Bàn về vấn đạo đức trí tuệ nhân tạo: cần sớm hình thành bộ hướng dẫn nguyên tắc hoạt động của AI
Cả thế giới đang nhắc đến trí tuệ nhân tạo, nhưng một bước tiến vĩ đại của nhân loại. Nhưng liệu có mấy ai trong chúng ta đã có một bộ nguyên tắc hướng dẫn AI dành cho các bên liên quan như quản lý sản phẩm, khoa học dữ liệu và các nhà nghiên cứu machine learning để đảm bảo rằng AI an ...

Cả thế giới đang nhắc đến trí tuệ nhân tạo, nhưng một bước tiến vĩ đại của nhân loại. Nhưng liệu có mấy ai trong chúng ta đã có một bộ nguyên tắc hướng dẫn AI dành cho các bên liên quan như quản lý sản phẩm, khoa học dữ liệu và các nhà nghiên cứu machine learning để đảm bảo rằng AI an toàn và không thiên vị được sử dụng để phát triển các giải pháp dựa trên nó không?
Nếu câu trả lời cho các câu hỏi trên không phải là “có” thì bạn nên bắt đầu suy nghĩ về việc đặt ra nguyên tắc hướng dẫn AI để giúp mọi người từ nhóm điều hành quản lý sản phẩm đến các nhà khoa học dữ liệu lập kế hoạch, xây dựng, thử nghiệm, triển khai và quản lý các sản phẩm dựa trên AI của bạn. Khả năng phát triển nhanh chóng của các hệ thống dựa trên AI đã bắt đầu rung lên hồi chuông cảnh báo về các tác động, chuẩn mực đạo đức và trách nhiệm của các sản phẩm dựa trên AI được tích hợp vào các quy trình kinh doanh khác nhau. Không còn công ty nào có thể che giấu những thông tin liên quan đến IP và các vấn đề về quyền riêng tư.
Trong bài viết này, chúng ta sẽ tìm hiểu về một số nguyên tắc hướng dẫn AI mà bạn có thể dùng cho doanh nghiệp của mình. Chúng dựa trên những nguyên tắc của Google để phát triển các sản phẩm có sử dụng AI, bao gồm:
- Những lợi ích chung cho doanh nghiệp
- Tránh thiên vị, đối xử không công bằng với một nhóm người dùng
- Đảm bảo an toàn cho khách hàng (Không bị những rủi ro kinh doanh)
- Đáng tin cậy (Khách hàng có thể yêu cầu giải thích)
- Bảo mật dữ liệu khách hàng
- Quản lý liên tục
- Được xây dựng bằng các công cụ và framework AI tốt nhất
Sơ đồ sau đại diện cho nguyên tắc hướng dẫn chuẩn mực đạo đức trong AI:
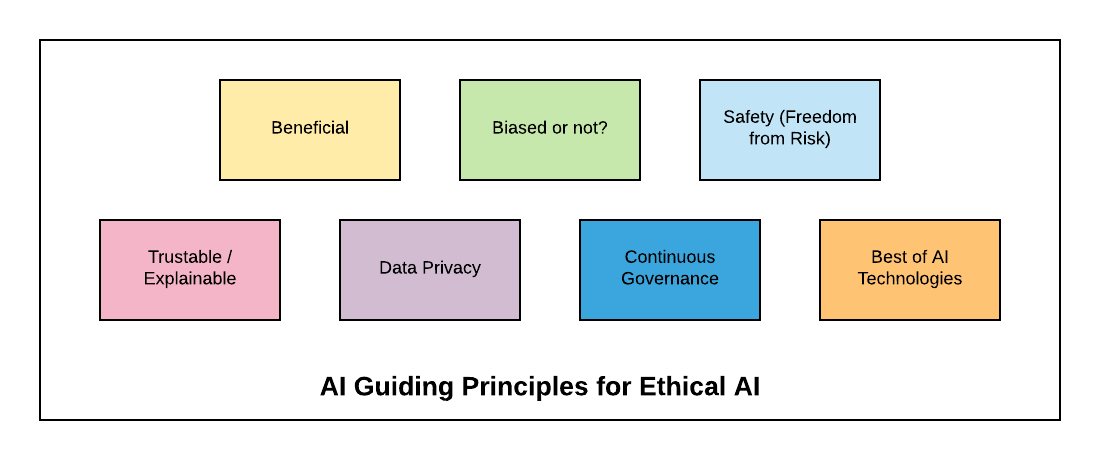
Những lợi ích chung cho doanh nghiệp
Các mô hình học tập AI / machine learning phải được xây dựng để giải quyết các vấn đề kinh doanh phức tạp, đồng thời đảm bảo rằng các lợi ích lớn hơn bất kỳ rủi ro nào do các mô hình gây ra. Sau đây là một vài ví dụ về các loại rủi ro khác nhau được đặt ra bởi các mô hình tương ứng:
Mô hình tin tức giả: Mô hình dự đoán tin tức có phải là tin giả hay không. Mô hình có độ chính xác cao 95% và thu hồi 85%. Việc thu hồi 85% cho thấy có một tập hợp các tin tức (mặc dù nhỏ hơn về số lượng) mà không được dự đoán là giả, và do đó, được lọc theo mô hình. Tuy nhiên, trong số tất cả các tin tức được dự đoán là giả, tỷ lệ chính xác 95% ngụ ý mô hình thực hiện tốt công việc dự đoán. Những lợi ích của mô hình này, theo ý kiến của tôi, lớn hơn tác hại được gây ra bởi các sai sót.
Mô hình chuẩn đoán và cảnh báo bệnh ung thư: Giả sử một mô hình được xây dựng để dự đoán ung thư. Độ chính xác của mô hình đi ra là 90%, có nghĩa là trong số tất cả các dự đoán của mô hình, 90% là chính xác. Tuy nhiên, giá trị thu hồi là 90%. Điều này đại diện cho thực tế là trong số những người đang thực sự bị ung thư, mô hình đã có thể dự đoán chính xác cho 90% người. Những người khác được dự đoán là âm tính. Điều đó có được chấp nhận không? Tôi không nghĩ vậy. Vì vậy, mô hình này sẽ không được chấp nhận, vì nó có thể sẽ làm tổn thương nhiều hơn nó giúp.
Tránh thiên vị đối xử không công bằng đối với một nhóm người dùng
Các mô hình AI / ML thường được đào tạo với các tập dữ liệu với giả định cơ bản rằng chúng không thiên vị. Thực tế thì lại ngược lại, trong khi xây dựng mô hình, cả bộ tính năng và dữ liệu được liên kết với các tính năng này sẽ cần được kiểm tra độ lệch. Sự thiên vị sẽ cần phải được kiểm tra, trong cả hai:
- Giai đoạn đào tạo mô hình
- Một khi mô hình được xây dựng và sẵn sàng để được thử nghiệm để di chuyển nó vào giai đoạn sản xuất.
Hãy xem xét một vài ví dụ để hiểu sự thiên vị trong tập dữ liệu đào tạo:
Thiên vị trong mô hình nhận dạng hình ảnh: Giả sử có một mô hình được xây dựng để xác định người trong một tấm ảnh. Việc phân biệt đối xử có thể thể hiện rõ nếu mô hình chỉ được đào tạo với hình ảnh có người da trắng. Do đó, mô hình – khi được thử nghiệm với hình ảnh mô tả những người có màu da khác nhau – sẽ không thể đưa ra kết quả chính xác.
Thiên vị trong mô hình tuyển dụng: Các mô hình được xây dựng để tuyển dụng có thể bị thiên vị như chỉ thuê nam hoặc nữ cho các vai trò cụ thể hoặc thuê những người có bộ kỹ năng cụ thể cho các vị trí riêng.
Chúng ta phải hiểu rằng có hai loại khác nhau của thiên vị. Một bác sĩ có thể sử dụng kinh nghiệm của họ để phân loại bệnh nhân bị một bệnh cụ thể, hay không. Điều này có thể được gọi là thiên vị tốt. Ngoài ra, một mô hình không nhận ra những người da màu được cho là phân biệt đối xử. Điều này có thể được gọi là sai lệch xấu. Mục đích của chúng ta là phát hiện những sai lệch như vậy và loại bỏ nó.
