Các thuật ngữ trong Xử lý ngôn ngữ tự nhiên
Vai trò của Xử lý ngôn ngữ tự nhiên-XLNNTN (Natural Language Processing-NLP) trong khai thác Big Data là không thể phủ nhận trong bối cảnh phát triển của doanh nghiệp hiện nay. Đối với ngôn ngữ tiếng Anh, ta đã được kế thừa nhiều tri thức cũng như nhiều công cụ có sẵn để áp dụng ngay ...

Vai trò của Xử lý ngôn ngữ tự nhiên-XLNNTN (Natural Language Processing-NLP) trong khai thác Big Data là không thể phủ nhận trong bối cảnh phát triển của doanh nghiệp hiện nay. Đối với ngôn ngữ tiếng Anh, ta đã được kế thừa nhiều tri thức cũng như nhiều công cụ có sẵn để áp dụng ngay vào thực tiễn. Tuy nhiên, đối với ngôn ngữ tiếng Việt, ta vẫn còn gặp nhiều khó khăn (nhân sự có chuyên môn còn hạn chế, ngữ liệu để huấn luyện chưa đủ lớn) bên cạnh những cơ hội rất lớn (thị trường Việt Nam chưa được khai thác) cho những ai đam mê lĩnh vực này.
Vì vậy, trong bài viết này, tôi xin lập ra danh sách các thuật ngữ thường gặp trong NLP để tiện tham khảo cũng như giúp cho những bạn mới bắt đầu có thể nhanh chóng tra cứu sơ để tiến hành nghiên cứu ngay các tài liệu khoa học. Bài viết sẽ luôn được cập nhật. Nếu có các thuật ngữ chưa rõ, các bạn có thể comment để chúng ta tiếp tục mở rộng thêm danh sách này.
Natural Language Processing (NLP) – Xử lý ngôn ngữ tự nhiên là lĩnh vực Khoa học máy tính kết hợp giữa Trí tuệ nhân tạo (Artificial Intelligence) và Ngôn ngữ học tính toán (Computational Linguistics) nhằm tập trung xử lý tương tác giữa con người và máy tính sao cho máy tính có thể hiểu hay bắt chước được ngôn ngữ của con người. Các ứng dụng thường thấy như hiện nay là Siri, Cortana và Google Now.
 Siri vs Google Now vs Cortana
Siri vs Google Now vs Cortana
Ambiguity – nhập nhằng (ở nhiều cấp độ: lexical – từ vựng, morphological – hình vị, syntactic – cú pháp, semantic – ngữ nghĩa, domain – lĩnh vực). Ví dụ nhập nhằng từ “đậu” đại diện cho một hành động hay “đậu” đại diện cho một loài thực vật trong câu “Con ruồi đậu mâm xôi đậu”.
Pre-processing – tiền xử lý dữ liệu, xử lý sơ bộ văn bản: xóa bỏ những kí tự, những mã điều khiển, những vùng không cần thiết cho hệ thống gồm: tách đoạn/câu/từ (paragraph/sentence/word segmentation), làm sạch (cleaning), tích hợp (integreation), chuyển đổi (transformation), giảm số chiều (reduction).
 ETL input output
ETL input output
Morphological analysis (Phân tích hình thái)
- Phân tích phụ tố (affix): ví dụ anti-comput-er-iza-tion
- Xử lý từ ghép (compound word): ví dụ carry out, out of sight, out of mind
- Xử lý các trường hợp tỉnh lược (ellipsis): I’m, o’clock, Dr.
