đoạn văn bản corpus mà chúng ta sẽ sử dụng trong bài viết này. Một corpus có thể hiểu là một tập hợp các văn bản thuộc về một hoặc nhiều đối tượng.
corpus = ['The sky is blue and beautiful.', 'Love this blue and beautiful sky!', 'The quick brown fox jumps over the lazy dog.', "A king's breakfast has sausages, ham, bacon, eggs, toast and beans", 'I love green eggs, ham, sausages and bacon!', 'The brown fox is quick and the blue dog is lazy!', 'The sky is very blue and the sky is very beautiful today', 'The dog is lazy but the brown fox is quick!' ] labels = ['weather', 'weather', 'animals', 'food', 'food', 'animals', 'weather', 'animals'] corpus = np.array(corpus) corpus_df = pd.DataFrame({'Document': corpus, 'Category': labels}) corpus_df = corpus_df[['Document', 'Category']] corpus_df

Bạn có thể thấy rằng chúng ta đã có được một vài đoạn văn bản từ những category khác nhau. Trước khi chúng ta nói về các kỹ thuật xử lý dữ liệu, như mọi khi, chúng ta cần thực hiện một số bước tiền xử lý hoặc sắp xếp lại để loại bỏ các ký tự, ký hiệu không cần thiết.
Tiền xử lý văn bản
Có rất nhiều cách khác nhau để "làm sạch" và tiền xử lý dữ liệu dạng văn bản. Dưới đây, mình nhấn mạnh một số điểm quan trọng nhất được sử dụng nhiều trong giai đoạn tiền xử lý ngôn ngữ tự nhiên (NLP).
- Xóa thẻ tags: Văn bản chúng ta gặp thường chứa nội dung không cần thiết như các thẻ HTML, không có giá trị khi phân tích. Thư viện BeautifulSoup là một công cụ tuyệt vời và cần thiết để xử lý trong trường hợp này.
- Xóa các ký tự có dấu: Trong bất kỳ văn bản nào, đặc biệt nếu bạn đang xử lý ngôn ngữ tiếng Anh, thường các bạn cần phải xử lý các ký tự có dấu. Do đó, chúng ta vần đảm bảo rằng các ký tự này cần được chuyển đổi và chuẩn hóa thành các ký tự ASCII. Một ví dụ đơn giản là chúng ta sẽ chuyển đổi ký tự é thành e.
- Biến đổi các từ viết tắt: Trong tiếng Anh, các từ viết tắt về cơ bản là phiên bản rút gọn của các từ hoặc âm tiết. Những từ viết tắt của các từ hoặc cụm từ thường được tạo ra bằng cách loại bỏ các chữ cái và âm tiết. Ví dụ như: do not -> don't, I would -> I'd. Chuyển đổi từ dạng viết tắt thành dạng đầy đủ cũng là một bước cần thiết để chuẩn hóa văn bản.
- Xóa các ký tự đặc biệt: Các ký tự đặc biệt thường là các ký tự không phải là chữ và số, thường gây "nhiễu" cho dữ liệu của chúng ta. Thông thường, regular expressions (regexes) có thể được sử dụng để xử lý vấn đề này.
- Từ gốc và ngữ pháp: Trong các ngữ cảnh khác nhau, các từ gốc thường được gắn thêm các tiền tố và hậu tố vào để đúng với ngữ pháp. Ví dụ các từ: WATCHES, WATCHING, and WATCHED. Chúng ta có thể thấy rằng chúng đều có chung từ gốc là WATCH
- Xóa các stopwords: stopwords là các từ có ít hoặc không có ý nghĩa gì đặc biệt khi xây dựng các đặc trưng. Đây thường là những từ giới từ, trợ từ có tần suất xuất hiện tương đối cao trong một văn bản thông thường ví dụ như: a, an, the... Chúng ta không có một danh sách chung tác stopwords tuy nhiên bạn có thể sử dụng thư viện nltk. Hoặc bạn cũng có thể tự xây dựng được các thư viện stopwords cho riêng ngôn ngữ bạn đang xử lý. Việc này cũng có ý nghĩa tương đối quan trọng trong xử lý ngôn ngữ tự nhiên.

