Nhận dạng chữ Kanji và Deploy mô hình Deep Learning với Tensorflow JS
Xin chào các bạn, cũng đã lâu rồi mình không có bài viết mới trên Viblo bởi dạo này mình tập trung vào làm Video Tutorial hơn. Nhưng xa Viblo lâu ngày quá cũng thấy buồn buồn, nhân tiện có nhiều người hỏi về cách thức thực hiện của bài toán Nhận dạng chữ số viết tay tiếng Nhật mà mình đã có chia ...
Xin chào các bạn, cũng đã lâu rồi mình không có bài viết mới trên Viblo bởi dạo này mình tập trung vào làm Video Tutorial hơn. Nhưng xa Viblo lâu ngày quá cũng thấy buồn buồn, nhân tiện có nhiều người hỏi về cách thức thực hiện của bài toán Nhận dạng chữ số viết tay tiếng Nhật mà mình đã có chia sẻ demo trên Facebook tại đây mình viết luôn một bài Viblo chia sẻ lại luôn. Bài viết này mình sẽ cố gắng viết thật đầy đủ chi tiết các bước làm để các bạn có thể hình dung được việc triển khai một mô hình Deep Learning trên trình duyệt bằng thư viện Tensorflow JS như thế nào nên có thể nó sẽ khá dài. OK chúng ta bắt đầu nhé.
Trước khi bắt đầu vào một vấn đề nào đó, việc đầu tiên mình thường lập dàn ý trước các bước thực hiện. Và đây các bước chúng ta sẽ thực hiện như sau:
- Bước 1: Chuẩn bị dữ liệu: chắc không phải bàn cãi về vấn đề này nữa, muốn dạy một con AI học thì tất nhiên phải có dữ liệu rồi phải không nào. Trong bài viết này chúng ta sẽ nhận dạng chữ cái viết tay của Tiếng Nhật. Ở đây mình có sử dụng một corpus có sẵn trên mạng phục vụ cho mục đích nghiên cứu có tên là ETLDB tuy nhiên do dữ liệu này có rất nhiều chữ nên mình chỉ sử dụng một tập nhỏ có chứa 3036 chữ cái để làm ví dụ mình họa mà thôi. Các bạn có thể tham khảo về phần dữ liệu mình sử dụng tại mục ETL-9. Tập dữ liệu này được tổ chức dưới dạng các Byte nên lúc đầu các bạn cần phải xử lý chúng để convert ra ảnh. Việc này khá tỉ mỉ và mất rất nhiều thời gian. Mình không khuyến khích các bạn làm công việc khá to tay này nên mình xin được chia sẻ luôn tập dữ liệu mà mình đã xử lý sẵn. Các bạn có thể download nó về tại đây. Giải nén dữ liệu này các bạn sẽ được hai thư mục là training_data và testing_data phục vụ cho việc huấn luyện mô hình sau này
- Bước 2: Tiền xử lý dữ liệu bước tiếp theo chúng ta sẽ phải xử lý dữ liệu từ ảnh thô đầu vào trước khi đưa vào trong mô hình. Việc này mình sẽ nói kĩ hơn trong phần tiếp theo
- Bước 3: Định nghĩa mô hình: chúng ta sẽ định nghĩa mô hình mạng nơ ron giúp nhận biết các chữ cái tiếng Nhật này.
- Bước 4: Huấn luyện mô hình: sau khi lựa chọn mô hình chúng ta tiến hành huấn luyện mô hình.
- Bước 5: Tinh chỉnh mô hình: đúng ra thì bước này các bạn sẽ phải tự làm bằng tay, lựa chọn các tham số cho mô hình đạt kết quả tốt nhất nhưng vì sợ các bạn nản nên mình sẽ đưa sẵn cho các bạn các tham số mà mình đã tối ưu rồi. Các bạn chỉ việc lắp vào mà chạy thôi
- Bước 6: Đánh giá mô hình: chúng ta sẽ lựa chọn mô hình cho kết quả tốt nhất
- Bước 7: Convert mô hình sang Tensorflow JS: Các bạn chuyển đổi mô hình này sang Tensorflow JS để có thể đọc được trên trình duyệt
- Bước 8: Xây dựng ứng dụng demo bằng Tensorflow JS phần này thì chắc nhiều bạn làm web sẽ rành hơn mình nên mình sẽ làm một giao diện đơn giản đủ để demo, ngoài ra sẽ nói sâu hơn về Tensorflow JS nhé.
