Đừng để dữ liệu ngoài database
Tài liệu: Don't Let Your Data Out of the Database Giữ dữ liệu trong database, không phải là vì các lý do bảo mật mà là để tránh các lỗi về hiệu suất. Thường thì cách tốt nhất để tăng tốc độ ứng dụng của bạn là để cho database server làm những gì mà nó được thiết kế để làm: thao tác trên dữ liệu. ...
Tài liệu: Don't Let Your Data Out of the Database
Giữ dữ liệu trong database, không phải là vì các lý do bảo mật mà là để tránh các lỗi về hiệu suất. Thường thì cách tốt nhất để tăng tốc độ ứng dụng của bạn là để cho database server làm những gì mà nó được thiết kế để làm: thao tác trên dữ liệu.
Hầu hết các framework và các ngôn ngữ lập trình ẩn database đằng sau một lớp trừu tượng đẹp đẽ và tao nhã. Các developers ngày nay không cần viết hay thậm chí hiểu về ngôn ngữ truy vấn cấu trúc(SQL=Structured Query Language), ngôn ngữ gốc của database server. Chúng ta xem SQL như là một ngôn ngữ cấp thấp, một di tích kĩ thuật của khoa học máy tính những năm 70, được để lại trong các tạp chí học thuật và trong các lớp học cao đẳng, đại học.
Tuy nhiên, không hiểu hết về SQL có thể dẫn đến một sai lầm to lớn. Sự thật, các vấn đề về hiệu suất có liên quan tới nhiều dữ liệu là kết quả của việc sử dụng ngôn ngữ cấp cao, giống như là Ruby hay Python, để làm việc với dữ liệu thay vì SQL. Giữ dữ liệu ở nơi nó thuộc về...trong database. Sử dụng database server của bạn để thao tác trên dữ liệu của bạn trong đó, và sau đó lấy ra kết quả mà ứng dụng của bạn thực sự cần.
Tôi sẽ chỉ cho bạn những gì tôi biết qua một ví dụ đơn giản.
Post và Comments
Giả sử, tôi có dữ liệu trong một mối quan hệ một-nhiều: một post có nhiều comments. Sử dụng ActiveRecord(ORM Ruby phổ biến), tôi thiết lập một liên kết một-nhiều bằng cách viết:
class Post < ActiveRecord::Base has_many :comments end class Comment < ActiveRecord::Base belongs_to :post end
Ruby cho phép query các comment cho một post xác định theo cách tự nhiên nhất, cách của con người làm là:
post = Post.find(1) post.comments
Nhưng nên nhớ ActiveRecord không phải là một magic framework. Nó không có một kết nối bí mật tới các bảng trong database. Nó nói chuyện với database server giống như bất kỳ các framework nào khác, sử dụng ngôn ngữ của server: SQL. Đọc log file, tôi có thể nhìn thấy cách mà ActiveRecord translate post.comments thành SQL:
select comments.* from comments where comments.post_id = 1
Sau khi thực thi câu lệnh SQL này, ActiveRecord chuyển đổi tập kết quả thành một mảng các đối tượng Ruby mà sau đó có thể sử dụng trong code. Cho ví dụ, nếu muốn lấy ra một comment mới nhất cho một post tôi có thể viết:
class Post
def latest_comment
comments.max{ |a, b| a.updated_at <=> b.updated_at }
end
end
Ở đây tôi yêu cầu Ruby sắp xếp các đối tượng comment và trả về comment mới nhất, comment với giá trị updated_at lớn nhất. Bây giờ tôi tìm kiếm người mà viết comment mới nhất cho post vừa rồi bằng cách viết:
post.latest_comment.author
Dữ liệu của tôi ở đâu? Vấn đề với cách tiếp cận này đó là nó không thể mở rộng được. Giả sử post này có hàng trăm hay thậm chí hàng ngàn các comment, trong trường hợp này, ActiveRecord sẽ chuyển tất cả các comment thành mảng các đối tượng Ruby bởi vậy tôi có thể lặp qua các comment trong phương thức latest_comment.
Lỗi của tôi là đã để dữ liệu ngoài database, thay vì tôi nên yêu cầu database làm việc cho tôi.