- Nhận diện tên riêng: John, Bush, IBM
- Nhân diện ranh giới từ (word boundary): tiếng Việt một từ có nhiều tiếng. Ví dụ: chúm chím, tuổi tác, hỏi han, tối om, giáo viên, hiện đại hóa, …
Parser (Phân tích ngữ pháp)
- Gán nhãn từ loại (Part Of Speech – POS tagging): một từ có nhiều từ loại (Danh từ, Động từ, Tính từ, …)
- Gán nhãn ranh giới ngữ: đâu là bắt đầu, kết thúc của các ngữ (phrase). Ví dụ ngữ danh từ, ngữ động từ, …
- Gán nhãn quan hệ ngữ pháp (grammatical relation)
- Gán nhãn cây cú pháp (parse tree)
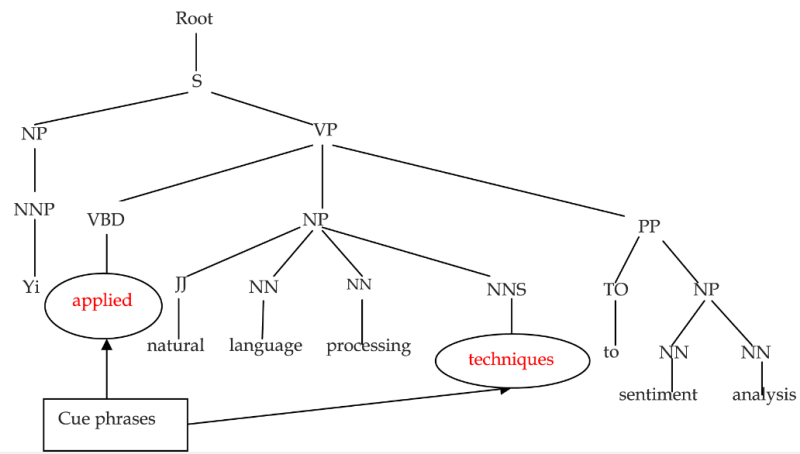 Parse tree
Parse tree
Anaphora – khử nhập nhằng thế đại từ. Ví dụ “The monkey ate the banana because it was hungry”. Đại từ “it” thay thế cho monkey hay banana.
Pragmatics – phân tích ngữ dụng: từ “sentence” trong phân tích văn phạm có nghĩa là câu, trong luật pháp có nghĩa là án tù. Do vậy, ta cần xem xét toàn bộ văn bản để đưa ra ý nghĩa chính xác.
 Đừng bỏ lỡ cơ hội gặp gỡ Microsoft tại sự kiện này! Đặt vé ngay!
Đừng bỏ lỡ cơ hội gặp gỡ Microsoft tại sự kiện này! Đặt vé ngay!
Corpus/Corpora – “ngữ liệu” là những “dữ liệu, cứ liệu của ngôn ngữ”, tức là những chứng cứ thực tế sử dụng ngôn ngữ, được dùng để kiểm chứng các quy luật của ngôn ngữ trong quá trình phân tích thông kê hay kiểm định giả thuyết thống kê của các mô hình dự đoán.
 Corpus
Corpus
Information Extraction – là tiến trình rút trích ra các thông tin có cấu trúc một cách tự động từ các nguồn dữ liệu không cấu trúc hay bán cấu trúc (unstructured/semi-structure) ví dụ như các tài liệu văn bản hay các trang web.
 Information Extraction
Information Extraction
Named Entity Recognition (NER) – là tiến trình xác định và phân loại các phần tử trong văn bản vào các danh mục được định nghĩa trước như tên người, tên tổ chức, địa điểm, giá trị tiền tệ, tỷ lệ phần trăm,…
 Named Entity Recognition
Named Entity Recognition
Sentiment Analysis -sử dụng các kĩ thuật NLP để rút trích thông tin chủ quan của người dùng từ một câu nói hay một văn bản. Đây cũng là kĩ thuật khai thác ý kiến người dùng xem họ đang có thái độ tích cực hay tiêu cực về sản phẩm của công ty.
 Sentiment Analysis
Sentiment Analysis
Bag of Words -mô hình thường dùng trong các tác vụ phân lớp văn bản (Text Classification). Thông tin sẽ được biểu diễn thành tập các từ đi kèm với tần xuất xuất hiện của mỗi từ này trong văn bản. Bag of Words được dùng như feature để huấn luyện cho classifier.
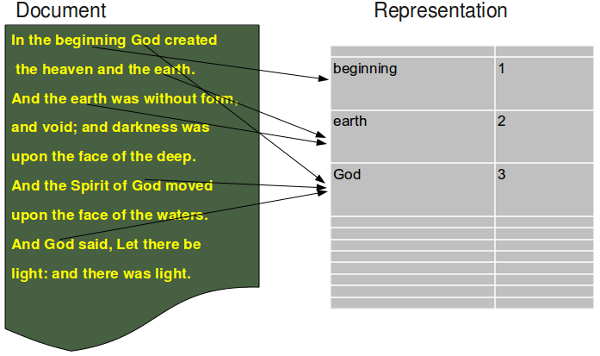 Bag of Words
Bag of Words
Explicit Semantic Analysis (ESA) -là tiến trình giúp máy hiểu được ý nghĩa của văn bản, được sử dụng trong Information Retrieval, Document Classification, Semantic Relatedness calculation (độ tương tự về ý nghĩa giữa các từ hay văn bản)
Latent Semantic Analysis (LSA) -tiến trình phân tích quan hệ giữa các văn bản và các từ. Đầu ra là mối liên quan giữa các khái niệm, văn bản, và các từ. LSA giả sử các từ gần nhau về mặt ý nghĩa sẽ xuất hiện trong các văn bản tương tự.
