Bắt đầu làm quen với mã hóa string trong ruby
Trong công nghệ thông tin (đặc biệt là lĩnh vực phần mềm và công nghệ) của ngày nay, chúng ta thấy thông tin ở dạng text ở mọi nơi. Text không được cung cấp cho chúng ta ở định dạng đa phương tiện như hình ảnh và video mà nó được lưu trữ nội bộ trong máy tính dưới dạng các con số có mã hóa. Điều đó ...
Trong công nghệ thông tin (đặc biệt là lĩnh vực phần mềm và công nghệ) của ngày nay, chúng ta thấy thông tin ở dạng text ở mọi nơi. Text không được cung cấp cho chúng ta ở định dạng đa phương tiện như hình ảnh và video mà nó được lưu trữ nội bộ trong máy tính dưới dạng các con số có mã hóa. Điều đó có nghĩa là muốn đọc được chúng thì chúng ta phải có một cách giải mã thật hiệu quả. Một ví dụ khá hiển nhiên cho điều tôi muốn nói về việc mã hóa string đó là khi chia sẻ các văn bản thông thường (các bài báo, các bài viết, …) qua các ngôn ngữ khác nhau mà (một hệ thống, một bộ phận) con người có thể không có sự hỗ trợ cho việc dịch và đọc nó. Và vì vậy, đây là lý do tại sao chúng tôi – các developer nên tự làm quen với các tool chúng tôi có để mã hóa và cách chúng tôi có thể hoàn thành công việc đọc các văn bản và làm tốt nhất các công việc của mình từ văn bản đó.
Một số lịch sử cơ bản và Unicode
Việc mã hóa ban đầu dành cho text trên máy tính là sử dụng 8 bits cho mỗi ký tự được mã hóa. Đây là nơi chúng ta nhận được mã ASCII, ANSI, OEM và nhiều đoạn mã hóa tương tự. Nếu bạn đã sử dụng DOS trước Windows thì đây là những gì bạn đã nhìn thấy vào thời điểm đó. Nhưng chỉ sử dụng 8 bits dữ liệu cho mỗi ký tự giới hạn bạn tối đa 255 ký tự. Điều này có nghĩa là nhiều ngôn ngữ trên thế giới hầu hết sẽ không thể làm việc với các bảng mã hóa cơ bản của tiếng Anh chính vì nó không để lại đủ không gian cho các chữ cái của các ngôn ngữ đó có thể thực hiện việc mã hóa và lưu trữ. Bởi vì nhiều ngôn ngữ tạo ra mã hóa riêng của họ.
Kể từ đó đã có những bước tiến lớn hướng tới việc tiêu chuẩn hóa trong cả hai bộ mã hóa và bộ ký tự đó là khi bắt đầu giới thiệu Unicode. Mã hóa được hỗ trợ rộng rãi nhất và được hỗ trợ hiện nay là UTF-8, là một mã hóa ký tự nhiều byte cho phép bất cứ nơi nào từ 1 byte đến 4 byte được sử dụng cho mỗi ký tự. Điều này mang lại cho chúng ta cả tính linh hoạt và hiệu quả mà chúng ta muốn trong một bảng mã. Ngoài ra UTF-8 không có tính xác thực, không có little endian hoặc big endian, đó là tên mà chúng ta cung cấp cho việc biết chúng ta nên đọc các byte từ trái sang phải, hoặc phải sang trái. UTF-8 có thể được đọc theo một trong hai hướng. Dễ hiểu hơn thì đại khái big endian và little endian là 2 tổ chức nền tảng để lưu trữ dữ liệu và tùy mỗi nền tảng thì có cách lưu trữ và sắp xếp khác nhau, mọi người có thể tham khảo thêm (Link1, Link2).
Các bảng mã Unicode có nhiều loại mã hóa có sẵn là UTF-7, UTF-8, UCS-2, UTF-16, UCS-4 và UTF-32. UCS là viết tắt của Universal Character Set và UTF là viết tắt của UCS Transformation format. Vì vậy, UCS là một ký tự cho mỗi nhóm 2 byte hoặc 4 byte có nghĩa là độ dài của string được mã hóa sẽ bằng với độ dài số byte ký tự được nhóm lại (the character byte grouping). Nói cách khác, viết mã cho chúng sẽ dễ dàng hơn nhiều vì độ dài sẽ dịch chính xác giữa phép đo grouping byte và ký tự đại diện thực tế. Tuy nhiên, định dạng chuyển đổi có thể có tối đa lên tới 3 byte chuyển đổi 1 ký tự từ byte đầu tiên, do đó bạn cần phải phân biệt giữa độ dài byte (byte length) và số lượng đồ thị (grapheme count). Vấn đề này không phát sinh nhiều trong Ruby nhưng làm việc ở các ngôn ngữ cấp thấp như Rust hoặc C sẽ khiến bạn thực sự chú ý đến chi tiết này.
