Android: Ứng dụng Augmented reality (AR) hiển thị đối tượng 3D
Trong bài đăng này, chúng tôi sẽ giới thiệu cách tạo một ứng dụng AR đơn giản để định vị mô hình 3D ở một vị trí cụ thể trong hiện trường. Chúng tôi không sử dụng các dấu hiệu được xác định trước và thay vào đó sẽ tạo một điểm đánh dấu dựa trên nội dung của cảnh. Nếu bạn đã quen thuộc với các SDK ...
Trong bài đăng này, chúng tôi sẽ giới thiệu cách tạo một ứng dụng AR đơn giản để định vị mô hình 3D ở một vị trí cụ thể trong hiện trường. Chúng tôi không sử dụng các dấu hiệu được xác định trước và thay vào đó sẽ tạo một điểm đánh dấu dựa trên nội dung của cảnh. Nếu bạn đã quen thuộc với các SDK AR khác nhau nhưng tò mò về các thuật toán mà họ thực hiện, bài viết này sẽ đưa ra một kỹ thuật đỉnh cao để giải quyết vấn đề. Đặc biệt chúng ta sẽ thấy làm thế nào để
- Đối chiếu các điểm đặc trưng với vị trí tham chiếu trong cảnh
- Xây dựng ma trận nội tại của máy ảnh .
- Ước tính đặt ra trong mỗi khung
- Hiển thị mô hình 3D tại vị trí tham chiếu
I. Đối chiếu các điểm đặc trưng với vị trí tham chiếu trong cảnh
Trước đây chúng ta đã thấy làm thế nào để trích xuất và làm nổi bật các điểm đặc trưng trong hiện trường. Bây giờ chúng ta sẽ sử dụng điểm đặc trưng để xác định vị trí tham chiếu trong một cảnh. Chúng tôi sẽ tập trung chủ yếu vào lớp học SimpleARClassvì nó chứa tất cả các phương pháp có liên quan. Trong dự án này, khi người dùng nhấn đôi màn hình, vị trí hiện tại được chụp trong phần xem trước của máy ảnh được chọn làm hình ảnh tham chiếu. Đây là cái gọi là "điểm đánh dấu" trong thực tế gia tăng. Sau đó, chúng tôi bắt đầu theo dõi vị trí của điểm đánh dấu trong khung mới. Nếu chúng ta có thể xác định hình ảnh hoặc điểm đánh dấu tham chiếu trong một khung mới, thì chúng ta đánh dấu nó bằng một hình chữ nhật màu đỏ cho biết vị trí của nó trong khung mới. Hai bước này là:
Tạo một điểm đánh dấu với hình ảnh tham chiếu. Phù hợp điểm đánh dấu trong một hình ảnh mới. Chúng ta hãy nhìn vào cả hai bước này một cách chi tiết.
Làm thế nào để tạo ra một điểm đánh dấu?
Một dấu hiệu trong thực tế bổ sung thường đề cập đến một hình ảnh nổi bật được in trên một tờ giấy và đặt trong hiện trường. Một tìm kiếm trên Internet cho thấy đây là ví dụ phổ biến nhất của sự kiện gia tăng. Tuy nhiên cách tiếp cận này đặt ra một hạn chế bổ sung là yêu cầu người sử dụng in một điểm đánh dấu. Chúng tôi tránh sự hạn chế này bằng cách tạo ra một điểm đánh dấu trong nội dung cảnh của chúng tôi. Chúng tôi giả định rằng người dùng sẽ nhấn đúp khi chỉ vào mặt phẳng vì các thuật toán được thiết kế để phù hợp với một điểm đánh dấu phẳng.
