Mô phỏng hệ truy vấn hình ảnh với Machine Learning - Semantic Search (Phần 1)
Mô tả bài toán Chuẩn bị dữ liệu Mô hình chung cho bài toán Truy vấn hình ảnh với ảnh Truy vấn hình ảnh với chữ Kết quả Kết luận Keyword : Content-Based Image Retrieval (CBIR), Semantic Search, Visual Search, Similar Searching, Approximate Nearest Neighbor Search (ANN Search), ...
- Mô tả bài toán
- Chuẩn bị dữ liệu
- Mô hình chung cho bài toán
- Truy vấn hình ảnh với ảnh
- Truy vấn hình ảnh với chữ
- Kết quả
- Kết luận
-
Keyword: Content-Based Image Retrieval (CBIR), Semantic Search, Visual Search, Similar Searching, Approximate Nearest Neighbor Search (ANN Search), Product Quantization, Polysemous Codes.
-
Link Github: https://github.com/huyhoang17/Semantic_Search
-
Trong phần 1, mình sẽ đề cập tới các nội dung tại mục 1, 2, 3, 4. Các nội dung còn lại sẽ được đề cập và hoàn thiện tại phần 2 của blog.
-
Machine Learning và Deep Learning là 2 trong rất nhiều các từ khóa được quan tâm và chú ý trong cuộc cách mạng công nghệ 4.0 hiện nay. Từ các thành tựu trong Computer Vision, NLP (natural language processing), Hệ gợi ý hay hệ khuyến nghị (Recommender System) cho tới các bài toán cụ thể về y khoa, y sinh, xe tự hành, v..v ... Mỗi bài toán đều có các cách xử lí dữ liệu và mô hình riêng, nhưng nhìn chung đều hướng tới 1 mục đích: cải thiện đời sống và giúp ích cho xã hội nói chung và cho các doanh nghiệp, startup, .. nói riêng.
-
Với tiêu chí: "Learn by doing", trong bài blog lần này, chủ đề mà mình muốn nói tới là mô phỏng 1 hệ truy vấn (tìm kiếm) hình ảnh, tương tự như Google Image Search vậy. Nếu các bạn nào đã từng sử dụng qua các dịch vụ hay mạng xã hội như: Flickr hay Pinterest sẽ thấy 2 mạng xã hội này có các chức năng tìm kiếm liên quan đến ảnh khá thú vị và độc đáo. Lấy ví dụ với Pinterest, một trong những mạng xã hội về ảnh lớn nhất hiện nay, có 1 chức năng vô cùng hay ho là cắt và tìm kiếm ảnh trực tiếp ngay trên nền ứng dụng. Các ảnh được truy vấn ra đều tương đồng với phần ảnh bị cắt, kèm theo đó là những từ khóa (tag) liên quan tới phần ảnh được cắt ra, khá thú vị phải không nào =)

- Lấy 1 ví dụ khác với Flickr, 1 dịch vụ upload và chia sẻ ảnh chất lượng cao phổ biến trên toàn thế giới, cũng gần tương tự với cách làm của Pinterest, khi sử dụng machine learning để tìm kiếm các ảnh theo các nhãn (tag) khi người dùng nhập 1 từ khóa vào (vì đơn giản không phải ảnh nào cũng được người dùng gán tag cho ảnh, chưa kể đến việc các tag có thể không liên quan đến ảnh), và tìm kiếm các ảnh tương đồng. Các bạn có thể thấy được sự hữu ích của thuật toán qua ảnh GIF bên dưới =) That's magic =)

- Như các bạn có thể thấy, việc tìm tòi và áp dụng các bài toán ứng dụng machine learning cho doanh nghiệp đem lại những bước đột phá và kết quả đáng ngạc nhiên như vậy. Phần tiếp theo của bài blog này, mình sẽ nói sâu hơn về các thuật toán với các code minh họa kèm theo. Hi vọng sẽ giúp ích cho các bạn đang trong quá trình tìm hiều về Image Search Engine. Mọi ý kiến phản hồi và góp ý, các bạn vui lòng comment bên dưới bài post hoặc email về địa chỉ: phan.huy.hoang@framgia.com nhé! Cảm ơn các bạn!
1. Mô tả bài toán
- Mô phỏng 1 hệ truy vấn hình ảnh với một số vấn đề như sau:
- Word Embedding
- Image Embedding
- Tìm kiếm các từ khóa tương đồng với 1 từ khóa cho trước
- Tìm kiếm ảnh tương đồng với 1 ảnh cho trước
- Tìm kiếm ảnh dựa trên sự kết hợp về ý nghĩa của CÁC từ khóa truy vấn
- Phương pháp tìm kiếm tương đồng (Nearest Neighbor Search)
2. Chuẩn bị dữ liệu
- Tập dữ liệu mình sử dụng trong bài toán này là: Tiny-Imagenet. Khá tương đồng với tập dữ liệu phổ biến Imagenet nhưng nhỏ hơn nhiều và phù hợp với quá trình test thử mô hình.
- Tiny Imagenet bao gồm 200 classes, mỗi class gồm có 500 ảnh training, 50 ảnh validation, 50 ảnh test. Vậy là với dữ liệu để training chúng ta có 100.000 ảnh, 1 con số không hề nhỏ.