 Latent Semantic Analysis
Latent Semantic Analysis
Latent Dirichlet Allocation (LDA) – kĩ thuật Topic Modeling thường dùng, ý tưởng của LDA dựa trên nguyên lý mỗi topic là phân bố của các từ, mỗi văn bản là sự trộn lẫn giữa nhiều topic, và mỗi từ phân bố vào một trong những topic này.
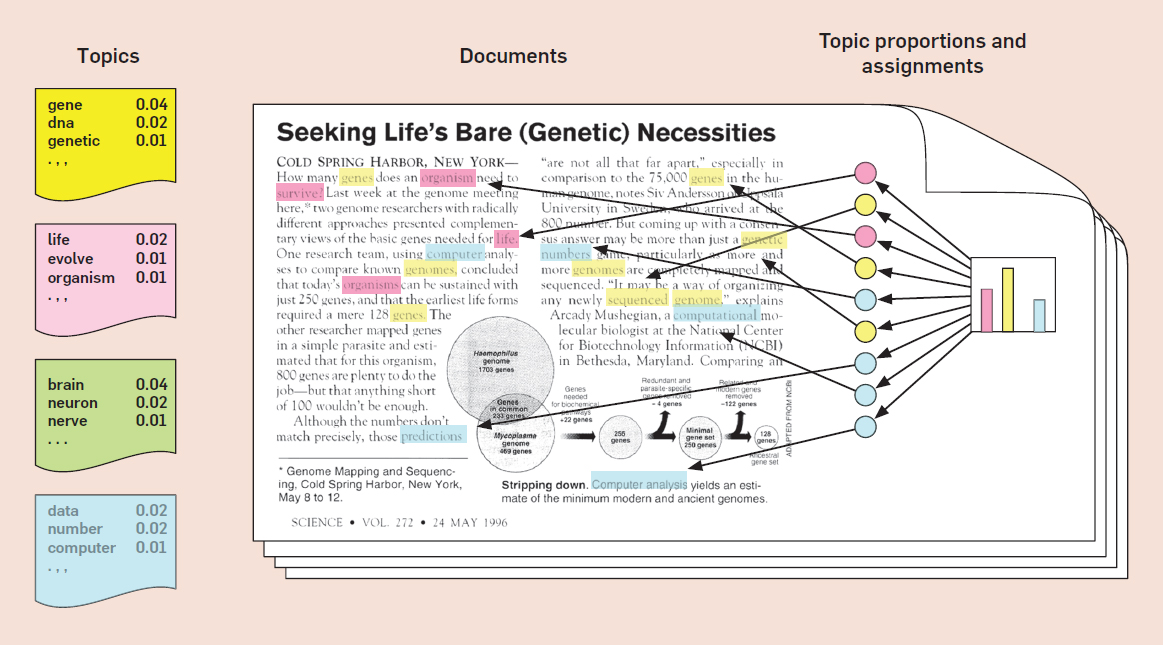 Latent Dirichlet Allocation
Latent Dirichlet Allocation
Tra cứu nhanh bảng thuật ngữ
| Thuật ngữ | Ý nghĩa |
|---|---|
| ambiguity | tính nhập nhằng |
| computer | ngành máy tính |
| linguistics | ngôn ngữ học |
| computational linguistics | ngôn ngữ học tính toán |
| applied linguistics | ngôn ngữ học ứng dụng |
| mathematical linguistics | ngôn ngữ học toán |
| acl – association for computational linguistics | hiệp hội ngôn ngữ học máy tính |
| spelling checker | kiểm lỗi chính tả |
| grammar checker | kiểm lỗi văn phạm |
| thesaurus | từ điển đồng nghĩa |
| text analyzer | phân tích văn bản |
| text classification | phân loại văn bản |
| text summarization | tóm tắt văn bản |
| voice synthesis | tổng hợp tiếng nói |
| automatic translation | dịch tự động |
| interlingual | liên ngôn ngữ nhằm biểu diễn chung cho tất cả các ngôn ngữ chính trên thế giới để tạo điều kiện thuận lợi trong việc trao đổi thông tin. |
| formal language | ngôn ngữ hình thức |
| formalization | hình thức hóa |
| machine readable dictionary | từ điển điện tử dành cho máy |
| corpus – linguistics | ngôn ngữ học ngữ liệu |
| corpus – based | dựa trên ngữ liệu |
| statistical linguistics | ngôn ngữ học thống kê |
| tagset | hệ thống nhãn |
| toolkit | các công cụ |
| pragmatic relation | quan hệ võ đoán (quan hệ mà không thể giải thích được lý do, quan hệ chỉ do quy ước,thói quen của cộng đồng) |
| phonetics | âm vị-đơn vị âm thanh nhỏ nhất để cấu tạo và khu biệt về mặt biểu hiện vật chất (âm thanh) của các đơn vị khác. Ví dụ: k-a-d(card);b-i-g(big) |
| morpheme | hình vị-đơn vị nhỏ nhất mang nghĩa (nghĩa ngữ pháp hay nghĩa từ vựng) được cấu tạo bởi các âm vị. Ví dụ: read-ing;book-s |
| word | từ–đơn vị mang nghĩa độc lập; được cấu tạo bởi (các) hình vị; có chức năng định danh. Ví dụ: I-am-reading-my–books. |
| phrase | ngữ-gồm hai hay nhiều từ có quan hệ ngữ pháp hay ngữ nghĩa với nhau. Vídụ: bức thư, mạng máy tính, computer system,… |
| sentence | câu-gồm các từ/ngữ có quan hệ ngữ pháp hay ngữ nghĩa với nhau và có chức năng cơ bản là thông báo. Ví dụ: I am reading my books. |
| text | văn bản-hệ thống các câu được liên kết với nhau về mặt hình thức, ngữ pháp, ngữ nghĩa và ngữ dụng. |
| hieararchical relation | quan hệ cấp bậc |
| syntagmatical relation | quan hệ ngữ đoạn |
| association relation | quan hệ liên tưởng |