Oài 8 phần liền đó, các bạn chịu khó đọc nha, mình sẽ không tách nó ra thành một series đâu vì đơn giản là mình chỉ chăm viết trong một khoảng thời gian nhất định (khi nào cao hứng) thôi. Nhỡ đầu tuần sau mình lại lười thì dự rằng series sẽ kéo dài vô tận mất. OK chúng ta bắt đầu thôi nào.
Các bạn chỉ việc download về rồi giải nén dữ liệu là xong. Next step nhé
Giờ là lúc chúng ta cần động vào code rồi đây. Trước tiên các bạn cần cài đặt một số package cần thiết như Tensorflow, Keras, Numpy, OpenCV, Jupyter Notebook .... Mình mặc định các bạn đã cài đặt thành công rồi nhé. Các bạn mở Jupyter Notebook lên, tạo một file kanji_recognition_training.ipynb cùng thư mục với thư mục data vừa giải nén nhé. Chúng ta bắt đầu bước đầu tiên
Import dependencies
import numpy as np from keras.preprocessing.image import ImageDataGenerator
Data Generator
Chúng ta sẽ sử dụng ImageDataGenerator của Keras để sinh ra dữ liệu nhằm đưa vào mô hình của chúng ta. Chúng ta cần định nghĩa hai bộ sinh dữ liệu, cho hai tập training và testing. Do trong file đữ liệu mình gửi cho các bạn đã phần chia sẵn hai folder training và testing cho các bạn rồi nên chúng ta chỉ cần truyền tham số folder_name vào thôi.
#Training generator with augmentation train_datagen = ImageDataGenerator( rotation_range=40, awidth_shift_range=0.2, height_shift_range=0.2, rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=False, vertical_flip=False, fill_mode='nearest')
bản chất của hàm sinh dữ liệu này là sẽ tạo ra cho chúng ta một vài mẫu dữ liệu mới dự trên các mẫu dữ liệu đã sẵn có. Mục đích của nó để làm phong phú thêm dữ liệu cho tập training giúp mô hình của chúng ta học được tốt trong nhiều trường hợp hơn. Phương pháp này gọi là Data augumentation có thể minh họa trong hình sau:
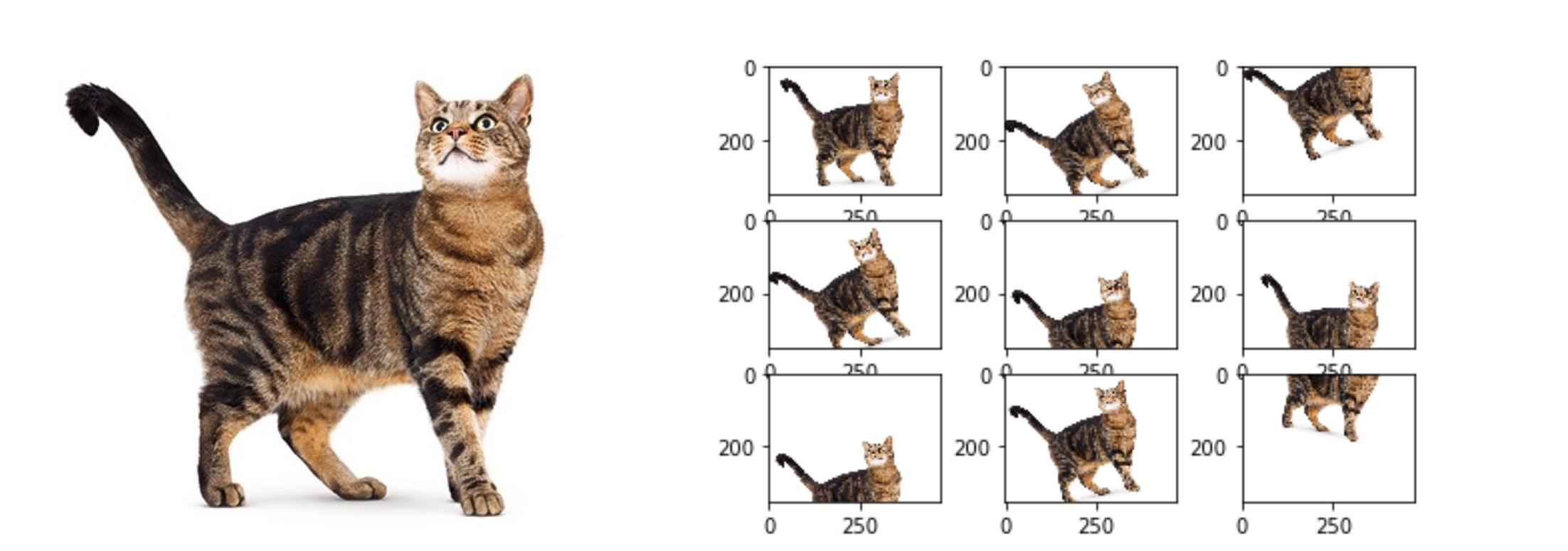
trong đó chúng ta cần lưu ý đến một vài tham số quan trọng:
- rotation_range: chúng ta sẽ xoay ảnh ngẫu nhiên trong khoảng 'rotation_range' độ
- awidth_shift_range: cắt ngẫu nhiên một phần chiều rộng theo tỷ lệ
- height_shift_range: cắt ngẫu nhiên một phần chiều cao theo tỷ lệ
- rescale: chuẩn hóa hay còn gọi là normalize dữ liệu, giúp đưa giá trị của dữ liệu về khoảng 0..1 giúp quá trình training được nhanh hơn
- shear_range cắt ngẫu nhiên một góc theo chiều kim đồng hồ.
