BM25 thuật toán xếp hạng các văn bản theo độ phù hợp
Trong tìm kiếm thông tin, Okapi BM25 là hàm tính thứ hạng được các công cụ tìm kiếm sử dụng để xếp hạng các văn bản theo độ phù hợp với truy vấn nhất định. Hàm xếp hạng này dựa trên mô hình xác suất, được phát minh ra vào những năm 1970 – 1980. Phương pháp có tên BM25 (BM – best ...

Trong tìm kiếm thông tin, Okapi BM25 là hàm tính thứ hạng được các công cụ tìm kiếm sử dụng để xếp hạng các văn bản theo độ phù hợp với truy vấn nhất định. Hàm xếp hạng này dựa trên mô hình xác suất, được phát minh ra vào những năm 1970 – 1980. Phương pháp có tên BM25 (BM – best match), nhưng người ta thường gọi “Okapi BM25”, vì lần đầu tiên công thức được sử dụng trong hệ thống tìm kiếm Okapi, được sáng lập tại trường đại học London những năm 1980 và 1990.
BM25 là một phương pháp xếp hạng được sử dụng rộng rãi trong tìm kiếm. Trong Web search những hàm xếp hạng này thường được sử dụng như một phần của các phương pháp tích hợp để dùng trong machine learning, xếp hạng.
Một trong những kỹ thuật tìm kiếm nổi tiếng hiện nay đang sử dụng thuật toán này là Elasticsearch. Khi tìm kiếm, Elascticsearch trả về cho mình ngoài các kết quả tìm được, còn có đánh giá độ liên quan của kết quả dựa trên giá trị thực dương score. Elasticsearch sẽ sắp xếp các kết quả trả về của các query theo thứ tự score giảm dần. Đây là điểm mà mình thấy rất thú vị trong Elasticsearch, và mình sẽ dành bài viết này để nói về cách làm thế nào người ta tính toán và đưa ra được giá trị score và từ đó hiểu được thuật toán BM25.
Lưu ý
Một số thuật ngữ rất hay được sử dụng trong Elasticsearch:
- relevance (độ liên quan)
- index (tương đương với database trong mysql)
- type (tương đương với table trong mysql)
- document (tương ứng với record trong mysql)
- term (từ, từ khóa)
- field (có thể gọi là trường)
Thực chất, BM25 dựa trên nền tảng của TF/IDF, và cải tiến dựa trên lý thuyết probabilitistic information retrieval. Vì vậy để hiểu được gốc rễ của nó trước tiên chúng ta cần phải biết TF/IDF là gì.
TF/IDF viết tắt của thuật ngữ tiếng Anh term frequency – inverse document frequency là trọng số của một từ trong văn bản thu được qua thống kê thể hiện mức độ quan trọng của từ này trong một văn bản, mà bản thân văn bản đang xét nằm trong một tập hợp các văn bản.
Các tính trọng số tf-idf:
- Term frequency
- Inverse document frequency
- Document Length
Term frequency
Yếu tố này đánh giá tần suất xuất hiện của term trong field. Càng xuất hiện nhiều, relevance càng cao. Dĩ nhiên rồi, một field mà từ khoá xuất hiện 5 lần sẽ cho relevance cao hơn là field mà từ khoá chỉ xuất hiện 1 lần.
Thông qua thử nghiệm thực thế và khảo sát người dùng thì Information Retrieval nhận ra rằng: Nếu một bài viết xuất hiện từ “dog” 6 lần thì nó có liên quan gấp đôi bài viết xuất hiện từ “dog” 3 lần không.Thì hầu hết mọi người đều nói không. Chắc chắn bài viết xuất hiện từ “dog” 6 lần sẽ liên quan nhiều hơn nhưng không thế nói nó có liên quan gấp 2 lần so với bài viết xuất hiện từ “dog” 3 lần được. Chính vì thế TF không còn được lấy trực tiếp, thay vào đó TF được tính theo công thức sau:
|
1 2 3 |
tf(t, d) = √frequency |
Giải thích: term frequency (tf) của t trong document d được tính bằng căn bậc hai của số lần t xuất hiện trong d.
