Xây dựng sơ bộ một hệ thống crawler
Mình vừa nhận được câu hỏi từ bạn đọc như sau: nên tiện đây mình sẽ viết 1 bài chia sẻ về hệ thống crawler mình đã làm sử dụng Scrapy gồm những gì. 1. Lấy xpath như thế nào? Để lấy được một đoạn mã xpath như thế này: //*[@id="aspnetForm"]/div[5]/div[1]/div[1]/div[1]/div[1]/div[1]/di ...
Mình vừa nhận được câu hỏi từ bạn đọc như sau:
 nên tiện đây mình sẽ viết 1 bài chia sẻ về hệ thống crawler mình đã làm sử dụng Scrapy gồm những gì.
nên tiện đây mình sẽ viết 1 bài chia sẻ về hệ thống crawler mình đã làm sử dụng Scrapy gồm những gì.
1. Lấy xpath như thế nào?
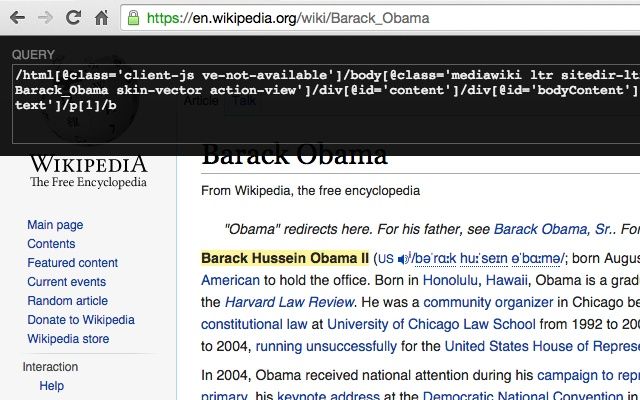
Để lấy được một đoạn mã xpath như thế này: //*[@id="aspnetForm"]/div[5]/div[1]/div[1]/div[1]/div[1]/div[1]/div[2]/h2/a mình hay dùng extension Xpath Helper. Tất nhiên mình có clone repo của extension này về và custome lại để cho thuận tiện việc lấy và insert template vào hệ thống. Trong 1 website, 1 xpath có thể đúng với page này nhưng lại không đúng với page kia nên bạn cần tối ưu xpath được suggest từ Xpath Helper sao cho phù hợp với nhiều page nhất.
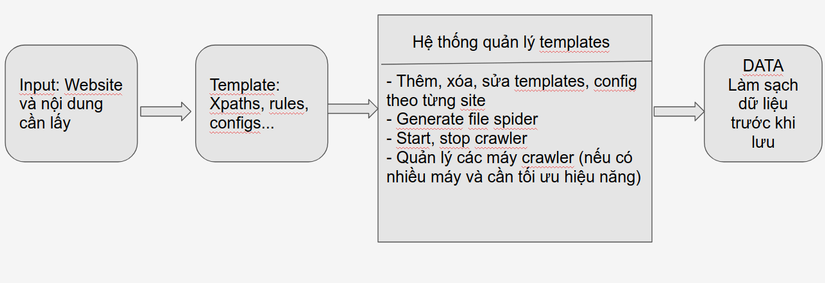
2. Hệ thống quản lý template
a, Backend
Có thể dùng luôn Flask để tạo hệ thống api với các chức năng thêm, xóa, sửa, generate file, start, stop một spider cho đỡ mất công học thêm thứ khác. Flask của python dùng thì max nhanh và đơn giản, chỉ cần import là sài thôi. Nên dùng databases NoSQL để lưu trữ thông tin các template vì tính linh động của chúng.
b, Frontend
React hoặc Angularjs xx . Mình làm backend là chính nên cũng không quan tâm lắm, cứ dễ dùng, nhiều support thì mình sài thôi. Trước thì mình có dùng React, nhưng giờ chuyển qua Angularjs xx rồi (xx là version của Angular nhé