Bên cạnh đó bạn cũng có thể thực hiện một số biện pháp tiêu chuẩn khác như tokenization, xóa bỏ các khoảng trắng thừa, chuẩn hóa chữ cái viết hoa, các biện pháp sửa lỗi chính tả, sửa lỗi ngữ pháp, xóa các ký tự lặp lại... Bạn có thể tham khảo source code từ notebook của tác giả.
Vì trọng tâm của bài viết này là về các kỹ thuật feature engineering nên chúng ta sẽ xây dựng một đoạn tiền xử lý văn bản hết sức đơn giản sau đây, chủ yếu tập trung vào loại bỏ các ký tự đặc biệt, xóa khoảng trắng thừa, xử lý các ký tự số, stopwords và xử lý chữ cái viết hoa.
wpt = nltk.WordPunctTokenizer() stop_words = nltk.corpus.stopwords.words('english') def normalize_document(doc): # lower case and remove special characterswhitespaces doc = re.sub(r'[^a-zA-Zs]', ', doc, re.I|re.A) doc = doc.lower() doc = doc.strip() # tokenize document tokens = wpt.tokenize(doc) # filter stopwords out of document filtered_tokens = [token for token in tokens if token not in stop_words] # re-create document from filtered tokens doc = ' '.join(filtered_tokens) return doc normalize_corpus = np.vectorize(normalize_document)
Khi đã có một pipeline tiền xử lý cơ bản, chúng ta hãy áp dụng nó cho đoạn văn bản mẫu ở trên:
norm_corpus = normalize_corpus(corpus) norm_corpus Output ------ array(['sky blue beautiful', 'love blue beautiful sky', 'quick brown fox jumps lazy dog', 'kings breakfast sausages ham bacon eggs toast beans', 'love green eggs ham sausages bacon', 'brown fox quick blue dog lazy', 'sky blue sky beautiful today', 'dog lazy brown fox quick'], dtype='<U51')
Từ Output chúng ta có thẩy có được cái nhìn rõ ràng về đoạn văn bản sau khi được xử lý. Bây giờ, hãy tiếp tục với các kỹ thuật feature engineering!
Bag of Words Model
Đây có lẽ là mô hình biểu diễn không gian vecto đơn giản nhất cho các văn bản phi cấu trúc. Mô hình không gian vecto chỉ đơn giản là một mô hình toán học để biểu diễn, đại diện cho văn bản (hoặc bất kỳ dạng dữ liệu nào khác) dưới dạng vecto số sao cho mỗi chiều của vecto là một đặc trưng của dữ liệu. Mô hình Bag of words biểu diễn cho mỗi mẫu dữ liệu văn bản dưới dạng một vecto số trong đó mỗi chiều là một từ cụ thể trong kho dữ liệu và giá trị có thể là tần số của nó xuất hiện trong đoạn văn bản (giá trị có thể là 0 hoặc 1) hoặc thậm chí là các giá trị có trọng số. Tên mô hình này là Bag of words thể hiện theo đúng nghĩa đen của nó nghĩa là một túi các từ, không quan tâm đến trật tự, trình tự, ngữ pháp.