UTF-7 và UTF-8 là vô tận trong khi UCS-2, UTF-16, UCS-4 và UTF-32 là hữu hạn. Tiêu chuẩn UTF cung cấp một dấu thứ tự byte hoặc BOM cho ngắn, đó là một vài bit với các điểm đánh dấu để chỉ ra hướng mà các byte sẽ được đọc. Ví dụ, mã hóa UTF-16LE có điểm đánh dấu 0xFF 0xFE để chỉ đó là little endian, có nghĩa là nó phải được đọc từ trái sang phải. UTF-16BE lật hai cái đó để chỉ báo đọc theo hướng khác. BOM này là một tính năng tuyệt vời vì chúng không chỉ cho biết hướng mà còn cho chúng ta một gợi ý rất lớn về việc mã hóa được sử dụng trong trường hợp chúng ta không biết. UTF-32 tuân theo nguyên tắc tương tự, với 0xFF 0xFE 0x00 0x00 được sử dụng cho việc sắp xếp (order) trong little endian và đơn giản là đảo ngược thứ tự của chúng nếu đó là số cuối lớn.
Bây giờ chúng ta có một sự hiểu biết cơ bản về các mã hóa được hỗ trợ tốt nhất từ các tiêu chuẩn Unicode. Nhưng ngay cả như vậy, mã hóa của nhiều loại khác vẫn tồn tại và khi hệ thống của chúng tôi cố gắng đọc các ký tự mà không có mã hóa chính xác, chúng tôi thường bị sai ngữ pháp hoặc được gọi chính thức là文字化け, tiếng Nhật có nghĩa là "chuỗi ký tự không rõ ràng". Vì vậy, hãy làm quen với những gì Ruby cung cấp về cách làm việc với mã hóa.
Phương thức mã hóa trong Ruby
Có hai phương thức cơ bản được sử dụng khi chuyển đổi hoặc biểu diễn một chuỗi và mã hóa chúng là String#force_encoding và String#encode. String#force_encoding là một cách để nói rằng chúng ta biết các bit cho các ký tự là chính xác và chúng ta chỉ muốn xác định một cách đúng đắn là các bit đó được hiểu như thế nào đối với các ký tự. String#encode sẽ chuyển đổi thành mã các bit tự tạo từ các ký tự bắt đầu từ bất kỳ string nào để mã hóa thành string mã hóa đích của chúng ta mong muốn. Dưới đây là một ví dụ:
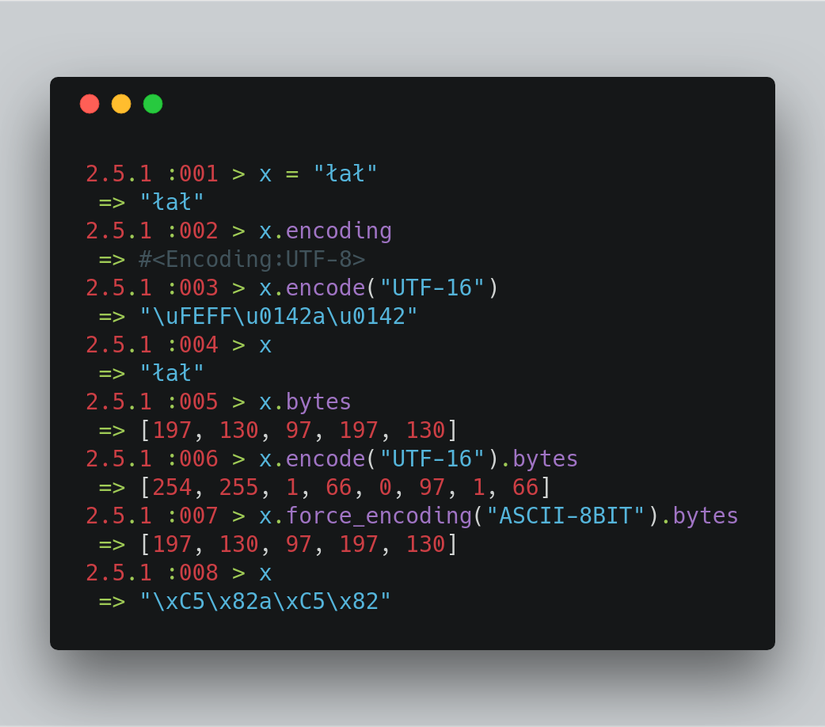
Ở trên, chúng ta có một số ký tự (characters) khác thường. Khi chúng ta sử dụng phương thức mã hóa, nó trả về một bản sao của chuỗi với các byte bên dưới thay đổi mà không sửa đổi chuỗi gốc. Để thay đổi bản gốc, bạn có thể sử dụng String # encode!. Với việc sử dụng x.encode ("UTF-16").bytes bạn có thể thấy sự khác biệt về các byte từ các byte UTF-8 chuẩn.
