HADOOP - CÀI ĐẶT HADOOP TRÊN UBUNTU (PHẦN 1)
1. Giới thiệu về Hadoop Hadoop là công nghệ phần mềm được thiết kế để lưu trữ và xử lý khối lượng dữ liệu lớn phân tán theo cụm máy chủ và cụm lưu trữ đại trà. Hồi những năm 2000, Google công bố tài liệu nghiên cứu cách tiếp cận và nguyên tắc thiết kế để xử lý khối lượng lớn dữ liệu đã được đánh ...
1. Giới thiệu về Hadoop
Hadoop là công nghệ phần mềm được thiết kế để lưu trữ và xử lý khối lượng dữ liệu lớn phân tán theo cụm máy chủ và cụm lưu trữ đại trà. Hồi những năm 2000, Google công bố tài liệu nghiên cứu cách tiếp cận và nguyên tắc thiết kế để xử lý khối lượng lớn dữ liệu đã được đánh chỉ mục trên web. Những tài liệu này đã ảnh hưởng đến sự phát triển của Hadoop. Ba trong số những nguyên tắc cơ bản thiết kế là:
- Thứ nhất, vì có đến hàng trăm hay thậm chí hàng ngàn cỗ máy lưu trữ thì lỗi xảy ra là điều hiển nhiên chứ không phải ngoại lệ, do đó giám sát liên tục, phát hiện lỗi, kháng lỗi và tự động phục hồi phải được tích hợp với hệ thống.
- Thứ hai, các tập tin rất lớn so với tiêu chuẩn truyền thống. Tập tin có dung lượng hàng GB và hàng tỷ đối tượng là rất phổ biến. Do đó, những giả định về thiết kế và các thông số như vận hành I/O hay kích thước khối phải xem xét lại
- Thứ ba, hầu hết các tập tin được cập nhật bằng cách thêm dữ liệu mới hơn là ghi đè lên dữ liệu hiện có. Việc ghi dữ liệu ngẫu nhiên trong một tập tin trên thực tế là không xảy ra. Khi ghi, các tập tin chỉ đọc và thường đọc theo thứ tự. Vì đây kiểu truy cập vào các tập tin lớn, nên sự bổ sung thêm trở thành tiêu điểm của việc tối ưu hóa hiệu suất và bảo đảm hoàn tất giao dịch.
- Hadoop Common: Đây là các thư viện và tiện ích cần thiết của Java để các module khác sử dụng. Cung cấp hệ thống file và lớp OS trừu tượng, đồng thời chứa các mã lệnh Java để khởi động Hadoop.
- Hadoop YARN: Đây là framework để quản lý tiến trình và tài nguyên của các cluster.
- Hadoop Distributed File System (HDFS): Đây là hệ thống file phân tán cung cấp truy cập băng thông cao cho ứng dụng khai thác dữ liệu.
- Hadoop MapReduce: Đây là hệ thống dựa trên YARN dùng để xử lý song song các tập dữ liệu lớn. Cho phép lập trình tạo ra các chương trình song song dùng để xử lý dữ liệu.

