Machine Learning cho mọi người, Phần 2.1: Supervised Learning
Ở phần 1 , mình đã giới thiệu về tầm quan trọng của Machine Learning và bức tranh toàn cảnh về trí tuệ nhân tạo và machine learning – trong quá khứ, hiện tại và tương lai. Phần 2: Supervised Learning Học có giám sát chia làm 2 loại chính : regression (hồi quy) và classification ...

Ở phần 1, mình đã giới thiệu về tầm quan trọng của Machine Learning và bức tranh toàn cảnh về trí tuệ nhân tạo và machine learning – trong quá khứ, hiện tại và tương lai.
Phần 2: Supervised Learning
Học có giám sát chia làm 2 loại chính : regression (hồi quy) và classification (phân loại) .Linear regression, cost function và gradient descent.
Chúng ta sẽ thu về lợi nhuận bao nhiêu nếu đầu tư nhiều vào quảng cáo? Liệu người vay có khả năng trả được khoản vay hay không ? Điều gì sẽ xảy ra với thị trường chứng khoán ngày mai?
Trong các vấn đề liên quan đến học tập có giám sát, chúng ta thường bắt đầu với một tập dữ liệu có chứa các ví dụ training với các labels chính xác kèm theo. Ví dụ, khi chúng ta học cách để phân loại chữ số viết tay, một thuật toán học giám sát sẽ nhận hàng ngàn bức ảnh về chữ số viết tay cùng với các labels thể hiện chính xác số đếm trên mỗi hình. Thuật toán sau đó học mối quan hệ giữa các hình và các số đếm liên quan, áp dụng mối qua hệ đã học được để phân loại một bức hình hoàn toàn mới ( không có nhãn kèm theo ) mà machine chưa từng thấy qua. Đó là cách bạn có thể gửi hình ảnh sec bằng ảnh điện thoại.
Để giải thích hoạt động cách học có giám sát, hãy phân tích dự đoán bằng số liệu thu nhập hằng năm dựa trên số năm học đại học mà người đó hoàn thành. Để rõ ràng hơn, chúng tôi muốn xây dựng một mô hình gần đúng với biểu thức f giữa số năm học đại học ( X ) và thu nhập hằng năm tương ứng ( Y )
![]()
|
1 2 3 4 5 6 7 8 9 |
X (input) = số năm học đại học Y (output) = thu nhập hằng năm f = hàm miêu tả mối quan hệ giữ X và Y (epsilong)= một hằng số ngẫu nhiên. |
Về epsilong:
- thể hiện sai số không thay đổi trong biểu thức, đó là giới hạn mang tính lý thuyết về hiệu suất của một thuật toán thông quan các hiện tượng gây nhiễu. Ví dụ, hãy xây dựng một biểu thức dự đoán đầu ra khi tung 1 đồng xu ?
- Ngược lại, nhà toán học Paul Erdos miêu tả epsilons như một đại lượng có ảnh hưởng không đáng kể bởi vì trong giải tích ϵ biểu thị một đại lượng nguyên dương nhỏ tùy ý.
Một phương thức dự đoán thu nhập sẽ tạo ra một mô hình dựa trên các quy tắc về thu nhập và giáo dục đại học. Ví dụ: “ Tôi ước tính rằng với mỗi năm đại học , thì thu nhập hằng năm tăng 5000$”.
thu nhập = ( $5000 * số năm đại học ) + thu thập cơ bản
Ban cũng có thể đưa ra một biểu thức phức tạp hơn thêm một số quy tắc về cấp bậc, năm kinh nghiệm làm việc, hạng của trường đã tốt nghiệp,…. Ví dụ: “ Nếu họ tốt nghiệp bằng cử nhân hoặc cao hơn, hãy tính thu nhập nhân thêm 1.5 “.
Những loại lập trình dựa trên các quy tắc có sẵn sẽ không hoạt động tốt trên các bộ dữ liệu phức tạp. Tưởng tượng việc cố gắng thiết kế một thuật toán phân loại hình ảnh được tạo từ các câu lệnh if-else mô tả sự kết hợp của các điểm ảnh để đưa ra kết luận là mèo hay không là mèo.
Học có giám sát giải quyết vấn đề này bằng cách để máy tính làm việc đó cho bạn. Với việc xác định các khuôn mẫu trong dữ liệu, máy có thể tạo nên các heruistic. Sự khác biệt chính giữa việc học của máy và con người là machine learning chạy trên các phần cứng máy tính và được hiểu rõ thông qua cách nhìn nhận của khoa học máy tính và thống kê, trong khi đó con người chỉ diễn trong bộ não sinh học.