from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(min_df=0., max_df=1.) cv_matrix = cv.fit_transform(norm_corpus) cv_matrix = cv_matrix.toarray() cv_matrix Output ------ array([[0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0], [0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0], [0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0], [1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0], [1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0], [0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0], [0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 1], [0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0] ], dtype=int64)
Như kết quả trên bạn có thể thấy rằng các văn bản của chúng ta đã được chuyển đổi thành các vecto số sao cho mỗi mẫu đầu vào đã được biểu diễn bằng một vecto (hàng) trong một ma trận đặc trưng. Đoạn source code sau đây có thể giúp bạn hiểu rõ hơn cách biểu diễn này:
# get all unique words in the corpus vocab = cv.get_feature_names() # show document feature vectors pd.DataFrame(cv_matrix, columns=vocab)
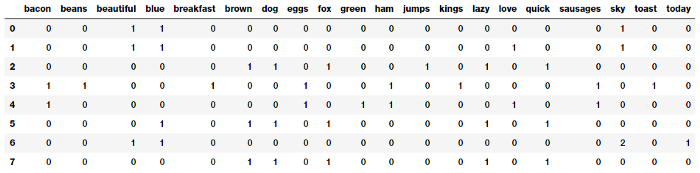
Bạn có thể thấy rõ ràng rằng mỗi cột trong ma trận đặc trưng trên đại diện cho một từ trong kho dữ liệu và mỗi hàng đại diện cho một mẫu. Giá trị trong mỗi ô biểu thị số lần từ đó xuất hiện trong một mẫu cụ thể. Do đó, nếu tập hợp các mẫu bao gồm N từ duy nhất trên toàn bộ không gian mẫu chúng ta sẽ có một vecto N chiều cho mỗi mẫu.
Bag of N-Grams
Với phương pháp trên 1 từ thường được định nghĩa là 1 âm tiết duy nhất (1-gram). Như chúng ta đã biết, mô hình Bag of words không xem xét đến thứ tự các từ. Nhưng điều gì sẽ xảy ra nếu chúng ta muốn tính đến cả các cụm từ hoặc tập hợp các từ? N-gram sẽ giúp chúng ta giải quyết vấn đề đó. Một n-gram về cơ bản là một tập hợp các âm tiết đứng cạnh nhau và xuất hiện trong các mẫu dữ liệu văn bản. Thông thường ta sẽ có Bi-gram (từ 2 âm tiết), Tri-gram (từ 3 âm tiết). Do đó, thực tế thì bag of n-grams chỉ là một phần mở rộng của mô hình bag of words. Chúng ta cùng xem xét ví dụ về Bi-grams dưới đây để hiểu rõ hơn.
# you can set the n-gram range to 1,2 to get unigrams as well as bigrams bv = CountVectorizer(ngram_range=(2,2)) bv_matrix = bv.fit_transform(norm_corpus) bv_matrix = bv_matrix.toarray() vocab = bv.get_feature_names() pd.DataFrame(bv_matrix, columns=vocab)
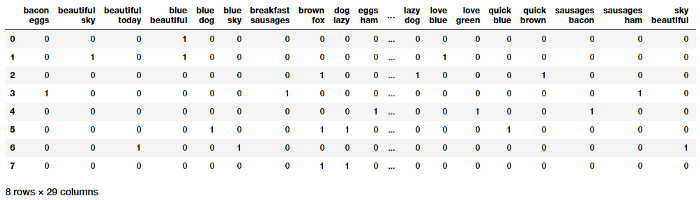
Như vậy chúng ta đã có các vecto đặc trưng cho các mẫu văn bản, trong đó mỗi đặc trưng bao gồm một Bi-grams đại diện cho một từ 2 âm tiết và giá trị cũng là số lần bi-grams xuất hiện trong các mẫu.
TF-IDF
Có một vấn đề tiềm ẩn có thể phát sinh với mô hình Bag of words đó là khi nó được sử dụng trên một văn bản lớn. Vì các vecto đặc trưng dựa trên tần số tuyệt đối, có thể sẽ có một số từ xuất hiện thường xuyên trên tất cả các mẫu và chúng sẽ có xu hướng làm lu mờ các từ khác. Và mô hình TF-IDF cố gắng giải quyết vấn đề này bằng cách sử dụng hệ số tỷ lệ hoặc chuẩn hóa trong tính toán của nó. TF-IDF là viết tắt của Term Frequency-Inverse Document Frequency. Hiểu một cách đơn giản nó là sự kết hợp của tần số xuất hiện của một từ trong một mẫu và nghịch đảo của tần số của từ đó trong toàn bộ tập dữ liệu. Kỹ thuật này được phát triển để đánh giá kết quả cho các truy vấn trong công cụ tìm kiếm và hiện tại nó là một phần không thể thiếu trong xử lý ngôn ngữ tự nhiên. Về mặt toán học có thể định nghĩa TF-IDF = tf x idf, công thức cụ thể như sau:
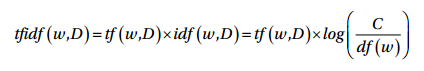
Theo công thức trên, tfidf(w,D) là một score TF-IDF cho từ w trong mẫu D. Thuật ngữ tf(w,D) đại diện cho tần số của từ w xuất hiện trong mẫu D có thể lấy được từ mô hình Bag of words. Thuật ngữ idf(w,D) là tần số nghịch đảo của w có thể tính là log của tổng số mẫu dữ liệu xuất hiện từ w. Mô hình này có thể có rất nhiều biến thể khác nhau, tuy nhiên chúng đều cho kết quả khá giống nhau. Chúng ta cùng xem ví dụ dưới đây.