2. Cài đặt Hadoop 2.7.0 single node cluster
2.1. Cài đặt các dependencies
-
Bước 1: Bạn mở terminal và chạy với quyền root:
sudo su
-
Bước 2: Cập nhật hệ thống:
apt-get update
-
Bước 3: Cài Open SSH Server:
apt-get install openssh-server
-
Bước 4: Tạo user và group cho Hadoop:
- Ở đây tôi tạo group với tên là hadoop :
sudo add group hadoop
- Thêm một user vào group hadoop. Ở đây tôi tạo một user với tên là hduser:
sudo adduser --ingroup hadoop hduser
- Ở đây tôi tạo group với tên là hadoop :
-
Bước 5:
Sau khi SSH Server được cài đặt, các cấu hình có thể được thực hiện trong file sshd_config trong thư mục đường dẫn /etc/ssh. Ta tạo một backup của sshd_config để có thể khôi phục lại cấu hình trong những trường hợp xấu bằng cách chạy câu lệnh dưới đây:
cp /etc/ssh/sshd_config /etc/ssh/sshd_config.factory-defaults
-
Bước 6:
Mở file sshd_config để thực hiện cấu hình:
Đầu tiên chạy lệnh:
cd / nano /etc/ssh/sshd_config
-- Tiếp theo thay đổi dòng #PasswordAuthentication yes thành PasswordAuthentication no để vô hiệu hóa xác thực trong SSH Server
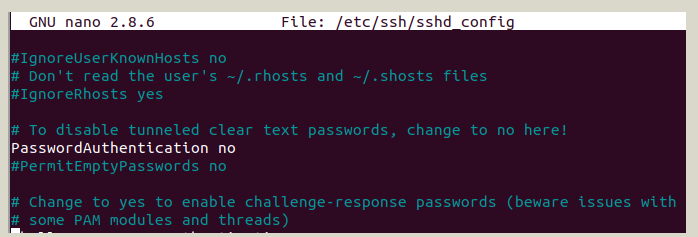
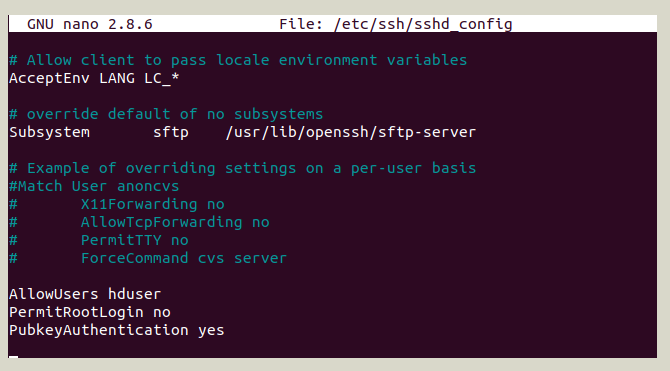
-- Tiếp tục thêm những dòng dưới đây vào file sshd_config:
AllowUsers hduser PermitRootLogin no PubkeyAuthentication yes
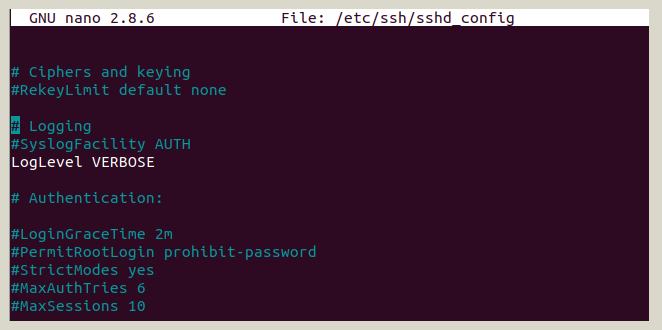
-- Tiếp tục thay đổi #LogLevel INFO thành Loglevel VERBOSE tại file sshd_config:
-- Cuối cùng save và restart lại SSH Server bằng câu lệnh dưới đây:
systemctl restart ssh
- Bước 7:
Sau khi máy chủ SSH được cấu hình, một khoá SSH cho người dùng hduser được tạo ra bằng cách chạy lệnh dưới đây.