Hãy nhìn gần hơn cách mà latest_comment làm viêc:

Từ phía bên phải, tôi bắt đầu với tất các các comment trong database(lấy mười nghìn comment). Tiếp theo, cần tìm kiếm các comment được liên kết với post, lọc theo cột post_id. Kết quả là một tập chứa một trăm các comment(giả sử dùng cho ví dụ này). Cuối cùng, sắp xếp các comment đã được lọc và lấy ra comment mới nhất, kết quả comment mới nhất ở phía bên trái.
Vấn đề với giải pháp Ruby là tôi thực hiện lọc trong database, nhưng sắp xếp trong Ruby. Ở giữa, toàn bộ tập các comment cho một post phải được truyền từ database server tới Ruby application server:
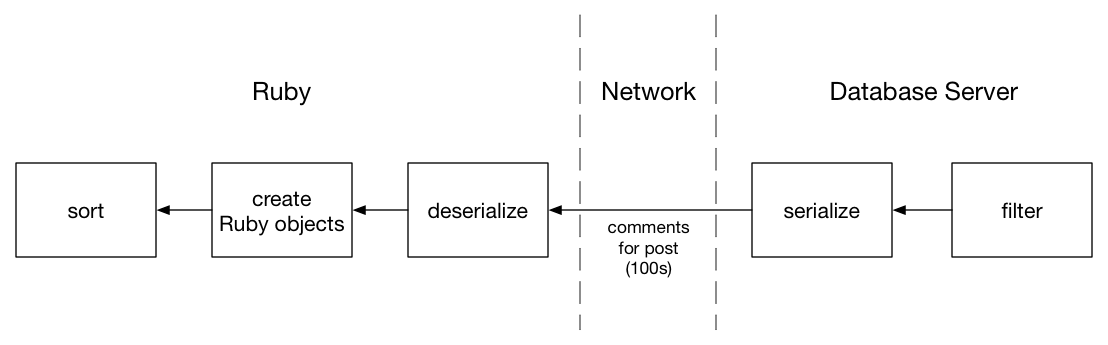
Để truyền tất cả các records, database cần chuyển chúng thành định dạng nhị phân, mà sau đó code của ruby(hay DB driver thực sự) cần unpack. Cuối cùng, ActiveRecord chuyển dữ liệu nhị phân này thành các đối tượng Ruby.
Tiến trình này tốn thời gian, cụ thể là tạo ra hàng trăm hay hàng nghìn đối tượng Ruby bao gồm việc cập phát một dãy các cấu trúc bộ nhớ và đặt chúng bên trong một mảng lớn. Sử dụng một process được gọi là "garbage collection", Ruby thậm chí phải tìm và phục hồi các đối tượng Ruby không được sử dụng cũ để giữ các comment, mà điều này có thể thậm chí mất rất nhiều thời gian.
Databases là nhanh hơn bạn tưởng Giải pháp rõ ràng: thực hiện tìm kiếm bên trong database và chỉ trả về comment mới nhất. Nhưng làm cách nào tôi yêu cầu database server tìm kiếm comment mới nhất? bằng cách sử dụng các phương thức của ActiveRecord như là where, order hay first để mô tả những gì tôi muốn, thay vì phải viết code trong Ruby. Dòng này sẽ làm một trick:
post.comments.order(updated_at: :desc).first
ActiveRecord translates điều này thành code SQL như sau:
select comments.* from comments where comments.post_id = 1 order by comments.updated_at desc limit 1
Điều này sẽ chạy nhanh hơn giải pháp trước, bởi vì database chỉ truyền một comment record qua network tới Ruby server: một comment mới nhất. Và Ruby chỉ tạo một đối tượng Ruby, cho comment mới nhất:

Bây giờ code được tối ưu cao nhất, chạy trên cùng một server mà giữ dữ liệu bảng comments, lọc các comment theo post, và sắp xếp phù hợp theo timestamp. Code này được sử dụng và test bởi hàng triệu các developers trên thế giới qua các năm. Không cần phải phát minh lại bằng cách viết lại cách sắp xếp riêng cho bản thân bạn sử dụng Ruby.