Khi người dùng nhấn đôi, chúng tôi gọi SimpleARClass::DoubleTapActionvà kiểm tra nếu có đủ điểm đặc trưng trong cảnh:
if(DetectKeypointsInReferenceImage()) {
trackingIsOn = true;
} else {
trackingIsOn = false;
}
Lưu ý rằng chúng tôi sử dụng điểm đặc trưng và điểm chính interchageably để tham khảo như nhau. Nếu DetectKeypointsInReferenceImagekhông phát hiện đủ điểm đặc trưng, thì chúng ta không tạo ra một điểm đánh dấu. DetectKeypointsInReferenceImageTương tự như DetectAndHighlightCorners(được đề cập trong hướng dẫn trước đó ) nhưng cũng lưu lại vector trọng lực:
bool SimpleARClass::DetectKeypointsInReferenceImage() {
//Detect feature points and descriptors in reference image
cameraMutex.lock();
cornerDetector->detectAndCompute(cameraImageForBack, cv::noArray(),
referenceKeypoints, referenceDescriptors);
cameraMutex.unlock();
MyLOGD("Numer of feature points in source frame %d", (int)referenceKeypoints.size());
if(referenceKeypoints.size() < MIN_KPS_IN_FRAME){
return false;
}
// source gravity vector used to project keypoints on imaginary floor at certain depth
gravityMutex.lock();
sourceGravityVector.x = gravity[0];
sourceGravityVector.y = gravity[1];
sourceGravityVector.z = gravity[2];
gravityMutex.unlock();
return true;
}
Chúng tôi sử dụng detectAndComputeAPI OpenCV để tính toán các điểm chính cũng như các mô tả của chúng. Một descriptor tính năng thường là một vector mã hoá và lưu trữ các khu phố lân cận của một điểm đặc trưng. Điều này giúp chúng tôi xác định duy nhất và kết hợp điểm đặc trưng trong một hình ảnh khác. Các tính năng dò điểm như ORB (được sử dụng trong dự án này), SIFT , SURF ... được đánh giá dựa trên khả năng kết hợp thành công các điểm mô tả trong các hình ảnh truy vấn. Lưu ý rằng referenceKeypointsvà referenceDescriptorslà các biến cá nhân và lưu trữ các vị trí và mô tả để sử dụng sau này.
II. Phù hợp với điểm đánh dấu trong một hình ảnh truy vấn
Để khớp với điểm đánh dấu, chúng tôi tính các điểm đặc trưng và mô tả của chúng cho một hình ảnh máy ảnh mới. Chúng tôi cố gắng kết hợp bộ mô tả của các điểm đặc trưng mới với các mô tả được lưu trữ của hình ảnh điểm đánh dấu. Nếu chúng ta có thể tìm thấy đủ số trận đấu giữa hai bộ, thì chúng ta tuyên bố rằng chúng ta có một sự kết hợp giữa hai hình ảnh (mặc dù chúng ta vẫn cần ước tính tư thế mới). Sự kết hợp được thực hiện trong SimpleARClass::MatchKeypointsInQueryImage. Chức năng này được gọi là bất cứ khi nào một hình ảnh xem trước máy ảnh mới có sẵn ProcessCameraImage. Chúng tôi downscale hình ảnh máy ảnh ProcessCameraImageđể xử lý tốc độ và sau đó gọi MatchKeypointsInQueryImage.
Đầu tiên chúng ta tính điểm tính năng mới và mô tả của chúng trong MatchKeypointsInQueryImage:
cameraMutex.lock();
cornerDetector->detectAndCompute(cameraImageForBack, cv::noArray(), queryKeypoints,
queryDescriptors);
cameraMutex.unlock();
MyLOGD("Number of kps in query frame %d", (int) queryKeypoints.size());
if (queryKeypoints.size() == 0) {
MyLOGD("Not enough feature points in query image");
return false;
}
Tiếp theo chúng ta đối sánh các mô tả ở trên với các thuật toán của marker sử dụng thuật toán k-neighbor neighbor nhất :
std::vector<std::vector<cv::DMatch> > descriptorMatches; std::vector<cv::KeyPoint> sourceMatches, queryMatches; // knn-match with k = 2 matcher->knnMatch(referenceDescriptors, queryDescriptors, descriptorMatches, 2);
Chúng ta đã khởi tạo matcher trước đó để được loại BruteForce-Hamming trong nhà xây dựng của SimpleARClass. Vì chúng tôi chọn k=2, chúng tôi nhận được hai điểm chính mà bộ mô tả phù hợp nhất với mỗi điểm tính năng truy vấn.
