Tìm hiểu về YOLO trong bài toán real-time object detection
Trong bài viết này mình xin chia sẻ một chút kiến thức hiểu biết của mình về YOLO, hi vọng có thể giúp mọi người trong các bài toán Object Detection. Object Detection là một bài toán quan trọng trong lĩnh vực Computer Vision, thuật toán Object Detection được chia thành 2 nhóm chính: Họ các mô ...
Trong bài viết này mình xin chia sẻ một chút kiến thức hiểu biết của mình về YOLO, hi vọng có thể giúp mọi người trong các bài toán Object Detection. Object Detection là một bài toán quan trọng trong lĩnh vực Computer Vision, thuật toán Object Detection được chia thành 2 nhóm chính:
- Họ các mô hình RCNN ( Region-Based Convolutional Neural Networks) để giải quyết các bài toán về định vị và nhận diện vật thể.
- Họ các mô hình về YOLO (You Only Look Once) dùng để nhận dạng đối tượng được thiết kế để nhận diện các vật thể real-time
Yolo là một mô hình mạng CNN cho việc phát hiện, nhận dạng, phân loại đối tượng. Yolo được tạo ra từ việc kết hợp giữa các convolutional layers và connected layers.Trong đóp các convolutional layers sẽ trích xuất ra các feature của ảnh, còn full-connected layers sẽ dự đoán ra xác suất đó và tọa độ của đối tượng.
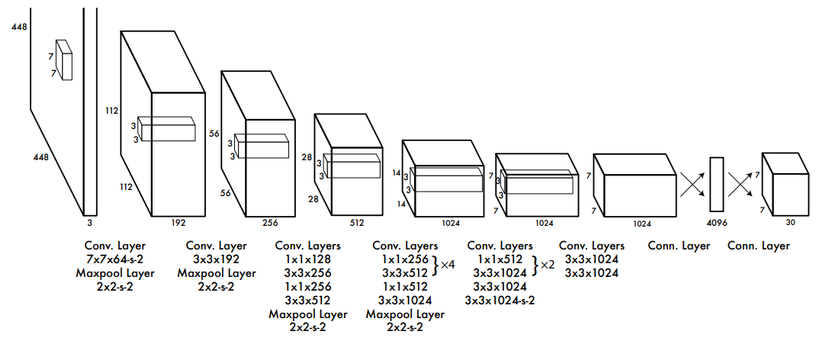
Đầu vào của mô hình là một ảnh, mô hình sẽ nhận dạng ảnh đó có đối tượng nào hay không, sau đó sẽ xác định tọa độ của đối tượng trong bức ảnh. ẢNh đầu vào được chia thành thành S×SS imes SS×S ô thường thì sẽ là 3×33 imes33×3, 7×77 imes77×7, 9×99 imes99×9... việc chia ô này có ảnh hưởng tới việc mô hình phát hiện đối tượng, mình xin trình bày ở phần sau. 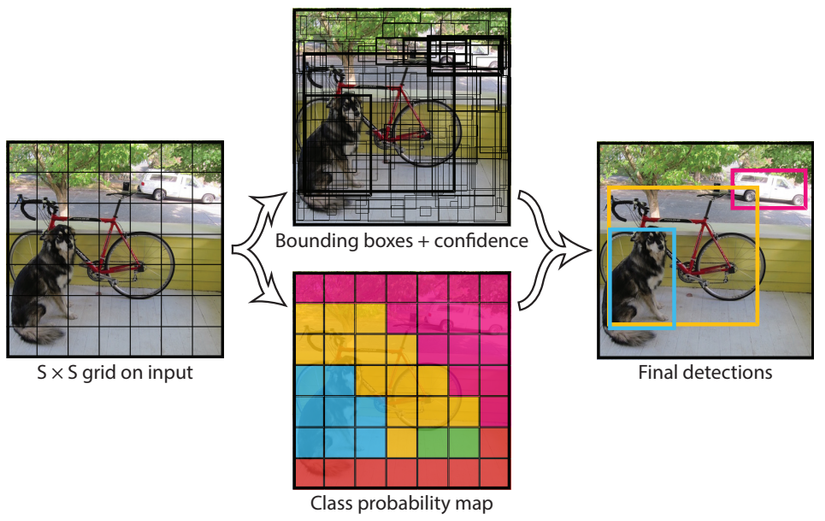
Với Input là 1 ảnh, đầu ra mô hình là một ma trận 3 chiều có kích thước S×S×(5×N+M)S imes S imes(5 imes N+ M)S×S×(5×N+M) với số lượng tham số mỗi ô là (5×N+M)(5 imes N + M)(5×N+M) với N và M lần lượt là số lượng Box và Class mà mỗi ô cần dự đoán. Ví dụ với hình ảnh trên chia thành 7×77 imes77×7 ô, mỗi ô cần dự đóan 2 bounding box và 3 object : con chó, ô tô, xe đạp thì output là 7×7×137 imes7 imes137×7×13, mỗi ô sẽ có 13 tham số, kết quả trả về (7×7×2=98)(7 imes7 imes2 = 98)(7×7×2=98) bounding box. Chúng ta sẽ cùng giải thích con số (5×N+M)(5 imes N + M)(5×N+M) được tính như thế nào.