Caching the Latest Comment Giả sử trong giao diện người dùng, tôi luôn luôn show ra tác giả của comment mới nhất khi next trên mỗi post. Bây giờ để hiển thị page, tôi cần thực hiện tìm kiếm comment này lặp đi lặp lại trên mỗi post. Một cách để tránh query toàn bộ comment có thể là lưu trữ tác giả của comment mới nhất bên trong bảng posts. Với cách này, tôi sẽ lấy tác giả của comment mới nhất một cách tự động khi tôi load các post. Không cần các tìm kiếm lặp lại, hay bất kỳ các query trên toàn bộ bảng comments.
Trong thực hành, nếu tôi nhớ không nhầm là tạo các index trên các cột post_id và updated_at, comment tìm kiếm trên SQL sẽ chạy rất nhanh, thậm chí nếu tôi thực thị nó nhiều lần. Tôi có thể thậm chí load các comment mới nhất cho tất cả các post sử dụng truy vấn SQL, nhưng vì mục đich của đối số ngày nay dù thế nào đi nữa hãy tìm hiểu về giải pháp caching.
Hơn nữa, ActiveRecord làm điều này rất dễ dàng. Tất cả cần làm là viết một migration giống như sau:
class AddLatestCommentAuthorToPosts < ActiveRecord::Migration
def change
add_column :posts, :latest_comment_author, :string
end
end
Bây giờ tôi chỉ cần chắc chắn post được update mỗi lần một user viết một comment mới.
post.update_attribute(:latest_comment_author, "user name")
Data Migration sử dụng Ruby Tất nhiên, tôi đã quên một việc quan trọng. Sử dụng update_attribute để lưu author cho bất kỳ các comment mới nào, nhưng thế còn về các comment đã tồn tại từ trước thì sao? làm thế nào có thể thiết lập được giá trị ban đầu của cột này cho tất cả các comment đã có từ trước trong database?
Đơn giản: chỉ cần thêm một phương thức tới migration mà phương thức này gọi update_attribute. Và đây là cách để làm nó:
class AddLatestCommentAuthorToPosts < ActiveRecord::Migration
def change
add_column :posts, :latest_comment_author, :string
populate_latest_comment_authors
end
def populate_latest_comment_authors
Post.all.each do |post|
latest_author = post.comments.order(updated_at: :desc).first.author
post.update_attribute(:latest_comment_author, latest_author)
end
end
end
Bởi vì bạn viết các migration trong Ruby nên ActiveRecord sẽ làm cho nó trở nên đơn giản để thực hiện các phép biến đổi phức tạp trong một cách đơn giản, tao nhã. Sử dụng Ruby lấy ra các post, lặp qua mỗi post, tìm kiếm comment mới nhất cho mỗi post, và update trường tác giả comment mới nhất.