- horizontal_flip: lật ảnh theo chiều ngang, ở đây chúng ta set bằng False vì dữ liệu chúng ta là chữ, lật ngược ảnh sẽ làm ảnh hưởng đến độ chính xác dữ liệu
- vertical_flip lật ảnh theo chiều dọc, ở đây chúng ta set bằng False vì dữ liệu chúng ta là chữ, lật ngược ảnh sẽ làm ảnh hưởng đến độ chính xác dữ liệu
Vậy là chúng ta đã viết xong hàm sinh dữ liệu và các phương pháp xử lý dữ liệu cho ảnh đầu vào sử dụng để training. Chúng ta sẽ cần phải định nghĩa cho tập test nữa tuy nhiên trên tập test thì sẽ đơn giản hơn nhiều:
# Testing generator test_datagen = ImageDataGenerator(rescale=1./255)
Tại sao lại đơn giản như vậy. Bởi vì chúng ta luôn nhớ một nguyên tắc là
Dữ liệu test là dữ liệu mà mô hình hoàn toàn chưa biết chính vì thế chúng ta không được xử lý gì trên đó.
Bước này đơn giản chúng ta chỉ chuẩn hóa dữ liệu về khoảng 0..1 mà thôi.
Định nghĩa model hyperparameters
BATCH_SIZE = 256 N_CLASSES = 3036 LR = 0.001 N_EPOCHS = 50 IMG_SIZE = 96
Chúng ta cần định nghĩa các tham số đã rất quen thuộc trong bất kể mô hình học máy nào. Thông thường một số tham số như LR - Learning Rate hay N_EPOCHS - số lần training các bạn sẽ phải tự tinh chỉnh tùy vào thuật toán học của các bạn. Số lượng BATCH_SIZE tùy thuộc vào cấu hình máy của các bạn.
Truyền dữ liệu cho train_generator và test_generator
Sau khi đã khai báo ở trên, việc chúng ta cần làm là truyền dữ liệu vào cho ảnh.
train_generator = train_datagen.flow_from_directory( 'training_data', # this is the target directory target_size=(IMG_SIZE, IMG_SIZE), # all images will be resized to 150x150 batch_size=BATCH_SIZE, class_mode='sparse')
và
validation_generator = test_datagen.flow_from_directory( 'testing_data', target_size=(IMG_SIZE, IMG_SIZE), batch_size=BATCH_SIZE, class_mode='sparse')
Có một vài thứ cần phải giải thích tại đây.
- Thư mục training_data và testing_data đều được tổ chức với 3036 thư mục con tương ứng với ảnh của 3036 chữ cái tiếng Nhật. Dữ liệu này đã được mình shuffle tức là xáo trộn lên để đảm bảo việc phân phối dữ liệu giữa các class trong các tập là đồng đều.
- target_size: là kích thước ảnh các bạn muốn resize về, điều này tùy thuộc vào mô hình mà các bạn sẽ sử dụng để training dữ liệu. Kích thước của anh phải tương ứng với đầu vào của mô hình
- class_mode='sparse': tham số này nhằm nói cho mô hình biết dữ liệu class của chúng ta thuộc kiểu sparse chứ không phải kiểu categorical hay còn gọi là one-hot encoder. Hiểu đơn giản thì chúng ta có 3036 chữ tiếng Nhật thì kiểu sparse sẽ biểu diễn mỗi class thành một số tự nhiên, còn categorical sẽ biểu diễn mỗi class là một vector one hot. OK chưa các bạn.