from sklearn.feature_extraction.text import TfidfVectorizer tv = TfidfVectorizer(min_df=0., max_df=1., use_idf=True) tv_matrix = tv.fit_transform(norm_corpus) tv_matrix = tv_matrix.toarray() vocab = tv.get_feature_names() pd.DataFrame(np.round(tv_matrix, 2), columns=vocab)
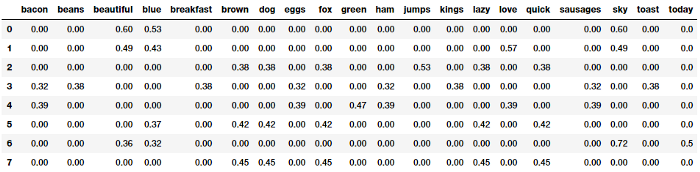
Các vecto đặc trưng có được từ TF-IDF có thể biển diễn các giá trị tỉ lệ và chuẩn hóa hơn so với các giá trị của mô hình bag of words cơ bản. Bạn có thể xem chi tiết hơn về mô hình này tại đây
Document Similarity
Document Similarity (hay độ tương tự của văn bản) là quá trình sử dụng số liệu dựa trên khoảng cách hoặc độ tương tự có thể sử dụng để xác định mức độ tương đương của một văn bản với bất kỳ văn bản nào khác dựa trên các đặc trưng được trích xuất ra từ bag of words hoặc tf-idf.

Chúng ta có thể xây dựng được các đặc trưng mới hữu ích được sử dụng trong các công cụ tìm kiếm, phân cụm văn bản, truy xuất thông tin từ các đặc trưng có được từ tf-idf và Document Similarity. Sự tương tự giữa các mẫu dữ liệu trong một kho văn bản cũng được hiểu là sự tương tự giữa từng cặp mẫu trong toàn bộ kho văn bản đó. Ví dụ, nếu ta có n mẫu trong kho văn bản thì output sẽ là một ma trận n * n tương ứng là score đột tương tự giữa từng cặp mẫu. Có rất nhiều công thức có thể sử dụng để tính toán độ tương tự này như khoảng cách cosin, khoảng cách euclide, khoảng cách manhattan... Trong ví dụ sau đây, chúng ta sẽ sử dụng khoảng cách phổ biến nhất - khoảng cách cosin để tính toán độ tương tự của các cặp mẫu dựa trên vecto đặc trưng TF-IDF đã có ở trên.