Các nghiên cứu thực nghiệm đã chỉ ra rằng chỉ đơn giản lựa chọn những người hàng xóm gần nhất của mỗi điểm đặc trưng dẫn đến một hiệu suất kém trong các tính năng phù hợp. Vì vậy, chúng tôi so sánh các khoảng cách của một điểm đặc trưng cho cả hai nước láng giềng và chỉ chọn những điểm đặc trưng trong đó khoảng cách đến hàng xóm gần nhất ít hơn một ngưỡng:
for (unsigned i = 0; i < descriptorMatches.size(); i++) {
if (descriptorMatches[i][0].distance < NN_MATCH_RATIO * descriptorMatches[i][1].distance) {
sourceMatches.push_back(referenceKeypoints[descriptorMatches[i][0].queryIdx]);
queryMatches.push_back(queryKeypoints[descriptorMatches[i][0].trainIdx]);
}
}
Sau đó, chúng ta sử dụng các cặp kết hợp các điểm đặc trưng để tính homographyma trận liên quan đến các tham chiếu và hình ảnh truy vấn:
Homography = cv :: findHomography ( Keypoint2Point ( sourceMatches ), Keypoint2Point ( queryMatches ),
cv :: RANSAC , RANSAC_THRESH , inlierMask );
Chúng tôi không trích xuất các camera đặt ra từ homographyma trận và, nói đúng, không cần phải tính nó, nhưng chúng tôi sử dụng nó để loại bỏ các ngoại lệ từ các cặp kết hợp các điểm chính:
for (unsigned i = 0; i < sourceMatches.size(); i++) {
if (inlierMask.at<uchar>(i)) {
sourceInlierKeypoints.push_back(sourceMatches[i]);
queryInlierKeypoints.push_back(queryMatches[i]);
}
}
Sau đó chúng tôi sử dụng homographyma trận để vẽ vị trí của điểm đánh dấu trong hình ảnh máy ảnh mới.
DrawShiftedCorners ( cameraImageForBack , homography );
III.Định hình
Định vị là một lĩnh vực phong phú về nghiên cứu về tầm nhìn máy tính và nó có thể có những biến thể tinh tế tùy thuộc vào bản chất của vấn đề. Trong trường hợp của chúng tôi, chúng tôi đã bắt đầu bằng cách nhấn đúp để chọn hình ảnh tham chiếu làm điểm đánh dấu. Sau đó, chúng tôi xác định điểm đánh dấu này trong một hình ảnh mới trong khung xem trước của máy ảnh. Bây giờ chúng tôi muốn tính toán độ dịch chuyển của điểm đánh dấu đối với hình ảnh xem trước của máy ảnh. Sự dịch chuyển này được bắt bởi một vector dịch và một vector quay tương ứng với sáu mức độ tự do của hình ảnh đánh dấu. Để ước lượng hình dáng, chúng ta cần phải tính toán các vector dịch và phép quay. Điều này được thực hiện trong chức năng TrackKeypointsAndUpdatePose. Chức năng này được gọi bởi ProcessCameraImagenếu MatchKeypointsInQueryImagecó thể kết hợp thành công các điểm đặc trưng trên các truy vấn và hình ảnh tham chiếu.
