Hướng tiếp cận Graph convolution network cho bài toán rút trích thông tin từ hóa đơn
The Mobile capture receipts Optical Character Recognition (MC-OCR) là cuộc thi về ảnh receipt (hóa đơn) có 2 task và team mình đã tham gia task thứ 2 là trích xuất các thông tin cơ bản bao gồm SELLER, SELLER_ADDRESS, TIMESTAMP, TOTAL_COST (bên bán, địa điểm, thời gian và tổng thanh toán) từ ánh ...
The Mobile capture receipts Optical Character Recognition (MC-OCR) là cuộc thi về ảnh receipt (hóa đơn) có 2 task và team mình đã tham gia task thứ 2 là trích xuất các thông tin cơ bản bao gồm SELLER, SELLER_ADDRESS, TIMESTAMP, TOTAL_COST (bên bán, địa điểm, thời gian và tổng thanh toán) từ ánh các hóa đơn đã được thu thập từ trước bằng điện thoại.
Các ảnh hóa đơn do BTC cung cấp có phần background (ngoại cảnh) không nhỏ (thậm chí hơn 50%), bị nghiêng và bị quay theo rất nhiều hướng khác nhau. Do đó để bước nhận dạng text chính xác nhất cần loại bỏ ngoại cảnh và xoay phần ảnh hóa đơn còn lại về đúng hướng của nó.
Segmentation và rotation
Để segment reciept ra khỏi background bọn mình xài 1 mạng có tên là Basnet ( Boundary-aware salient object detection) . Đây là một mạng salient object detection - hiểu đơn giản nó chỉ quan tâm foreground/object và background mà không cần biết là object đó thuộc class nào ( phiên bản nâng cấp hơn Basnet của cùng tác giả là U2mathbf{U}^2U2). Mình sử dụng luôn pretrained model của tác giả xài luôn và không tiến hành bước fine-tune nào.

Hình 1 : Kết quả từ model segmentation
Sau khi segment bọn mình tính góc nghiêng giữa trục trên-dưới cúa receipt và trục đứng của ảnh sau đó xoay phần receipt theo đúng hướng của nó.
Image orientation ( xác định hướng của receipt)
Bọn mình xài một mạng self-supervised để xác định hướng của receipt với ý tưởng như trong paper Unsupervised Representation Learning by Predicting Image Rotations của tác giả Spyros Gidaris . Mỗi receipt có thể ở 1 trong 4 hướng bị xoay khác nhau là 0, 90, 180, 270 độ như hình minh họa ở dưới.
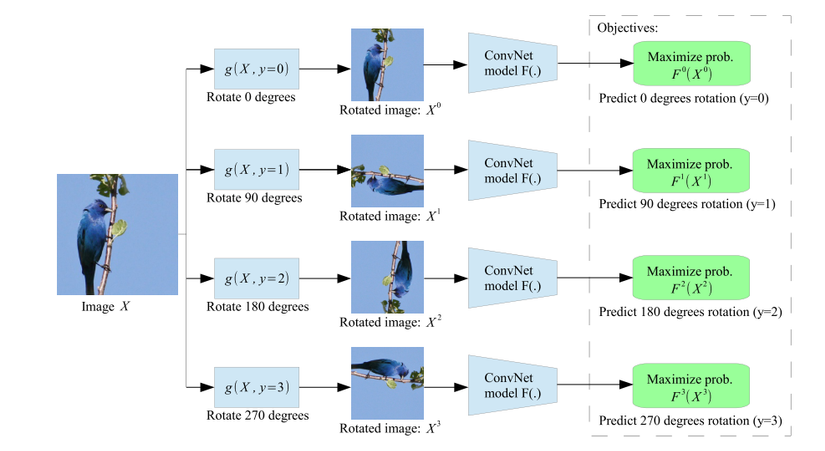
Hình 2 : Self-supervised cho bài toán rotation image
Cũng giống như các team khác team mình xài CRAFT cho text detection và VietOCR cho text recognition. Đã có rất nhiều bài viết về cái này mình sẽ không đi sâu vào nó nữa
Để giải quyết bài toán key information extraction (trích xuất thông tin cơ bản) có rất nhiều hướng tiếp cận như text classification hay template matching nhưng mình thấy hướng tiếp cận Graph là hay nhất. Mỗi receipt được mô hình hóa dưới dạng graph G(V,E)G(V, E)G(V,E) trong đó VVV (vertices/nodes) là tập các đỉnh tương ứng với bounding box mỗi vùng có text (textbox/text bounding box) và EEE là tập các cạnh biểu diễn cho mối quan hệ giữa các đỉnh. Bài toán này thuộc lớp Node classification có rất nhiều ý tưởng được đề xuất ra như PICK (processing keyinformation extraction from documents using improved graph learning-convolutional networks ) kết hợp giữa vision feature và text feature , điểm mình không thích ở bài này là sự kết hợp quá cứng nhắc của 2 feature này. Team mình thích các tiếp cận dựa trên text feature và vị trí box hơn nên sử dụng paper Residual Gated Graph Convnets của tác giả Xavier Bresson, một nhân vật rất nổi tiếng với nhiều paper về graph. Xavier Bresson cũng tạo ra một Benchmarking Graph Neural Networks với rất nhiều model được viết trên thư viện DGL .