Inverse document frequency
Inverse document frequency dùng để đánh giá độ đặc biệt của một từ dựa vào tần suất xuất hiện của term trên toàn bộ index. Càng xuất hiện nhiều thì bài viết càng ít liên quan. Nghe có vẻ hơi ngược ngạo như thật sự nó rất hợp lý:
Ví dụ: Bạn muốn tìm kiếm thuật toán BM25 là gì. Khi bạn tìm kiếm gooogle với từ khóa “thuật toán” thì sẽ nhận được rất nhiều kết quả nhưng lại có rất ít kết quả bạn mong muốn. Còn khi bạn tìm kiếm với từ khóa “BM25” thì nhận được ít kết quả hơn nhưng bạn sẽ thấy rõ ràng các kết quả tìm kiếm sẽ sát với kết quả bạn mong muốn. Suy ra từ khóa “thuật toán” sẻ có giá trị thấp hơn từ khóa “BM25”, “BM25” sẽ cho ra kết quả có relevance cao hơn vì nó xuất hiện ít hơn trên toàn bộ index.
Tương tự, người dùng cho rằng không thể kết luận 1 từ xuất hiện trong 10 bài viết sẽ đặc biệt hơn 10 lần một từ xuất hiện trong 100 bài viết.Tổng hợp dữ liệu thực tế công thức của Inverse document frequency được tính như sau:
|
1 2 3 |
log ( numDocs / docFreq + 1) + 1 |
Giải thích: inverse document frequency (idf) của t là logarit cơ số e (logarit tự nhiên) của thương giữa tổng số documents trong index và số documents xuất hiện t (giá trị công thêm 1 ở đây để tránh xảy ra lỗi Division by zero).
Document Length
Yếu tố này đánh giá độ dài của field. Field càng ngắn, thì term sẽ có giá trị càng cao; và ngược lại. Điều này hoàn toàn dễ hiểu, bạn có thể thấy một từ xuất hiện trong title sẽ có giá trị hơn rất nhiều cũng từ đó nhưng xuất hiện trong content.
Kết quả trung bình được tính từ dữ liệu khảo sát người dùng như sau:
| Raw Length | Field Norm Score |
|---|---|
| 1 | 1.0 |
| 2 | 0.707 |
| 4 | 0.5 |
| 64 | 0.125 |
| 128 | 0.088 |
| 256 | 0.0625 |
|
1 2 3 |
norm(d) = 1 / √numTerms |
Giải thích: field-length norm (norm) là nghịch đảo của căn bậc hai số lượng term trong field. (có thể hiểu là số lượng chữ của field đó)
All Together
score cuối cùng sẽ là tích của 3 giá trị trên:
|
1 2 3 |
IDF score * TF score * fieldNorms |
Hay
|
1 2 3 |
log(numDocs / (docFreq + 1)) * √frequency * (1 / √numTerms) |
Trong đó:
- numDocs chính là maxDocs, đôi khi bao gồm cả những document đã bị delete
- fieldNorm được tính toán và lưu trữ dưới dạng 8 bit floating point number. Nên khi tính toán, hệ thống sẽ encode và decode giá trị của fieldNorm về 8 bit, và theo đó, bạn sẽ thấy giá trị filedNorm đôi khi hơi khác so với tính toán một chút xíu xíu thôi. Nếu muốn hiểu thêm bạn có thể tham khảo tại đây
IDF trong BM25
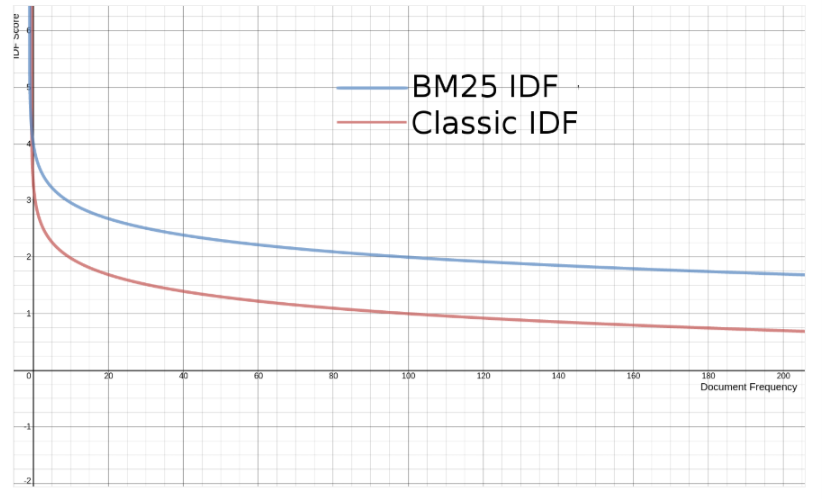
Biểu đồ
Trên biểu đồ cho thấy IDF trong BM25 khá giống IDF trong TF/IDF. Tuy nhiên BM25 đã chỉnh sửa công thức tính lại để thêm khả năng đưa ra score âm khi tần suất xuất hiện của term trên toàn bộ index rất cao(term rất ít đặc biệt).
