Tìm hiểu và xây dựng các hệ thống Chatbot trong thực thế
Tạo chatbot đơn giản trong Laravel với BotMan Chatbot đã thay đổi cuộc chơi thương mại điện tử như thế nào? Xu hướng và hiệu quả của việc sử dụng Chatbot những năm gần đây Vào thời điểm mình viết bài viết này, Chatbot thậm chí đã là một danh từ nổi tiếng mà khi ...

Xu hướng và hiệu quả của việc sử dụng Chatbot những năm gần đây
Vào thời điểm mình viết bài viết này, Chatbot thậm chí đã là một danh từ nổi tiếng mà khi nhắc đến thì mỗi người đều đã có những hình dung khá cụ thể của riêng mình dành cho nó. Theo một thống kê thực tế từ đầu năm 2018 của Hubspot, số lượng hàng hóa bán ra cho người dùng trên toàn thế giới thông qua chatbot chiếm tới hơn 47% và con số này cho đến nay chắc chắn đã lớn hơn rất nhiều. Ngoài những ưu điểm như luôn luôn sẵn sàng giao tiếp, tư vấn cho người dùng 24/7, chatbot còn giúp chúng ta tiết kiệm được nguồn nhân lực và thời gian lớn để có thể đầu tư vào những hoạt động khác.

Lợi ích và ưu điểm của hệ thống này là khá rõ ràng, cho đến bây giờ thì các hệ thống Chatbot ngày càng trở nên linh động, hoàn hảo hơn , có thể thấy rõ nhất là đối với những chatbot được tạo ra bởi các tập đoàn công nghệ lớn như Google với Google Assistant hay Apple với Siri, Cortana của Microsoft… Trong bài viết lần này, mình sẽ đi sâu vào việc phân loại các hệ thống Chatbot hiện nay, và sau đó, chúng ta sẽ cùng nhau thử xây dựng một Chatbot đơn giản, phục vụ cho việc tìm kiếm thông tin và kiến thức từ internet nhé
Chatbot
Mục tiêu của một hệ thống Chatbot là duy trì và tiếp tục cuộc hội thoại cùng người dùng với mục tiêu bắt chước kiểu nói chuyện “không có cấu trúc” giữa người với người. Tính hữu dụng và độ thông minh của Chatbot được đánh giá dựa trên phép thử Turing. Hiện nay để tối ưu hóa, các hệ thống chatbot sẽ chỉ tập trung vào việc lựa chọn một số lĩnh vực nói chuyện, kiến thức cụ thể cho Chatbot (domain) và đánh giá bằng phép thử Turing trên đúng giới hạn này.
Phân loại các hệ thống Chatbot
Chatbot là một hệ thống dựa vào các kỹ thuật về xử lý ngôn ngữ tự nhiên, vậy nên giống với hầu hết các bài toán về xử lý ngôn ngữ khác, các hệ thống Chatbot có thể được chia làm 2 loại
- Hệ thống Chatbot dựa vào các quy luật, thói quen trong ngôn ngữ của người dùng (Rule-based chatbots)
- Hệ thống Chatbot xây dựng trên một kho dữ liệu hội thoại cho trước (Corpus-based chatbots) – Kho văn bản này có thể được thu thập bằng lượng lớn dữ liệu từ các cuộc nói chuyện của người dùng, sử dụng các phương pháp trích xuất thông tin (Infomation Retrieval) hoặc các phương pháp máy học để tạo ra câu trả lời dựa vào ngữ cảnh trò chuyện với người dùng.
Rule-based chatbots và hệ thống ELIZA
Hiểu một các đơn giản, Rule-based chatbot sẽ trả lời người dùng dựa hoàn toàn vào các thói quen sử dụng ngôn ngữ của chúng ta mà không cần xử lý việc ghi nhớ thông tin trước đó. Tuy rằng trong ngôn ngữ nói hàng ngày của chúng ta, mỗi người đều sẽ có những cách diễn đạt, cách sử dụng từ ngữ riêng để tạo ra các câu hội thoại của bản thân, nhưng thói quen sử dụng ngôn ngữ con người có xu hướng lặp lại khá nhiều. Những thói quen này sẽ được lập trình viên khai thác để xây dựng Chatbot với độ phức tạp chương trình tùy vào mong muốn của người tạo ra. Ví dụ có thể kể đến là nếu trong câu hỏi của người có nhắc tới “thời tiết”, “mưa nắng” hay “nhiệt độ” thì khả năng cao người dùng đang muốn hỏi về tình hình thời tiết..