Thông thường các bạn sẽ phải tự build mô hình từ đầu tuy nhiên trong này mình sử dụng Keras nên nó đã định nghĩa cho mình vài mô hình Deep Learning khá nổi tiếng rồi. Các bạn chỉ cần chạy về thôi. Ở đây mình lựa chọn MobileNet - vì sao ư? Đơn giản là Mobile Net cho hiệu năng rất tốt, chạy rất nhanh chính vì thế nó rất thích hợp để chạy trên trình duyệt - browser của các bạn
from keras.applications.mobilenet import MobileNet model = MobileNet(input_shape=(IMG_SIZE, IMG_SIZE, 3), include_top=True, classes=N_CLASSES, weights=None)
Đơn giản như vậy thôi. Ở đây mình sử dụng lại toàn bộ kiến trúc mạng của MobileNet kể cả các lớp Dense cuối cùng. Ngoài ra có một lưu ý nữa các bạn cần lưu ý. Nếu như các bạn không set weights = None thì mặc định Mobilenet sẽ sử dụng weights đã được training từ tập dữ liệu ImageNet. Việc này là cần thiết nếu như các bạn định sử dụng phương pháp Transfer Learning tuy nhiên trong bài này có vẻ như Transfer Learning không có ý nghĩa cho lắm bởi vì tập dữ liệu của chúng ta là chữ viết tay trong khi ImageNet là phân loại rất nhiều hình ảnh như chó mèo lợn gà ngan ngỗng... nên nó chỉ phù hợp với những bài toán nhận dạng hình ảnh trong doimain của nó mà thôi. Ở đây đặt weights=None chúng ta sẽ training lại mạng MobileNet trên tập dữ liệu của chúng ta.
Để xem kiến trúc mô hình chúng ta có thể sử dụng lệnh sau
model.summary()
Kết quả như sau:

Chúng ta có khoảng hơn 6 triệu tham số phải tối ưu trong quá trình training.
Định nghĩa callbacks
Việc định nghĩa callbacks của mô hình giống như việc chúng ta sẽ lưu lại những thời kỳ hoàng kim của lịch sử training .Nói hoa mỹ thì có thể như vậy, nhưng các bạn cứ hiểu đơn giản là callbacks là các hàm chúng ta sử dụng để theo dõi quá trình training của mô hình và lưu lại những lần mô hình đạt kết quả tốt nhất. Trong bài viết này mình chỉ sử dụng ModelCheckpoint để lưu lại mô hình tốt nhất.
# Training from keras.callbacks import ModelCheckpoint model_file = "models_4/weights-improvement-{epoch:02d}-{val_loss:.2f}.hdf5" checkpoint = ModelCheckpoint(model_file, monitor='val_loss', verbose=1, save_best_only=True, mode='min') callbacks_list = [checkpoint]
các bạn phải tạo thư mục models_4 nhằm lưu trữ các trọng số được tối ưu. Ở đây giá trị để so sánh giúp chúng ta biết được khi nào mô hình đạt kết quả tốt là val_loss. Các bạn cũng có thể sử dụng val_accuracy tuy nhiên nó không thể hiện đúng bản chất của việc training. Bởi vì việc training là tìm các điểm tối ưu nên chúng ta kì vọng rằng với gíá trị val_loss nhỏ nhất sẽ đưa mô hình đến kết quả tối ưu tốt nhất.
Compile mô hình
model.compile(loss=keras.losses.sparse_categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy'])
Ở đây chúng ta sử dụng hàm mất mát là sparse_categorical_crossentropy do dữ liệu của chúng ta được đọc theo kiểu class là sparse. Hàm tối ưu chúng ta sử dụng là Adadelta các bạn cso thể sử dụng một số hàm khác như Adam, SGD, Momentum ... để thấy được sự khác biệt trong kết quả nhé.
OK vậy là chúng ta đã xong bước chuẩn bị rồi. Giờ chúng ta tiến hành training mô hình thôi.