Trong TrackKeypointsAndUpdatePose, chúng tôi bắt đầu với việc chiếu các điểm chính của hình ảnh tham chiếu trên một sàn được giả định là 75 đơn vị cách xa máy ảnh của thiết bị:
sourceKeypointLocationsIn3D = myGLCamera -> GetProjectedPointsOnFloor ( sourceInlierPoints ,
sourceGravityVector ,
CAM_HEIGHT_FROM_FLOOR ,
cameraImageForBack . cols ,
cameraImageForBack . rows );
Điều này được thực hiện để chuyển đổi các vị trí 2D của các điểm chính trên hình ảnh sang các vị trí 3D trong hiện trường. Chúng tôi đã đưa ra hai giả thiết trong khi tính toán vị trí 3D. Trước tiên, chúng tôi giả định rằng các điểm đặc trưng nằm trên mặt đất. Thứ hai, chúng tôi giả định rằng thiết bị ở độ cao CAM_HEIGHT_FROM_FLOORtừ hình ảnh tham chiếu. Giá trị của CAM_HEIGHT_FROM_FLOORkhông phải là quan trọng và có thể được chọn là bất kỳ số hợp lý. Giả định đầu tiên là rất quan trọng vì nếu các điểm không nằm trên bề mặt phẳng thì hiệu suất của thuật toán sẽ rất kém.
Hàm GetProjectedPointsOnFloorđược thực hiện trong myGLCamera.cpp . Nó bao gồm các phép tính lượng giác đơn giản để xác định vị trí 3D của một điểm. Tóm lại, chúng ta xem vị trí của điểm trong hình ảnh, tức là tọa độ 2D của nó. Chúng tôi sử dụng điều này để xác định vị trí của điểm trên máy bay gần. Chúng tôi tạo ra một tia sáng từ mắt của máy ảnh tới điểm trên máy bay gần. Sau đó, sử dụng vector trọng lực, chúng ta giao cắt các tia với mặt đất và tìm vị trí 3D của điểm trên sàn nhà. Chúng tôi bỏ qua các chi tiết toán học.
Tiếp theo chúng ta xác định ma trận nội tại của máy ảnh trong TrackKeypointsAndUpdatePose, và chủ đề này xứng đáng một tiểu mục do tầm quan trọng của nó trong tầm nhìn máy tính.
IV. Xác định ma trận nội tại của máy ảnh
Chúng tôi tham khảo tài liệu của OpenCV cho các phương trình mô tả một mô hình máy ảnh trên bầu trời thường được sử dụng để mô hình hóa một cảnh trong quá trình xử lý hình ảnh. Trong mô hình này, ma trận nội tại của máy ảnh được cho bởi
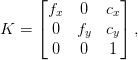
Ở đâu f_xvà f_ylà tiêu cự cho trục X và trục Y tương ứng trong các đơn vị pixel và (c_x, c_y)là điểm chính của hình ảnh lý tưởng nằm ở trung tâm hình ảnh. Chúng tôi đã bỏ qua các hệ số méo mà có thể bóp méo hình ảnh do một số đặc tính vật lý của ống kính thực. Để xác định ma trận này, nhiều hướng dẫn thực tế bổ sung mô tả một bước bổ sung liên quan đến hiệu chuẩn máy ảnh. Trong bước này, họ có hiệu quả xác định các thông số nội tại của máy ảnh và xây dựng ma trận này. Cách tiếp cận như vậy là cần thiết khi chúng ta đang làm việc với máy ảnh có các thông số nội tại cần phải được ước tính. Vì Android cung cấp một API để truy vấn field-of-view (FOV) của máy ảnh, chúng ta có thể xác định độ dài tiêu cự của máy ảnh từ FOV của nó.
Chúng ta hãy nhìn vào chức năng MyGLCamera::ConstructCameraIntrinsicMatForCV:
> cv::Mat MyGLCamera::ConstructCameraIntrinsicMatForCV(float imageWidth, float imageHeight) {
> //derive camera intrinsic mx from GL projection-mx
> cv::Mat cameraIntrinsicMat = cv::Mat::zeros(3, 3, CV_32F);
>
> // fx, fy, camera centers need to be in pixels for cv
> // assume fx = fy = focal length
> // FOV = 2 arctan(imageHeight / focalLength)
> float focalLength = imageHeight / 2 / tan((FOV * M_PI / 180)/2);
> cameraIntrinsicMat.at<float>(0, 0) = focalLength;
> cameraIntrinsicMat.at<float>(1, 1) = focalLength;
>
> // principal point = image center
> cameraIntrinsicMat.at<float>(0, 2) = imageWidth / 2;
> cameraIntrinsicMat.at<float>(1, 2) = imageHeight / 2;
>
> cameraIntrinsicMat.at<float>(2, 2) = 1.;
> return cameraIntrinsicMat;
> }
Nó sử dụng mối quan hệ FOV = 2 arctan(imageHeight / focalLength)để tính toán độ dài tiêu cự của máy ảnh từ FOV. Mục còn lại của ma trận nội tại dễ dàng để điền vào.