from sklearn.metrics.pairwise import cosine_similarity similarity_matrix = cosine_similarity(tv_matrix) similarity_df = pd.DataFrame(similarity_matrix) similarity_df
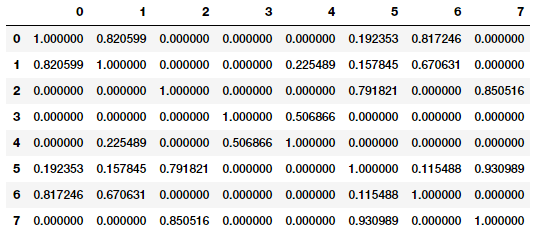
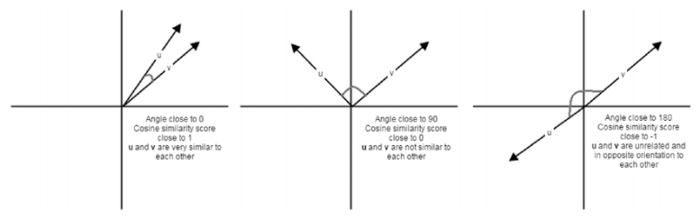
Về cơ bản, khoảng cách cosin cung cấp cho chúng ta một số liệu biểu thị góc giữa 2 vecto đặc trưng tương ứng của từng mẫu. Góc giữa hai mẫu càng gần nhau thì độ tương tự của hai mẫu đó càng lớn như được mô tả trong hình dưới đây
Nhìn vào ma trận độ tương tự (similarity matrix) các bạn có thể thấy rõ ràng rằng các mẫu (0, 1 và 6), (2, 5 và 7) rất giống nhau và các mẫu (3 và 4) hơi giống nhau nhưng cường độ không mạnh lắm. Điều này chỉ ra rằng các mẫu đó một số đặc trưng tương tự nhau. Đây chính là một ví dụ hoàn hảo về việc nhóm hoặc phân cụm văn bản có thể giải quyết được bằng cách học không giám sát (unsupervised learning). Đặc biệt chúng có thể áp dụng xử lý trên khối lượng lớn mẫu văn bản.
Phân cụm tài liệu sử dụng đặc trưng tương tự
Phân cụm (clustering) tận dụng phương pháp học không giám sát để nhóm các điểm dữ liệu (trong trường hợp này là các mẫu văn bản) thành các nhóm hoặc các cụm. Chúng ta sẽ sử dụng thuật toán phân cụm không giám sát để thử nhóm các mẫu văn bản tương tự từ kho văn bản đã có trước đó. Có hai phương pháp phân cụm chính là agglomerative và divisive methods. Ở đây chúng ta sẽ sử dụng phương pháp agglomerative. Đây là phương pháp phâm cụm từ dưới lên trên, tức là mỗi mẫu hoặc tài liệu ban đầu được xếp vào các cụm riêng biệt và được nối với nhau bằng cách sử dụng các thang đo khoảng cách và các tiêu chuẩn để hợp nhất liên kết như mô tả trong hình dưới đây.
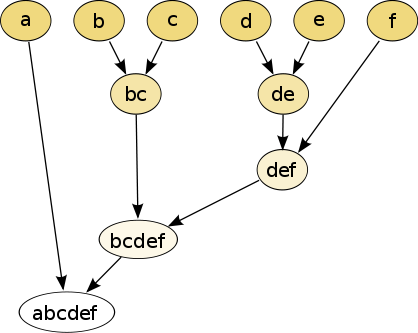
Việc lựa chọn tiêu chí để hợp nhất các liên kết quyết định rất lớn đến kết quả của bài toán. Một vài tiêu chuẩn liên kết như Ward, liên kết hoàn chỉnh (Complete linkage), liên kết trung bình (Average linkage)... Các tiêu chí này nhằm mục đích chọn các cặp cụm dữ liệu ở tầng thấp nhất và ở các cụm cao hơn để hợp nhất dựa trên giá trị tối ưu của hàm mục tiêu. Trong ví dụ sau đây, chúng ta sẽ chọn phương pháp phương sai tối thiểu Ward để làm tiêu chí liên kết các cặp cụm với mục đích giảm thiểu tổng phương sai trong cụm đó. Sử dụng similarity matrix có được ở trên chúng ta cùng xem xét ví dụ sau để hiểu rõ hơn về việc liên kết các mẫu dữ liệu.
