Giới thiệu về MaryTTS
Abstract : Hiện nay, chúng ta đang sống trong thời đại công nghệ thông tin, xung quanh chúng ta là hàng loạt thiết bị công nghệ, và việc giao tiếp với chung đang là một vấn nổi bật hiện nay. Trong một số bài viết của bạn @YinLong đã giới thiệu về các đặc tính của Tiếng Việt và tổng quan về các mô ...
Abstract: Hiện nay, chúng ta đang sống trong thời đại công nghệ thông tin, xung quanh chúng ta là hàng loạt thiết bị công nghệ, và việc giao tiếp với chung đang là một vấn nổi bật hiện nay. Trong một số bài viết của bạn @YinLong đã giới thiệu về các đặc tính của Tiếng Việt và tổng quan về các mô hình của tổng hợp tiếng nói (Text To Speech - TTS), do đó, trong bài viết này, tôi sẽ đặt lại vấn đề của tổng hợp tiếng nói ở phần I. Tiếp theo, phần 2 tôi sẽ giới thiệu về MaryTTS và kiến trúc để tổng hợp về tiếng nói.
I. Đặt vấn đề
- Như trong một bộ phim giả tưởng của maven, nhân vật Javist là một mong muốn của chúng ta, nó có thể hiểu câu nói và trả lời câu hỏi chúng ta.
- Hay một ví dụ khác, bạn nghĩ thế nào khi khi trên đường đi làm, trong thời gian tắc đường, một hệ thống tổng hợp và đọc tin tức trên báo cho bạn nghe mà bạn không cần mở điện thoại, vừa có thể tránh việc vi phạm luật giao thông, vừa tránh buồn chán khi đợi thông xe cũng như biết tin tức mới và tránh mất thời gian vô ích?
- Một ví dụ khác, tôi rất thích đọc các tiểu thuyết, tuy nhiên, việc đọc trên điện thoại nhiều, tôi hay bị mỏi mắt, nếu như điện thoại có thể tự động đọc giống như các cô phát thanh viên đọc truyện trên kênh truyện đọc đêm khya?
- Và rất nhiều vấn đề có thể giải quyết được khi chúng ta có thể giao tiếp được với máy tính. Và tổng hợp tiếng nói là một đề quan trọng trong giao tiếp giữa người với máy tính.
- Để tổng hợp được nói, một số mô hình được đề xuất đã được giới thiệu trong bài Xử lý tiếng nói - Tổng quan về tổng hợp tiếng nói. Với một số mô hình, đã có một số platform để hỗ trợ người dùng, như trong bài này, tôi giới thiệu về hệ thống MaryTTS. Phần II tôi trình bay về kiến trúc của hệ tổng hợp MaryTTS.
II. Giới thiệu về MaryTTS
- Tổng quan về MaryTTS
- MaryTTS là một mã nguồn mở.
- MaryTTS là một platform giúp chúng ta có thể xây dựng bộ tổng hợp tiếng nói cho từng ngôn ngữ khác nhau một cách dễ dàng nhất.
- MaryTTS được xây dựng dựa trên ngôn ngữ Java, vì thế, nó có thể được build không phụ thuộc vào môi trường, chỉ yêu cầu máy tính của bạn cài Java và Maven để quản lý thư viện của nó.
- MaryTTS tổng hợp tiếng nói dựa trên mô hình HMM Base như đã được trình bày trong bài Xử lý tiếng nói - Tổng quan về tổng hợp tiếng nói. Do đó, platform này khá phù hợp để xây dựng hệ thống TTS cho Tiếng Việt và một số ngôn ngữ có thành điệu khác.
- MaryTTS có thể thay đổi các tham số vật lý của âm thanh khi tổng hợp thông qua SSML (Speech Synthesis Markup Language). Tôi sẽ có một bài riêng để giới thiệu về nó.
- Sử dụng MaryTTS để tổng hợp tiếng nói như thế nào?
- Để build một hệ thống có thể tổng hợp tiếng nói bằng MaryTTS cho một ngôn ngữ có sẵn thì có khá nhiều việc để làm, trong bài viết này, tôi xin phép chỉ hướng dẫn qua cách build hệ thống TTS cho tiếng anh, vì ngôn ngữ này đã training sẵn trong hệ thống.
- Đầu tiên, bạn cần vào Github để pull code.
- Để build và chạy hệ thống này, máy của bạn yêu cầu phải được cài sẵn Java và Maven.
- Sau khi clone code từ trên hệ thống, bạn và đã cài xong các yêu cầu như trên, ta có thể vào thư mục marytts, gõ lệnh mvn clean và sau đó là mvn install để build hệ thống.
- Sau khi hệ thống, ta sẽ thấy thư mục target. Tiếp theo, bạn vào thư mục marytts-<version>/bin. Trong thư mục này là kết quả của việc build hệ thống thành công ở trên. Để khởi động server, với window, bạn sử dụng marytts-server.bat, tương tự với ubuntu cũng như mac, bạn sử dụng marytts-server.sh. Sau khi khởi động thành công server, bạn có thể sử dụng ứng dụng marytts-client hoặc có thể vào trình duyệt với đường dẫn localhost:59125. Và giờ để tổng hợp 1 đoạn âm thanh từ một đoạn text thật đơn giản phải không? (Lưu ý: hiện tại hệ thống chỉ có cho Tiếng Anh, để vs các ngôn ngữ khác, mình sẽ giới thiệu ở một bài khác).
- Kiến trúc chung của MaryTTS
- Trong phần này, tôi sẽ trình bày về kiến trúc chung của platform MaryTT.