Hệ thống Chatbot thành công và nổi tiếng nhất thuộc loại này là ELIZA Chatbot . ELIZA được tạo ra từ năm 1966, và được coi như một bước tiến quan trọng trong lịch sử của Chatbot nói chung và trí tuệ nhân tạo nói riêng. ELIZA mô phỏng một bác sỹ tâm lý với công việc lắng nghe và hỏi kỹ càng về những câu chuyện của bệnh nhân, giúp cho họ có thể dần dần nói ra những điều mà họ không thể chia sẻ được với ai. Hãy đi sâu vào tìm hiểu một chút hệ thống điển hình của Rule-based chatbots này để hiểu hơn về nó.
Hãy xem ví dụ một đoạn hội thoại giữa ELIZA (được viết in hoa) và một người bình thường được đăng tải trên hệ thống của họ dưới đây (tiếng Anh)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
... ELIZA: WHO ELSE IN YOUR FAMILY TAKES CARE OF YOU? (Còn ai nữa trong già đình cũng chăm sóc và quan tâm tới bạn không?) user: My father (Bố tôi) ELIZA: YOUR FATHER (Bố của bạn ư?) user: You are like my father in some ways. (Cách bạn nói chuyện cũng có nhiều điểm rất giống ông ấy) ELIZA: WHAT RESEMBLANCE DO YOU SEE (Bạn thấy điểm nào tương tự à?) user: You are not very aggressive but I think you don’t want me to notice that. (Bạn không quá khó tính, nhưng tôi nghĩ bạn cũng không muốn tôi chú ý tới điều đó) ELIZA: WHAT MAKES YOU THINK I AM NOT AGGRESSIVE (Sao bạn lại nghĩ tôi không khó tính) user: You don’t argue with me. (Bạn không tranh luận với tôi) ELIZA: WHY DO YOU THINK I DON’T ARGUE WITH YOU (Sao bạn lại nghĩ tôi sẽ không tranh luận với bạn) user: You are afraid of me. (Bạn có vẻ lo lắng cho tôi) ELIZA: DOES IT PLEASE YOU TO BELIEVE I’M AFRAID OF YOU (Việc tôi lo lắng cho bạn có làm bạn vui không?) user: My father is afraid of everybody. (Bố tôi thậm chí còn lo lắng cho tất cả mọi người) ELIZA: WHAT ELSE COMES TO MIND WHEN YOU THINK OF YOUR FATHER (Còn điều gì bạn nghĩ tới khi nghĩ về bố bạn?) ... |
Đoạn hội thoại diễn ra một cách thực sự rất tự nhiên (Mình có cố gắng dịch ra tiếng Việt nhưng chắc sẽ không được hay lắm). Vậy ELIZA làm thế nào để đạt được điều này? Nhìn qua một số thuật toán “pattern matching” của ELIZA
|
1 2 3 4 5 |
(1 you 2 me) [pattern] -> (WHAT MAKES YOU THINK I 2 YOU?) [trả lời] |
Trong các mẫu câu, các số 1, 2 sẽ thay thế cho các động từ. Ví dụ của việc áp dụng pattern trên vào câu trong thực tế như sau
|
1 2 3 4 5 |
(you hate me) [pattern] -> (WHAT MAKES YOU THINK I HATE YOU?) [trả lời] |
Để xác định được câu nói của người dùng rơi vào mẫu nào (pattern), ELIZA sẽ bắt dựa trên các từ khóa (keyword) xuất hiện trong câu nói của người dùng. Điều này đồng nghĩa với việc hệ thống đã phải định nghĩa sẵn các keyword, đồng thời sắp xếp thứ tự ưu tiên của chúng một cách thực sự hợp lý (Trong trường hợp trong câu xuất hiện nhiều keyword của các pattern khác nhau). Với mỗi pattern, chúng ta sẽ có 3-5 kiểu trả lời để hệ thống random lựa chọn
Cũng theo tác giả, nếu không có keyword nào được xác định, phản hồi của ELIZA sẽ là những mẫu câu kiểu: “PLEASE GO ON”, “THAT’S VERY INTERESTING”, hay “I SEE”. Điều này như một gợi ý để người dùng tiếp tục đưa ra câu hội thoại mới.
Corpus-based chatbots
Thay vì việc sử dụng những luật xây dựng bằng tay như rule-based chatbots, hệ thống chatbot dựa trên kho dữ liệu hội thoại trong thực tế của người với để tìm ra được những phản hồi phù hợp cho hoàn cảnh của mình. Những dữ liệu hội thoại này có thể được thu thập trực tiếp trên một số platform trò chuyện hoặc lấy ra từ các lời thoại của nhân vật trong các bộ phim với nhau.