from scipy.cluster.hierarchy import dendrogram, linkage Z = linkage(similarity_matrix, 'ward') pd.DataFrame(Z, columns=['DocumentCluster 1', 'DocumentCluster 2', 'Distance', 'Cluster Size'], dtype='object')
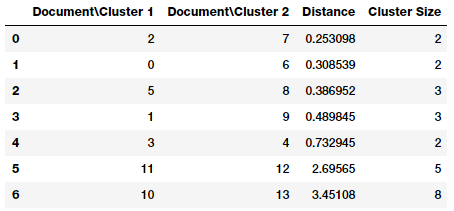
Từ hình trên ta có thể dễ dàng nhận thấy rằng ở mỗi bước (tương ứng là các hàng) các điểm dữ liệu nào (hoặc cụm nào) sẽ được liên kết với nhau. Nếu bạn có n điểm dữ liệu thì ma trận liên kết Z sẽ có hình dạng (n-1) * 4 trong đó Z[i] sẽ cho chúng ta biết cụm nào được hợp nhất ở bước thứ i. Mỗi hàng có 4 phần tử, hai phần tử đầu tiên định danh điểm dữ liệu hoặc nhãn của cụm, phần tử thứ ba là khoảng cách giữa hai điểm dữ liệu hoặc cụm đầu tiên, phần tử cuối cùng là số điểm dữ liệu trong cụm sau khi được hợp nhất hoàn toàn. Bạn hãy tham khảo tại đây để hiểu rõ hơn vấn đề này. Bây giờ chúng ta sẽ mô hình hóa ma trận lên để tưởng tượng tốt hơn
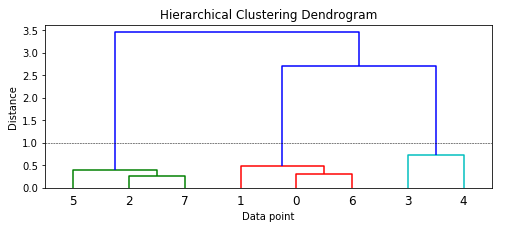
Bạn có thể thấy rằng mỗi điểm dữ liệu ban đầu đều thuộc các cụm riêng lẻ và sẽ được hợp nhất với các điểm dữ liệu khcas để tạo thành cụm. Từ màu sắc và sự phân nhánh bạn có thể thấy rằng mô hình đã xác định được ba cụm chính nếu bạn sử dụng một thước đo khoảng cách từ 1.0 trở lên (trong biểu đồ là đường chấm đứt). Sử dụng khoảng cách này chúng ta sẽ có nhãn của các cụm bằng cách sau.
from scipy.cluster.hierarchy import fcluster max_dist = 1.0 cluster_labels = fcluster(Z, max_dist, criterion='distance') cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel']) pd.concat([corpus_df, cluster_labels], axis=1)

Như vậy, chúng ta đã xác định được chính xác 3 cụm khác nhau của các tài liệu trong kho văn bản. Hi vọng điều này đã cung cấp cho các bạn một ý tưởng tốt về cách sử dụng đặc trưng TF-IDF và đặc trưng tương tự của văn bản để phâm cụm các tài liệu,
Topic Models
Chúng ta cũng có thể sử dụng một số kỹ thuật tổng hợp, tóm tắt để trích xuất các chủ đề hoặc khái niệm đặc trưng của văn bản. Ý tưởng về các topic models xoay quanh quá trình sắp xếp các văn bản vào những dạng chủ đề, khái niệm. Mỗi chủ để được biểu diễn dưới dạng là tập hợp của các từ/thuật ngữ có trong kho văn bản. Nếu chúng xuất hiện cùng với nhau các từ/thuật ngữ này sẽ biểu thị, tượng trưng cho một chủ đề hoặc khái niệm cụ thể. Chúng ta có thể dễ dạng phân biệt các chủ đề với nhau nhờ ngữ nghĩa của các thuật ngữ đó. Tuy nhiên, các chủ đề thường có sự chồng chéo nhất định trên dữ liệu. Các topic models sẽ cực kỳ hữu ích trong việc tóm tắt, rút gọn khối lượng lớn tài liệu, văn bản để trích xuất, mô tả các khái niệm chính nhất. Chúng cũng hữu ích trong việc trích xuất các đặc trưng từ dữ liệu văn bản để nắm bắt các pattern tiềm ẩn trong dữ liệu đó.
