Xây dựng cho sản xuất: Ứng dụng web - Ghi nhật ký tập trung
Giới thiệu Chúng tôi cuối cùng đã sẵn sàng để thiết lập đăng nhập tập trung cho thiết lập ứng dụng sản xuất của chúng tôi. Ghi nhật ký tập trung là một cách tuyệt vời để thu thập và trực quan hóa nhật ký máy chủ của bạn. Nói chung, việc thiết lập một hệ thống ghi nhật ký phức tạp không quan trọng ...
Giới thiệu
Chúng tôi cuối cùng đã sẵn sàng để thiết lập đăng nhập tập trung cho thiết lập ứng dụng sản xuất của chúng tôi. Ghi nhật ký tập trung là một cách tuyệt vời để thu thập và trực quan hóa nhật ký máy chủ của bạn. Nói chung, việc thiết lập một hệ thống ghi nhật ký phức tạp không quan trọng bằng việc sao lưu và theo dõi vững chắc, nhưng nó có thể rất hữu ích khi cố gắng xác định các xu hướng hoặc các vấn đề với ứng dụng của bạn.
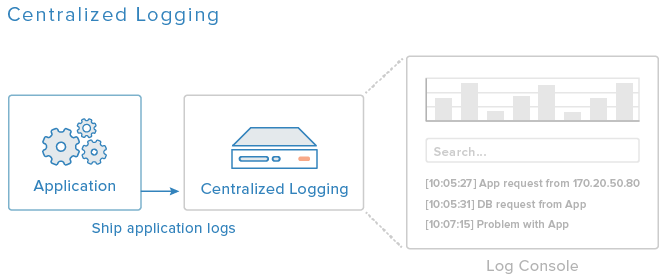
Trong hướng dẫn này, chúng tôi sẽ thiết lập một ngăn xếp ELK (Elasticsearch, Logstash và Kibana), và cấu hình các máy chủ bao gồm ứng dụng của chúng tôi để gửi các bản ghi liên quan của chúng đến máy chủ ghi nhật ký. Chúng tôi cũng sẽ thiết lập Bộ lọc logstash sẽ phân tích cú pháp và cấu trúc nhật ký của chúng tôi, điều này sẽ cho phép chúng tôi dễ dàng tìm kiếm và lọc chúng, đồng thời sử dụng chúng trong hiển thị Kibana.
Điều kiện tiên quyết
Nếu bạn muốn truy cập bảng điều khiển ghi nhật ký của mình thông qua tên miền, hãy tạo Bản ghi trong miền của bạn, như "logging.example.com", trỏ đến khai thác gỗ địa chỉ IP công cộng của máy chủ. Ngoài ra, bạn có thể truy cập trang tổng quan giám sát qua địa chỉ IP công cộng. Chúng tôi khuyên bạn nên thiết lập máy chủ web ghi nhật ký để sử dụng HTTPS và giới hạn quyền truy cập vào máy chủ bằng cách đặt nó sau VPN.
Cài đặt ELK trên máy chủ ghi nhật ký
Thiết lập ELK trên khai thác gỗ máy chủ bằng cách làm theo hướng dẫn này: Làm thế nào để cài đặt Elasticsearch, Logstash, và Kibana 4 trên Ubuntu 14.04.
Nếu bạn đang sử dụng DNS riêng để phân giải tên, hãy đảm bảo theo dõi Lựa chọn 2 bên trong Tạo phần Giấy chứng nhận SSL.
Dừng lại khi bạn đến Thiết lập Logstash Forwarder phần.
Thiết lập Logstash Forwarder trên các máy khách
Thiết lập Logstash Forwarder, người gửi nhật ký, trên máy chủ khách hàng của bạn, ví dụ: db1, app1, app2 và lb1, bằng cách làm theo Thiết lập phần Logstash Forwarder, của hướng dẫn ELK.
Khi bạn hoàn thành, bạn sẽ có thể đăng nhập vào Kibana thông qua khai thác gỗ địa chỉ mạng công cộng của máy chủ và xem nhật ký hệ thống của từng máy chủ của bạn.
Xác định nhật ký để thu thập
Tùy thuộc vào ứng dụng và thiết lập chính xác của bạn, các bản ghi khác nhau sẽ có sẵn để được thu thập vào ngăn xếp ELK của bạn. Trong trường hợp của chúng tôi, chúng tôi sẽ thu thập các bản ghi sau:
- Nhật ký truy vấn chậm MySQL (db1)
- Truy cập và nhật ký lỗi Apache (app1 và app2)
- Nhật ký HAProxy (lb1)
Chúng tôi đã chọn những nhật ký này vì chúng có thể cung cấp một số thông tin hữu ích khi khắc phục sự cố hoặc cố gắng xác định xu hướng. Máy chủ của bạn có thể có các nhật ký khác mà bạn muốn thu thập, nhưng điều này sẽ giúp bạn bắt đầu.
