Decision Tree Learning
Decision tree learning is a method for finding a approximate solution using training data, in which the learned function is represented by a decision tree. In other words, Its a hierarchical data structure implemention of the divide-and-conquer strategy. It can be used for both classification, ...
 Decision tree learning is a method for finding a approximate solution using training data, in which the learned function is represented by a decision tree. In other words, Its a hierarchical data structure implemention of the divide-and-conquer strategy. It can be used for both classification, clusterization and regression. Learned trees can also be re-represented as sets of some if-then rules to improve easy readability. Its very popular and successfully applied to a broad range of tasks from learning to diagnose medical cases to learning to assess credit risk of loan applicants.
Decision tree learning is a method for finding a approximate solution using training data, in which the learned function is represented by a decision tree. In other words, Its a hierarchical data structure implemention of the divide-and-conquer strategy. It can be used for both classification, clusterization and regression. Learned trees can also be re-represented as sets of some if-then rules to improve easy readability. Its very popular and successfully applied to a broad range of tasks from learning to diagnose medical cases to learning to assess credit risk of loan applicants.
When I was a student, I got a chance to work with C4.5 algorithm for my thesis. C4.5 is the extended version of ID3 algorithm, which is considered as the basic standard algorithm for Decision tree learning. In this post I'll try to describe a little bit about the Decision tree learning mechanism.
Decision Tree Representation
Decision trees classify the data by sorting them into the tree, starting from the root to some leaf node, which provides the classification of the instance. Each node in the tree specifies a test of some attribute of the instance. An instance is classified by starting at the root node of the tree, testing the attribute specified by this node, then moving down the tree branch corresponding to the value of the attribute in the given example. This process is then repeated for the subtree rooted at the new node.
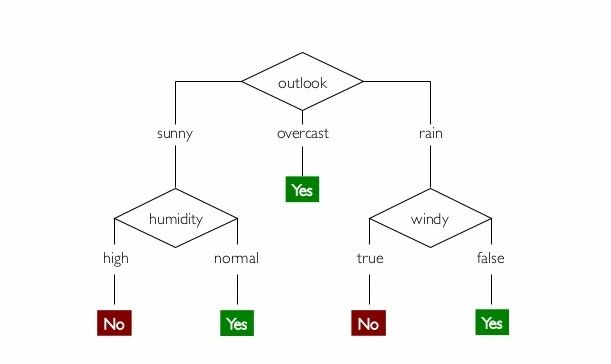 Lets explain it with the famous weather data set. This is a typical learned decision tree. This simple decision tree will help us to decide weather the day is suitable for a playing tennis or not. For example,
(Outlook = Sunny, Temperature = Hot, Humidity = High, Wind = Strong)
Lets explain it with the famous weather data set. This is a typical learned decision tree. This simple decision tree will help us to decide weather the day is suitable for a playing tennis or not. For example,
(Outlook = Sunny, Temperature = Hot, Humidity = High, Wind = Strong)
It would be sorted down to the leftmost branch of this decision tree and would therefore be classified as a negative instance result.
APPROPRIATE PROBLEMS FOR DECISION TREE LEARNING
-
Instances are represented by attribute-value pairs. Instances are described by a fixed set of attributes (e.g., Temperature) and their values (e.g., Hot).
-
The target function has discrete output values. The decision tree in our example assigns a boolean classification (e.g., yes or no) to each example.
-
Disjunctive descriptions may be required. As mentioned, decision trees naturally represent disjunctive expressions.
-
The training data may contain errors. Decision tree learning methods are robust to errors, both errors in classifications of the training examples and errors in the attribute values that describe these examples.
-
The training data may contain missing attribute values. Decision tree methods can be used even when some training examples have unknown values.
THE BASIC DECISION TREE LEARNING ALGORITHM
Most algorithms that have been developed for learning decision trees are variations on core algorithm that employs a top-down, greedy search of possible decision trees.
Our basic algorithm, ID3, learns decision trees by constructing them in a top-down appraoch. It begin with the question "which attribute should be tested at the root of the tree?'
To answer this question, each instance attribute is evaluated using a statistical test to determine how well it can classifies the training examples. The best attribute is selected and used as the test at the root node of the tree. A descendant of the root node is then created for each possible value of this attribute, and the training examples are sorted to the appropriate descendant node. The entire process is then repeated using the training examples associated with each descendant node to select the best attribute to test at that point in the tree. This forms a greedy search for an acceptable decision tree, in which the algorithm never backtracks to reconsider earlier choices.
ENTROPY MEASUREMENT
In order to define information gain precisely, we begin by defining a measurement. its commonly used in information theory, called entropy. It characterizes the purity of an arbitrary collection of examples. Given a collection S, containing positive and negative examples of some target concept, the entropy of S relative to this boolean classification is,
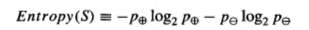
ID3 Algorithm
In short:
- Calculate the entropy of every attribute using the data set
- Split the set into subsets using the attribute for which the resulting entropy (after splitting) is minimum
- Make a decision tree node containing that attribute
- Recursively go through subsets using remaining attributes.
Algorithm:
ID3 (Examples, Target_Attribute, Attributes)
Create a root node for the tree
If all examples are positive, Return the single-node tree Root, with label = +.
If all examples are negative, Return the single-node tree Root, with label = -.
If number of predicting attributes is empty, then Return the single node tree Root,
with label = most common value of the target attribute in the examples.
Otherwise Begin
A ← The Attribute that best classifies examples.
Decision Tree attribute for Root = A.
For each possible value, vi, of A,
Add a new tree branch below Root, corresponding to the test A = vi.
Let Examples(vi) be the subset of examples that have the value vi for A
If Examples(vi) is empty
Then below this new branch add a leaf node with label = most common target value in the examples
Else below this new branch add the subtree ID3 (Examples(vi), Target_Attribute, Attributes – {A})
End
Return Root
ID3 is a greedy algorithm that grows the tree top to bottom. At each node it select the attribute that gives best classifies result from the local training examples. This process continues until the tree perfectly classifies the training examples, or until all attributes have been used.
In the next post we will dive more deep and we will see the implementation of C4.5 algorithm for clusterization and classification.
References:
https://www.amazon.com/Machine-Learning-Tom-M-Mitchell/dp/0070428077/ https://www.amazon.com/Introduction-Machine-Learning-Adaptive-Computation/dp/026201243X http://whatis.techtarget.com/definition/machine-learning