Đây là bước quan trọng và cũng cực nhọc nhất trong quá trình thực hiện một bài toán về Deep Learning bởi vì nó ngốn rất nhiều thời gian của các bạn. Nếu như các bạn không có một GPU đủ tốt thì mình không khuyến khích các bạn chạy bước này đởn giản vì có thể máy của các bạn sẽ bị treo và không làm được gì khác cả. Lúc này các bạn có thể bỏ qua bước này và đến bước tiếp theo sử dụng pretrained model của mình luôn
model.fit_generator( train_generator, steps_per_epoch=576840 // BATCH_SIZE, epochs=50, validation_data=validation_generator, validation_steps=30360 // BATCH_SIZE, callbacks=callbacks_list)
Và ngồi chờ nó chạy thôi. Mình đang training với 50 epochs trên máy có GPU GTX 1080Ti các bạn có thể theo dõi kết quả tại epochs thứ 7 của mình:
Epoch 1/50 2253/2253 [==============================] - 898s 399ms/step - loss: 5.1680 - acc: 0.1007 - val_loss: 3.6318 - val_acc: 0.2318 Epoch 00001: val_loss improved from inf to 3.63177, saving model to models_4/weights-improvement-01-3.63.hdf5 Epoch 2/50 2253/2253 [==============================] - 899s 399ms/step - loss: 0.8022 - acc: 0.7814 - val_loss: 0.4588 - val_acc: 0.8706 Epoch 00002: val_loss improved from 3.63177 to 0.45881, saving model to models_4/weights-improvement-02-0.46.hdf5 Epoch 3/50 2253/2253 [==============================] - 894s 397ms/step - loss: 0.2622 - acc: 0.9269 - val_loss: 0.2270 - val_acc: 0.9375 Epoch 00003: val_loss improved from 0.45881 to 0.22699, saving model to models_4/weights-improvement-03-0.23.hdf5 Epoch 4/50 2253/2253 [==============================] - 898s 399ms/step - loss: 0.1652 - acc: 0.9541 - val_loss: 0.2404 - val_acc: 0.9329 Epoch 00004: val_loss did not improve Epoch 5/50 2253/2253 [==============================] - 892s 396ms/step - loss: 0.1237 - acc: 0.9661 - val_loss: 0.1482 - val_acc: 0.9592 Epoch 00005: val_loss improved from 0.22699 to 0.14815, saving model to models_4/weights-improvement-05-0.15.hdf5 Epoch 6/50 2253/2253 [==============================] - 891s 396ms/step - loss: 0.0991 - acc: 0.9728 - val_loss: 0.1910 - val_acc: 0.9484 Epoch 00006: val_loss did not improve Epoch 7/50 1969/2253 [=========================>....] - ETA: 1:51 - loss: 0.0845 - acc: 0.9771
Mỗi epochs chạy mất khoảng 15 phút. Vậy chạy hết 50 epochs các bạn sẽ mất khoảng 12.5 giờ. Tức là các bạn có thể cắm máy chạy xuyên đêm. (Tất nhiên là với cấu hình máy có GPU như của mình nhé). Như các bạn đã thấy tại epochs thứ 7 chúng ta có thể đánh giá mô hình bằng một vài tham số như sau:
Mô hình tốt nhất đạt được:
loss: 0.1237 - acc: 0.9661 - val_loss: 0.1482 - val_acc: 0.9592
do mới ở epochs thứ 7 nên chúng ta vẫn có thể kì vọng val_loss sẽ giảm sâu hơn nữa. Đợi chờ là hạnh phúc thôi. Thời điểm mình viết bài này đang là 19h15 phút. Chúng ta sẽ để máy training và ngày mai lên xem kết quả nhé. Còn bạn nào không chạy được thì cũng đừng lo, các bạn chỉ cần hiểu bản chất của mô hình thôi, việc training cứ để mình lo. Các bạn sẽ chỉ cần tải pre-trained model về vài chạy thôi. Dễ như ăn kẹo vậy
Sau khi chúng ta tiến hành training thuật toán khoảng 50 epochs thì chúng ta thu được kết quả như sau:
Epoch 00028: val_loss improved from 0.03998 to 0.03460, saving model to models_4/weights-improvement-28-0.03.hdf5 Epoch 29/50 2253/2253 [==============================] - 879s 390ms/step - loss: 0.0203 - acc: 0.9945 - val_loss: 0.0366 - val_acc: 0.9917 Epoch 00029: val_loss did not improve Epoch 30/50 2253/2253 [==============================] - 878s 390ms/step - loss: 0.0192 - acc: 0.9948 - val_loss: 0.0419 - val_acc: 0.9903 Epoch 00030: val_loss did not improve Epoch 31/50 2253/2253 [==============================] - 882s 391ms/step - loss: 0.0182 - acc: 0.9952 - val_loss: 0.0326 - val_acc: 0.9929 Epoch 00031: val_loss improved from 0.03460 to 0.03261, saving model to models_4/weights-improvement-31-0.03.hdf5 Epoch 32/50 2253/2253 [==============================] - 880s 391ms/step - loss: 0.0181 - acc: 0.9952 - val_loss: 0.0489 - val_acc: 0.9889 Epoch 00040: val_loss did not improve Epoch 41/50 2253/2253 [==============================] - 899s 399ms/step - loss: 0.0145 - acc: 0.9961 - val_loss: 0.0396 - val_acc: 0.9912 Epoch 00041: val_loss did not improve Epoch 42/50 2253/2253 [==============================] - 898s 399ms/step - loss: 0.0138 - acc: 0.9963 - val_loss: 0.0301 - val_acc: 0.9924 Epoch 00042: val_loss improved from 0.03261 to 0.03010, saving model to models_4/weights-improvement-42-0.03.hdf5 Epoch 43/50 2253/2253 [==============================] - 898s 398ms/step - loss: 0.0139 - acc: 0.9961 - val_loss: 0.0332 - val_acc: 0.9925 Epoch 00043: val_loss did not improve Epoch 44/50 2253/2253 [==============================] - 897s 398ms/step - loss: 0.0135 - acc: 0.9964 - val_loss: 0.0324 - val_acc: 0.9926 Epoch 00044: val_loss did not improve Epoch 45/50 2253/2253 [==============================] - 900s 400ms/step - loss: 0.0138 - acc: 0.9963 - val_loss: 0.0334 - val_acc: 0.9922 Epoch 00049: val_loss did not improve Epoch 50/50 2253/2253 [==============================] - 877s 389ms/step - loss: 0.0123 - acc: 0.9966 - val_loss: 0.0485 - val_acc: 0.9896 Epoch 00050: val_loss did not improve
các bạn thấy có những bước mà val_loss đạt giá trị nhỏ nhất là step thứ 42, sau đó val_loss có dấu hiệu không tăng thêm được nữa. Mô điều dễ nhận thấy là train_loss đã xuống khá sâu và độ chính xác trên tập training đã gần đạt 100% chứng tỏ mô hình của chúng ta đã học rất tốt trên tập training. Nếu training nữa thì có thể sẽ dẫn đến hiện tượng overfitting thế nên chúng ta sẽ lấy mô hình tốt nhất tại step thứ 42 này. Kết quả của mô hình tại bước này là
Epoch 42/50 2253/2253 [==============================] - 898s 399ms/step - loss: 0.0138 - acc: 0.9963 - val_loss: 0.0301 - val_acc: 0.9924
Ở đây chúng ta sử dụng hai độ đo là loss và accuracy để đánh giá. Các bạn nếu có thời gian có thể tìm hiểu thêm một số độ đo khác để đánh giá mô hình như precision, độ hồi tưởng recall hay độ đó F1-Score để đánh giá mô hình chính xác hơn nhé.
Như các bạn đã biết, Tensorflow JS là một nền tảng mới của Tensorflow sử dụng để chạy các mô hình Deep Learning trên trình duyệt. Nhưng trước tiên muốn thực hiện chúng các bạn cần phải cài đặt dependecies để convert mô hình của chúng ta sang định dạng này.
pip install tensorflowjs
Các bạn nên cài nó sang một môi trường ảo virtualenv độc lập tránh bị xung đội với các môi trường lập trình sẵn có. Tiếp theo để convert sang TF JS các bạn cần phải load lại weights tại step thứ 42 mà chúng ta đã lưu đã :
model.load_weights('models_4/weights-improvement-42-0.03.hdf5')
Do bước training các bạn có thể không training được nên các bạn có thể download trực tiếp model này tại đây
Ngoài ra các bạn nên tách bước convert thành một file riêng để cho thuận tiện. Muốn làm được điều này các bạn cần lưu lại toàn bộ kiến trúc của mô hình dưới một file .json như sau:
with open("model_mobilenet.json", "w") as json_file:
json_file.write(model.to_json())
các bạn cũng có thể download kiến trúc của mô hình mình đã training tại đây
Bây giờ các bạn sẽ cần thực hiện các bước để convert sang Tensorflow JS. Các bạn đặt tên một notebook mới, lựa chọn môi trường ảo mà các bạn đã cài đặt tensorflowjs, load lại mô hình vừa lưu.