3. Mô hình chung cho bài toán
-
Trước khi có sự bùng nổ của deep learning hiện nay, các phương pháp xử lí ảnh truyền thống như: HOG, SIFT, .. được sử dụng khá nhiều. Tuy nhiên, với sự phát triển của Deep Learning trong vài năm trở lại đây, mạng neural của Deep Learning cũng được coi như 1 phương pháp Feature Extraction, điển hình là mạng neural network cơ bản CNN (Convolution Neural Network), thường được sử dụng với các bài toán liên quan xử lí ảnh và cho độ chính xác tốt hơn nhiều các phương pháp truyền thống.
-
Lấy ví dụ với 1 mạng CNN khá quen thuộc, đã từng đứng đầu đạt Top 5 Error trong Imagenet Classification Challenge 2014, VGG hay Visual Geometry Group:
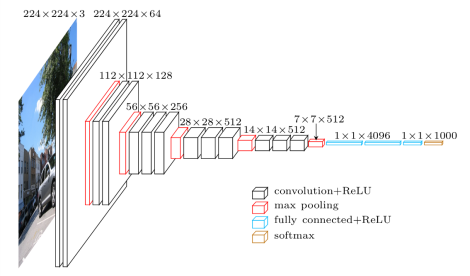
- Như các bạn có thể thấy, input của mạng VGG16 là 1 ảnh có kích thước 244x244x3 (pixels), output là 1 layer với 1000 node, tương ứng với 1000 class trong Imagenet, sử dụng Softmax với phân phối xác suất đầu ra ứng với từng class. Các lớp hidden layers ở giữa bao gồm các layer cơ bản của 1 mạng CNN như: lớp Convolution, Pooling (Max Pooling, Avegare Pooling, ..), Fully Connected Layer và Activation Function (Sigmoid, Tanh, Relu, ..). Như mình đã nói ở trên, mạng neural hoạt động cũng tương tự như 1 feature extraction, với các layer ở lớp đầu dùng để bóc tách các low level feature như: góc, cạnh, hình khối vật thể. Các layer ở lớp cao hơn thực hiện bóc tách cách high level feature, ứng với các đặc trưng riêng của từng đối tượng:
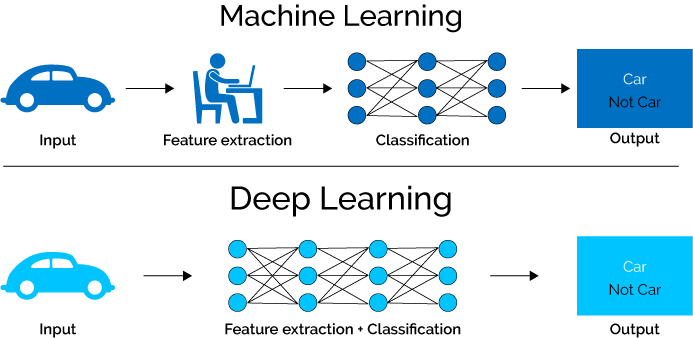
- 1 phương pháp thường được sử dụng để biểu diễn ảnh input đầu vào là thay vì sử dụng đầu ra cố định 1000 node với hàm softmax như ảnh bên trên, sau khi thực hiện training mô hình, ta có thể sử dụng các layer gần cuối như một feature extraction để biểu diễn cho ảnh đó. Việc chọn layer nào là tùy các bạn, có thể chọn layer fully connected ngay trước softmax hoặc output của layer max pooling cuối cùng, nhưng sẽ sử dụng các layer gần cuối. Các bạn có thể tìm hiểu thêm với 1 số từ khóa kèm theo, mình sẽ không đề cập quá sâu trong bài blog lần này: feature extraction, transfer learning, fine-tuning, image embedding
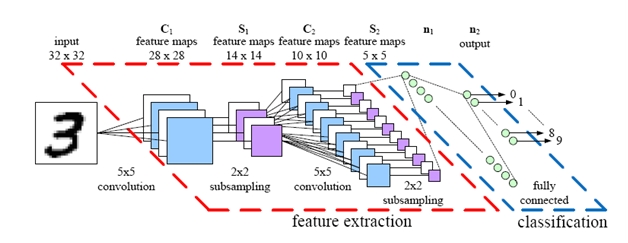
- Như ví dụ với ảnh bên trên, ta sử dụng đầu ra của lớp pooling cuối cùng làm feature extraction. Sau khi thực hiện flatten được 1 vector 1024 chiều chẳng hạn thì vector 1024D đó chính là biểu diễn cho tập dữ liệu ảnh của mình. Khi so sánh độ tương đồng giữa 2 ảnh, ta tính bằng một metric như: cosine, euclid, ... Khoảng cách càng nhỏ chứng tỏ sự tương đồng giữa 2 hay nhiều vector càng cao. Ở đây có 1 chú ý là mình sử dụng pretrained VGG16 model được huấn luyện trên tập dữ liệu Imagenet, tập dữ liệu mới của mình là tương đồng với imagenet (tiny-imagenet
