AI Conversation (2)
Trong bài trước, mình có nhắc đến Tensorflow để xây dựng 1 ứng dụng conversational. Trước hết tìm hiểu về Tensorflow. Là gì? TensorFlow là 1 library do Google phát triển và opensource vào tháng 11/2015. TensorFlow được cho là sử dụng trong nhiều service của Google: phân loại email của ...
Trong bài trước, mình có nhắc đến Tensorflow để xây dựng 1 ứng dụng conversational. Trước hết tìm hiểu về Tensorflow.
Là gì?
TensorFlow là 1 library do Google phát triển và opensource vào tháng 11/2015. TensorFlow được cho là sử dụng trong nhiều service của Google:
- phân loại email của Gmail,
- nhận biết phát âm và dịch tự động,
- nhận biết khuôn mặt trong Google Photo,
- tối ưu hoá kết quả tìm kiếm,
- quảng cáo trong Youtube.
Đặc trưng của TensorFlow là xử lý được tất cả các loại dữ liệu có thể biểu diễn dưới dạng data flow graph hay low level như xử lý chữ viết tay.
TensorFlow được viết bằng C++, thao tác interface bằng Python vì thế performance rất tốt, dùng được cả CPU lẫn GPU nên TF có thể chạy trên cả PC thông thường lẫn 1 server cực lớn, thậm chí cả smartphone cũng có thể sử dụng được.
Cài đặt
- Trên windows cần cài Python 3.5.x (chỉ hỗ trợ python này trên windows), sau đó chạy -pip3 install --upgrade tensorflow (TensorFlow with CPU support only) hoặc -pip3 install --upgrade tensorflow-gpu (TensorFlow with GPU support) xem thêm tại Installing TensorFlow on Windows
- Trên Ubuntu Installing TensorFlow on Ubuntu
- Trên Mac Installing TensorFlow on Mac OS X
- Ngoài ra, chi tiết xem tại đây
Các khái niệm cơ bản
Tensor
- Tensor là khái niệm cơ bản nhất trong TensorFlow.
- Tensor là cấu trúc dữ liệu được sử dụng trong toàn TensorFlow, đại diện cho tất cả các loại dữ liệu. Hay nói cách khác là tất cả các loại dữ liệu đều là tensor.
- Việc trao đổi dữ liệu trong quá trình xử lý chỉ thông qua tensor.
- Hiểu đơn giản thì tensor là mảng n chiều hay list cộng thêm 1 số thứ khác.
- Tensor có 3 thuộc tính là Rank, Shape, Type.
Biểu đồ tính toán
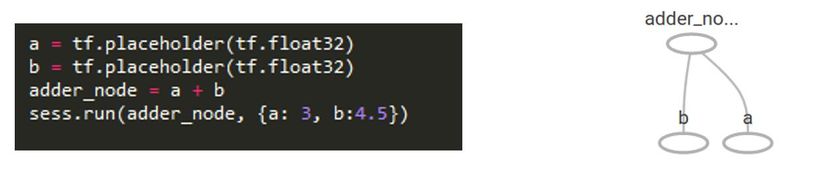
Biểu đồ tính toán (là một loạt các phép toán TensorFlow sắp xếp thành một biểu đồ của các nút) chương trình TensorFlow Core như là hai phần rời rạc:
- Xây dựng biểu đồ tính toán
- Chạy biểu đồ tính toán
Ví dụ ta có phép tính và bên cạnh là Tensorboard
Rank
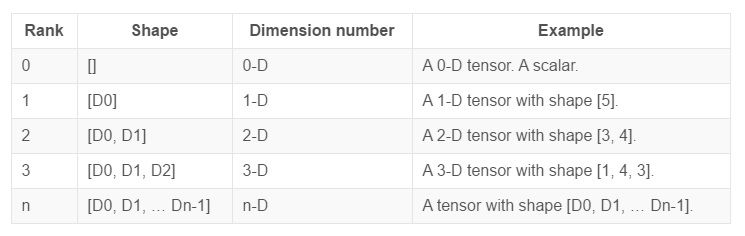
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] có Rank 2 => Rank là số chiều của dữ liệu.

Shape
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] có shape là [3, 3]
t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] có shape là [1, 3, 3]
=> Shape là chiều của tensor.