Có nhiều kỹ thuật khác nhau để mô hình hóa chủ đề văn bản và hầu hết chúng liên quan đến một số dạng phân tách ma trận. Một số kỹ thuật như Latent Semantic Indexing (LSI) sử dụng các phương pháp phân tách ma trận, cụ thể hơn là phân tách các giá trị đơn lẻ. Chúng ta sẽ sử dụng một kỹ thuật khác là Latent Dirichlet Allocation (LDA), một kỹ thuật sử dụng mô hình xác suất tổng quát trong đó mỗi mẫu tài liệu bao gồm một sự kết hợp của một số chủ đề và mỗi thuật ngữ hoặc từ có thể được gán cho một chủ đề cụ thể. Phương pháp này tương tự như phương pháp pLSI (probabilistic LSI). Các bạn có thể tham khảo bài viết xuất sắc này của Christine Doig để hiểu rõ hơn về mặt toán học.
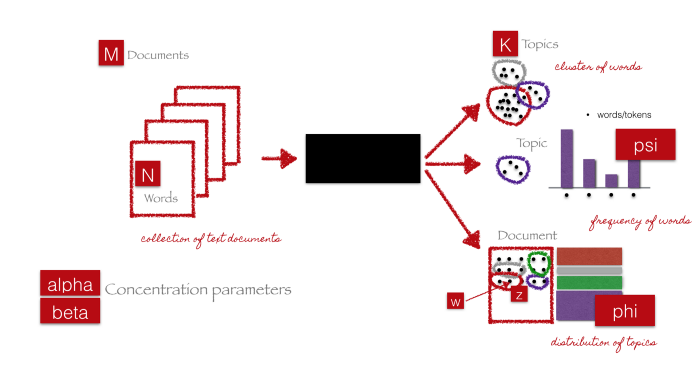
Black box trong hình trên biểu diễn thuật toán cốt lõi sử dụng các tham số đã đề cập trước đó để trích xuất chủ đề K của dữ liệu M. Các bước sau đây sẽ giải thích đơn giản nhất về các bước diễn ra.

Chúng ta sẽ sử dụng các framework như gensim hoặc scikit-learn và áp dụng mô hình LDA để tạo ra các chủ đề.
from sklearn.decomposition import LatentDirichletAllocation lda = LatentDirichletAllocation(n_topics=3, max_iter=10000, random_state=0) dt_matrix = lda.fit_transform(cv_matrix) features = pd.DataFrame(dt_matrix, columns=['T1', 'T2', 'T3']) features
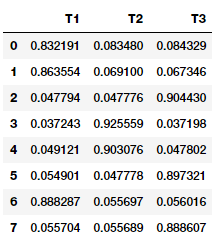
Từ hình trên bạn có thể thấy rõ ràng rằng mẫu dữ liệu nào có tương quan mạnh nhất đến chủ đề tương ứng. Chúng ta có thể xem xét cụ thể các chủ đề và các từ/thuật ngữ chính như sau
tt_matrix = lda.components_ for topic_weights in tt_matrix: topic = [(token, weight) for token, weight in zip(vocab, topic_weights)] topic = sorted(topic, key=lambda x: -x[1]) topic = [item for item in topic if item[1] > 0.6] print(topic) print() Topic 1 ------- [('sky', 4.3324395825632624), ('blue', 3.3737531748317711), ('beautiful', 3.3323652405224857), ('today', 1.3325579841038182), ('love', 1.3304224288080069)] Topic 2 ------- [('bacon', 2.3326959484799978), ('eggs', 2.3326959484799978), ('ham', 2.3326959484799978), ('sausages', 2.3326959484799978), ('love', 1.335454457601996), ('beans', 1.3327735253784641), ('breakfast', 1.3327735253784641), ('kings', 1.3327735253784641), ('toast', 1.3327735253784641), ('green', 1.3325433207547732)] Topic 3 ------- [('brown', 3.3323474595768783), ('dog'