Trong học có giám sát, máy tính cố gắng tìm hiểu mối quan hệ giữa thu nhập và giáo dục từ lúc bắt đầu, bằng cách chạy các training data đã được dán nhãn thông qua một thuật toán learning. Chức năng learn này được sử dụng để ước tính thu nhập của những người có thu nhập Y không rõ ràng, miễn là chúng ta có số năm đại học X là đầu vào. Nói cách khác, chúng ta có thể áp dụng mô hình này đối với các dữ liệu không có nhãn và dự đoán Y.
Mục đích của học có giám sát là dự đoán giá trị Y càng chính xác càng tốt khi được cho một ví dụ biết X và không biết Y. Sau đây chúng ta sẽ tìm hiểu những cách tiếp cận phổ thông nhất để làm việc đó.
Hai nhiệm vụ chính của học có giám sát là : regression và classfication
|
1 2 3 4 |
Regression: dự đoán continous numerical value. Ngôi nhà được bán với giá bao nhiêu? Classification: gán một label. Liệu rằng bức tranh này là chó hay mèo? |
Phần còn lại của bài viết sẽ thảo luận về regression . Trong phần 2.2, chúng ta sẽ nghiên cứu sâu hơn về classification.
Regression: dự đoán continous value.
Regression dự đoán một continous target variable Y. Nó cho phép chúng ta ước tính một giá trị, như giá nhà hay tuổi thọ con người, dựa trên giá trị input X.
Ở đây, target variable được hiểu là một biến chưa xác định chúng ta cần dự đoán, và continuous nghĩa là không có gián đoạn (discontinuities) trong giá trị Y có thể nhận. Cân nặng và chiều cao của một người là một continuous value. Discrete variables, chỉ nhận một giới hạn các giá trị – ví dụ, số lượng trẻ em mà một người có là một discrete variable.
Dự đoán thu nhập là một regression cổ điển. Giá trị input X bao gồm các thông tin liên quan đến các cá nhân trong tập dữ liệu để có thể dự đoán thu nhập, như số năm học đại học, số năm kinh nghiệm làm việc, loại việc làm hoặc là zip code. Những thuộc tính trên được gọi là features, hoặc dưới dạng numerical ( số học ) ( số năm kinh nghiệp làm việc ) hoặc categorical ( cấp loại ) ( loại công việc và chuyên ngành học ).
Bạn sẽ muốn có càng nhiều tập dữ liệu training liên quan đến các thuộc tính của giá trị target Y, để mô hình có thể học từ mối quan hệ f giữa X và Y ( hàm f(X)=Y ).
Dữ liệu được chia ra làm training data set và test data set. Trainig set có nhãn, nên mô hình của bạn có thể học từ những ví dụ có nhãn này. Test data set thì không có nhãn, nghĩa là bạn không cần phải biết giá trị được dự đoán. Điều quan trọng là mô hình của bạn có thể khởi tạo các trường hợp mà nó chưa gặp phải trước đó để hoạt động hiệu quả trên test data.
|
1 2 3 4 5 6 7 8 9 |
Regression Y = f(X) + ϵ, where X = (x1, x2…xn) Training: Máy học f từ các training data đã được gán nhãn. Test: Máy dự đoán Y từ những testing data chưa dán nhãn. |
Lưu ý: X có thể là một Ten-xơ với số chiều bất kì. Ten-xơ 1D là một vectơ ( 1 hàng, nhiều cột), Ten-xơ 2D là một ma trận ( nhiều hàng, nhiều cột), tương tự bạn có thể có nhiều Ten-xơ với 3 4 5 hoặc nhiều chiều hơn. ( ví dụ Ten-xơ 3D với trục ngang, trục dọc, trục cao). Để hiểu rõ tham khảo phần đầu tiên ở bài viết này linear algebra review.
Trong ví dụ dưới hình dạng 2D sau, nó có thể là 1 file có đuôi .csv với mỗi hàng gồm trình độ học vấn và thu nhập một người. Nếu thêm nhiều cột có nhiều thuộc tính hơn thì sẽ có một mô hình phức tạp hơn nhưng có thể chính xác hơn.