Dự đoán mỗi bounding box gồm 5 thành phần : (x, y, w, h, prediction) với (x, y ) là tọa độ tâm của bounding box, (w, h) lần lượt là chiều rộng và chiều cao của bounding box, prediction được định nghĩa Pr(Object)∗ IOU(pred,truth)Pr(Object) * IOU(pred, truth)Pr(Object)∗ IOU(pred,truth) xin trình bày sau. Với hình ảnh trên như ta tính mỗi ô sẽ có 13 tham số, ta có thể hiểu đơn giản như sau tham số thứ 1 sẽ chỉ ra ô đó có chứa đối tượng nào hay không P(Object), tham số 2, 3, 4, 5 sẽ trả về x, y ,w, h của Box1. Tham số 6, 7, 8, 9, 10 tương tự sẽ Box2, tham số 11, 12, 13 lần lượt là xác suất ô đó có chứa object1( P(chó|object), object2(P(ô tô|object)), object3(P( xe đạp|object)). Lưu ý rằng tâm của bounding box nằm ở ô nào thì ô đó sẽ chứa đối tượng, cho dù đối tượng có thể ở các ô khác thì cũng sẽ trả về là 0. Vì vậy việc mà 1 ô chứa 2 hay nhiều tâm của bouding box hay đối tượng thì sẽ không thể detect được, đó là một hạn chế của mô hình YOLO1, vậy ta cần phải tăng số lượng ô chia trong 1 ảnh lên đó là lí do vì sao mình nói việc chia ô có thể làm ảnh hưởng tới việc mô hình phát hiện đối tượng.
Trên ta có đề cập prediction được định nghĩa Pr(Object)∗ IOU(pred,truth)Pr(Object) * IOU(pred, truth)Pr(Object)∗ IOU(pred,truth), ta sẽ làm rõ hơn IOU(pred, truth) là gì. IOU (INTERSECTION OVER UNION) là hàm đánh giá độ chính xác của object detector trên tập dữ liệu cụ thể. IOU được tính bằng:
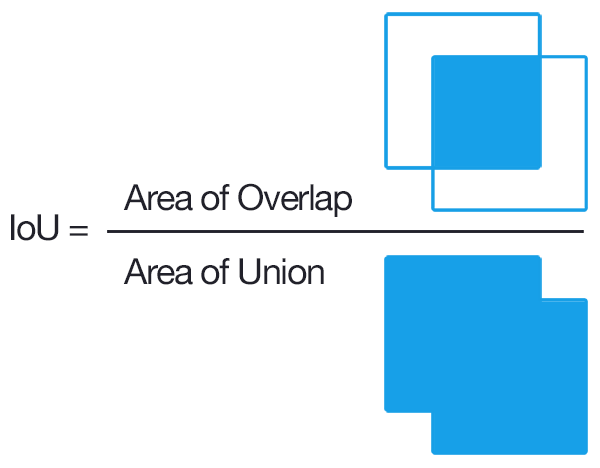
Trong đó Area of Overlap là diện tích phần giao nhau giữa predicted bounding box với grouth-truth bouding box , còn Area of Union là diện tích phần hợp giữa predicted bounding box với grouth-truth bounding box. Những bounding box được đánh nhãn bằng tay trong tập traing set và test set. Nếu IOU > 0.5 thì prediction được đánh giá là tốt.
Hàm lỗi trong YOLO được tính trên việc dự đoán và nhãn mô hình để tính. Cụ thể hơn nó là tổng độ lôĩ của 3 thành phần con sau :
- Độ lỗi của việc dự đoán loại nhãn của object - Classifycation loss
- Độ lỗi của dự đoán tọa độ tâm, chiều dài, rộng của boundary box (x, y ,w, h) - Localization loss
- Độ lỗi của việc dự đoán bounding box đó chứa object so với nhãn thực tế tại ô vuông đó - Confidence loss
Classifycation loss
Classifycation loss - độ lỗi của việc dự đoán loại nhãn cuả object, hàm lỗi này chỉ tính trên những ô vuông có xuất hiện object, còn những ô vuông khác ta không quan tâm. Classifycation loss được tính bằng công thức sau: 
Localization loss
Localization loss là hàm lỗi dùng để tính giá trị lỗi cho boundary box được dự đoán bao gồm tọa độ tâm, chiều rộng, chiều cao của so với vị trí thực tế từ dữ liệu huấn luyện của mô hình. Lưu ý rằng chúng ta không nên tính giá trị hàm lỗi này trực tiếp từ kích thức ảnh thực tế mà cần phải chuẩn hóa về [0, 1] so với tâm của bounding box. Việc chuẩn hóa này kích thước này giúp cho mô hình dự đoán nhanh hơn và chính xác hơn so với để giá trị mặc định của ảnh. Hãy cùng xem một ví dụ: 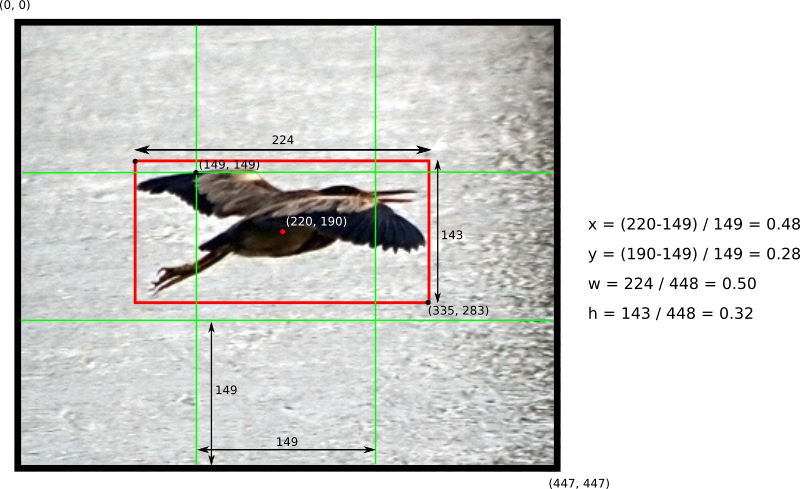
Giá trị hàm Localization loss được tính trên tổng giá trị lỗi dự đoán toạ độ tâm (x, y) và (w, h) của predicted bounding box với grouth-truth bounding box. Tại mỗi ô có chưa object, ta chọn 1 boundary box có IOU (Intersect over union) tốt nhất, rồi sau đó tính độ lỗi theo các boundary box này.