Thiết lập nhật ký MySQL
Nhật ký truy vấn chậm của MySQL thường được đặt tại /var/log/mysql/mysql-slow. Nó bao gồm các nhật ký chạy đủ lâu để được coi là "truy vấn chậm", vì vậy việc xác định các truy vấn này có thể giúp bạn tối ưu hóa hoặc khắc phục sự cố ứng dụng của bạn.
Bật Nhật ký truy vấn chậm MySQL
Nhật ký truy vấn chậm không được bật theo mặc định, vì vậy hãy định cấu hình MySQL để ghi lại các loại truy vấn này.
Mở tệp cấu hình MySQL của bạn:
sudo vi /etc/mysql/my.cnf
Tìm nhật ký đã nhận xét_chậm chạp_truy vấn "line và uncomment nó để nó trông như thế này:
/etc/mysql/my.cnf
log_slow_queries = /var/log/mysql/mysql-slow.log
Lưu và thoát.
Chúng ta cần phải khởi động lại MySQL để đặt thay đổi có hiệu lực:
sudo service mysql restart
Bây giờ MySQL sẽ ghi lại các truy vấn chạy dài của nó vào tệp nhật ký được chỉ định trong cấu hình.
Tệp nhật ký của tàu MySQL
Chúng ta phải cấu hình Logstash Forwarder để gửi bản ghi truy vấn chậm MySQL tới máy chủ đăng nhập của chúng ta.
Trên máy chủ cơ sở dữ liệu của bạn, db1, mở tệp cấu hình Logstash Forwarder:
sudo vi /etc/logstash-forwarder.conf
Thêm phần sau, trong phần "tệp" trong các mục hiện có, để gửi nhật ký truy vấn chậm MySQL dưới dạng "mysql-slow" tới máy chủ Logstash của bạn:
logstash-forwarder.conf â MySQL slow query
,
{
"paths": [
"/var/log/mysql/mysql-slow.log"
],
"fields": { "type": "mysql-slow" }
}
Lưu và thoát. Điều này cấu hình Logstash Forwarder gửi các bản ghi truy vấn chậm MySQL và đánh dấu chúng là các bản ghi kiểu "mysql-slow", các bản ghi này sẽ được sử dụng để lọc sau này.
Khởi động lại Logstash Forwarder để bắt đầu vận chuyển các bản ghi:
sudo service logstash-forwarder restart
Codec đầu vào nhiều dòng
Nhật ký truy vấn chậm MySQL có định dạng nhiều dòng (tức là mỗi mục nhập kéo dài nhiều dòng), vì vậy chúng tôi phải bật codec đa kênh của Logstash để có thể xử lý loại nhật ký này.
Trên máy chủ ELK, khai thác gỗ, mở tập tin cấu hình nơi đầu vào Lumberjack của bạn được xác định:
sudo vi /etc/logstash/conf.d/01-lumberjack-input.conf
Trong lumberjack định nghĩa đầu vào, thêm các dòng sau:
codec => multiline {
pattern => "^# User@Host:"
negate => true
what => previous
}
Lưu và thoát. Điều này cấu hình Logstash để sử dụng bộ xử lý nhật ký đa cấp khi nó gặp các bản ghi có chứa mẫu được chỉ định (tức là bắt đầu bằng "# User @ Host:").
Tiếp theo, chúng ta sẽ thiết lập bộ lọc Logstash cho các bản ghi MySQL.