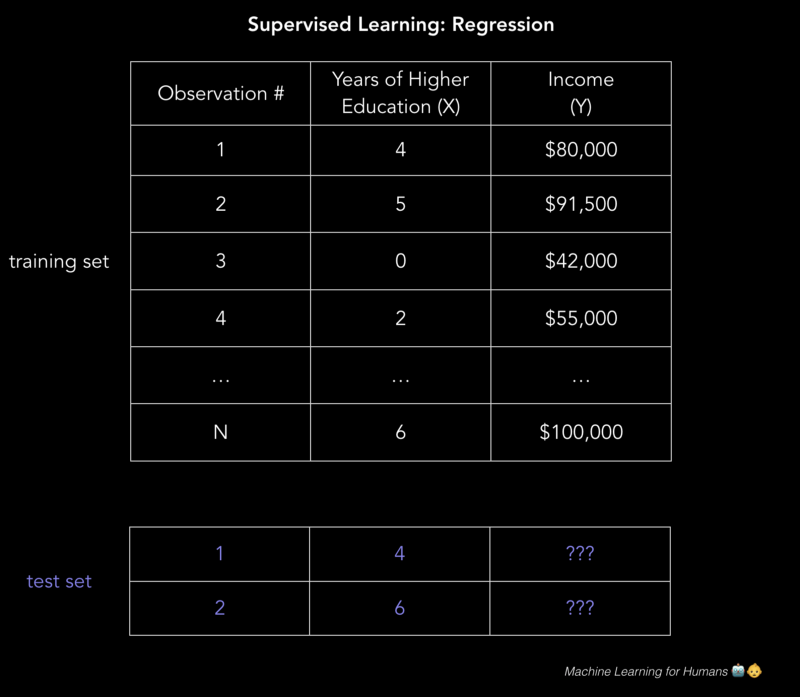
Vậy làm thế nào để giải quyết những vấn đề này?
Vậy làm thế nào để xây dựng một mô hình đưa ra những tiên đoán chính xác và hợp lí trong thế giới thực? Đó là sử dụng thuật toán học có giám sát ( supervised learning).
Giờ sẽ chuyển qua phần thú vị: tìm hiểu về thuật toán. Chúng ta sẽ khám phá một số cách tiếp cận regression va classification, qua đó minh họa bằng các khái niệm quan trọng trong machine learning.
Linear regression
“Draw the line. Yes, this counts as machine learning.”
Đầu tiên, chúng ta sẽ tập trung vào việc giải quyết vấn đề dự đoán thu nhập với linear regression, bỏi vì mô hình linear không hoạt động hiệu quả với nhiệm vụ nhận dạng hình ảnh ( Đây là một phạm trù của deep learning, chúng ta sẽ tìm hiểu sau ).
Ta có một tập dữ liệu X, và các giá trị nhắm tới tương tứng là Y. Mục địch của ordinary least squares (OLS) regression là học mô hình linear mà chúng ta sử dụng để dự đoạn một giá trị y mới được cho bởi một giá trị x không biết trước, với ít sai số nhất. Chúng ta muốn dự đoán thu nhập của một người dựa vào số năm đại học họ đã học.
|
1 2 3 4 5 |
X_train = [4, 5, 0, 2, …, 6] #năm học đại học Y_train = [80, 91.5, 42, 55, …, 100] # thu nhập hằng năm tương ứng, đơn vị: nghìn đô. |
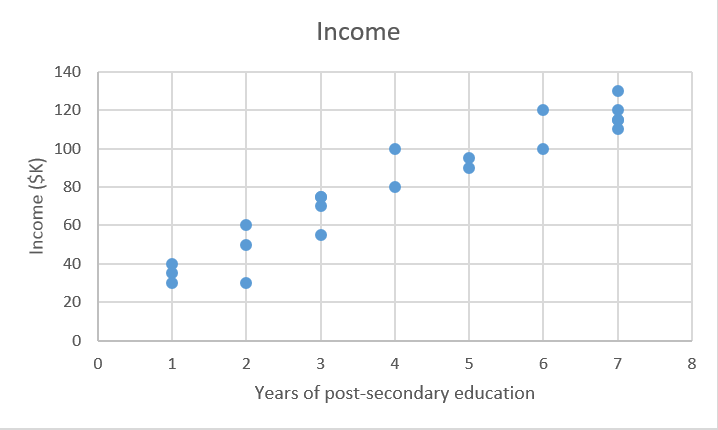
Linear regression là một parametric method, có nghĩa là nó tạo ra các giả định về hình thức quan hệ của các hàm X và Y ( sẽ chỉ ra một ví dụ về mô hình non-parametric sau). Mô hình của chúng ta sẽ là một hàm dự đoán giá trị y từ giá x xác định cho trước:
![]()
Ở trường hợp này, chúng ta xác định rõ ràng x và y có mối quan hệ tuyến tính. Nghĩa là với mỗi đơn vị x tăng, thì y cũng tăng một giá trị không đổi ( hoặc giảm tùy dấu).