| morphology | hình thái-mối quan hệ giữa đơn vị ngôn ngữ với hình thức cấu tạo của đơn vị đó |
| grammar | ngữ pháp-mối quan hệ giữa đơn vị ngôn ngữ này với các đơn vị ngôn ngữ hữu quan |
| semantic | ngữ nghĩa-mối quan hệ giữa đơn vị ngôn ngữ với nội dung (mặt ý nghĩa) của đơn vị đó. Xác định nghĩa của từng từ và tổ hợp của chúng để tạo nghĩa của câu. Thí dụ trong phân tích (Ônggià) (đi) (nhanhquá), động từ “đi” có thể có nghĩa “bước đi”, hay “chết” hay “điều khiển”(khi đánh cờ),…và tương ứng ta có các nghĩa khác nhau của câu. |
| pragmatic | ngữ dụng-mối quan hệ giữa đơn vị ngôn ngữ với mục đích sử dụng của đơn vị đó. Mối quan hệ giữa ngôn ngữ và ngữ cảnh sử dụng ngôn ngữ (contextofuse). Ngữ dụng như vậy nghiên cứu việc ngôn ngữ được dùng để nói về người và vật như thế nào. |
| flexional | ngôn ngữ hòa kết |
| agglutinate | ngôn ngữ chắp dính |
| isolate | ngôn ngữ đơn lập |
| polysynthetic | ngôn ngữ đa tổng hợp |
| classifier | từ chỉ loại-phó danh từ chỉ loại: cái bàn, cuốn sách, bức thư, con chó, con sông, vì sao,… |
| affix | phụ tố |
| comparative linguistics | ngôn ngữ học so sánh |
| lexicology | từ vựng học |
| etymology | từ nguyên học-nghiên cứu lịch sử của từ |
| encyclopedia | bách khoa toàn thư |
| denotative meaning | nghĩa biểu vật-liên hệ giữa từ và sự vật (hiện tượng, thuộc tính, hành động,…) |
| significative meaning | nghĩa biểu niệm-liên hệ giữa từ và ý (ý nghĩa, ý niệm, biểu niệm,…) |
| pragmatical meaning | nghĩa ngữ dụng-còn gọi là nghĩa biểu thái, nghĩa hàm chỉ (connotative meaning) là mối liên hệ giữa từ với thái độ chủ quan, cảm xúc của người nói. |
| structural meaning | nghĩa cấu trúc-là mối quan hệ giữa từ với các từ khác trong hệ thống từ vựng. Quan hệ giữa từ này với từ khác thể hiện trên hai trục: trục đối vị (paradigmatial axis) và trục ngữ đoạn (syntagmatical axis) |
| stem | thân từ-có thể bao gồm một hay nhiều hình vị gốc. Ví dụ: babysit |
| inflection | biến cách-là dạng mà trong đó có một hình vị ràng buộc kết hợp vào một từ để thể hiện những ý nghĩa ngữ pháp như: thì(tense),số (number), giống (gender), cách (case),… |
| derivation | dẫn xuất-là dạng từ mới được hình thành trên cơ sở từ gốc kết hợp với các phụ tố nhằm thể hiện những ý nghĩa từ vựng, như: lặp lại (re-), chống (anti-), người/vật thực hiện (-er/-or),… |
| double consonant | gấp đôi phụ âm |
| syntactic group | đoản ngữ-một nhóm những từ có liên hệ trực tiếp với nhau ở trong câu gọi là tổ hợp từ, và loại tổ hợp từ có quan hệ chính phụ được gọi là đoản ngữ. Đoản ngữ có vai trò quan trọng trong việc phân tích cú pháp và mô hình hóa câu để hiểu câu dễ dàng. |
| pos tagging | xác định loại từ-xem mỗi từ trong câu là loại gì (danh từ, động từ, giới từ,…) |