Type
Là các dạng số trong Tensorflow
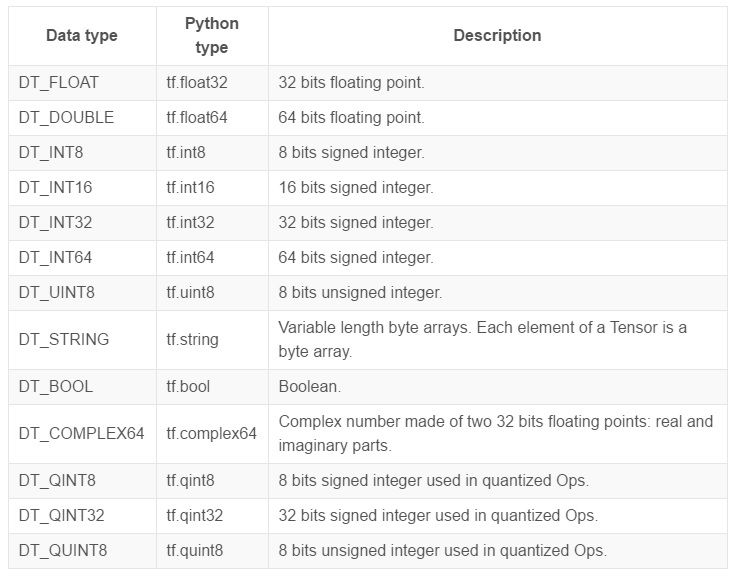
Ngoài ra còn có const, variable,... thì cũng giống bình thường.
tf.train API
Tensorflow có rất nhiều api, nhưng trước hết là tìm hiểu về tf.train này đã.
Ta có:
import numpy as np import tensorflow as tf # Model parameters W = tf.Variable([.3], tf.float32) b = tf.Variable([-.3], tf.float32) # Model input and output x = tf.placeholder(tf.float32) linear_model = W * x + b y = tf.placeholder(tf.float32) # loss loss = tf.reduce_sum(tf.square(linear_model - y)) # sum of the squares # optimizer optimizer = tf.train.GradientDescentOptimizer(0.01) train = optimizer.minimize(loss) # training data x_train = [1,2,3,4] y_train = [0,-1,-2,-3] # training loop init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) # reset values to wrong for i in range(1000): sess.run(train, {x:x_train, y:y_train}) # evaluate training accuracy curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x:x_train, y:y_train}) print("W: %s b: %s loss: %s"%(curr_W, curr_b, curr_loss))
Giải thích:
- W: trọng số (weights)
- b: bias
- linear_model: hàm số gần nhất thoả mãn bộ dữ liệu (dữ liệu đầu vào và kết quả thực tế cho trước)
- [x, y] cặp dữ liệu đầu vào và kết quả
- loss: Hàm mất mát trả về một số thực không âm thể hiện sự chênh lệch giữa hai đại lượng: y’ được dự đoán và y đúng. Trong trường hợp lý tưởng, tức là khi y’ = y, hàm mất mát sẽ trả về giá trị cực tiểu, bằng 0.
- TensorFlow cung cấp các trình tối ưu hóa mà từ từ thay đổi từng biến đã cho để giảm thiểu mất mát. Trình tối ưu hóa đơn giản nhất là gradient descent.
Tức là thế này, đây là quá trình training 1 mô hình (1 hàm số) bằng các giá trị đầu vào có sẵn và đầu ra có sẵn tương ứng:
- Tính giá trị output .
- So sánh output với giá trị mong muốn (đầu ra có sẵn tương ứng với đầu vào).
- Nếu chưa đạt được giá trị mong muốn (hàm loss chưa đạt được giá trị tối thiêu) thì hiệu chỉnh trọng số (W) và tính lại output.
Theo ví dụ ở trên, sau khi ta chạy thì sẽ được kết quả:
W: [-0.9999969] b: [ 0.99999082] loss: 5.69997e-11
Trước hết cần tìm hiểu Neural Networks
RNN là gì?
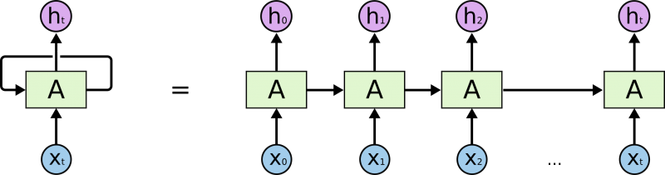
- Ý tưởng của RNN đó là thiết kế một Neural Network sao cho có khả năng xử lý được thông tin dạng chuỗi (sequential information), ví dụ một câu là một chuỗi gồm nhiều từ.
- RNN tạo ra các mạng vòng lặp bên trong chúng, cho phép thông tin được lưu trữ lại cho các lần phân tích tiếp theo.
- Recurrent có nghĩa là thực hiện lặp lại cùng một tác vụ cho mỗi thành phần trong chuỗi. Trong đó, kết quả đầu ra tại thời điểm hiện tại phụ thuộc vào kết quả tính toán của các thành phần ở những thời điểm trước đó.