from keras.models import model_from_json
from keras.utils.generic_utils import CustomObjectScope
# Load pretrained model
with CustomObjectScope({'relu6': keras.applications.mobilenet.relu6,'DepthwiseConv2D': keras.applications.mobilenet.DepthwiseConv2D}):
model = model_from_json(open('model_mobilenet.json').read())
model.load_weights('models_4/weights-improvement-42-0.03.hdf5')
Sau đó việc convert sang TF JS rất đơn giản các bạn chỉ cần chạy lệnh sau
import tensorflowjs as tfjs tfjs.converters.save_keras_model(model, 'model_mobilenet')
Lúc này mô hình sẽ được lưu trong thư mục model_mobilenet có định dạng như sau:
Các bạn thấy mô hình của chúng ta khá nhẹ nên việc load trên web sẽ đơn giản hơn nhiều. OK chúng ta đã hoàn thành xong việc load trên Web và cuối cùng chúng ta sẽ đi đến bước quan trọng và được mong chờ nhất đó chính là Deployment - triển khai mô hình của chúng ta lên trình duyệt. Bước này mình sẽ nói thật kĩ nhé
Trong phần này mình sẽ giải thích một số bước xử lý đơn giản trên Tensorflow JS mà các bạn có thể sử dụng. Nhưng trước hết các bạn có thể clone code mà mình đã làm theo repo sau. Ở đây mình chỉ làm một ví dụ đơn giản thôi. Trong phần này lưu ý quan trong nhất có các thành phần sau:
Thư mục model
Thư mục này chứa model mà các bạn đã export ra từ lúc nãy.
File mapping kanji
Các bạn có thể tìm thấy file này trong thư mục js/kanji_classes.js file này mình đã tạo sẵn cho các bạn chỉ việc xài thôi
const KANJI_CLASSES = {
0: '亜',
1: '唖',
2: '娃',
3: '阿',
4: '哀',
5: '愛',
6: '挨',
7: '姶',
8: '逢',
9: '葵',
10: '茜',
11: '穐',
12: '悪',
13: '握',
14: '渥', ....
}
Mục đích cơ bản chúng ta sẽ sử dụng nó để mapping các class của mô hình ra thành các chữ Kanji tương ứng
File xử lý chính
File xử lý chính của chúng ta là js/app.js chúng ta sẽ nói rõ hơn một vài phần trong file này. Ở đây các hàm vẽ trên HTML Canvas không thuộc phạm vi của bài viết này nên các bạn tự tham khảo code của mình nhé. Mình sẽ chỉ nói các hàm chính xử lý liên quan đến Deep Learing thôi.
Hàm load_model()
Chúng ta sử dụng hàm này để load model mà chúng ta vừa training
//------------------------------------- // loader for model //------------------------------------- async function loadModel() { console.log("model loading.."); // clear the model variable model = undefined; // load the model model = await tf.loadModel("./model/model.json"); console.log("model loaded.."); } loadModel();
Model được lưu tại thư mục model và chúng ta load nó trực tiếp ra bằng lệnh tf.loadModel(). Lưu ý rằng load model có thể mất một khoảng thời gian tùy vào cấu hình máy của các bạn. Ở đây mình sử dụng console.log để in ra thông báo khi model đã load thành công. Các bạn có thể sử dụng một vài package khác để tạo thêm hiệu ứng cho đẹp mắt.
Hàm xử lý dữ liệu đầu vào
Chúng ta lưu ảnh đầu vào trên HTML Canvas nên chúng ta cần phải xây dựng một hàm để xử lý dữ liệu đầu vào.