| chunking | xác định cụm từ-thí dụ “ông già” là cụm danh từ, “đi” là cụm động từ, “nhanh quá” là cụm trạng từ. Như vậy câu trên có hai phân tích (Ông già)(đi)(nhanh quá) hoặc (Ông)(già đi)(nhanh quá) |
| parsing | xác định quan hệ ngữ pháp-(Ông già)(đi)(nhanh quá) là quan hệ chủ ngữ-vị ngữ-trạng ngữ. |
| shallow parsing | phân tích sơ bộ |
| fully parsing | phân tích đầy đủ-phân tích cả tầng ngữ nghĩa |
| acoustic | âm học |
| text to speech | tổng hợp tiếng nói |
| alphabet set | bộ chữ-là bất kỳ một tập ký hiệu nào, tập này không nhất thiết phải hữu hạn hay đếm được (nhưng trên thực tế những tập này là hữu hạn) |
| string | chuỗi (sigma)-định nghĩa một cách hình thức những chuỗi trên một bộ chữ (alphabet) |
| language | ngôn ngữ-là một tập những chuỗi có chiều dài hữu hạn trên một bộ chữ hữu hạn (sigma) nào đó) |
| grammar | văn phạm |
| unrestricted grammar | văn phạm không hạn chế-được đoán nhận bằng một máy Turing. Đây là văn phạm loại 0 |
| context-sensitive grammar | văn phạm cảm ngữ cảnh-được đoán nhận bằng một máy Turing. Đây là văn phạm loại 1. |
| context-free grammar | văn phạm phi ngữ cảnh-sự áp dụng các luật sản sinh trong P thì hoàn toàn không bị điều kiện gì về ngữ cảnh ràng buộc. Được đoán nhận bằng PDA-push down acceptor. |
| derivation sequence | dãy suy dẫn |
| derivation tree | cây suy dẫn |
| categorized grammar | văn phạm mục |
| Chomsky normal form | dạng chính tắc |
| pharagraph segmentation | tách đoạn-tách văn bản thành các đoạn và xem đoạn văn là một khối liên tục các câu. |
| token | một dãy tuần tự các ký tự trong bảng chữ cái, hoặc dãy tuần tự các con số (một chữ số có chứa dấu chấm là dấu chấm thập phân được xem như là một token), hoặc một ký tự không nằm trong bảng chữ cái (như dấu chấm câu, dấu ngoặc kép, các ký tự mở rộng,…) |
| sigmoid | hàm “nén” |
| back propagation | lan truyền ngược |
| ellipsis | tỉnh lược-ví dụ: I’m, o’clock, Dr. |
| TBL-Transformation Based Learning | giải thuật học cải biến |
| Stochastic transduction | chuyển dịch trạng thái có xác suất |
| acceptor | máy đoán nhận |
| transducer | chuyển dịch |
| parser | phân tích ngữ pháp bao gồm phân tích từ pháp (ngữ pháp của từ-POS tagger) và phân tích cú pháp (ngữ pháp của câu), bước trung gian là phân đoạn ngữ (phrase–chunker) |
| transformation rules | luật cải biến |
| wordnet | cơ sở tri thức khổng lồ về ngữ nghĩa của từ vựng theo hướng liệt kê nét nghĩa |
| LDOCE-Longman Dictionary Of Contemporary | hệ thống nhãn ngữ nghĩa LDOCE English |
| polysemy | từ đa nghĩa |
| hamonymy | từ đồng nghĩa |
| contrastive | nghĩa không liên quan với nhau |