- Trong biểu đồ trên, A nhận thông tin của x_t tại thời điểm t và phản hồi lại tương ứng kết quả đầu ra h_t tại thời điểm t.
Nói cách khác, RNNs là một mô hình có trí nhớ (memory), có khả năng nhớ được thông tin đã tính toán trước đó. Không như các mô hình Neural Network truyền thống đó là thông tin đầu vào (input) hoàn toàn độc lập với thông tin đầu ra (output). Về lý thuyết, RNNs có thể nhớ được thông tin của chuỗi có chiều dài bất kì, nhưng trong thực tế mô hình này chỉ nhớ được thông tin ở vài bước trước đó.
Trong TF, để sử dụng RNN ta có thể làm theo ví dụ như sau:
lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size) # Initial state of the LSTM memory. state = tf.zeros([batch_size, lstm.state_size]) probabilities = [] loss = 0.0 for current_batch_of_words in words_in_dataset: # The value of state is updated after processing each batch of words. output, state = lstm(current_batch_of_words, state) # The LSTM output can be used to make next word predictions logits = tf.matmul(output, softmax_w) + softmax_b probabilities.append(tf.nn.softmax(logits)) loss += loss_function(probabilities, target_words)
Tại sao lại là BasicLSTMCell thì mọi người có thể tìm hiểu thêm về Vấn đề phụ thuộc quá dài
Sequence-to-Sequence Models
RNN có thể được sử dụng như là mô hình ngôn ngữ cho việc dự đoán các phần tử của một chuỗi khi cho bởi các phần tử trước đó của một chuỗi. Tuy nhiên, chúng ta vẫn còn thiếu các thành phần cần thiết cho việc xây dựng các mô hình đối thoại, hay các mô hình máy dịch, bởi vì chúng ta chỉ có thể thao tác trên một chuỗi đơn, trong khi việc dịch hoạt động trên cả hai chuỗi – chuỗi đầu vào và chuỗi được dịch sang.
Các mô hình chuỗi sang chuỗi được xây dựng bên trên mô hình ngôn ngữ bằng việc thêm vào một bộ mã hóa Encoder và một bộ giải mã Decoder.
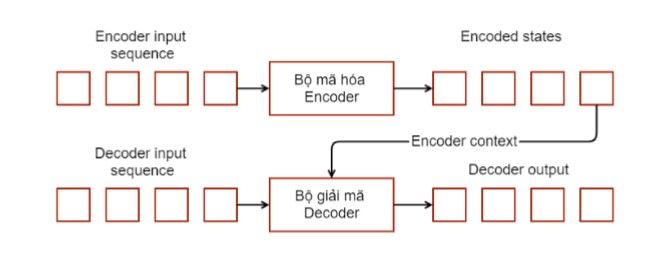
- Bao gồm hai mạng RNN: Một cho bộ mã hóa, và một cho bộ giải mã.
- Bộ mã hóa nhận một chuỗi (câu) đầu vào và xử lý một phần tử (từ trong câu) tại mỗi bước.
- Mục tiêu của nó là chuyển đổi một chuỗi các phần tử vào một vectơ đặc trưng có kích thước cố định mà nó chỉ mã hóa thông tin quan trọng trong chuỗi và bỏ qua các thông tin không cần thiết.
Sử dụng trong TF:
outputs, states = basic_rnn_seq2seq(encoder_inputs, decoder_inputs, cell)
Nói lan man từ nãy tới giờ, thì chốt lại vấn đề là ta đang dùng Tensorflow để xây dựng 1 ứng dụng giao tiếp, trong đó dùng train api của TF để "dạy" nó và dùng seq2seq api để tạo ra cách mà nó trả lời câu hỏi đưa ra. Clone app từ Deep Q&A (đây là 1 mô hình được dựa trên A neural conversational model của Google, tất nhiên là không phải do mình làm, nhưng tin mình đi, để cài đặt và chạy ra được kết quả cũng phức tạp ngang việc code ra nó đấy)
Cài đặt những thứ cần thiết
Yêu cầu
- python 3.5
- tensorflow
- numpy
- CUDA (nếu dùng bản TF với GPU)
- nltk (natural language toolkit for tokenized the sentences)
- tqdm (progression bars lúc mình training)
Download additional data để chạy nltk.
python3 -m nltk.downloader punkt
Sử dụng Cornell dataset để training Model của chúng ta, đây là 1 tập hợp các câu đối thoại trong phim mà ngta đã tổng hợp lại