su hduser ssh-keygen -t rsa -P ""
Họ tạo ra một cặp khóa RSA mà không có mật khẩu. Một mật khẩu sẽ được yêu cầu mỗi lần hadoop tương tác với node nên để chúng ta có thể tiết kiệm cho bản thân mình những nhắc nhở cho một mật khẩu mỗi lần
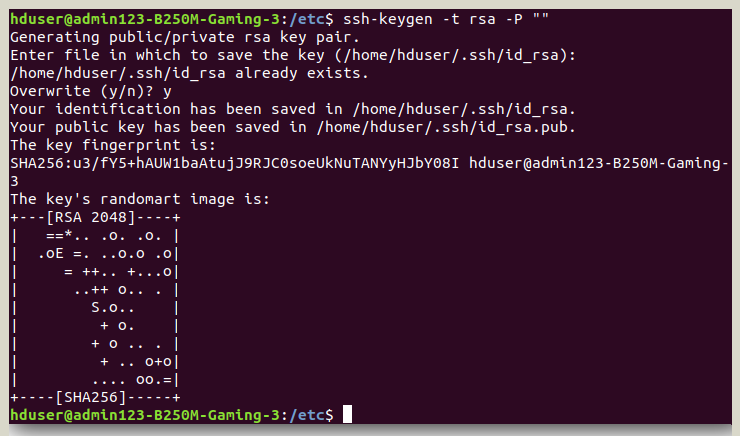
-- Sau khi key được tạo, bạn có thể sử dụng nó để kích hoạt truy cập SSH vào máy local bằng cách chạy lệnh dưới đây:
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
-- Test localhost:
ssh localhost
2.2. Cài Apache Hadoop 2.7.0
- Bước 1: Cài đặt Oracle Java 8:
add-apt-repository ppa:webupd8team/java apt-get update apt-get install oracle-java8-installer java -version
-
Bước 2: Download và cài đặt Hadoop 2.7.0
Login với user hduser:
su hduser
Thực hiện các câu lệnh dưới:
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.0/hadoop-2.7.0.tar.gz sudo tar -xzvf hadoop-2.7.0.tar.gz sudo mkdir /usr/local/hadoop sudo mv hadoop-2.7.0 /usr/local/hadoop sudo chown -R hduser /usr/local/hadoop
-
Bước 3: Thực hiện cấu hình trong file .bashrc trong user hduser
-- Mở file .bashrc
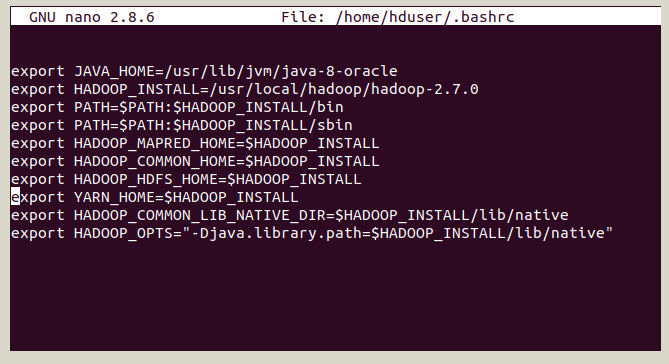
su hduser readlink -f /usr/bin/java nano ~/.bashrc-- Thêm đoạn code dưới đây vào file:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle export HADOOP_INSTALL=/usr/local/hadoop/hadoop-2.7.0 export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib/native"
-- Như hình dưới đây:
-- Save file
-- Lưu thay đổi trên trong file .bashrc với câu lệnh source ~/.bashrc
- Bước 4: Xuất đường dẫn JAVA_HOME
-- Thư mục /usr/local/hadoop/hadoop-2.7.0/etc/hadoop chứa các file cấu hình. Mở hadoop-env.sh trong trình soạn thảo văn bản và đặt biến JAVA_HOME bằng cách thêm dòng dưới đây. Điều này quy định java sẽ được sử dụng bởi Hadoop
cd /usr/local/hadoop/hadoop-2.7.0/etc/hadoo nano hadoop-env.sh
-- Thêm dòng dưới đây:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
-- Save file hadoop-env.sh
- Bước 5:
Tạo một thư mục hoạt động như là thư mục cơ sở cho các thư mục tạm thời khác và gán nó cho người dùng hduser bằng cách chạy các lệnh dưới đây:
sudo mkdir -p /app/hadoop/tmp sudo chown hduser /app/hadoop/tmp