Chúng tôi truy vấn FOV ngang của thiết bị (vì chúng tôi thấy đây là một giá trị đáng tin cậy trong vài thiết bị) trong hàm Java CameraClass::SaveCameraFOVvà lấy được FOV dọc từ nó. FOV dọc được thông SimpleARClassqua thông qua cuộc gọi JNI SetCameraParamsNative. Sau đó, FOV dọc được chuyển đến MyGLCameratrong khi tạo ra đối tượng của nó SimpleARClass::PerformGLInits.
V. Xác định các tham số bên ngoài và ước tính đặt ra
Các vectơ dịch và xoay được gọi là các tham số bên ngoài của máy ảnh. Cho đến nay, chúng tôi đã tính vị trí 3D của các điểm đặc trưng từ khung tham chiếu và ma trận nội tại của máy ảnh. Chúng ta đã biết vị trí 2D của các điểm đặc trưng trong hình ảnh xem trước máy ảnh (khung truy vấn). Với ba đầu vào chúng ta có thể giải quyết cho các vector dịch và quay xác định tư thế tương ứng với khung truy vấn. Đây được gọi là vấn đề điểm-n-điểm . Chúng tôi sử dụng solvePnPchức năng từ OpenCV để giải quyết vấn đề này:
pnpResultIsValid = cv::solvePnP(sourceKeypointLocationsIn3D, queryInlierPoints,
cameraMatrix, distCoeffs,
rotationVector, translationVector);
Hãy nhớ rằng tất cả các hoạt động này đang xảy ra trên sợi camera. Mặc dù chúng tôi đã tính toán các tham số bên ngoài, chúng tôi không thể sử dụng chúng để vẽ mô hình 3D trong chủ đề này. Chúng ta hãy xem làm thế nào để render trên thread GLES.
VI. Render một mô hình 3D với các thông số bên ngoài
Xem xét chức năng SimpleARClass::Render. Trong phần đầu của chức năng này, chúng tôi sẽ hiển thị hình ảnh của máy ảnh dưới dạng nền như được mô tả trong hướng dẫn trước. Lưu ý rằng chủ đề kết xuất thực hiện nhanh hơn nhiều so với chủ đề máy ảnh. Bởi thời gian một khung mới được xử lý trên sợi camera, Renderchức năng đã được gọi là nhiều lần. Do đó, chúng ta cần lưu các bản dịch và các vectơ luân hồi là kết quả của solvePnPviệc chúng có thể được sử dụng để tạo ra mô hình 3D trong khi khung ảnh tiếp theo được xử lý. Chúng ta cũng cần phải lật trục của các tham số bên ngoài để phù hợp với hệ tọa độ của OpenGL ES:
/ / Tạo một bản sao của kết quả pnp, nó sẽ được giữ lại cho đến khi kết quả được cập nhật lần nữa ttranslationVectorCopy = translationVector.clone(); rotationVectorCopy = rotationVector.clone(); // flip OpenCV results to be consistent with OpenGL's coordinate system translationVectorCopy.at<double>(2, 0) = -translationVectorCopy.at<double>(2, 0); rotationVectorCopy.at<double>(0, 0) = -rotationVectorCopy.at<double>(0, 0); rotationVectorCopy.at<double>(1, 0) = -rotationVectorCopy.at<double>(1, 0); renderModel = true;
Chúng tôi thiết lập một lá cờ renderModelđể cho biết rằng kết quả bên ngoài có sẵn và có thể được sử dụng để làm cho các mô hình.