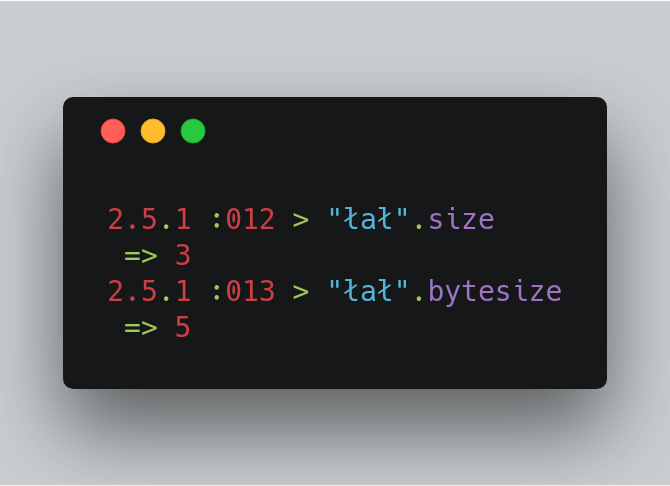
Dưới đây là ví dụ về kích thước byte khác với độ dài ký tự.
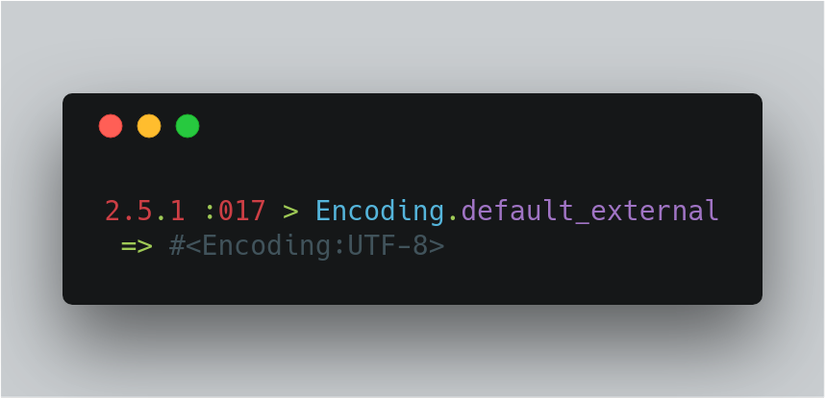
Các hệ điều hành khác nhau có các kiểu mã hóa ký tự mặc định khác nhau vì vậy các ngôn ngữ lập trình cần hỗ trợ chúng. Ruby có phương thức Encoding.default_external xác định mã hóa mặc định của hệ điều hành hiện tại là:
Ruby mặc định là UTF-8 làm mã hóa của nó vì vậy nếu nó đang mở các tệp từ hệ điều hành và mặc định khác với UTF-8, nó sẽ chuyển mã đầu vào từ mã hóa đó sang UTF-8. Nếu bạn không mong muốn vậy, bạn có thể thay đổi mã hóa mặc định trong Ruby bằng Encoding.default_internal. Nếu không, bạn có thể sử dụng mã hóa IO cụ thể trong mã Ruby của bạn.
