BIG DATA - Hadoop setup and attributes
Overview Ở bài trước mình đã giới thiệu BIG DATA Các bạn có thể đọc nó trước khi vào bài này Hadoop là gì? Nó là một framework mã nguồn mở được viết bằng java, cho phép xử lý phân tán các tập dữ liệu lớn. Nó chạy ứng dụng trên các cụm phần cứng lớn và xử lý hàng ngàn terabytes dữ liệu trên hàng ...
Overview
Ở bài trước mình đã giới thiệu BIG DATA Các bạn có thể đọc nó trước khi vào bài này
Hadoop là gì? Nó là một framework mã nguồn mở được viết bằng java, cho phép xử lý phân tán các tập dữ liệu lớn. Nó chạy ứng dụng trên các cụm phần cứng lớn và xử lý hàng ngàn terabytes dữ liệu trên hàng ngàn nodes. Hadoop lấy cảm hứng từ Google MapReduce và Google File System (GFS). Điểm mạnh của nền tảng Hadoop là cung cấp độ tin cậy và tính sẵn sàng cao.

Big data solutions
Về cơ bản, các hệ thống được xây dựng lên đều sẽ có hệ thống lưu trữ và xử lý dữ liệu. Các hệ thống lữu trữ này có thể là Oracle, MS SQL server, DB2 hoặc MySQL và các phần mềm khác có thể tương tác với cơ sở dữ liệu.
Nếu dữ liệu vẫn cứ ít, hệ thống vẫn chạy nhanh và ổn định thì không vấn đề. Nhưng vì hệ thống càng lâu, dữ liệu thu thập càng nhiều. Điều này làm hệ thống trở nên cồng kềnh và ì ạch.
Chúng ta thử phân tích hướng giải quyết của google
Google đã giải quyết vấn đề này bằng cách sử dụng một thuật toán gọi là MapReduce. Thuật toán này chia dữ liệu thành các phần nhỏ và gán dữ liệu này cho nhiều máy tính, các máy tính này được kết nối qua mạng. Ta có thể thấy sơ đồ dưới đây:
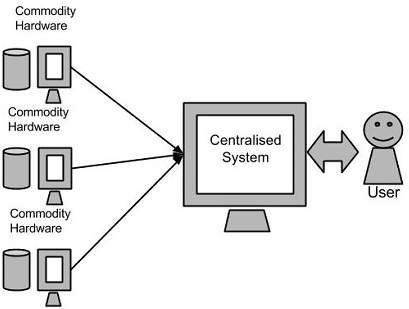
Sự ra đời của Hadoop Hadoop được Doug Cutting và đội của ông xây dựng vào năm 2005. Hadoop chạy các ứng dụng bằng cách sử dụng thuật toán MapReduce, nơi dữ liệu được chạy xử lý song song trên các CPU khác nhau
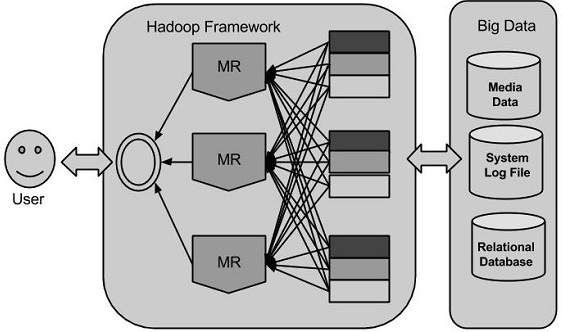
Introduction Hadoop
Hadoop gồm 4 modules:
- Hadoop Common: là các thư viện và tiện ích cần thiết của Java để các module khác sử dụng. Những thư viện này cung cấp hệ thống file và lớp OS trừu tượng, đồng thời chứa các mã lệnh Java để khởi động Hadoop.
- Hadoop YARN: là framework để quản lý tiến trình và tài nguyên của các cluster.
- Hadoop Distributed File System (HDFS): là hệ thống file phân tán cung cấp truy cập thông lượng cao cho ứng dụng khai thác dữ liệu.
- Hadoop MapReduce: là hệ thống dựa trên YARN dùng để xử lý song song các tập dữ liệu lớn.

MapReduce
Hadoop MapReduce là một framework dùng để viết các ứng dụng xử lý song song một lượng lớn dữ liệu có khả năng chịu lỗi cao xuyên suốt hàng ngàn cụm máy tính. Hadoop MapReduce thực hiện 2 tác vụ map và reduce
Map: đây là tác vụ đầu tiên, trong đó dữ liệu đầu vào được chuyển đổi thành tập dữ liệu theo cặp key/value.
Reduce: tác vụ này nhận kết quả đầu ra từ tác vụ Map, kết hợp dữ liệu lại với nhau thành tập dữ liệu nhỏ hơn.
Thông thường, kết quả input và output được lưu trong hệ thống file. Framework này sẽ tự động quản lý, theo dõi và tái thực thi các tác vụ bị lỗi.