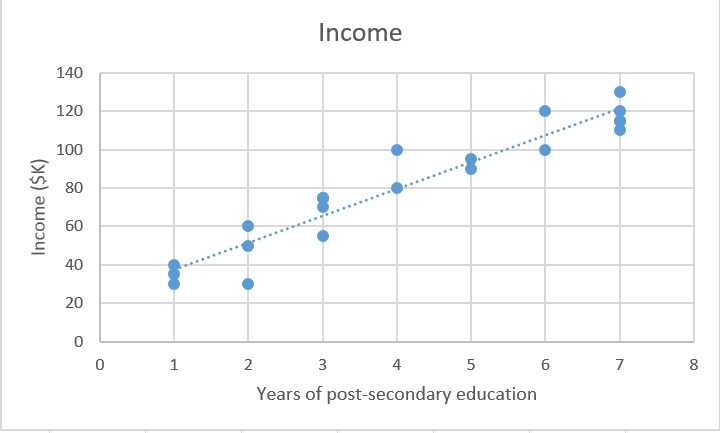
Mục tiêu của chúng ta là tìm ra các tham số trong biểu thức trên ( β0 và β1) tối ưu hóa các sai số trong biểu thức dự đoán.
Để tìm ra tham số phù hợp nhất:
1.Xác định cost function ( loss function), hàm này tính toán độ chênh lệch của mô hình trên giữa y dự đoán và y trong training data.
- Tìm các tham số sẽ tối ưu hóa sự chênh lệch, tức là làm cho biểu thức càng chính xác càng tốt ( costfunction nhỏ nhất ).
Về mặt hình học, theo hai chiều, kết quả này phù hợp nhất. Trong ba chiều, chúng ta sẽ vẽ một mặt phẳng với trục cao.
Lưu ý chiều không gian: ví dụ của chúng ta là hai chiều , nhưng thông thường bạn sẽ có nhiều thuộc tính (x) hơn và các hệ số (beta) trong biểu thức , ví dụ: khi thêm các tham số có liên quan hơn để cải thiện tính chính xác của biểu thức dự đoán. Ví dụ nếu thêm một tham số nữa thì sẽ có thêm chiều cao trong không gian 3 chiều.
Về mặt toán học, chúng ta tính hiệu giữa mỗi điểm dữ liệu (y) và điểm dự đoán của (ŷ). Bình phương hiệu này này để tránh số âm, sau đó cộng hết lại và lấy trung bình. Đây là công thức tính cost function:
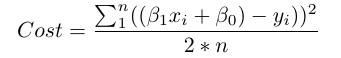
Vì đây là một vì dụ đơn giản, chúng ta có thể tìm ra một giải pháp chính xác hơn bằng cách sử dụng giải tích để tìm ra các tham số beta tối ưu nhằm giảm cost function. Nhưng khi cost function trở nên phức tạp, việc tìm ra một hướng đi bằng giải tích không còn khả thi nữa. Lúc này người ta sẽ dùng tới gradient descent, cho phép chúng ta làm tối giản độ phức tạp của cost function.
Gradient descent: learn the parameters
“Put on a blindfold, take a step downhill. You’ve found the bottom when you have nowhere to go but up.”
Gradient descent sẽ được nhắc lại nhiều lần, đặc biệt là trong nơ-ron networks. Các thư viện machine learning như scikit-learn và TensorFlow sử dụng nó như nền tảng mọi nơi, vì vậy cần phải nắm rõ các khái niệm chi tiết.
Mục đích của gradient descent là tìm điểm cưc tiểu của hàm cost function bằng cách lặp đi lặp lại để tiếp cận gần hơn điêm cực tiểu.
Hãy tưởng tượng bạn bịt mắt và đang đi qua một thung lũng. Bạn muốn đến điểm thấp nhất của thung lũng. Vậy làm cách nào?