Corpus-based hiện nay thường sẽ có 2 kiểu hoạt động chính: Trích xuất thông tin cần thiết (Information Retrieval) và áp dụng các bài toán Deep learning theo dạng sequence to sequence (tương tự như Dịch tự động)
Information Retrieval based chatbots (IR-based)

Hệ thống nổi tiếng nhất làm theo mô hình này là Simsimi. Ứng dụng từng một thời được rất rất nhiều sự quan tâm của cộng đồng mạng tại Việt Nam. Cơ chế hoạt động của một hệ thống IR-based có bước đầu tiên là tìm trong cơ sở dữ liệu hội thoại, một câu nói có độ tương tự cao nhất với câu nói hiện tại của user. Từ đó có 2 cách để đưa ra câu trả lời:
- Dùng chính câu nói đó
response = most\_similar (q)response=most_similar(q)
- Dùng câu trả lời cho câu nói đó
response = process (most\_similar (q))response=process(most_similar(q))
Trong thực tế, trong mỗi bài toán, chúng ta lại có cách tính độ tương tự câu nói khác nhau, nhưng cách thông thường nhất vẫn là sử dụng thuật toán TF-IDF để chuyển về dạng vector số thực và tính toán độ tương tự dựa vào khoảng cách cosine.
Mặc dù nhìn qua, cách đưa ra câu trả lời sau khi đã xử lý câu hội thoại tương tự được lấy ra trong cơ sở dữ liệu có vẻ là cách hợp lý hơn, tuy nhiên trong thực tế thì không phải vậy. Việc thêm một bước xử lý một cách gián tiếp (xử lý trên câu tương tự với câu nói của người dùng) sẽ khiến kết quả có khả năng bị nhiễu khá lớn.
Ngoài ra ở phần tiếp theo, mình cũng sẽ giới thiệu với các bạn về một hệ thống chatbot IR-based nhưng được biến đổi đi một chút để phù hợp với nhiệm vụ trả lời các câu hỏi về kiến thức.
Sequence to sequence chatbots
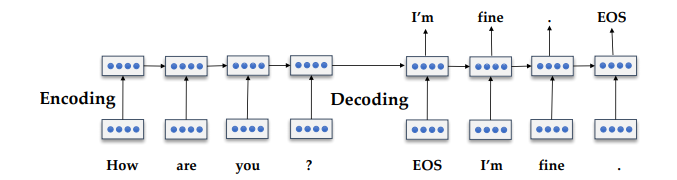
Sequence to sequence là một bài toán đang được giải quyết một cách khá mạnh mẽ bởi các mạng Deep Learning bây giờ. Với đầu vào là 1 câu, dựa trên tập dữ liệu của chúng ta, chúng ta sẽ có thể sinh ra câu trả lời dựa vào Deep Learning. Bài toán này gần tương tự như bài toán dịch tự động (Auto Translation), chỉ khác ở chỗ, trong trường hợp này của chatbots, ngôn ngữ nguồn và ngôn ngữ đích sẽ cùng là một ngôn ngữ.
Một số từ khóa các bạn có thể tìm hiểu theo hướng giải quyết này đó là: Recurrent Neural Network, LSTM, GRU, TCN và Transformer.
Chatbot cho một nhiệm vụ cụ thể (Frame Based Agents)
Ngoài 2 kiểu Chatbot là Rules-based và Corpus-based mình vừa giới thiệu ở trên, mình cũng muốn nói tới 1 loại Chatbot khác nữa. Đa số các Chatbot mà mọi người tiếp xúc (ngoại trừ 1 số chatbot assistant của các hãng công nghệ lớn) đều thuộc loại này – Frame Based Agents. Dịch nôm na là Chatbot Đại Lý. Nó mô phỏng nhiệm vụ của một đại lý, sẽ thu thập các yêu cầu của Khách hàng và gửi yêu cầu đó đi khi đã thu thập đầy đủ được thông tin.