Hadoop Distributed File System
Hadoop có thể làm việc trực tiếp với bất kì hệ thống dữ liệu phân tán như Local FS, HFTP FS, S3 FS, và các hệ thống khác. Nhưng hệ thống file thường được dùng bởi Hadoop là Hadoop Distributed File System (HDFS). Hadoop Distributed File System dựa trên Google File System, cung cấp một hệ thống dữ liệu phân tán, được thiết kế để chạy trên các cụm máy tính lớn (gồm hàng ngàn máy tính) có khả năng chịu lỗi cao.
How Does Hadoop Work?
-
Stage1: Một user submit một công việc lên Hadoop với yêu cầu xử lý các thông tin cơ bản (lưu dữ liệu input, lấy dữ liệu phân tán)
-
Stage2: Hadoop submit và thiết lập job tracker. Sau đó hệ thống sẽ phân phối tác vụ đến các máy trạm khác đồng thời theo dõi và quản lý tiến trình các máy này.
-
Stage3: Task - tracker trên các nodes sẽ xử lý các công việc theo luồng MapReduce. Và cuối cùng thì sẽ lưu ra 1 file trên hệ thống.
Installation Hadoop
Hadoop được hỗ trợ bởi nền tảng GNU/Linux và hoạt động tốt trên môi trường này. Vì vậy, chúng ta phải sử dụng hệ điều hành Linux để cài đặt Hadoop. Bài viết này tối sẽ nói đến Ubuntu 14.04 LTS
ssh-key generate
$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/lucky/.ssh/id_rsa): Created directory '/home/lucky/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/lucky/.ssh/id_rsa. Your public key has been saved in /home/lucky/.ssh/id_rsa.pub. The key fingerprint is: ab:e4:49:f4:d5:ea:25:0d:c3:6e:b6:46:db:c8:40:67 lucky@lucky-pc The key's randomart image is: +--[ RSA 2048]----+ | .E.. | |. . ... + | |... . o o o . | | +. . = o | | o+. . S . | |o.++.. . | |..oo. | | | | | +-----------------+
Copy public key id_rsa.pub vào authorized_keys, và phân quyền read/write cho owner của authorized_keys đó.
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
Java installing
Java là điều kiện tiên quyết để cài đặt Hadoop. Trước hết, bạn nên kiểm tra java đã có trong hệ thống của bạn hay chưa bằng lệnh:
$ java -version
Nếu chưa có thì bạn thực hiện
Step1: Download java JDK <latest version> - X64.tar.gz
Step2: Tìm đến file download và thưc hiện
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Step3: move jdk đến "usr/local"
$ mv jdk1.7.0_71 /usr/local/ $ exit
Step4: tạo Path cho biến JAVA_HOME bằng các copy đoạn dưới vào ~/.bashrc
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=$PATH:$JAVA_HOME/bin
Để apply được bạn chạy lệnh này
$ source ~/.bashrc
Step5: Config java
alternatives --install /usr/bin/java java usr/local/java/bin/java 2 alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 alternatives --set java usr/local/java/bin/java alternatives --set javac usr/local/java/bin/javac alternatives --set jar usr/local/java/bin/jar
Hadoop Installing
Có thể download bằng file hoặc bằng wget command line như sau:
# cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Setting Hadoop bằng cách tạo PATH trong ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
Sau đó bạn có thể kiểm tra hadoop
$ hadoop version Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
Test Hadoop Hãy kiểm tra một ví dụ đơn giản của Hadoop. Ví dụ đếm tổng số từ trong 1 file.
Ta tạo 1 file .txt
$ mkdir input $ cp $HADOOP_HOME/*.txt input $ ls -l input total 24 -rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt -rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt -rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txt
Bắt đầu với chạy với lệnh này để đếm số lượng từ trong 1 file
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input output
File kết quả sẽ xuất ra 1 file trong output
$cat output/* "AS 4 "Contribution" 1 "Contributor" 1 "Derivative 1 "Legal 1 "License" 1 "License"); 1 "Licensor" 1 "NOTICE” 1 "Not 1 "Object" 1 "Source” 1 "Work” 1 "You" 1 "Your") 1 "[]" 1 "control" 1 "printed 1 "submitted" 1 (50%) 1 (BIS), 1 (C) 1 (Don't) 1 (ECCN) 1 (INCLUDING 2 (INCLUDING, 2 .............
Như vậy là đã cài đặt thành công Hadoop.
Summary
Vậy là tôi đã hướng dẫn các bạn cài đặt Hadoop, khá đơn giản phải không? Bài tiếp theo chúng ta sẽ tiến hành cài đặt tính năng cho hadoop và bắt đầu chạy thử các ứng dụng test với dữ liệu lớn
Link tham khảo
https://www.tutorialspoint.com/hadoop/index.htm
http://www.guru99.com/learn-hadoop-in-10-minutes.html
http://www.guru99.com/how-to-install-hadoop.html