Phương án khả thi nhất là bạn sẽ đi trên bề mặt của nó và di chuyển hướng xuống dốc nhất. Bước đi và lặp lại tiến trình cho đến khi mặt đất bằng phẳng. Lúc đó bạn biết mình đã ở điểm thấp nhất của thung lũng. Nếu bạn di chuyển ở một phương bất kì thì bạn sẽ bị kẹt ở những nơi có cùng độ cao hoặc thậm chí lên cao hơn.
Quay trở lại toán học, bề mặt thung lũng sẽ là cost function, và điểm thấp nhấp của thung lũng sẽ là điểm cực tiểu của hàm.
Giờ hãy xem lại cost function:
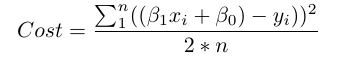
Nó là một hàm với 2 biến β0 và β1 .Tất cả những biến còn lại đều đã được xác đinh. Chúng ta muốn tìm điểm cực tiểu của hàm này.
Hàm sẽ là f(β0,β1)=z. Để bắt đầu gradient descent, bạn cần có vài dự đoán về các tham số để tới điểm cực tiểu.
Tiếp theo, sẽ đạo hàm từng phần cost function với các tham số tương ứng [dz/dβ0, dz/dβ1]. Mỗi một đạo hàm từng phần tương ứng với tổng sai số sẽ tăng hoặc giảm nếu bạn tăng β0 hoặc β1 một giá trị rất nhỏ.
Nói cách khác, chúng ta cần xử lí giá trị β0 như thế nào giả sử nếu tăng β0 làm tăng giá trị loss function ? Lúc này bạn sẽ đi theo hướng ngược để làm giảm cost function.
Tương tự, với β1, nếu đạo hàm từng phần dz/β1 là một số âm, thì tăng β1 vì nó sẽ làm giảm cost function. Nếu đó là một số dương, nên giảm β1. Nếu nó là số 0, không thay đổi β1 bởi vì nó đã đạt cực tiểu.
Tiếp tục làm điều đó cho đến khi đi đến điểm cực tiểu, tức là thuật toán hội tụ và cost function đã giảm. Có rất nhiều tricks và các trường hợp ngoại lệ vượt quá phạm vi của loạt bài này, nhưng nói chung, đây là cách tìm ra các tham số tối ưu cho mô hình của mình.
Overfitting
Overfitting: “Sherlock, your explanation of what just happened is too specific to the situation.” Regularization: “Don’t overcomplicate things, Sherlock. I’ll punch you for every extra word.” Hyperparameter (λ): “Here’s the strength with which I will punch you for every extra word.”
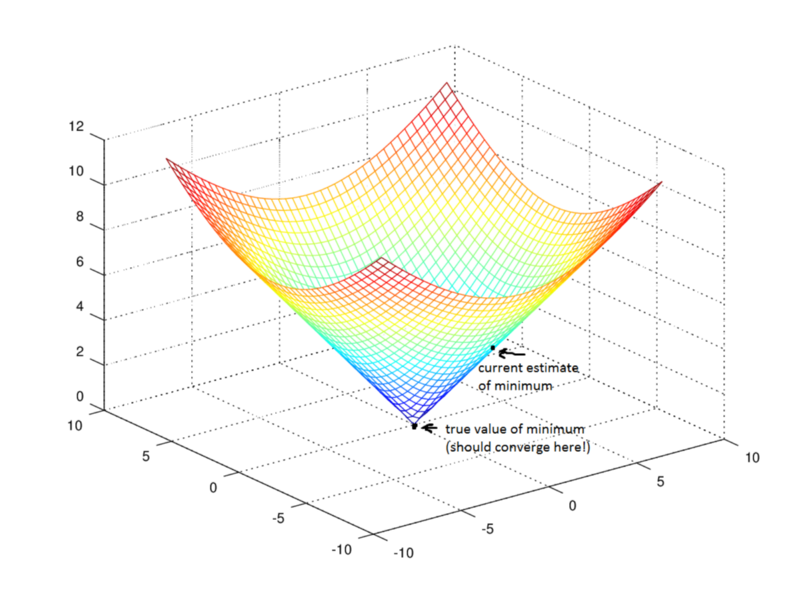
Một vấn đề thường thấy trong machine learning là overfitting: tìm một hàm sẽ thỏa đầy đủ các training data mà biểu thức học được, nhưng không thể hoạt động tốt trên các test data mới. Overfitting xảy ra khi một mô hình overlearns từ training data
đến nỗi nó bắt đầu chọn các điểm khác thường không phù hợp với thực tế Điều này là một vấn đề rất quan trọng bởi vì lúc này bạn đang làm cho biểu thức trở nên phức tạp hơn. Underfitting là một vấn đề liên quan đến việc mô hình không đủ phức tạp để nắm bắt được các xu hướng cơ bản của dữ liệu.
