Distributed System with DRuby
Khái niệm Hệ thống phân tán đơn giản chỉ là dịch word by word của từ tiếng anh Distributed System . Nếu đã từng bước một (hoặc vài chân) vào thế giới lập trình, ắt hẳn mọi người đã có ít nhất một lần nghe tới khái niệm phân tán. Trong phạm vi bài viết này, mọi người có thể hiểu phân tán như ...
Khái niệm
Hệ thống phân tán đơn giản chỉ là dịch word by word của từ tiếng anh Distributed System.
Nếu đã từng bước một (hoặc vài chân) vào thế giới lập trình, ắt hẳn mọi người đã có ít nhất một lần nghe tới khái niệm phân tán.
Trong phạm vi bài viết này, mọi người có thể hiểu phân tán như sau : Chia nhỏ công việc cần thực hiện (phân chia) thành nhiều công việc nhỏ và đem đi xử lý ở nhiều chỗ khác nhau (phát tán) để tăng tốc độ và hiệu quả xử lý.
Nói một cách cụ thể hơn sẽ là như thế này : Bạn có 1 công việc cần xử lý, thay vì giao cho một máy (một process - tiến trình) xử lý, bạn sẽ giao cho nhiều máy (nhiều process) xử lý nhiều phần khác nhau của công việc, kết quả của mỗi phần sẽ được tổng hợp lại, khiến công việc được xử lý xong xuôi.
Khoan đã, nếu nói như trên, để tăng tốc độ và hiệu quả xử lý của một công việc, chúng ta chẳng phải đã có xử lý đa luồng (multithread) rồi đó hay sao, việc gì phải cần một hệ thống phân tán làm gì cho phức tạp, vì quá trình truyền giữa các máy, đồng bộ chẳng phải khó khăn hơn không.
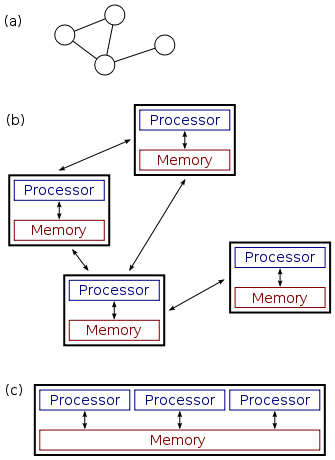
Well, thực tế thì multithread khá phát triển và thân quen với nhiều người hơn, nhất là đối với một ngôn ngữ script như Ruby thì khái niệm đó đã được triển khai khá tốt, khiến việc lập trình đa luồng đỡ vất vả hơn so với các ngôn ngữ khác. Có hai hướng tiếp cận trong lập trình đa luồng ở Ruby, đó là Fork và Thread. Trước khi tìm hiểu về Distributed System, chúng ta hãy lướt qua một chút về 2 khái niệm này để hiểu thêm vì sao lại có sự ra đời của Distributed System và đã được implement dưới cái tên là dRuby như thế nào.
Phân biệt Concurrency và Parallelism
Thông thường, nếu không có gì đặc biệt, một đoạn code sẽ được thực hiện bởi một tiến trình (process) tuần tự từ trên xuống dưới, với mục đích là giải quyết một nhu cầu nào đó trong cuộc sống.
Tuy nhiên, cuộc đời không phải lúc nào cũng chỉ tuân theo một thứ tự, sẽ có nhiều lựa chọn, yêu cầu mà chúng ta có thể xử lý đồng thời. Trong lập trình, một công việc có thể có nhiều xử lý thay vì phải thực hiện tuần tự, chúng ta có thể thực hiện cùng một lúc để tăng tốc độ xử lý. Lúc này khái niệm multithreading được đưa ra, với một mục tiêu muôn thuở : tối ưu tốc độ xử lý.
Đối với Ruby, có một câu nói mà vẫn hay được nhắc đi nhắc lại về multithread, đó là : Concurrency và Parallelism trong Ruby không giống nhau, không phải là một.
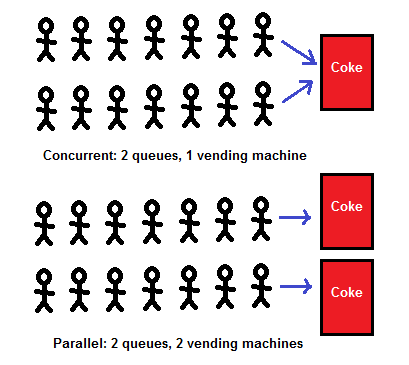
Nhìn hình minh họa, mọi người có thể hình dung qua được hai khái niệm này khác nhau như thế nào. Ở đây một tiến trình có thể coi như một cái máy bán Cocacola. 2 hàng người muốn mua coca tương đương với 2 công việc có thể xử lý đồng thời.