Nhưng tôi đã tạo ra một lỗi hiệu suất tương tự như trước! hãy nhìn vào log của Rails sau khi chạy migration này, tôi tìm thấy một dãy các câu lệnh SQL được lặp lại:
SELECT "comments".* FROM "comments" WHERE "comments"."post_id" = $1 ORDER BY "comments"."updated_at" DESC LIMIT 1 [["post_id", 2]] UPDATE "posts" SET "latest_comment_author" = $1, "updated_at" = $2 WHERE "posts"."id" = 2 [["latest_comment_author", "Harry"], ["updated_at", "2015-06-17 13:58:42.512160"]] SELECT "comments".* FROM "comments" WHERE "comments"."post_id" = $1 ORDER BY "comments"."updated_at" DESC LIMIT 1 [["post_id", 3]] UPDATE "posts" SET "latest_comment_author" = $1, "updated_at" = $2 WHERE "posts"."id" = 3 [["latest_comment_author", "Harry"], ["updated_at", "2015-06-17 13:58:42.514676"]] SELECT "comments".* FROM "comments" WHERE "comments"."post_id" = $1 ORDER BY "comments"."updated_at" DESC LIMIT 1 [["post_id", 1]] UPDATE "posts" SET "latest_comment_author" = $1, "updated_at" = $2 WHERE "posts"."id" = 1 [["latest_comment_author", "Harry"], ["updated_at", "2015-06-17 13:58:42.516071"]]
Hơn nữa, tôi đã để dữ liệu ngoài database. Bằng cách load tất các các post sử dụng Post.all, và lặp trên chúng sử dụng each, tôi đã gây ra một dãy các câu lênh SQL lặp lại này. Bây giờ tôi đang truyền tất cả dữ liệu post, và sau đó nhiều dữ liệu truyền đi truyền lại mỗi post giữa database và ứng dụng Ruby:
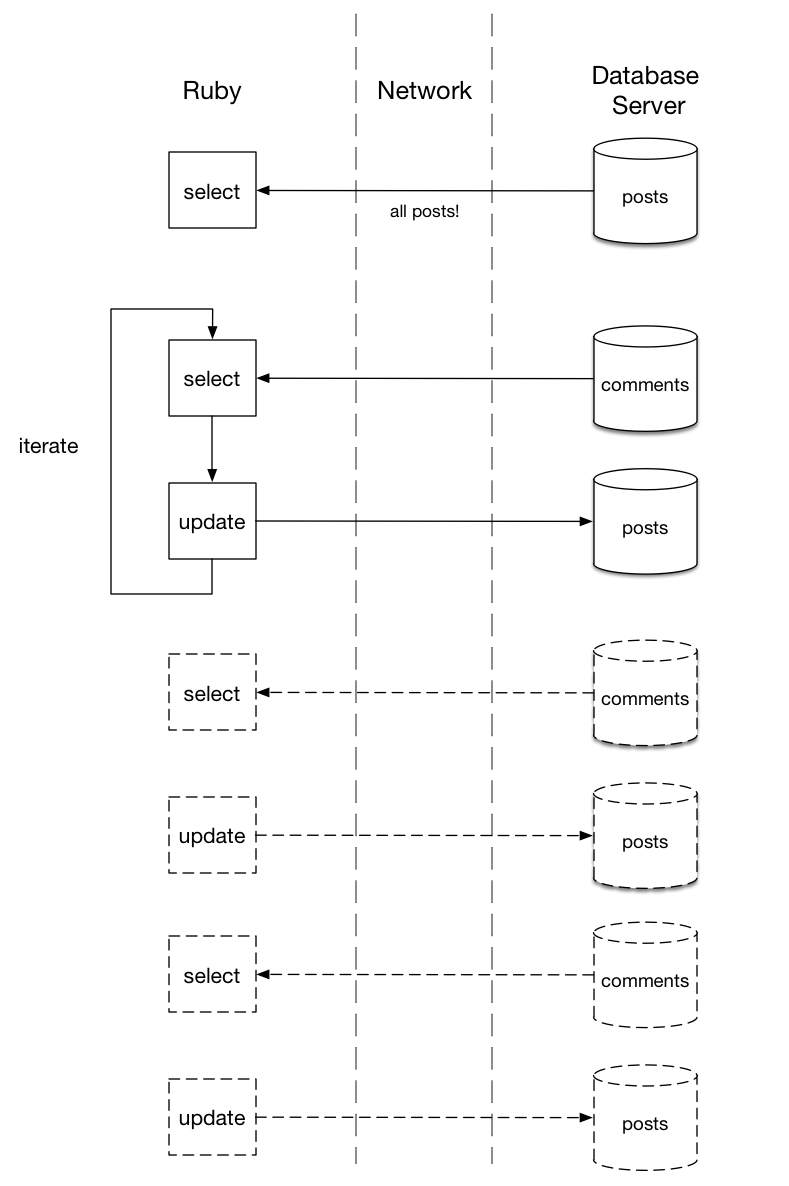
Giống như code trước của tôi, migration này thực hiện một cách xử lý tồi. Nếu tôi chỉ có một vài các post nó chắc chắn không phải là vấn đề. Nhưng tưởng tượng nếu ở đó có hàng nghìn hay thậm chỉ một trăm nghìn các post record: migration này phải mất vài phút hay thậm chí vài giờ để hoàn thành! database server và Ruby cần serialize, transmit và deserialize dữ liệu cho mỗi câu lệnh SQL.
Đó có phải là một cách tốt hơn.
Data Migration sử dụng SQL Giải pháp này giống giải pháp trước: Không cho phép dữ liệu ngoài database. Thay vì viết code Ruby để update mỗi post record, thì yêu cầu database server làm điều này. database server đã có tất cả dữ liệu post được tối ưu, có thể được load trong bộ nhớ. Nó có thể lặp trên các post và update chúng rất nhanh.
