Xây dựng web crawler cơ bản với mechanize
Web crawler có chức năng lấy thông tin từ website , trích xuất ra những thông tin người sử dụng cần, đồng thời cũng tìm những link có trong trang web đó và tự động truy cập vào những link đó. Các tên gọi khác của crawler là robot, bot, spider, worm, ant. Nhưng gần đây tên gọi crawler là thông dụng ...
Web crawler có chức năng lấy thông tin từ website , trích xuất ra những thông tin người sử dụng cần, đồng thời cũng tìm những link có trong trang web đó và tự động truy cập vào những link đó. Các tên gọi khác của crawler là robot, bot, spider, worm, ant. Nhưng gần đây tên gọi crawler là thông dụng nhất.
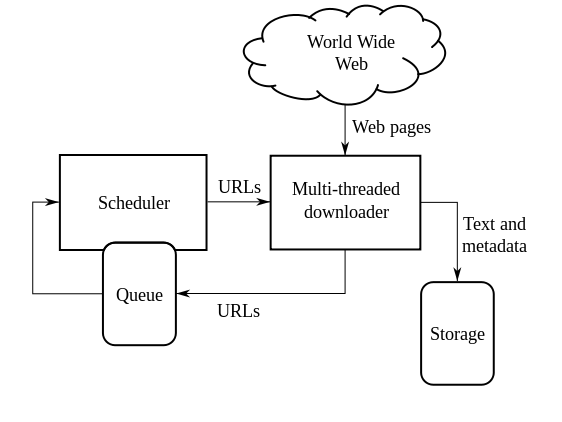
Mô hình crawler đơn giản:
- Chọn URL khởi đầu
- Sử dụng HTML protocol để lấy trang web
- Trích xuất ra các link. Lưu lại trong queue
- Lặp đi lặp lại bước 2,3
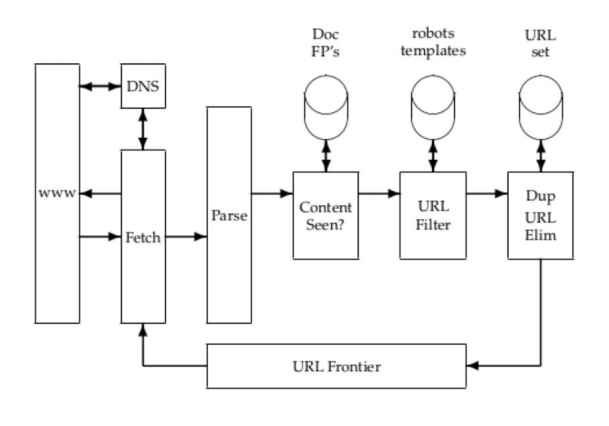
Cụ thể hơn, các module quan trọng của 1 crawler:
- URL Frontier: chứa danh sách các URl chưa được lấy
- Fetch module lấy các trang web
- DNS resolution module xác định địa chỉ của server của trang web đã lấy
- Parsing module trích xuất text và link từ trang web đã lấy
- Duplicate elimination module loại bỏ các URL trùng lặp
Ví dụ minh họa về việc lấy thông tin nhà đất từ trang http://nhadat24h.net Cài đặt:
gem "mechanize"
bundle install
Crawl data: Khởi tạo đối tượng
agent = Mechanize.new
Lấy thông tin trang, trong trang này chúng ta sẽ có 1 danh sách các nhà đang được bán và cho thuê:
page = agent.get "http://nhadat24h.net/ban-bat-dong-san-viet-nam-nha-dat-viet-nam-s686599" + "/#{page_number}"
Để lấy được thông tin từ từng page, chúng ta cần có được cấu trúc của trang:
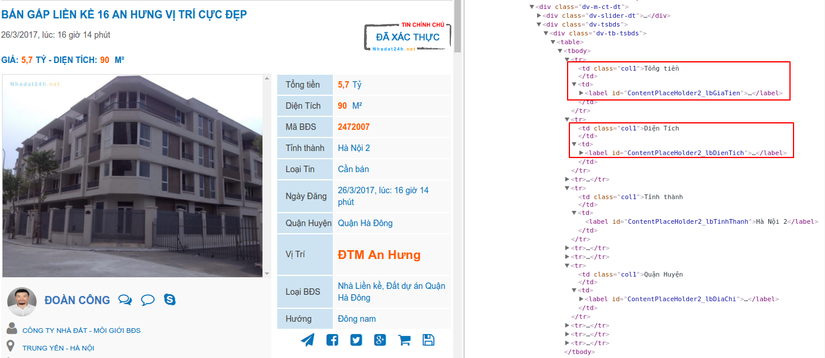 Như các bạn có thể thấy, chúng ta có id của từng trường, vậy chúng ta có thể lấy như sau:
Như các bạn có thể thấy, chúng ta có id của từng trường, vậy chúng ta có thể lấy như sau:
crawled_page = Mechanize.new.get room_url #get price crawled_page.at("#ContentPlaceHolder2_lbGiaTien").try :text #get area crawled_page.at("#ContentPlaceHolder2_lbDienTich").try :text
Lấy thông tin chi tiết, chúng ta sẽ truy cập vào từng trang đã lấy ở trên để lấy thông tin chi tiết từng nhà:
room_url = "http://nhadat24h.net" + link.attributes["href"].try :value page.search("#ContentPlaceHolder2_KetQuaTimKiem1_Pn1 [class^=a-title]").each do |link| crawl_room room_url end private def crawl_room room_url crawled_params = Crawlers::RoomFromNhadat24h.new(room_url).crawled_params room = Room.find_or_initialize_by code: crawled_params[:code], provider_site_cd: crawled_params[:provider_site_cd] room.assign_attributes crawled_params room.save end
Vậy là chúng ta đã hoàn thành việc crawl.
Chú ý: Thông thường, chúng ta sẽ lưu trữ số lượng khổng lồ thông tin sau khi crawl, vậy để có tốc độ đọc ghi cao, hiệu suất lớn và dễ mở rộng, chúng ta nên sử dụng MongoDB. Để tìm hiểu thêm về MongoDB các bạn có thể tham khảo tại: https://viblo.asia/tags/mongodb
Demo project về crawl thông tin nhà đất từ 2 trang http://www.muabannhadat.vn và http://nhadat24h.net https://github.com/otchoo/room_crawler/tree/develop