Bias-Variance Tradeoff
Bias: Thiên vị
Variance: Phương sai
Khi một mô hình trở nên phức tạp và linh hoạt hơn, bias của nó giảm (nó sẽ mô tả training data), nhưng variance tăng (nó không thể tổng quát đc). Cuối cùng, để có một mô hình lí tưởng, bạn cần thỏa Thiên vị thấp và phương sai thấp.
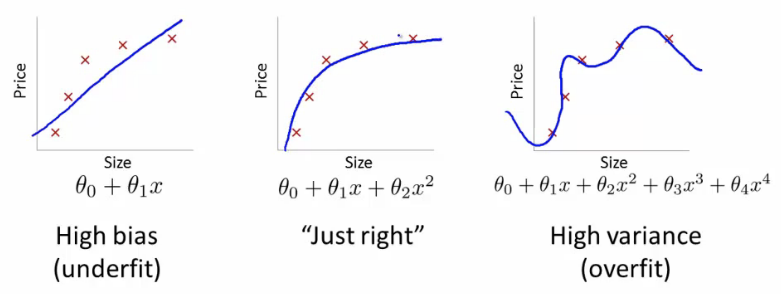
Nhớ rằng điều duy nhất chúng ta quan tâm là cách mô hình hoạt động trên test data. Bạn muốn dự đoán email nào sẽ bị đánh dấu là spam với những email hoàn toàn mới, chứ không chỉ là xây dựng mô hình chính xác 100% để phân loại những email mà nó đã sử dụng để xây dựng nên mô hình đó. Nhận thức muộn là 20/20 – câu hỏi thực sự là liệu những bài học kinh nghiệm sẽ giúp ích cho tương lai hay không.
Mô hình ngoài cùng bên phải có cost function là 0 bởi vì nó khớp hoàn hảo với các điểm input. Nhưng nó lại không mang tính tổng quát. Liệu điều gì xảy ra nếu có một điểm không nằm trên đồ thị trên? Nó sẽ làm nhiều nhiệm vụ phức tạp để phù hợp một điểm mới nếu không nằm trên đường đồ thị trên.
Hai cách để tránh overfitting:
1.Sử dụng nhiều training data hơn. Việc sử dụng nhiều dữ liệu sẽ càng tránh khả năng overfit.
- Use regularization Chỉnh sửa cost function để xây dựng lại một mô hình mới nhằm làm cho mô hình ít phức tạp hơn.
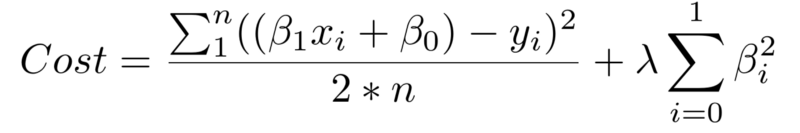
Số hạng thứ nhất là tổng thông thường của cost function. Số hạng thứ hai là regularization term nhằm thêm một số hạng mới để xử lí các hệ số beta lớn tăng tính tổng quát của mô hình ( mô tả được cả ở trên training data và test data) .Với hai yếu tố này, cost function cân bằng giữa hai yếu tố ưu tiên: thỏa mãn training data và ngăn không bị overfit.
Hệ số lambda trong regularization là một tham số hyperparameter: một thiết lập chung có thể tùy chình để cải thiện hiệu suất. Giá trị lambda cao sẽ làm hạn chế cao các hệ số beta lớn có thể dẫn tới việc overfitting tiềm ẩn. Để xác định giá trị tốt nhất cho lambda, nên sử dụng một phương pháp được gọi là cross-validation, bao gồm việc giữ một phần training data trong quá trình học, và sau đó xem mô hình của bạn mô tả phần bị giữ lại như thế nào?. Chúng ta sẽ đi sâu hơn về vấn đề này
Woo! We made it.
Đây là tổng hợp những gì chúng ta đã học được:
- Cách để học có giám sát khiến máy tính học những training data được dán nhãn mà không cần phải lập trình cụ thể.
- Tác vụ của học có giám sát: regression và classification
- Linear regression, bread-and-butter parametric algorithm
- Gradient descent
- Overfitting và regularization
Techtalk via medium.com