Nhưng theo cách nào? làm cách nào để yêu cầu database server update tất cả các post? tôi cần nói với ngôn của database: SQL. Bằng cách viết trực tiếp SQL, tôi có thể chắc chắn rằng database đang làm chính xác những gì tôi muốn, và sử dụng thuật toán hiệu quả nhất có thể. Tôi có thể chắc chắn database của tôi và tôi hiểu chúng.
Ở đây là một cách để update tất cả các post sử dụng SQL:
update posts set latest_comment_author = ( select author from comments where comments.post_id = posts.id order by comments.updated_at desc limit 1 )
Chương trình SQL rất nhỏ này thực sự sử dụng các lệnh SQL giống với những gì tôi đã thấy được lặp lại trong log file. Nhưng ở đó có một sự khác biệt quan trọng: code SQL này không liên quan tới giá trị post_id được hard code như là 1 hay 2. Ở đây tôi đã update tất cả các post với một lệnh!
Công việc này được thực hiện như thế nào? Hãy nhìn hình dưới đây:
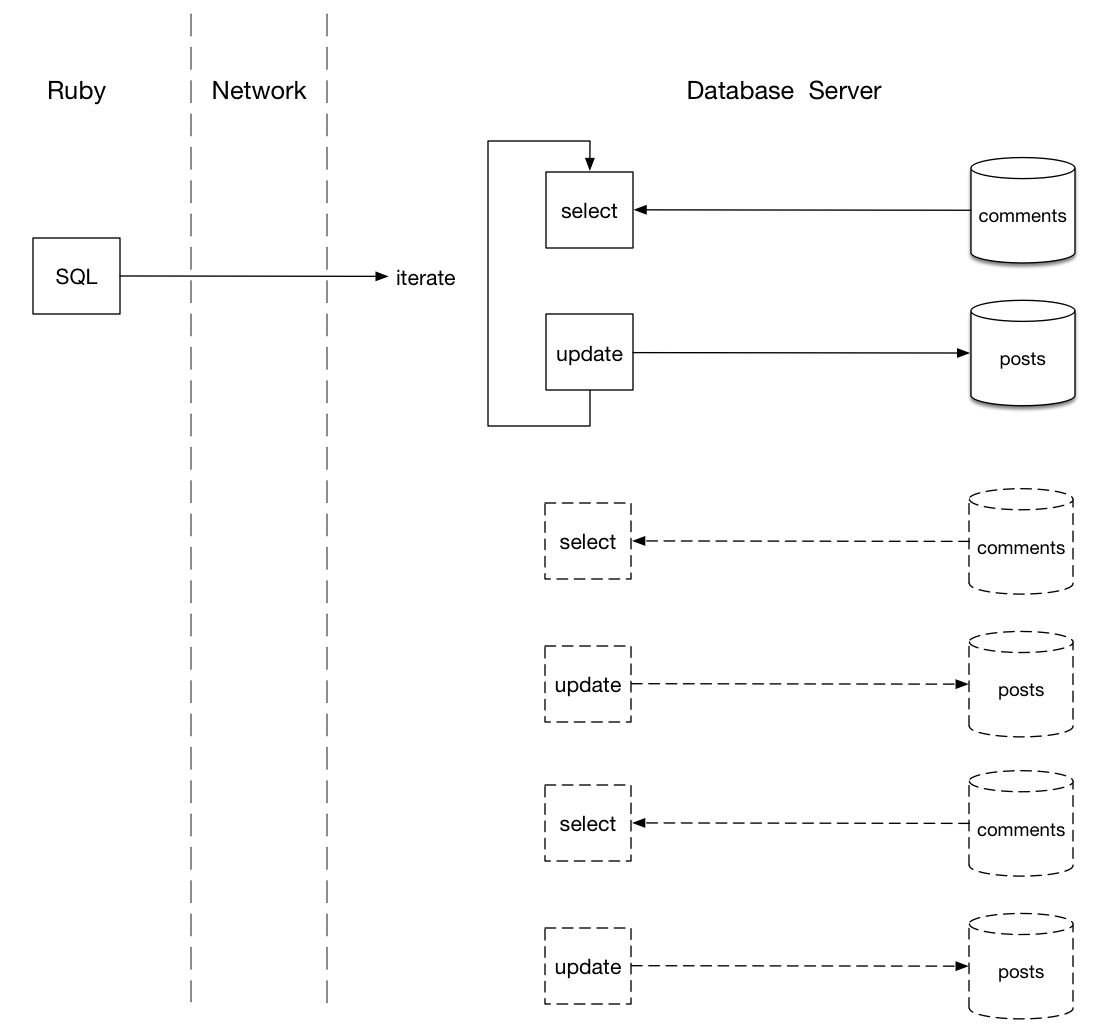
Sử dụng SQL migration, code ruby chỉ gửi một lệnh SQL tới database server, mà nó được truyền qua network tới database. Sau đó, ở phía bên phải database server thực hiện lặp giống nhau trên bảng posts, lựa chọn comment mới nhất cho mỗi post.