Bộ lọc nhật ký MySQL
Trên máy chủ ELK, khai thác gỗ, mở một tệp mới để thêm bộ lọc nhật ký MySQL của chúng tôi vào Logstash. Chúng tôi sẽ đặt tên cho nó 11-mysql.conf, do đó, nó sẽ được đọc sau khi cấu hình đầu vào Logstash (trong 01-lumberjack-input.conf tập tin):
sudo vi /etc/logstash/conf.d/11-mysql.conf
Thêm định nghĩa bộ lọc sau:
11-mysql.conf
filter {
# Capture user, optional host and optional ip fields
# sample log file lines:
if [type] == "mysql-slow" {
grok {
match => [ "message", "^# User@Host: %{USER:user}(?:[[^]]+])?s+@s+%{HOST:host}?s+[%{IP:ip}?]" ]
}
# Capture query time, lock time, rows returned and rows examined
grok {
match => [ "message", "^# Query_time: %{NUMBER:duration:float}s+Lock_time: %{NUMBER:lock_wait:float} Rows_sent: %{NUMBER:results:int} s*Rows_examined: %{NUMBER:scanned:int}"]
}
# Capture the time the query happened
grok {
match => [ "message", "^SET timestamp=%{NUMBER:timestamp};" ]
}
# Extract the time based on the time of the query and not the time the item got logged
date {
match => [ "timestamp", "UNIX" ]
}
# Drop the captured timestamp field since it has been moved to the time of the event
mutate {
remove_field => "timestamp"
}
}
}
Lưu và thoát. Điều này cấu hình Logstash để lọc mysql-slow nhập nhật ký với các mẫu Grok được chỉ định trong match chỉ thị. Các apache-access nhật ký loại đang được phân tích bằng mẫu Grok Logstash cung cấp khớp với định dạng thông điệp nhật ký Apache mặc định, trong khi apache-error các bản ghi loại đang được phân tích bằng bộ lọc Grok được viết để khớp với định dạng nhật ký lỗi mặc định.
Để đặt các bộ lọc này hoạt động, hãy khởi động lại Logstash:
sudo service logstash restart
Tại thời điểm này, bạn sẽ muốn đảm bảo rằng Logstash đang chạy đúng, vì các lỗi cấu hình sẽ làm cho nó thất bại.
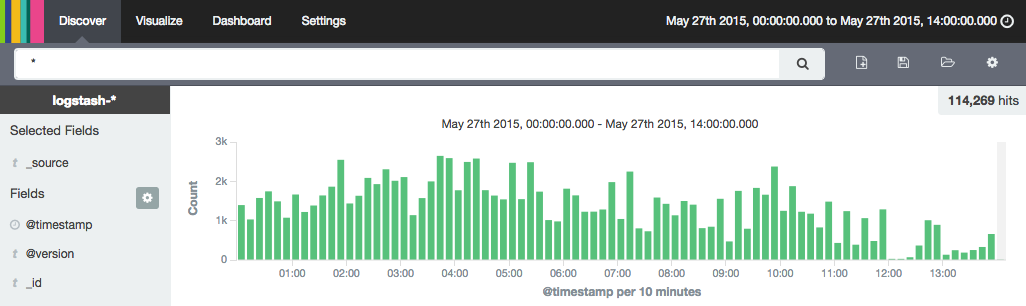
Bạn cũng sẽ muốn xác nhận rằng Kibana có thể xem nhật ký Apache được lọc.
Nhật ký Apache
Nhật ký của Apache thường nằm ở /var/log/apache2, có tên là "access.log" và "error.log". Thu thập các nhật ký này sẽ cho phép bạn xem các địa chỉ IP của người đang truy cập vào máy chủ của bạn, những gì họ đang yêu cầu và hệ điều hành và trình duyệt web nào họ đang sử dụng, ngoài bất kỳ thông báo lỗi nào mà Apache đang báo cáo.
Gửi tệp nhật ký Apache của tàu
Chúng ta phải cấu hình Logstash Forwarder để gửi các truy cập Apache và các bản ghi lỗi tới máy chủ đăng nhập của chúng ta.
Trên máy chủ ứng dụng, app1 và app2 của bạn, hãy mở tệp cấu hình Logstash Forwarder:
sudo vi /etc/logstash-forwarder.conf
Thêm phần sau, trong phần "tệp" trong các mục hiện có, để gửi nhật ký Apache, dưới dạng các kiểu thích hợp, tới máy chủ Logstash của bạn:
logstash-forwarder.conf â Apache access and error logs
,
{
"paths": [
"/var/log/apache2/access.log"
],
"fields": { "type": "apache-access" }
},
{
"paths": [
"/var/log/apache2/error.log"
],
"fields": { "type": "apache-error" }
}
Lưu và thoát. Điều này cấu hình Logstash Forwarder để gửi các truy cập Apache và các bản ghi lỗi và đánh dấu chúng là các kiểu tương ứng của chúng, nó sẽ được sử dụng để lọc các bản ghi.
Khởi động lại Logstash Forwarder để bắt đầu vận chuyển các bản ghi:
sudo service logstash-forwarder restart
Ngay bây giờ, tất cả các bản ghi Apache của bạn sẽ có địa chỉ IP nguồn khách hàng khớp với địa chỉ IP riêng của máy chủ HAProxy, vì proxy ngược HAProxy là cách duy nhất để truy cập máy chủ ứng dụng của bạn từ Internet. Để thay đổi điều này để hiển thị IP nguồn của người dùng thực đang truy cập trang web của bạn, chúng tôi có thể sửa đổi định dạng nhật ký Apache mặc định để sử dụng X-Forwarded-For các tiêu đề mà HAProxy đang gửi.