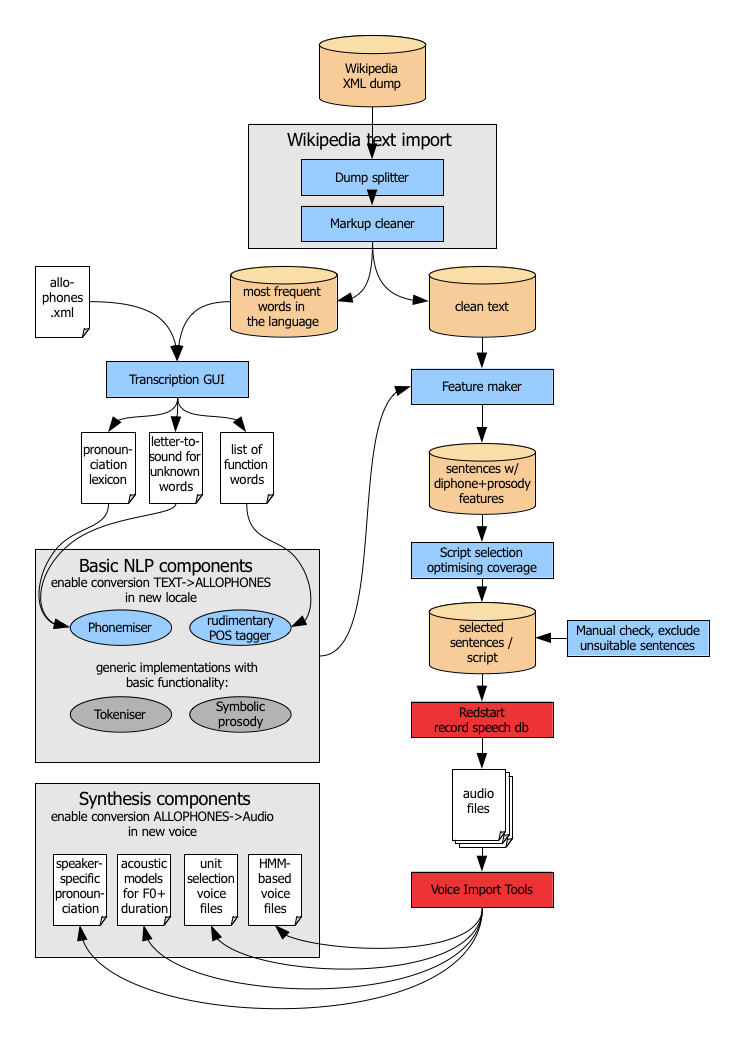
- Tôi chia hệ thống trên thành 2 thành phần, bao gồm phẳn lý ngôn ngữ tự nhiên (phần phía bên trái) và phần xử lý tiếng nói (phần phía bên phải).
- Với đoạn văn bản đầu vào, kết hợp với bộ allophones đã được cung cấp từ đầu, đoạn văn bản này sẽ được tách thành các các câu, sau đó, tách thành token. Từng ngôn ngữ riêng thì sẽ có cách tách riêng, ví dụ như tiếng Anh thì token là một từ nguyên thể, các dạng khác của nó được chuyển về dạng chuẩn, ví dụ như playing -> play, với những ngôn có ký tự không phải ký tự latinh như tiếng Nhật, tiếng Hàn, tiếng Thái thì vấn đề này khá phức tạp. Với tiếng việt, các bạn có thể tham khảo thư vntokenize của thầy Lê Hồng Phương
- Sau khi tách được thành các token riêng biệt, hệ thống sẽ chuẩn hóa đoạn văn bản trên, ví dụ như "57" -> "năm mươi bảy", "HCM"->"Hồ Chí Minh", "20/10" -> "Hai mươi tháng mười"... Với Tiếng Việt, có khá nhiều vấn đề cần xử lý, như cần phân biệt ngày tháng với trường hợp phân số, hoặc có thể phân biệt được các từ viết tắt giống nhau nhưng ở trong các trường hợp giống nhau thì nó cần phải giải quyết thế nào? Vấn đề này tôi sẽ trình bày ở một bài viết khác.
- Sau khi văn bản đã được chuẩn hóa, các từ của văn bản sẽ được chuyển thành các phones, ví dụ "Trũi khẽ thở dài"->"c u4 j4+X E4+t_h 73+z a2 j2".
- Sau khi có được các phones được phân tích, sẽ đưa được tách thành cách diphone hoặc triphone tùy theo yêu cầu của các bạn, một diphone là tập hợp của hai thành phần, như ví dụ trên, ta có diphone #-c hoặc c-u4..., tương tự với triphone. Các diphone sẽ kết hợp các tham số vật lý(nếu bạn có muốn thay đổi). Sau đó, dựa vào kiến trúc dữ liệu đã được training, hệ thống sẽ tổng hợp và tạo ra file âm thanh có nội dung như đoạn text bạn nhập vào. Phần này là HMM Base, tôi sẽ giới thiệu ở một bài gần nhất.
- Vậy là với một đoạn văn bản, thông qua hệ thống MaryTTS, ta đã có 1 âm thanh.
Trong bài viết này, tôi đã đặt lại vấn đề của tổng hợp tiếng nói, cũng như giới thiệu về MaryTTS cũng như kiến trúc của nó, trong kì tiếp theo, tôi sẽ trình bày về bài toán chuẩn hóa văn bản và một số phương pháp giải quyết hiện nay.
Cảm ơn các bạn đã theo dõi!