| complementary | nghĩa có liên quan một cách hệ thống với nhau |
| homograph | nghĩa của từ đồng tự |
| primitives | sơ cấp |
| selectional restriction | ràng buộc ngữ nghĩa |
| content words | từ thực |
| ontology | hệ thống nhãn ngữ nghĩa, bản thể học để phân loại tri thức |
| collocation | ngôn từ-xét đến hình thái và ngữ nghĩa của các từ lân cận. Chẳng hạn khi thấy “bank…river” -> “bờ sông”, “bank…account/money”-> “ngân hàng” |
| anaphora | thế đại từ |
| granularity | độ mịn |
| syntactic tree transfer | chuyển đổi cây cú pháp |
| Pp-attachment | khử nhập nhằng ngữ giới từ |
| entry | mục từ trong từ điển |
| idiom | thành ngữ |
| subcategory | tiểu từ loại như danh từ thuộc loại con nào (danh từ đếm được, không đếm được,…), động từ loại con nào (tha động từ, tự động từ,…) |
| case role | ngữ pháp cách: agent (human), instrument (object) |
| categories | danh từ chỉ loài |
| subcategories | chủng loại |
| modality | tình thái: từ này dùng trong cảnh huống nào: trịnh trọng, thân mật, thông tục,… |
| interlingual MT | dịch qua ngôn ngữ trung gian |
| demo | biểu diễn |
| concordance | từ đồng hiện |
| phoneme synthesis | tổng hợp âm vị |
| punctuation | ngừng nghỉ |
| intonation | ngữ điệu lên xuống |
| alignment | liên kết với nhau trong ngữ liệu song song |
| category | chủng loại như thông tin về số (ít/nhiều), về thời, đếm được. |
| tags | Nhãn |
| empiricism | chủ nghĩa kinh nghiệm |
| rationalism | chủ nghĩa lý luận |
| data driven | dữ liệu thực tiễn |
| theory driven | mô hình lý thuyết |
| deductive | nghiên cứu theo phương pháp xác suất thống kê |
| inductive | nghiên cứu theo phương pháp luật suy diễn |
| children language acquisition | nhận biết ngôn ngữ của trẻ |
| language performance | sự thực hiện ngôn ngữ |
| Language competence | năng lực ngôn ngữ |
| parole | lời nói |
| rationalism | nghiên cứu dựa theo lý luận |
| bilingual parallel corpora | ngữ liệu song ngữ |
| parallel corpora | ngữ liệu song song |
| estimation maximization | ước lượng cực đại |
| marginal phenomena | những trường hợp ngoại lệ mà không tuân theo luật chính |
| flip flop | là hiện tượng mà khi hệ thống có một sự thay đổi nào đó để khắc phục một lỗi sai này, nhưng hệ thống sẽ dẫn đễn lỗi sai khác mà ta không ngờ tới) |
| post edit | hiệu đính |
| fertility | giá trị sản sinh |
| greedy decoding | tìm kiếm tham lam |
| baseline | gán nhãn sơ khởi |
| template | khung luật định sẵn |
| pipeline style | công việc thực hiện nối tiếp nhau |
| concept | thực thể cùng loại |
| instance-based learning | học dựa trên trường hợp (similarity, example, memory-based) |
| fitness | hàm đánh giá |
| ensembles of classifier | tập hợp phân lớp |
Người viết Ông Xuân Hồng