Mở tệp cấu hình Apache của bạn (apache2.conf):
sudo vi /etc/apache2/apache2.conf
Tìm dòng trông như thế này:
[Label apache2.conf â Original "combined" LogFormat]
LogFormat "%h %l %u %t "%r" %>s %O "%{Referer}i" "%{User-Agent}i"" combined
Thay thế % h với % {X-Chuyển tiếp-For} i, do đó, nó trông như thế này:
[Label apache2.conf â Updated "combined" LogFormat]
LogFormat "%{X-Forwarded-For}i %l %u %t "%r" %>s %O "%{Referer}i" "%{User-Agent}i"" combined
Lưu và thoát. Điều này cấu hình nhật ký truy cập Apache để bao gồm địa chỉ IP nguồn của người dùng thực tế của bạn, thay vì địa chỉ IP riêng của máy chủ HAProxy.
Khởi động lại Apache để thay đổi nhật ký có hiệu lực:
sudo service apache2 restart
Bây giờ chúng ta đã sẵn sàng để thêm các bộ lọc nhật ký Apache vào Logstash.
Bộ lọc nhật ký Apache
Trên máy chủ ELK, khai thác gỗ, mở một tệp mới để thêm bộ lọc nhật ký Apache của chúng tôi vào Logstash. Chúng tôi sẽ đặt tên cho nó 12-apache.conf, do đó, nó sẽ được đọc sau khi cấu hình đầu vào Logstash (trong 01-lumberjack-input.conf tập tin):
sudo vi /etc/logstash/conf.d/12-apache.conf
Thêm các định nghĩa bộ lọc sau:
12-apache.conf
filter {
if [type] == "apache-access" {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
}
filter {
if [type] == "apache-error" {
grok {
match => { "message" => "[(?<timestamp>%{DAY:day} %{MONTH:month} %{MONTHDAY} %{TIME} %{YEAR})] [%{DATA:severity}] [pid %{NUMBER:pid}] [client %{IPORHOST:clientip}:%{POSINT:clientport}] %{GREEDYDATA:error_message}" }
}
}
}
Lưu và thoát. Điều này cấu hình Logstash để lọc apache-access và apache-error nhập nhật ký với các mẫu Grok được chỉ định trong tương ứng match chỉ thị. Các apache-access nhật ký loại đang được phân tích bằng mẫu Grok Logstash cung cấp khớp với định dạng thông điệp nhật ký Apache mặc định, trong khi apache-error các bản ghi loại đang được phân tích bằng bộ lọc Grok được viết để khớp với định dạng nhật ký lỗi mặc định.
Để đặt các bộ lọc này hoạt động, hãy khởi động lại Logstash:
sudo service logstash restart
Tại thời điểm này, bạn sẽ muốn đảm bảo rằng Logstash đang chạy đúng, vì các lỗi cấu hình sẽ làm cho nó thất bại. Bạn cũng sẽ muốn xác nhận rằng Kibana có thể xem nhật ký Apache được lọc.
Nhật ký HAProxy
Nhật ký của HAProxy thường nằm ở /var/log/haproxy.log. Thu thập các nhật ký này sẽ cho phép bạn xem các địa chỉ IP của người đang truy cập trình cân bằng tải của bạn, những gì họ yêu cầu, máy chủ ứng dụng nào đang phân phối các yêu cầu của họ và các chi tiết khác về kết nối.
Tệp nhật ký tàu HAProxy
Chúng ta phải cấu hình Logstash Forwarder để gửi các bản ghi HAProxy.
Trên máy chủ HAProxy của bạn, lb1, mở tệp cấu hình Logstash Forwarder:
sudo vi /etc/logstash-forwarder.conf
Thêm phần sau, trong phần "tệp" trong các mục hiện có, để gửi nhật ký HAProxy dưới dạng "haproxy-log" vào máy chủ Logstash của bạn:
logstash-forwarder.conf â HAProxy logs
,
{
"paths": [
"/var/log/haproxy.log"
],
"fields": { "type": "haproxy-log" }
}
Lưu và thoát. Điều này sẽ cấu hình Logstash Forwarder để gửi các bản ghi HAProxy và đánh dấu chúng là haproxy-log, sẽ được sử dụng để lọc nhật ký.