Sau đó chúng ta cập nhật ma trận ModelMyGLCamera bằng cách truyền các tham số bên ngoài:
cv::Mat defaultModelPosition = cv::Mat::zeros(3,1,CV_64F); defaultModelPosition.at<double>(2,0) = -CAM_HEIGHT_FROM_FLOOR; myGLCamera->UpdateModelMat(translationVectorCopy, rotationVectorCopy, defaultModelPosition);
Chúng tôi vượt qua một tham số bổ sung defaultModelPositioncho biết vị trí của mô hình 3D trong không gian thế giới. Vì chúng ta giả định rằng mặt phẳng tham chiếu nằm ở khoảng cách CAM_HEIGHT_FROM_FLOORtừ máy ảnh, chúng ta cũng cần đặt mô hình 3D ở cùng một khoảng cách từ máy ảnh trong không gian thế giới. Khác với mô hình sẽ xuất hiện để được "nổi" trên mặt phẳng tham chiếu. Bạn có thể kiểm tra điều này bằng cách chuyển một số giá trị khác với CAM_HEIGHT_FROM_FLOORmã trên.
Chúng ta hãy nhìn vào chức năng MyGLCamera::UpdateModelMat. Phần đầu tiên của hàm chuyển đổi vector dịch sang newModelMatvà điều này khá đơn giản. Sau đó, chúng ta sử dụng chức năng Rodrigues của OpenCV để chuyển đổi vector quay thành một ma trận quay. Vòng quay thực sự là một phần tư và được lưu giữ như là một bộ ba-sử dụng một ký pháp nhỏ gọn.
cv::Mat newRotationMat; cv::Rodrigues(rotationVector, newRotationMat); newRotationMat.copyTo(newModelMat(cv::Rect(0, 0, 3, 3)));
Ma trận quay được sao chép vào góc trên cùng bên trái của ma trận mô hình. Điều này tương tự như ma trận dịch chuyển-xoay như được mô tả trong tài liệu của OpenCV .
Sau đó, chúng tôi tạo ra một glm::mat4từ OpenCV của Mat:
newModelMat.convertTo(newModelMat, CV_32F); newModelMat = newModelMat.t(); modelMat = glm::make_mat4((float *) newModelMat.data);
Chúng tôi sử dụng defaultModelPositionđể tạo ra một ma trận dịch tương ứng với vị trí mặc định của mô hình 3D trong không gian thế giới. Điều này được nhân với modelMatđể tạo ra ma trận Mẫu mới được sử dụng để hiển thị mô hình.
Trở lại SimpleARClass:Render; Chúng ta có được ma trận MVP mới sau khi sắp xếp nó đối với vector trọng lực hiện tại sử dụng GetMVPAlignedWithGravity. Cuối cùng chúng ta render mô hình 3D (chúng tôi đã tải OBJ bằng cách sử dụng Assimp như mô tả trong một hướng dẫn trước đó ). Mô hình 3D sẽ luôn xuất hiện ở cùng vị trí trong cảnh miễn là chúng tôi có thể theo dõi điểm đánh dấu tham chiếu trong hình ảnh truy vấn. Hơn nữa, nó sẽ xuất hiện để đứng trên sàn nhà ở một vị trí thẳng đứng vì chúng ta sử dụng vector trọng lực để sắp xếp nó. Điều này tạo ra một ảo giác rằng mô hình này thực sự hiện diện trong hiện trường và được gọi là "verisimilitude" trong thuật ngữ AR.
Lưu ý : Trong dự án này chúng tôi sử dụng "theo dõi" để tham khảo các điểm đặc trưng phù hợp trong hình ảnh truy vấn với các điểm đánh dấu từ hình ảnh. Đây là một hoạt động chuyên sâu về tính toán và không thể được thực hiện trong thời gian thực ngay cả trong nhiều điện thoại cao cấp. Các ứng dụng AR thường sử dụng thuật toán nhanh hơn để theo dõi đối tượng và có thể sử dụng một kỹ thuật phù hợp để thỉnh thoảng sửa cho các tham số bên ngoài. Để đơn giản, chúng tôi sẽ không giới thiệu thuật toán theo dõi trong dự án này.