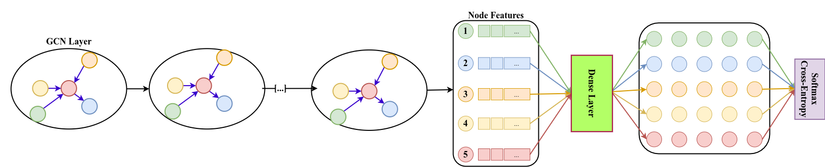
Hình 3 : Graph architecture cho bài toán node classification
Định nghĩa về node feature và edge feature.
1. Node features
Node featue được tổng hợp từ tọa độ textbox và text do model của OCR nhận diện ra. Mỗi textbox là một vector L=(xi, yi∣ i∈[1,4])L=(x_i,~y_i|~i in [1,4])L=(xi, yi∣ i∈[1,4]) trong đó (xi, yix_i,~y_ixi, yi tọa độ góc của textbox). Text từ OCR sẽ được embedding và vào đưa vào một mạng LSTM. Sau đó thông tin về tọa độ textbox và text được kết hợp bằng cách cộng theo từng phần tử (element-wise) với nhau tạo thành node feature. Mình sử dụng embedding theo character mà không dùng những pretrained model như word2vec hay bert vì các lí do sau: a) hóa đơn có cả tiếng Việt lẫn tiếng Anh lẫn số, b) nhiều từ tiếng Việt bị nhận diện sai dấu/thanh và cuối cùng là c) không có nhiều thông tin về ngữ cảnh.
2. Edge features
Edge (cạnh) biểu diễn sự liên kết giữa mỗi cặp node trong graph.
Trước tiên chúng ta định nghĩa liên kết giữa hai nodes bất kì. Giả định rằng text trong reciept được sắp xếp theo thứ tự trái-phải trên-dưới, hai nodes được gọi là có liên kết nếu:
d(v, vj)=abs(vy−vj,y)<3×hvd(v,~v_j) = abs(v_y - v_{j, y}) < 3 imes h_v d(v, vj)=abs(vy−vj,y)<3×hv
trong đó hhh là chiều cao của node hiện tại. Nói một cách đơn giản, hai node được coi là có liên kết với nhau khi khoảng cách theo trục yyy giữa chúng không vượt quá 3 lần chiều cao của node hiện tại. Ta định nghĩa edge feature của 2 node có liên kết là một vector khoảng cách theo trục xxx và yyy cho bởi công thức :
distance(vi, vj)=(abs(vi,x−vj,x),abs(vi,y−vj,y)) distance(v_i,~v_j) = (abs(v_{i, x} - v_{j, x}), abs(v_{i, y} - v_{j, y})) distance(vi, vj)=(abs(vi,x−vj,x),abs(vi,y−vj,y))
3. Network architecture (Kiến trúc Graph model) Mình sử dụng graph model có tên là Residual Gated Graph Convnets . Edge và node features theo các định nghĩa ở trên được đưa qua layer RG-GCN (Residual Gated Graph Convnets).
h=x+(Ax+∑vj→vη(ej)⊙Bxj)+,mathbf{h}=mathbf{x}+left(mathbf{Ax}+sum_{v_j o v} eta(e_j) odot mathbf{Bx}_j ight)^+, h=x+⎝⎜⎛Ax+vj→v∑η(ej)⊙Bxj⎠⎟⎞+,
trong đó xmathbf{x}x là Residual (hay skip connection như trong Resnet), Axmathbf{Ax}Ax là tác động của node hiện tại ∑...sum ...∑... là tác động của các node lân cận, +^++ là hàm ReLu). ηetaη là tỉ trọng của mỗi node lân cận tác động đến node hiện tại và được tính theo công thức:
η(ej)=σ(ej)(∑vk→vσ(ek))−1, eta(e_j) = sigma(e_j) left(sum_{v_k o v}sigma(e_k) ight)^{-1}, η(ej)=σ(ej)(vk→v∑σ(ek))−1,
σsigmaσ là hàm sigmod, eje_jej và eke_kek là features của các edges liên kết với node hiện tại vvv từ các nodes lân cận vjv_jvj và vkv_kvk. eje_jej theo thứ tự được tính từ các công thức sau:
ej=Cejx+Dxj+Ex,e_j = mathbf{C}e_j^{x} +mathbf{Dx}_j + mathbf{Ex}, ej=Cejx+Dxj+Ex,
ejh=ejx+(ej)+,e_j^h = e_j^x + (e_j)^+, ejh=ejx+(ej)+,
với ejxe_j^xejx và ejhe_j^hejh là input và outout của hidden layer từ feature vector của cạnh eje_jej nối đỉnh hiện tại vvv với đỉnh vjv_jvj. A,B,C,D,Emathbf{A,B,C,D,E}A,B,C,D,E là các ma trận của các phép quay được học từ quá trình huấn luyện mạng.