//----------------------------------------------- // preprocess the canvas //----------------------------------------------- function preprocessCanvas(image) { // resize the input image to target size of (1, IMG_SIZE, IMG_SIZE, 3) let tensor = tf.fromPixels(image) .resizeNearestNeighbor([IMG_SIZE, IMG_SIZE]) .expandDims() .toFloat(); return tensor.div(255.); }
trong hàm này chúng ta sẽ thực hiện resize ảnh về đúng kích thước ảnh đầu vào trên model hiện tại đang là 96x96 sau đó chuẩn hoá lại dữ liệu để đưa vào mô hình. Các bạn thấy các bước này giống y hệt như bước sinh dữ liệu trong phần training phải không?. Sau khi xử lý dữ liệu rồi chúng ta sẽ đi đến hàm quan trọng nhất đó chính là hàm dự đoán chữ số nhé
Hàm dự đoán chữ Kanji
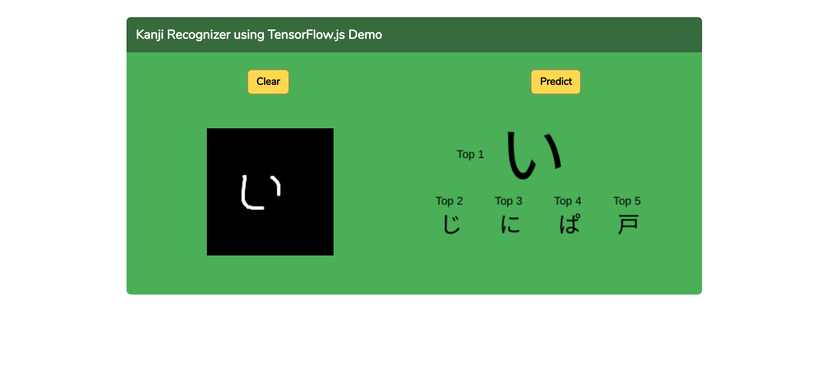
//-------------------------------------------- // predict function //------------------------------------------ async function predict() { // preprocess canvas let tensor = preprocessCanvas(canvas); // make predictions on the preprocessed image tensor let predictions = await model.predict(tensor).dataSync(); // get the model's prediction results let top_k = getTopK(predictions, TOP_K) drawTopResult(top_k) }
Hàm này sẽ lấy dữ liệu từ canvas đi qua hàm xử lý dữ liệu rồi dự đoán bằng model đã được load. Kết quả được dự đoán sẽ được xử lý trong hàm getTopK tức là lấy ra top những chữ dự đoán chính xác nhất. Hàm này như sau
//--------------------- // Get top_k function //--------------------- function getTopK(predictions, k){ // Input: predictions is the output dataSync of model.predict() function top_k = Array.from(predictions) .map(function(p, i){ return { probability: p, className: KANJI_CLASSES[i] }; }).sort(function(a,b){ return b.probability - a.probability; }).slice(0, TOP_K); return top_k }
Vẽ kết quả trên trình duyệt
Sau khi có top K từ mô hình các bạn có thể vẽ lại kết quả của mô hình trả ra trên canvas. Mình cũng không rành về phần này lắm nên cách làm của mình khá đơn giản đó là fill trực tiếp dữ liệu ra các pixel cố định trên canvas. Các bạn có thể thực hiện nó theo cách khác nhé. Ở đây mình chỉ làm theo cách đơn giản thôi
function drawTopResult(top_k){ result_ctx.clearRect(0, 0, result_ctx.canvas.awidth, result_ctx.canvas.height); var best_character = top_k[0]['className'] var top_2_character = top_k[1]['className'] var top_3_character = top_k[2]['className'] var top_4_character = top_k[3]['className'] var top_5_character = top_k[4]['className'] result_ctx.font = "10pt Arial"; result_ctx.fillText('Top 1', 30, 55); result_ctx.fillText('Top 2', 5, 110); result_ctx.fillText('Top 3', 75, 110); result_ctx.fillText('Top 4', 145, 110); result_ctx.fillText('Top 5', 215, 110); result_ctx.font = "60pt Arial"; result_ctx.fillText(best_character, 80, 80); result_ctx.font = "20pt Arial"; result_ctx.fillText(top_2_character, 10, 143); result_ctx.fillText(top_3_character, 80, 143); result_ctx.fillText(top_4_character, 150, 143); result_ctx.fillText(top_5_character, 220, 143); }
Oài đã trải qua 8 phần chắc các bạn đã nản lắm rồi phải không. Hi vọng các bạn đủ kiên nhẫn để đọc được đến những dòng này. Để chạy được kết quả các bạn có thể running theo câu lệnh sau:
python -m http.server
Ở đây mình đang sử dụng python3 nhé. Các bạn mở trình duyệt lên theo liên kết sau http://0.0.0.0:8000/ và thử kết quả nhé. Các bạn có thể xem demo trên link youtube mà mình đã gửi đầu bài. Các bạn lưu ý bật console log lên để check lúc nào model load xong thì mới thực hiện demo nhé.
Tại đây
Deep Learning thực sự rất thú vị và càng ngày càng tiến lại gần với những công nghệ truyền thống như Web, Mobile hơn. Tensorflow JS là một nền tảng rất hay ho để có thẻ deployment mô hình deep learning trên trình duyệt và nó rất thích hợp với những bạn đam mê làm web. Hi vọng bài viết này sẽ đem lại nhiều điều bổ ích cho các bạn. Viết đến đây cũng khá dài rồi mình xin phép được dừng phím tại đây. Hẹn gặp lại các bạn trong những bài viết sau.