Điều này có vẻ tương tự, nhưng ở đó có một sự khác biệt chủ yếu là: Sự lặp xảy ra hoàn toàn trong database server. Không có dữ liệu cần pack, transmit tới Ruby Server và unpack lại. Sự thật, code thực hiện các câu lệnh SELECT lặp lại được biên dịch thành ngôn ngữ máy và sẽ chạy rất nhanh. Một lần nó lấy ra comment mới nhất, nó có thể trực tiếp update mỗi post bởi vì bảng posts đã được lưu trữ ở vị trí gần trên hard drive của server giống nhau, hay thậm chí trong bộ nhớ.
Tại sao code SQL lặp lại? Bạn phải tự hỏi tại sao tôi vẽ một sự lặp lại trong database server ở hình trên. Rốt cuộc tôi gửi tới database một lệnh đơn giản chứa một câu lệnh UPDATE và một câu lệnh SELECT nhưng tại sao database cần thực thi lựa chọn lặp đi lặp lại?
Lý do tại sao mà code SQL sử dụng một correlated subquery, bởi vì SELECT bên trong sử dụng một giá trị từ query phía bên ngoài. Đây là một SQL như trước:

Chú ý rằng câu lệnh SELECT bên trong liên quan tới post.id, một giá trị từ câu lệnh UPDATE bao quanh. Điều này đòi hỏi database server lặp trên tất cả các post, thực thi select bên trong cho mỗi hàng. Tôi sẽ để lại nó giống như là một bài tập cho người đọc viết lại điều này sử dụng một câu lệnh UPDATE-FROM, một JOIN hay thậm chí là Postgres window functions, mà có thể tránh được việc SELECT lặp lại.
Tuy nhiên, hãy nhớ nếu ở đó có các index trên các cột trong bảng comments, sự lặp lại lựa chọn comment mới nhất cho mỗi post sẽ rất nhanh. Nó tất nhiên sẽ nhanh gấp hàng nghìn lần gửi câu lệnh SELECT được lặp lại và câu lệnh UPDATE SQL từ Ruby Server qua network.
Bạn có cần học SQL không? Thật sự thì tôi có thể viết data migration này sử dụng Ruby code. ActiveRecord cung cấp một tập các phương thức phong phú, thậm chí cho phép cho các subselect sử dụng các query giả mạo. Và trong trường hợp hiếm gặp là khi ActiveRecord không thể phát sinh SQL tôi cần, tôi có thể luôn luôn phải sử dụng đến thư viện Arel Ruby bên dưới. Trong thực hành, hiếm khi thấy bạn sẽ thực sự cần viết code SQL trong ứng dụng Rails.
Vậy thì tại sao phải học SQL? Bạn nên học SQL bởi vì nó sẽ đưa cho bạn sự hiểu biết sâu bên trong làm cách nào database servers thực sự làm việc. Bạn sẽ học được những gì các database server có thể thực sự làm, và những gì không thể. Bạn không cần phát sinh lại bộ máy khi bạn đã có một server sử dụng các thuật toán mạnh mẽ và bạn cũng không cần phải giả mạo lại nó bằng bất cứ cách nào mà bạn có thể viết.
Sử dụng database server cho những gì nó đã được thiết kế để làm: giải quyết các vấn đề dữ liệu. Dù bạn có viết SQL trực tiếp hay không hoặc sử dụng một công cụ như là ActiveRecord để phát sinh SQL một cách tự động, thì thực hiện việc tìm kiếm, sắp xếp hay tính toán bạn cần xử lý trong database.
Không để dữ liệu ngoài database cho đến khi bạn cần...cho đến khi bạn chỉ có các giá trị mà ứng dụng của bạn thực sự cần.