Đảm bảo an toàn cho khách hàng (Không bị những rủi ro kinh doanh)
Cần kiểm tra hiệu suất của một mô hình để giảm thiểu sai số một cách thích hợp. Điều này giúp đảm bảo sự tự do và không vướng phải các rủi ro liên quan đến chức năng kinh doanh. Chúng ta hãy lấy một ví dụ về một mô hình machine learning dự đoán liệu các đơn đặt hàng của người mua có thể được phân phối dựa trên điểm tín dụng của họ hay không.
Nếu mô hình không dự đoán chính xác rằng đơn đặt hàng sẽ được phân phối dưới dạng khoản phải thu, nhà cung cấp có thể gặp phải nguy cơ không nhận được thanh toán hóa đơn đúng hạn, điều này sẽ ảnh hưởng đến doanh thu của họ. Do đó, mô hình này không nên được dùng, chủ yếu là do chúng có thể tác động đến kinh doanh một cách tiêu cực dẫn đến mất doanh thu.
Đáng tin cậy (Khách hàng có thể yêu cầu giải thích)
Mô hình phải đáng tin cậy hoặc có thể giải thích được. Song song đó, khách hàng khi sử dụng có thể yêu cầu các thông tin chi tiết liên quan đến những tính năng nào đã tác động đến kết quả của dự đoán.
Bảo mật dữ liệu khách hàng
Là một phần của quá trình quản trị, bảo mật dữ liệu khách hàng phải được tôn trọng. Nếu khách hàng được thông báo rằng quyền riêng tư dữ liệu của họ sẽ được duy trì và dữ liệu của họ sẽ không được sử dụng cho bất kỳ mục đích nào liên quan đến kinh doanh mà không nhận được sự chấp thuận nào từ họ. Doanh nghiệp nên thiết lập nhóm QA hoặc nhóm kiểm toán để đảm bảo việc bảo mật dữ liệu khách hàng luôn được làm tốt.
Quản lý liên tục
Vòng đời mô hình machine learning bao gồm các khía cạnh liên quan đến một số điều sau đây:
- Dữ liệu
- Kỹ thuật tính năng
- Xây dựng mô hình (đào tạo / thử nghiệm)
- Đường ống / cơ sở hạ tầng ML
Là một phần của nguyên tắc hướng dẫn AI, các kiểm soát quản trị liên tục nên được đưa vào các khía cạnh kiểm toán liên quan đến tất cả các điều trên. Bao gồm:
Dữ liệu: Liệu mô hình có được đào tạo với tập dữ liệu cần được kiểm tra một cách liên tục theo cách thủ công hay tự động. Mặt khác, liệu dữ liệu không được phép sử dụng để xây dựng mô hình có được sử dụng không.
Tính năng Kỹ thuật: Tầm quan trọng của các tính năng đã được kiểm tra hay chưa. Liệu các tính năng dẫn xuất có sử dụng dữ liệu không được phép theo thỏa thuận bảo mật dữ liệu hay không.
Xây dựng mô hình: Liệu hiệu suất của mô hình là tối ưu. Liệu bài test mô hình có thiên vị. Liệu mô hình có được thử nghiệm trên các lát dữ liệu khác nhau hay không.
Đường ống ML: Liệu các đường ống ML có được bảo mật hay không.
Được xây dựng bằng các công cụ và framework AI tốt nhất
Bạn phải được đảm bảo rằng các mô hình AI được xây dựng bằng các công cụ và framework tốt nhất. Ngoài ra, những người tham gia xây dựng mô hình AI nên được huấn luyện đều đặn với các phương pháp hay nhất cùng tài liệu giáo dục mới nhất. Các công cụ và framework khác phải đảm bảo một số điều sau đây:
- Hầu hết các công nghệ AI tiên tiến như AutoML được sử dụng.
- Sử dụng những cách thực hành tốt nhất liên quan đến an toàn.
Techtalk via dzone