Công thức:
|
1 2 3 |
idf(t) = log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) |
Trong đó:
- docCount: số lượng document
- docFreq: số lượng document chứa term
TF trong BM25

Biểu đồ
Trên biểu đồ cho thấy: Đối với TF/IDF thì score từ TF sẽ tăng vô hạn khi TF tăng lên. Để giảm tác động của TF với relevance thì BM25 đã chỉnh sửa công thức của TF lại. Kết quả score của TF sẽ giới hạn tới 1 điểm cực đại, và chúng ta có thể tùy chỉnh giới hạn này:
Công thức:
|
1 2 3 |
((k + 1) * tf) / (k + tf) |
*Trong đó: *
- k: hằng số (thường là 1.2)
- freq: frequency của term trong document
Document Length trong BM25
Thực ra công thức TF bên trên kia là chưa thực sự hoàn chỉnh, nó đúng với những document có độ dài trung bình trong toàn bộ index. Nếu độ dài document quá ngắn hoặc quá dài so với độ dài trung bình, thì công thức trên sẽ cho kết quả thiếu chính xác.
Vì thế người ta thêm vào trong công thức trên 2 tham số, một hằng số b và một giá trị độ dài L, công thức sẽ trở thành:
Công thức:
|
1 2 3 |
((k + 1) * freq) / (k * (1.0 - b + b * L) + freq) |
Trong đó:
- b=0.75 (mặc định).
- L là tỉ lệ giữa độ dài của document so với độ dài trung bình của tất cả documents.
|
1 2 3 |
L = fieldLength / avgFieldLength |
Cũng như k, bạn có thể điều chỉnh b để phù hợp với mô hình bạn xây dựng. b càng gần 0 thì độ ảnh hưởng của document length càng nhỏ, và ngược lại, b càng lớn thì độ ảnh hưởng của document length càng lớn.
Đây là biểu đồ thể hiện giá trị của TF đối với các độ dài khác nhau của document:
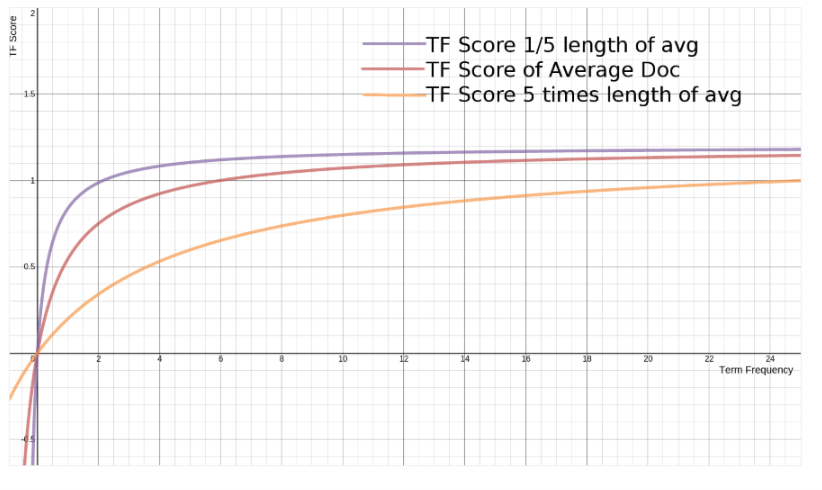
Biểu đồ
All Together
Ta có công thức cuối cùng của BM25
|
1 2 3 |
IDF * (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * (fieldLength / avgFieldLength))) |
Vậy chúng ta đã đi qua được 2 thuật toán dùng để xếp hạng các văn bản theo độ phù hợp là BM25 và TF/IDF. Đồng thời hiểu được các sắp xếp kết quả tìm kiếm của kỹ thuật tìm kiếm Elasticsearch mà chúng ta hay dùng.Hi vọng các bạn có những trải nghiệm thú vị. Tham khảo: tại đây
Techtalk via Viblo