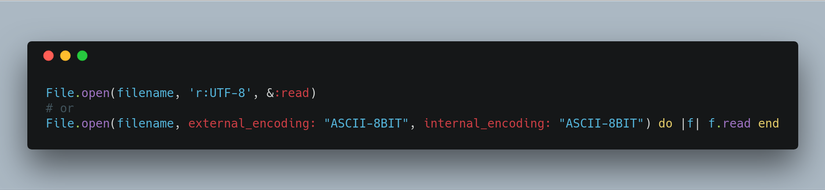
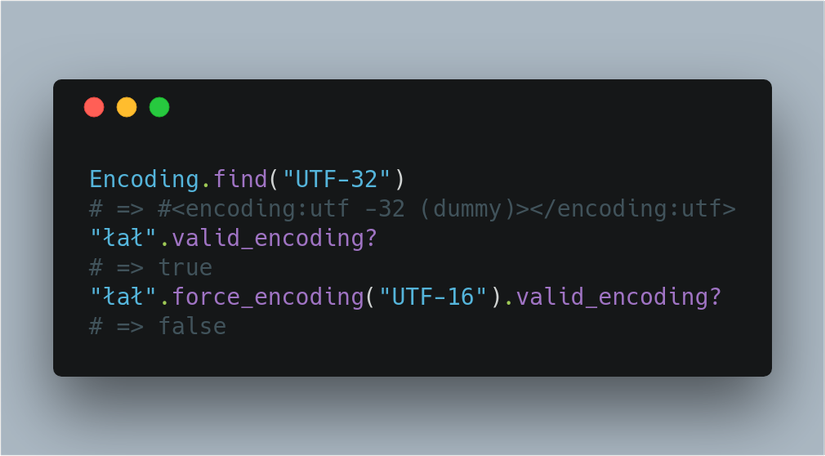
Khi bạn chọn sử dụng String#encode hoặc String#encode! bạn có thể bỏ qua việc cung cấp một tham số để nó tự động sử dụng bộ mã hóa trong Encoding.default_internal. Các phương thức (methods) này cũng có thể lấy hai mã hóa làm tham số đầu tiên để chỉ ra những gì cần chuyển mã từ đâu và sang đâu.Bạn có thể tìm thấy phương thức mã hóa với Encoding.find sau khi thiết lập một mã hóa, và bạn có thể kiểm tra nó:
Một vài thông tin chi tiết cấp thấp cho Ruby
Để có được bức tranh rõ ràng nhất về những gì đang xảy ra trong Ruby khi làm việc với mã hóa, đơn giản nhất, đọc mã nguồn sẽ cho bạn biết tất cả ...( miễn là bạn hiểu C ). Sẽ có nhiều methods sẽ kiểm tra tính tương thích ASCII trước tiên vì lý do hiệu suất. Các hành động đơn giản như hợp nhất hai chuỗi với các đoạn được mã hóa kiểu khác nhau có thể không quá quan trọng nếu chúng hoàn toàn tương thích ASCII. Cơ mà điều này không có nghĩa là các loại mã hóa khác không được hỗ trợ, ... việc này chỉ để ưu tiên hiệu suất, ưu tiên được cung cấp cho kiểu mã hóa ký tự phổ biến nhất.
Nếu bạn đang viết một extensions của Ruby hoặc một thư viện / ứng dụng được tích hợp với Ruby runtime gọi từ API viết bằng ngôn ngữ C, thì sẽ rất hữu ích nếu biết rằng định danh cho các giá trị mã hóa được tạo ra trong thời gian biên dịch là gì. Cơ mà, một số trong những điều đáng suy nghĩ trong Ruby là khác nhau giữa môi trường của ngông ngữ Rubies (có thể là phiên bản, …) trên các hệ thống khác nhau nhưng ở đây không cần lo lằng gì cả bởi vì tại thời gian biên dịch, tất cả mọi thứ được thực hiện để làm việc tốt với chính nó (chính môi trường làm việc đó). Tuy nhiên, điều này có nghĩa là các tệp nhị phân được xây dựng sẵn của Ruby có thể có một số khác biệt tinh tế so với những gì hệ thống được cài đặt trên sẽ được thiết lập. Vì vậy, điều tốt nhất để Ruby hoạt động rất tốt thông qua việc tích hợp với API viết bằng C là biên dịch Ruby cho hệ thống. Bây giờ, điều này không phải lúc nào cũng đúng vì nó phụ thuộc từ nhị phân sang nhị phân. Vì vậy, đối với các máy chủ của bạn, hãy theo dõi các tình huống mà "nó hoạt động trên máy của tôi" cho mỗi phiên bản Ruby, nhưng cũng có những lỗi cụ thể không hoạt động trên máy chủ. Hãy thay đổi compile của Ruby và điều này rất có thể khắc phục vấn đề của bạn.
Tài liệu
Có rất nhiều nguồn tuyệt vời để đọc về chủ đề này. Bạn có thể đọc quyển sau: The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!), nó sẽ cho bạn một cái nhìn tổng quát hơn bài viết này của mình về lịch sử của mã hóa (https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/). Ngoài ra còn có một cuốn sách trực tuyến rất hữu ích cho Unicode – Programming with Unicode (http://unicodebook.readthedocs.io/index.html).
Tổng kết
Làm việc với mã hóa khá thú vị khi bạn biết mình đang làm việc với cái gì. Nhưng khi bạn phải làm việc với cái gì đó mơ hồ, điều đó có thể khó chịu. Khi làm việc với các hệ thống có thể tích hợp với các mã hóa thay thế, hãy đảm bảo ghi lại mã hóa cho phương tiện bạn nhận được nếu nó không phải là một trong các tiêu chuẩn được chấp nhận trên toàn cầu như UTF. Tốt hơn là luôn sẵn sàng cung cấp thông tin này khi xử lý văn bản.
Bài viết được mình tham khảo và dịch lại, có thể nó không biểu thị hết ý, hoặc không đúng, mong mọi người góp ý nhiều hơn nữa để mình hoàn thiện sự hiểu biết của bản thân.
Xin cảm ơn mọi người đã theo dõi bài viết.