Một ví dụ cụ thể ở đây là Chatbot của một Khách sạn, hỗ trợ người dùng đặt phòng trước. Một cuộc hội thoại giữa nhân viên và khách hàng để book phòng thường sẽ diễn ra theo tiến trình như sau
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
Nhân viên: Xin chào, đây là khách sạn X, em sẽ giúp anh chị đặt phòng tại khách sạn. Ngày anh chị muốn đặt là ngày bao nhiêu ạ? Khách hàng: từ thứ 6 đến chủ nhật tuần này Nhân viên: Anh chị sẽ có thể checkin vào lúc mấy giờ ạ? Khách hàng: khoảng 5h chiều Nhân viên: Hiện có 1 phòng có thể checkin lúc 4h chiều và 1 phòng có thể checkin từ 6h chiều. Anh chị muốn chọn giờ nào ạ? Khách hàng: Vậy anh chọn lúc 4h Nhân viên: Anh cho em xin tên người đặt ạ Khách hàng: Phạm Hoàng Anh Nhân viên: Em cảm ơn anh, em xác nhận lại thông tin book phòng của mình ạ. Người đặt: Phạm Hoàng Anh, book từ ngày.. đến ngày.., thời gian checkin 4h chiều. Em cảm ơn anh đã sử dụng dịch vụ ạ. |
Trên là một đoạn hội thoại ví dụ về cách hoạt động của Chatbot này. Như mình đã nói từ đầu, chatbot làm nhiệm vụ giúp khách hàng đặt phòng và nó sẽ thu thập các thông tin từ phía khách hàng cho tới khi đủ thông tin thì thôi. Một số thông tin cơ bản nó cần có thể dễ thấy như:
- Ngày checkin
- Giờ checkin
- Ngày checkout
- Tên người đặt.
Với loại Chatbot này, luồng thực hiện của Chatbot là khá rõ ràng chứ không “mông lung” như các loại trên. Thiếu thông tin nào Chatbot sẽ phải hỏi thêm về thông tin đó, tuy nhiên thách thức đặt ra ở việc lấy thông tin sao cho chính xác. Ví dụ trong trường hợp hỏi các thông tin ngày, nhiều người sẽ có thể kèm luôn cả giờ trong câu trả lời như: “Anh book từ 4-5h 15-9-2019”. Vậy làm sao để lấy được ngày và giờ một cách chính xác? Mỗi người sẽ có một cách trả lời thông tin riêng, điều này cần thời gian để chúng ta có thể handle được toàn bộ các tình huống.
Thử làm một Question – Answering Chatbot
Như mình đã nói ở phần trên, tại cuối bài, chúng ta sẽ cùng nhau tạo ra một hệ thống Chatbot đơn giản, với nhiệm vụ là trả lời các câu hỏi về kiến thức. Luồng xử lý sẽ bao gồm các công đoạn sau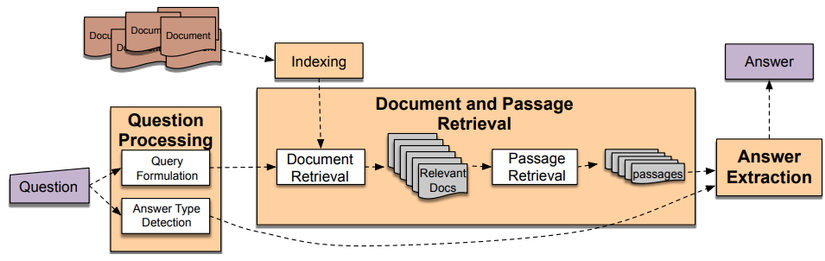
- Question processing: Xử lý ngôn ngữ trong câu hỏi (Bao gồm tách từ, tách các keyword, xác định dạng câu hỏi)
- Document Retrieval: Thu thập các tài liệu liên quan dựa vào đầu ra của Question processing, xử lý và làm sạch thông tin
- Answer Extraction: Lấy ra được câu trả lời hợp lý nhất dựa vào câu hỏi và các tài liệu thu thập được
Để tiện cho các bạn theo dõi, mình có đẩy code lên github ở link sau: https://github.com/hoanganhpham1006/SimpleQuestionAnswering
Các thư viện chúng ta sẽ cần sử dụng cho chức năng này bao gồm:
- Underthesea: Thư viện/ Open Source mạnh về xử lý ngôn ngữ tiếng Việt
- Google API Search: Để thu thập các nguồn tài liệu trên Internet
- Framler: Một thư viện rất hữu dụng của tác giả huyhoang17, mình sẽ giải thích cụ thể về tác dụng của nó ở phần sau
Đầu tiên chúng ta sẽ import các thư viện cần thiết
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from underthesea import word_tokenize from underthesea import ner from nltk import sent_tokenize import requests import framler import string from urllib.parse import urlparse from google import google import framler import operator from tqdm import tqdm |
Đối với các bài toán tiếng Việt, việc tách từ là việc quan trọng nhưng khó hơn rất nhiều so với tiếng Anh. Nếu như trong tiếng Anh, chúng ta chỉ cần tách các từ ra theo khoảng trắng thì tiếng Việt lại không đơn giản như thế. Việc sử dụng các từ ghép khiến cho việc tách sẽ làm mất đi ý nghĩa của các từ này, từ đó kéo theo kết quả của các bài toán không được như mong muốn. Tuy nhiên, sự khó khăn đó của chúng ta đã có underthesea giải quyết hộ)