Khởi động lại Logstash Forwarder để bắt đầu vận chuyển các bản ghi:
sudo service logstash-forwarder restart
Bộ lọc nhật ký HAProxy
Trên máy chủ ELK, khai thác gỗ, mở một tệp mới để thêm bộ lọc nhật ký HAProxy của chúng tôi vào Logstash. Chúng tôi sẽ đặt tên cho nó 13-haproxy.conf, do đó, nó sẽ được đọc sau khi cấu hình đầu vào Logstash (trong 01-lumberjack-input.conf tập tin):
sudo vi /etc/logstash/conf.d/13-haproxy.conf
Thêm định nghĩa bộ lọc sau:
filter {
if [type] == "haproxy-log" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:timestamp} %{HOSTNAME:hostname} %{SYSLOGPROG}: %{IPORHOST:clientip}:%{POSINT:clientport} [%{MONTHDAY}[./-]%{MONTH}[./-]%{YEAR}:%{TIME}] %{NOTSPACE:frontend_name} %{NOTSPACE:backend_name}/%{NOTSPACE:server_name} %{INT:time_request}/%{INT:time_queue}/%{INT:time_backend_connect}/%{INT:time_backend_response}/%{NOTSPACE:time_duration} %{INT:http_status_code} %{NOTSPACE:bytes_read} %{DATA:captured_request_cookie} %{DATA:captured_response_cookie} %{NOTSPACE:termination_state} %{INT:actconn}/%{INT:feconn}/%{INT:beconn}/%{INT:srvconn}/%{NOTSPACE:retries} %{INT:srv_queue}/%{INT:backend_queue} "(%{WORD:http_verb} %{URIPATHPARAM:http_request} HTTP/%{NUMBER:http_version})|<BADREQ>|(%{WORD:http_verb} (%{URIPROTO:http_proto}://))" }
}
}
}
Lưu và thoát. Điều này cấu hình Logstash để lọc haproxy-log nhập nhật ký với các mẫu Grok được chỉ định trong tương ứng match chỉ thị. Các haproxy-log các bản ghi loại đang được phân tích bằng mẫu Grok Logstash cung cấp khớp với định dạng thông điệp tường trình HAProxy mặc định.
Để đặt các bộ lọc này hoạt động, hãy khởi động lại Logstash:
sudo service logstash restart
Tại thời điểm này, bạn sẽ muốn đảm bảo rằng Logstash đang chạy đúng, vì các lỗi cấu hình sẽ làm cho nó thất bại.
Thiết lập Visualization Kibana
Bây giờ bạn đang thu thập nhật ký của mình ở vị trí trung tâm, bạn có thể bắt đầu sử dụng Kibana để hình dung chúng. Hướng dẫn này có thể giúp bạn bắt đầu với điều đó: Làm thế nào để sử dụng Kibana Dashboards và Visualizations.
Một khi bạn cảm thấy thoải mái với Kibana, hãy thử hướng dẫn này để trực quan hóa người dùng của bạn một cách thú vị: Cách lập bản đồ vị trí người dùng với GeoIP và ELK.
Phần kết luận
Xin chúc mừng! Bạn đã hoàn thành loạt bài hướng dẫn Thiết lập ứng dụng web sản xuất. Nếu bạn làm theo tất cả các hướng dẫn, bạn nên có một thiết lập giống như những gì chúng tôi đã mô tả trong hướng dẫn tổng quan (với DNS riêng và sao lưu từ xa):
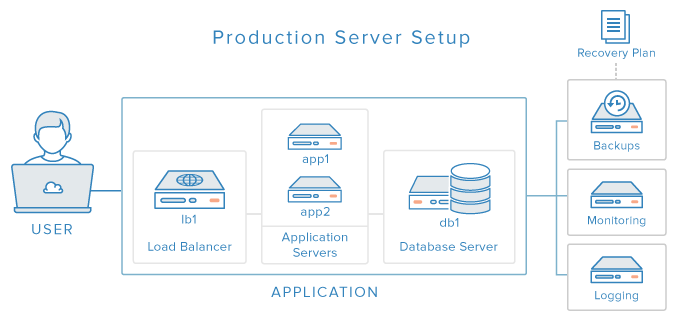
Tức là, bạn cần phải có một ứng dụng đang hoạt động, với các thành phần được tách riêng, được hỗ trợ bởi các thành phần sao lưu, giám sát và ghi nhật ký tập trung. Hãy chắc chắn kiểm tra ứng dụng của bạn và đảm bảo tất cả các thành phần hoạt động như mong đợi.
