Discord đã lưu trữ hàng tỉ messages mỗi ngày như thế nào?
Người viết: Ngo Thang (@tango) Mình biết đến Discord cách đây khoảng 2 năm, tại thời điểm mà giá bitcoin tăng khủng khiếp ấy. Khi đó không biết mọc ở đâu lắm thầy phán bitcoin quá, kéo theo cùng các group cho kèo (thu phí) trên Discord cũng dần dần mọc ra từ đó. Không chỉ các ...

Người viết: Ngo Thang (@tango)
Mình biết đến Discord cách đây khoảng 2 năm, tại thời điểm mà giá bitcoin tăng khủng khiếp ấy.
Khi đó không biết mọc ở đâu lắm thầy phán bitcoin quá, kéo theo cùng các group cho kèo (thu phí) trên Discord cũng dần dần mọc ra từ đó. Không chỉ các anh tây lông mà ngay cả Việt Nam mình cũng rất nhiều.
Mà thôi đi vào vấn đề chính đã.
Về số lượng messages trên Discord theo thống kê như sau: vào tháng 7 năm 2017, số lượng messages 1 ngày là 40 triệu. Nhưng đến tháng 12 thì đã đạt 120 triệu messages 1 ngày. Sự tăng trưởng khá là nhanh chỉ trong vòng 5 tháng. Và đến bây giờ chắc phải hơn 1 tỉ messages 1 ngày.
Vậy cùng nhau đi tìm hiểu xem họ đã lưu đống messages khổng lồ đó như thế nào nhé.
Bối cảnh
Discord là 1 ứng dụng chat. Nó giống như slack ấy. Cũng tạo được team, group riêng. Phân quyền người dùng, gọi điện, gửi tin nhắn, cung cấp API đủ cả.
Discord được ra đời đầu tiên vào năm 2015, và họ chỉ code trong vòng đúng 2 tháng (2 tháng code xong cũng thấy pro thật). Khi đó họ sử dụng MongoDB để lưu trữ dữ liệu.
Tại thời điểm này họ chỉ lưu dữ liệu trên 1 replica MongoDB duy nhất thôi, và không muốn sử dụng sharding trong MongoDB vì nó quá phức tạp, 1 phần vì bản thân Discord cũng không chắc chắn về mức độ ổn định của nó.
Còn 1 điều mình thấy khá thú vị về Discord đó là về văn hoá công ty:
Làm thế nào thì làm nhưng service phải được build thật nhanh để tung ra thị trường, xem phản ứng của người dùng. Tuy nhiên cũng cần phải có 1 đường lui đến 1 solution mạnh mẽ hơn.
Công ty mình cũng đang đi theo hướng này. Cũng build thật nhanh, và luôn luôn có giải pháp công nghệ tốt hơn khi đối mặt với big data.
Về messages được lưu trong collection của MongoDB với bộ index là channel_id và created_at.
Giai đoạn đầu với dữ liệu còn nhỏ, MongoDB chạy khá là mượt mà. Tuy nhiên, vào đầu tháng 12 khi dữ liệu messages đạt đến 120 triệu messages trên 1 ngày thì đã xảy ra 1 số vấn đề như sau:
- data và index không thể fit đầy vào RAM (dữ liệu to thế mà chỉ dùng 1 node thì khó có thể fit đầy RAM được)
- Thời gian latency bắt đầu kéo dài ra.
Đã đến lúc cần phải chuyển sang 1 database mới phù hợp hơn với logic hiện tại.
Vấn đề đang gặp phải
- Phần voice chat làm server chịu tải khá lớn, đến nỗi không thể gửi được message. số lượng message loại này chỉ tầm khoảng 1k messages mỗi năm. Khá là ít.
- Phần private message (trong group private) cũng làm khá nặng server. Loại messages này mỗi năm đạt từ 100k đến 1 triệu messages. Các group private này có số lượng member không nhiều, chỉ tầm 100 member thôi.
- Các message trong public group thì được gửi khá là nhiều. Các public group này có số lượng thành viên lớn hơn, tầm khoảng 1000 người. Tổng messages trong 1 năm khoảng 1 triệu và gửi thường xuyên hơn.
Yêu cầu về mặt hệ thống
Khi chọn database mới thì cần phải đáp ứng được những yêu cầu sau:
- Khả năng mở rộng
- Chịu lỗi tốt
- Không mất nhiều công trong quá trình bảo trì
- Đã có nhiều công ty lớn dùng
- Có thể dự đoán được hiệu năng.
- Không muốn cache message trong Redis hay Memcached.
- Open source (muốn tự mình control được hệ thống mà không phải phụ thuộc vào bên thứ 3)
Từ những yêu cầu trên thì chỉ có Cassandra là phù hợp nhất.
Cassandra có thể dễ dàng thêm, xoá node để tăng hiệu năng. Và các node đồng bộ dữ liệu với nhau thông qua cơ chế P2P (peer to peer) nên khi 1 node có bị chết đi chăng nữa thì các node khác vẫn chứa dữ liệu nên độ chịu lỗi khá cao.
Ngoài ra còn có các công ty lớn đang dùng như Netflix, Apple, Facebook, Twitter với hàng nghìn node nên có thể tự tin về hiệu năng của nó.
Nếu bạn nào chưa biết về Cassandra thì có thể tham khảo tại đây.
Data Modeling
Cơ chế tổ chức data trong Cassandra như sau:
- Được tổ chức dưới dạng KKV (key key value) store.
- Trong đó, tổ hợp của 2 chữ K này là khoá chính:
- Chữ K đầu tiên là partition key.
- Partition gồm nhiều row, mỗi row được định danh bởi K thứ 2 (được gọi là cluster key). Cluster key này cũng đóng vai trò là khoá chính trong partition.
