Không biết Deep Learning vẫn làm được Deep Learning với AutoML: Bài toán phát hiện ảnh "nhạy cảm".
Trong bài viết trước về buổi phỏng vấn đầy thú vị giữa nhà báo công nghệ Tony Peng và tiến sĩ Lê Viết Quốc- chuyên gia AI, đồng sáng lập Google Brain, chúng ta đã được hiểu qua về công nghệ AutoML mà Google đã và đang phát triển với khả năng tự động xây dựng các mô hình Deep Learning cho bài ...

Trong bài viết trước về buổi phỏng vấn đầy thú vị giữa nhà báo công nghệ Tony Peng và tiến sĩ Lê Viết Quốc- chuyên gia AI, đồng sáng lập Google Brain, chúng ta đã được hiểu qua về công nghệ AutoML mà Google đã và đang phát triển với khả năng tự động xây dựng các mô hình Deep Learning cho bài toán Computer Vision(Thị giác máy tính). Kết quả đạt được khá ấn tượng khi mô hình được sinh ra bởi máy tính có thể đạt được hiệu suất bằng với hiệu suất của con người.
Hiện nay AutoML đã được Google triển khai thực tế trên Cloud với giá rất là "phải chăng"(khoảng 20$/ 1h). Ba bài toán có thể xử lý bao gồm Computer Vision, Natural language và Translation.
Tuy nhiên, có một lựa chọn phải chăng và hợp lý hơn là 1 thư viện miễn phí, mã nguồn mở được phát triển bởi DATA LAB thuộc trường đại học Texas A&M. Mình xin giới thiệu các bạn ngay trong bài viết này, đó chính là autokeras.
Giới thiệu về Auto Keras
Mục tiêu của Auto Keras là cung cấp một công cụ xây dựng các kiến trúc Deep Learning có thể được sử dụng dễ dàng bởi tất cả mọi người, những lập trình viên có nền tảng về khoa học dữ liệu và học máy hạn chế.
Về cơ bản, Auto Keras cũng được xây dựng tương tự theo phương pháp cho AutoML của Google, thuật toán được sử dụng là Efficient Neural Architecture Search (ENAS) đã được mình đề cập trong bài trước.
Để cài đặt Auto Keras cho python. Ta thực hiện chạy lệnh đơn giản thông qua pip(Hiện tại, Auto Keras chỉ tương thích với python 3.6):
pip install autokeras
Việc sử dụng Auto Keras là cực kì đơn giản, chỉ cần bạn biết một chút python và đọc document của Auto Keras là có thể xây dựng được 1 model cho riêng mình.
Sau đây mình thực hiện luôn một ví dụ để mọi người thấy được sự đơn giản nhưng hiệu quả của nó.
Xây dựng model phát hiện ảnh "nhạy cảm"
Đây là một bài toán thực tưởng là đùa nhưng thực ra rất là quan trọng, nhất là đối với các mạng xã hội phổ biến như Facebook và Zalo. Việc phát hiện những hình ảnh "mang ý đồ xấu" trên các phương tiện truyền thông luôn được quan tâm một cách đặc biệt, góp phần ngăn chặn những hành vi xấu, vi phạm chuẩn mực đạo đức cũng như luật pháp Việt Nam.
Trước tiên, để làm được bài toán này, cũng như bao bài toán khác, chúng ta cần có dữ liệu huấn luyện. Dĩ nhiên, với mục đích demo, giới thiệu về một công nghệ mới là AutoML trong Keras, mình sẽ thu thập dữ liệu hiền nhất có thể với 2 nhãn(0: ảnh bình thường, 1: ảnh xấu). Bạn có thể xem qua dữ liệu huấn luyện tại đây.
Dữ liệu gồm 275 ảnh đẹp và 243 ảnh xấu.
Trước tiên, ta tiến hành đọc dữ liệu ảnh từ 2 thư mục bằng hàm imread() của openCV đồng thời resize lại ảnh về kích thước 64x64, sau đó chuyển toàn bộ dữ liệu về 1 numpy array.
import os import autokeras import cv2 from tqdm import tqdm import numpy as np path_data = '../data/' x_data = [] y_data = [] for i_name in tqdm(os.listdir(os.path.join(path_data, '1'))): image = cv2.imread((os.path.join(path_data, '1', i_name))) resized_image = cv2.resize(image, (64, 64)) x_data.append(resized_image) y_data.append([1]) for i_name in tqdm(os.listdir(os.path.join(path_data, '0'))): image = cv2.imread((os.path.join(path_data, '0', i_name))) resized_image = cv2.resize(image, (64, 64)) x_data.append(resized_image) y_data.append([0]) x_data = np.array(x_data) y_data = np.array(y_data)
Kiểm tra lại kết quả thực hiện đoạn code trên:
print(x_data.shape, y_data.shape)
Kết quả:
(518, 64, 64, 3) (518, 1)
Vì ảnh bây giờ là 64x64 với 3 channel trong kênh màu RGB.
Thực hiện chia dữ liệu thành 2 tập ngẫu nhiên để train và validation theo tỉ lệ 9:1.
from sklearn.model_selection import train_test_split x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.1)
Tiến hành huấn luyện với Auto Keras:
from autokeras.image_supervised import ImageClassifier clf = ImageClassifier(verbose=True) clf.fit(x_train, y_train, time_limit=12 * 60 * 60)
Và đợi,...
Sẽ khá là lâu vì autoKeras sẽ tiến hành sinh ra rất nhiều kiến trúc Deeplearning và thực hiện tìm kiếm để đưa ra mô hình tốt nhất.
Khi thực hiện, quan sát kết quả xuất ra trên cửa sổ dòng lệnh bạn sẽ thấy cách mà chương trình làm việc.
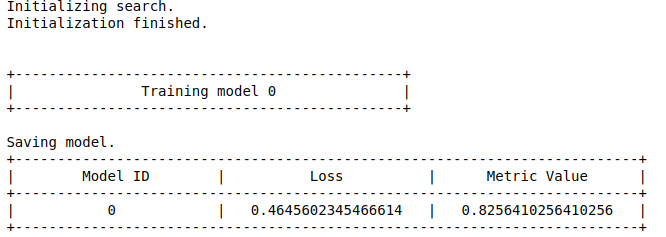