Giá trị hàm lỗi dự đoán tọa độ tâm (x, y) của predicted bounding box và (x̂, ŷ) là tọa độ tâm của truth bounding box được tính như sau :
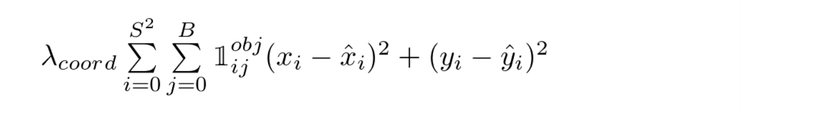
GIá trị hàm lỗi dự đoán (w, h ) của predicted bounding box so với truth bounding box được tính như sau :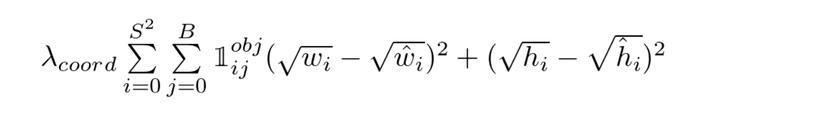 Với ví dụ trên thì S =7, B =2, còn λcoord là trọng số thành phần trong paper gốc tác giả lấy giá trị là 5
Với ví dụ trên thì S =7, B =2, còn λcoord là trọng số thành phần trong paper gốc tác giả lấy giá trị là 5
Confidence loss
Confidence loss là độ lỗi giữa dự đoán boundary box đó chứa object so với nhãn thực tế tại ô vuông đó. Độ lỗi này tính trên cả những ô vuông chứa object và không chứa object.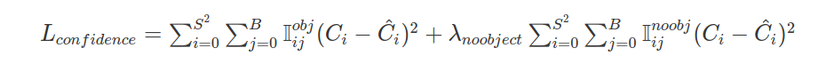
Với ví dụ trên thì S =7, B =2, còn λnoobject là trọng số thành phần trong paper gốc tác giả lấy giá trị là 0.5. Đối với các hộp j của ô thứ i nếu xuất hiệu object thì Ci =1 và ngược lại
Total loss
Tổng lại chúng ta có hàm lỗi là tổng của 3 hàm lỗi trên : 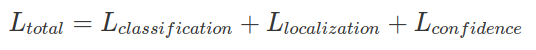 hay:
hay:
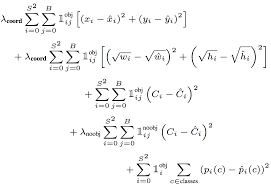
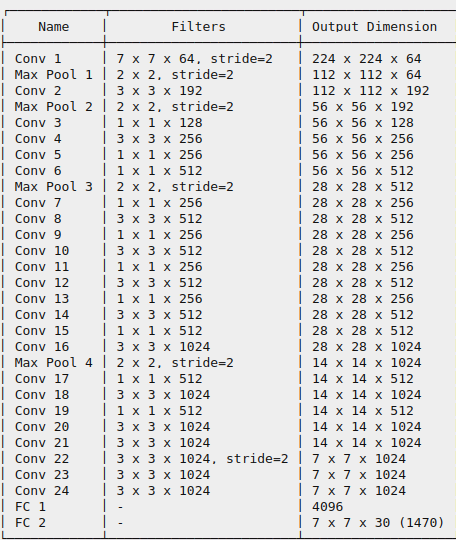
Như ta đã nói ở trên mô hình mạng YOLO là một mô hình mạng CNN thông thường gồm các convolutional layers kết hợp maxpooling layers và cuối cùng là 2 lớp fully connected layers, với hàm kích hoạt cho layer cuối cùng là một linear activation function và tất cả các layers khác sẽ sử dụng leaky RELU :