Trong trường hợp xử lý Concurrency (đồng thời), mỗi người trong 2 hàng sẽ lần lượt được mua cocacola, nhưng trong một thời điểm chỉ có một người được mua coca.
Ngược lại trong trường hợp xứ lý Parallelism (song song), mỗi người trong 2 hàng sẽ được phục vụ bởi 2 máy bán coca khác nhau, có nghĩa là cùng một thời điểm có 2 người được mua coca một lúc.
Ví dụ trên là minh chứng rõ ràng nhất cho sự khác nhau giữa Concurrency và Parallelism.
Mặc dù 2 tác vụ đều được xử lý theo một cách hiểu chung là cùng một lúc, tuy nhiên khi nói về bản chất, khái niệm Parallesim khắt khe hơn ở chỗ chúng cần được xử lý cùng một lúc song song với nhau, khác với Concurrency là một process có thể xử lý từng phần của 2 tác vụ, lúc tác vụ này, lúc tác vụ khác.
Sự khác nhau cơ bản về Parallelism và Concurrency như đã mô tả ở trên đã dẫn đến 2 khái niệm mà chúng ta hay sử dụng khi lập trình đa luồng trong Ruby, đó là Fork và Thread.
Fork và Thread trong Ruby
Fork
Fork là một cách để thực hiện multithreading thông qua việc tạo ra nhiều process.
Nếu như liên tưởng đến ví dụ máy bán coca ở trên, chúng ta có thể hiểu fork là việc tạo ra thêm máy bán coca khi có thêm người xếp hàng chờ.
Để hiểu thêm về Fork, chúng ta có thể làm một ví dụ nho nhỏ sau đây.
Chúng ta có một đoạn code dùng để gửi mail như sau :
class Mailer def self.deliver(&block) mail = MailBuilder.new(&block).mail mail.send_mail end Mail = Struct.new(:from, :to, :subject, :body) do def send_mail fib(30) puts "Email from: #{from}" puts "Email to : #{to}" puts "Subject : #{subject}" puts "Body : #{body}" end def fib(n) n < 2 ? n : fib(n-1) + fib(n-2) end end class MailBuilder def initialize(&block) @mail = Mail.new instance_eval(&block) end attr_reader :mail %w(from to subject body).each do |m| define_method(m) do |val| @mail.send("#{m}=", val) end end end end
Để chạy benchmark đoạn code trên, chúng ta có thể sử dụng như sau :
puts Benchmark.measure{ 100.times do |i| Mailer.deliver do from "eki_#{i}@eqbalq.com" to "jill_#{i}@example.com" subject "Threading and Forking (#{i})" body "Some content" end end }
Nếu chạy với cách tuần tự như trên, chúng ta có thể có kết quả như sau (chạy trên chip i3-4460 MRI 2.2.3):
15.250000 0.020000 15.270000 ( 15.304447)
Giờ chúng ta sẽ áp dụng Fork để tạo ra nhiều process xử lý việc gửi mail cùng một lúc như sau :
puts Benchmark.measure{ 100.times do |i| fork do Mailer.deliver do from "eki_#{i}@eqbalq.com" to "jill_#{i}@example.com" subject "Threading and Forking (#{i})" body "Some content" end end end Process.waitall }
Đây là cách implement theo đúng tiêu chuẩn Parallelism, có bao nhiêu hàng chờ thì sẽ có bấy nhiêu máy bán coca phục vụ. Nếu chạy lại đoạn code trên thì thời gian sẽ được giảm đáng kể:
0.000000 0.030000 27.000000 ( 3.788106)
Có thể thấy tốc độ được cải thiện gấp gần 50 lần. Tuy nhiên theo quy luật ở đời, không có gì đạt được một cách dễ dàng mà không phải trả giá, nếu kiểm tra lượng memory, chúng ta có thể thấy lượng ram tiêu thụ cũng gần gấp 50 lần :
Đây chính là trade-off của fork: việc tạo ra nhiều process một lúc sẽ tiêu tốn số lượng ram gấp nhiều lần so với 1 process. Thử tưởng tượng 1 process của bạn tốn 30MB memory, nếu fork tạo ra 100 process gửi mail trên kia, memory sẽ nhanh chóng cán mốc 3GB, và out of memory không còn là một giấc mơ nữa.
Thread
Ngoài cách tạo ra nhiều process ở trên, chúng ta có một cách khác để thực hiện việc xử lý đa luồng, đó là sử dụng Thread (cái này chắc mọi người sẽ thấy quen thuộc hơn so với cái What does the Fork say trên kia ^^).
threads = [] puts Benchmark.measure{ 100.times do |i| threads << Thread.new do Mailer.deliver do from "eki_#{i}@eqbalq.com" to "jill_#{i}@example.com" subject "Threading and Forking (#{i})" body "Some content" end end end threads.map(&:join) }
Mỗi process của Ruby sẽ có một Main Thread, và một process có thể có nhiều Thread. Việc chúng ta làm ở trên có ý nghĩa là tạo ra thêm nhiều Thread, mang ý nghĩa thông báo cho process như sau: Này, cái đoạn code gửi mail ở trên kia có thể xử lý đồng thời được đấy, 100 lần gửi mail này có thể thực hiện cái nào trước cũng được, không phụ thuộc lẫn nhau đâu.