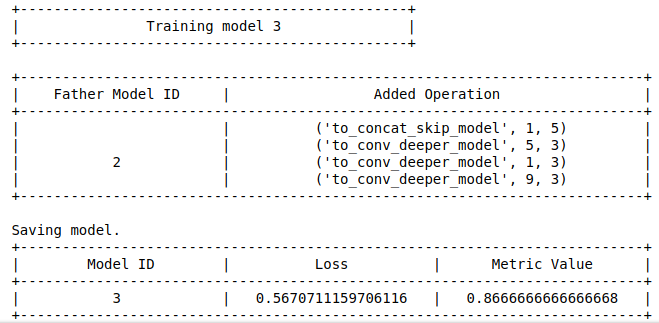
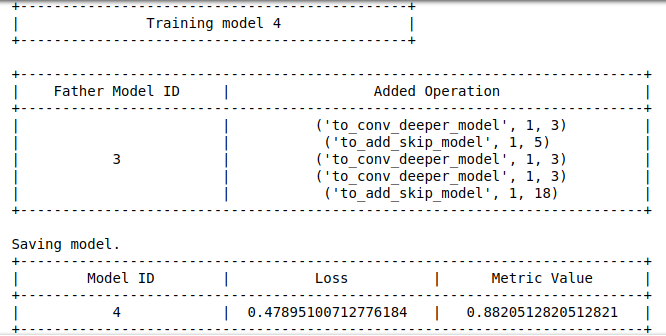
Thực ra quá trình tìm kiếm còn tiếp tục thực hiện ra là lâu nhưng tại lần training thứ 4, mình thấy accuracy trên tập validation đạt 88% nên thôi, mình dừng tạm.
Mô hình tốt nhất cho bài toán này đã được lưu, tiến hành huấn luyện lại sử dụng mô hình tốt nhất:
clf.final_fit(x_train, y_train, x_val, y_val, retrain=True) score = clf.evaluate(x_val, y_val) print(score)
Lưu model huấn luyện được về định dạng h5 file để sử dụng sau này.
clf.load_searcher().load_best_model().produce_keras_model().save('model.h5')
Sử dụng mô hình đã huấn luyện để dự đoán cho ảnh mới bằng việc tải một hình ảnh mới trên google mà không có trong dữ liệu huấn luyện và kiểm tra kết quả:
 (IMG_7438-1.jpg)
(IMG_7438-1.jpg)
path_image = 'IMG_7438-1.jpg' image = cv2.imread(path_image) resized_image = np.array([cv2.resize(image, (64, 64))]) y = clf.predict(resized_image) if(y == 1): print("Ảnh nhạy cảm") else: print("Ảnh đẹp")
Kết quả cho ra ảnh trên là "Ảnh nhạy cảm". Vì hiệu năng của mô hình khá cao nên việc "bắt" được những hình ảnh như thế này là điều khá dễ.
Còn đây là ảnh đẹp và thật may mô hình vẫn đúng trong trường hợp này.

Và cuối cùng, ta xem lại xem model chúng mà Auto Keras vừa xây dựng cho ta có hình dạng như thế nào