Model graph có thể được định nghĩa theo class như sau
class GatedGCN_layer(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.A = nn.Linear(input_dim, output_dim)
self.B = nn.Linear(input_dim, output_dim)
self.C = nn.Linear(input_dim, output_dim)
self.D = nn.Linear(input_dim, output_dim)
self.E = nn.Linear(input_dim, output_dim)
self.bn_node_h = nn.BatchNorm1d(output_dim)
self.bn_node_e = nn.BatchNorm1d(output_dim)
def message_func(self, edges):
Bh_j = edges.src['Bh']
# e_ij = Ce_ij + Dhi + Ehj
e_ij = edges.data['Ce'] + edges.src['Dh'] + edges.dst['Eh']
edges.data['e'] = e_ij
return {'Bh_j' : Bh_j, 'e_ij' : e_ij}
def reduce_func(self, nodes):
Ah_i = nodes.data['Ah']
Bh_j = nodes.mailbox['Bh_j']
e = nodes.mailbox['e_ij']
# sigma_ij = sigmoid(e_ij)
sigma_ij = torch.sigmoid(e)
# hi = Ahi + sum_j eta_ij * Bhj
h = Ah_i + torch.sum(sigma_ij * Bh_j, dim=1) / torch.sum(sigma_ij, dim=1)
return {'h' : h}
def forward(self, g, h, e, snorm_n, snorm_e):
h_in = h # residual connection
e_in = e # residual connection
g.ndata['h'] = h
g.ndata['Ah'] = self.A(h)
g.ndata['Bh'] = self.B(h)
g.ndata['Dh'] = self.D(h)
g.ndata['Eh'] = self.E(h)
g.edata['e'] = e
g.edata['Ce'] = self.C(e)
g.update_all(self.message_func, self.reduce_func)
h = g.ndata['h'] # result of graph convolution
e = g.edata['e'] # result of graph convolution
h = h * snorm_n # normalize activation w.r.t. graph node size
e = e * snorm_e # normalize activation w.r.t. graph edge size
h = self.bn_node_h(h) # batch normalization
e = self.bn_node_e(e) # batch normalization
h = torch.relu(h) # non-linear activation
e = torch.relu(e) # non-linear activation
h = h_in + h # residual connection
e = e_in + e # residual connection
return h, e
Sau khi stack (L=8) layers của RG-GCN các node-feature được đưa vào một layer dense và dùng chung weight cho tất cả các node và layể cuối cùng sử dụng hàm lỗi dạng cross entropy để phân loại node.
Pseudo label - thêm nhãn giả
Để tạo data training cho graph model, mình thêm ground truth (gồm 4 đỉnh polygon của text, text và class label) vào dataset đã tạo ở bước trước đó (Text detection) và loại bỏ những textbox của nếu nó trùng lặp với textbox của BTC bởi IoU > 0.2. Những box còn lại sẽ được gán nhãn là Other.
Data Augmentation
Để tăng độ đa dạng cho dataset mình làm giàu thêm bằng cách thay thế các field SELLER và ADDRESS dựa trên bộ từ điển được tạo ra từ ground truth của BTC và lấy nghẫu nhiên cho TIMESTAMP và TOTAL. Cả hai text detector là CTPN và CRAFT cũng được sử dụng để làm giàu dữ liệu.
Training và accuracy
Dataset sau khi làm giàu đến khoảng 10k mẫu và được chia theo tỉ lệ 80:20 cho train và test.
Quá trình trên GTX 1080TI với 10 epochs cho đồ thị như sau:
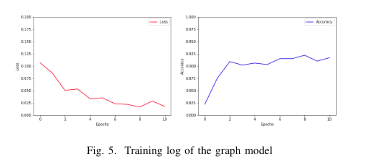
Kết quả accuracy trên từng field như sau :

1. Spelling correction
Mình sử dụng grounth truth để sửa lại text trong trường hợp bị nhận diện sai. Ví dụ với địa chỉ và tên công ty/shop /market thường là tên riêng nên mình tạo một dictionary theo cặp với key là giá trị text nhận diện được và value là ground truth của BTC. Khi inference nếu company/address trùng với key trong dictionary thì companty/address đó được thay thế bằng value trong dictionary.
2. Regular expression
Một số trường hợp ngày tháng/timestamp bị sai do lúc làm pseudo label thì giá trị giữa grouth truth và OCR không khớp nhau. Trong trường hợp này khi inference một số trường hợp về date bị bỏ sót, regular expression được dùng trong trường hợp này để trích xuất đúng phần datetime/timestamp bổ trợ cho model graph.

- An invoice reading system using agraph convolutional network
- Information extractionfrom text intensive and visually rich banking documents
- Learning graph nor-malization for graph neural networks
- Unsupervised Representation Learning by Predicting Image Rotations
- Residual Gated Graph ConvNets
- https://atcold.github.io/pytorch-Deep-Learning/
- https://github.com/graphdeeplearning/benchmarking-gnns
- https://github.com/pbcquoc/vietocr
- https://github.com/clovaai/CRAFT-pytorch