Process Ruby sẽ hiểu được ý trên và thực hiện các Thread liên tục luân phiên nhau, với kết quả như sau :
13.710000 0.040000 13.750000 ( 13.740204)
Trông có vẻ chẳng khác gì so với nếu chạy không Thread nhỉ. Ở đây có một việc cần làm rõ, đó là MRI hiện đang sử dụng GIL (Global Interpreter Lock), một thứ mà khiến cho Thread hoạt động mà không hoạt động.
Nguyên nhân là bởi vì GIL sẽ không support việc 1 process chạy nhiều thread một lúc, mà chỉ cho 1 process thực hiện 1 thread 1 lúc. Việc này sẽ dẫn đến kết quả là ví dụ với 100 thread được tạo ra ở trên, Ruby sẽ thực hiện 100 thread đổng thời nhưng không song song (1 máy bán coca cho 100 hàng 1 lúc). Kết quả là hiệu năng không được cải thiện là mấy.
Mọi người có thể đọc thếm về GIL ở đây
Ưu và nhược điểm của Fork và Thread
Vậy là chúng ta đã có một cái nhìn sơ lược về Fork và Thread.
Một số ưu điểm và nhược điểm của 2 cách tiếp cận trên sẽ được mô tả dưới đây.
Process
- Dùng nhiều memory
- Nếu process chính (dùng để tạo các fork process) kết thúc trước các process con, các process con có thể trở thành zombie process (không được clean up, chiếm dụng bộ nhớ). -> Memory Leak.
- Để chuyển qua lại giữa các process, OS sẽ phải tốn công sức do phải lưu trữ và reload lại mọi thứ của 1 process
- Các process được fork sẽ được cấp một vùng nhớ riêng (khiến cho các process có tính isolation, không liên quan lẫn nhau)
- Yêu cầu giao tiếp giữa các process với nhau khi cần đồng bộ
- Khởi tạo và clean up mất thời gian
- Dễ code và debug
Threads
- Dùng ít memory (so với Fork)
- Không có hiện tượng zombie threads
- Vì dùng chung memory nên tốn ít tài nguyên hơn so với forrt
- Cần xử lý vấn đề về các vùng nhớ dùng chung giữa các process
- Các process có thể giao tiếp thông qua queues và các vùng nhớ chung
- Khởi tạo và clean up nhanh
- Phức tạp hơn cho việc code và debug
Chúng ta có thể nhận thấy cho dù là Fork hay Thread thì đều có những điểm mạnh và điểm yếu riêng. Tuy nhiên một vấn đề chung mà cả hai hướng tiếp cận này đều đang gặp phải, đó là việc xử lý dù cho có chia ra thành nhiều process hay thread đi chăng nữa, thì tất cả đều đang được thực hiện trên cùng một máy tính.
Ngày nay, với sự xuất hiện của các hệ phân tán ngày càng nhiều, các tác vụ nặng nếu chỉ chạy trên một máy tính có thể sẽ mất rất nhiều thời gian. Thay vào đó, đã có những hướng phát triển việc thực thi công việc trên nhiều máy. Và dRuby là một cách tiệp cẩn để có thể làm được việc chia sẽ công việc thực thi trên nhiều máy bằng ngôn ngữ Ruby. Sang phần tiếp theo, chúng ta sẽ cùng tìm hiểu cấu trúc và nguyên lý làm việc của dRuby
Thật ra, dRuby là một library căn bản, đã được phát triển và tồn tại trong các phiên bản Ruby từ khá lâu. dRuby là từ viết tắt của distributed Ruby. Chúng ta có thể sử dụng dRuby mà không cần cài đặt bất cứ một gem gì.
Đúng như tên gọi của nó, dRuby sẽ giúp các bạn viết các ứng dụng phân tán, dựa trên mô hình Client-Server cơ bản.
Mô hình của dRuby : Server và Client
Về cơ bản, mô hình Server và Client chỉ đơn giản mô tả hai đối tượng : Một đối tượng dùng để chứa các tài nguyên/công việc được gọi là Server, và một đối tượng dùng để truy vấn tài nguyên/công việc được gọi là Client. Client và Server sẽ giao tiếp với nhau thông qua Request và Response.
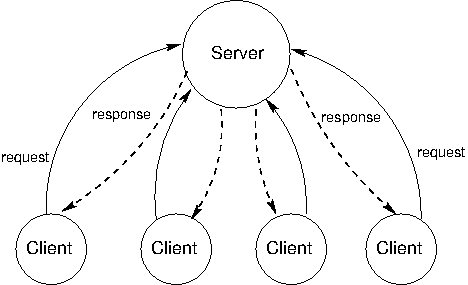
Vì đang nói đến mô hình Server Client trong hệ thống phân tán, nên chúng ta có thể hiểu như sau :
- Một(hoặc nhiều) công việc/tài nguyên cần xử lý hoặc đem ra cho mọi người dùng, được chia ra và định nghĩa thành nhiều điểm truy cập (endpoint) cho các máy khác connect đến và lấy về làm, ấy gọi là server
- Những máy biết đến cái endpoint có công việc cần xử lý hoặc có thứ cần sử dụng, truy cập vào, lấy việc về và xử lý (Có thể xử lý ngay tại chỗ hoặc đem về khu của riêng mình), ấy gọi là client.
Với mô hình đơn giản như vậy, việc khó khăn sẽ chính ở cách Server và Client trao đổi thông tin với nhau. Làm thế nào để Client có thể lấy thông tin được từ Server.
Cách đơn giản nhất, được nghĩ ra đầu tiên đó là Remote Procedure Call (RPC), có nghĩa là ở phía client có thể gọi đến các phương thức ở phía Server (lý do có chữ remote).
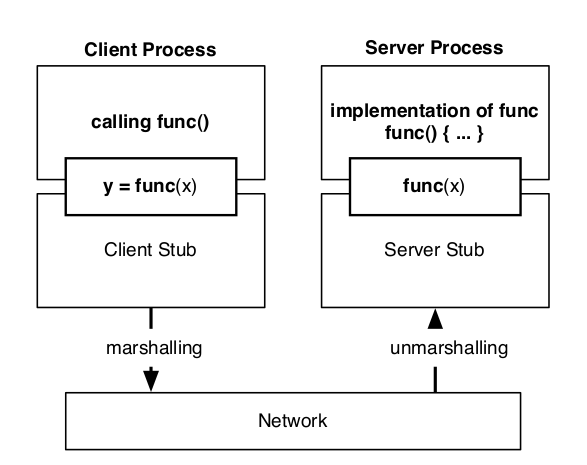
Với cách implement như thế này, như theo hình vẽ đã mô tả, ở phía client chỉ đơn giản gọi hàm y = func(x), trong khi hàm func(x) được mô tả và implement ở phía server. Hàm sẽ được gọi thông qua RPC và được thực thi ở phía server, kết quả trả về sẽ truyền vào biến y của client. Việc thực hiện truyền và xử lý hàm được thông qua hai thành phần Client Stub và Server Stub, sẽ đảm nhận việc gọi hàm và lấy kết quả trả về giữa hai thành phần.
Mở rộng hơn khái niệm RPC, chúng ta sẽ đến với Remote Method Invocation (RMI). Nếu đã làm quen với Ruby một thời gian, chúng ta hẳn sẽ quen với sự khác nhau giữa việc gọi hàm (call method) và gửi message (send message). Và bản chất giữa RMI và RPC khác nhau cũng như vậy. Nếu như RPC chỉ đơn giản là việc gọi hàm từ xa, thì RMI cung cấp việc gửi message từ xa đến một đối tượng cụ thể. Và Server Stub lẫn Client Stub có nhiệm vụ đảm bảo việc gửi message này diễn ra một cách suôn sẻ
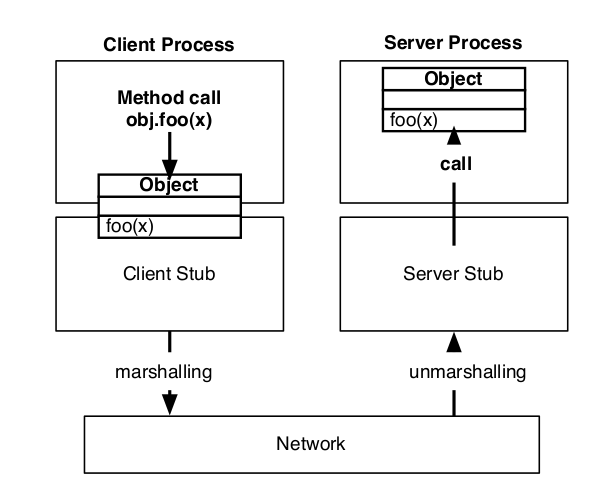
Chính vì việc có thể thực hiện việc gửi mesage, chúng ta có thể sử dụng object của server ở bên phía client giống như một object local. Và các hệ thống có thể làm được việc đó được có thêm 1 cái tên : Distributed Object System. dRuby là một hệ thống có tên đó, vậy chắc hẳn các bạn đã hiểu cơ chế hoạt động cơ bản của dRuby rồi chứ