Message được index trong MongoDB sử dụng channel_id và created_at. Trong đó channel_id là partition key bởi vì tất quả query đều thao tác trong channel. Nhưng mà created_at không thể là cluster key được vì có thể 2 message đều được tạo ra cùng thời điểm.
Nhưng thật may mỗi ID trong Discord luôn luôn duy nhất (vì sử dụng cơ chế Snowflake của twitter). Khi đó khoá chính sẽ trở thành (channel_id, message_id). Trong đó message_id chính là snowflake.
Điều đó giúp ta dễ dàng lấy được message dựa vào channel_id.
Khi đó cấu trúc bảng messages sẽ như sau:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE messages ( channel_id bigint, message_id bigint, author_id bigint, content text, PRIMARY KEY (channel_id, message_id) ) WITH CLUSTERING ORDER BY (message_id DESC); |
Khi import data from MongoDB sang Cassandra thì gặp phải 1 vấn đề sau. Đó là xuất hiện cảnh báo kích thước partition đã vượt quá 100MB. (Có lẽ dữ liệu trong 1 partition có kích thước lớn không được phân tán sang các cluster bên cạnh nên bị cảnh báo này chăng?)
Do đó mà cần chia nhỏ dữ liệu ra để fit vừa 100MB. Họ kiểm tra 1 channel to nhất Discord thấy messages trong 10 ngày sẽ có kích thước tầm 100MB. Do đó quyết định cho messages vào từng bucket với khoảng thời gian là 10 ngày.
Cụ thể như sau:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DISCORD_EPOCH = 1420070400000 // thời điểm lúc 12:00 1/1/2015 BUCKET_SIZE = 1000 * 60 * 60 * 24 * 10 // tin nhắn trong 10 ngày def make_bucket(snowflake): if snowflake is None: timestamp = int(time.time() * 1000) - DISCORD_EPOCH else: # When a Snowflake is created it contains the number of # seconds since the DISCORD_EPOCH. timestamp = snowflake_id >> 22 return int(timestamp / BUCKET_SIZE) def make_buckets(start_id, end_id=None): return range(make_bucket(start_id), make_bucket(end_id) + 1) |
Khi đó primary key sẽ trở thành: ((channel_id, bucket), message_id)
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE messages ( channel_id bigint, bucket int, message_id bigint, author_id bigint, content text, PRIMARY KEY ((channel_id, bucket), message_id) ) WITH CLUSTERING ORDER BY (message_id DESC); |
Để query lấy messages gần đây thì chỉ cần tạo ra 1 bucket từ current_time cho đến channel_id (vì channel_id được tạo ra bởi Snowflake, mà channel thường được tạo trước sau đó mới đến message nên có thể coi channel_id như message đầu tiên).
Và chúng ta sẽ query tuần tự trong partition để lấy đủ message thì thôi.
Hiệu năng
Quả đúng như đồn đại, tốc độ write luôn luôn nhanh hơn tốc độ read. Write mất khoảng 0.5ms trong khi read mất tầm khoảng 5ms. Mặc dù read chậm hơn thật nhưng mà chỉ mất đến milisecond thì vẫn nhanh chán.
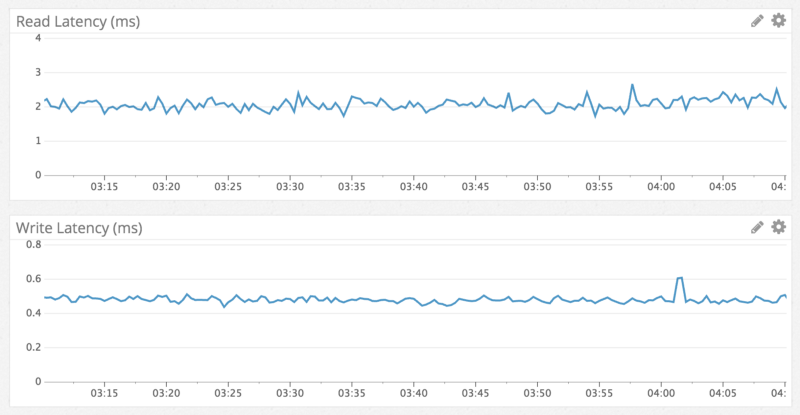
Tại sao write lại luôn nhanh hơn read?
Write nhanh hơn read vì nó không liên quan quá nhiều đến I/O. Nó chỉ cần ghi vào trong commit log và memtable là xong. Và khi memtable bị full sẽ bị đẩy xuống disk.
Khi read thì có thể nó sẽ phải lấy dữ liệu trong disk nên tốc độ đương nhiên là chậm hơn rồi.
Nếu mà data vẫn ở trong memtable thì chắc chắn tốc độ sẽ ngang ngửa read. Do cái này là trung bình của tất cả các trường hợp nên sẽ cho ra kết quả write luôn nhanh hơn read.
Đây là kết quả khi muốn xem 1 tin nhắn cách đây 1 năm.

Kết quả bên trên được test ở trong 1 channel to nhất Discord (có trên 1k thành viên). Tốc độ quả rất là nhanh.
1 điều ngạc nhiên đã xảy ra
Cassandra hoạt động khá suôn sẻ suốt 6 tháng và đến 1 ngày có 1 việc xảy ra. Họ phát hiện ra 1 kênh mất tầm 20s để load dữ liệu. Tại sao lại load lâu như vậy?
Khi vào kiểm tra thấy kênh này chỉ còn duy nhất 1 tin nhắn. Kiểm tra thấy admin của channel này đã dùng api discord để xoá hàng triệu messages đi.
Như chúng ta đã biết, việc xoá dữ liệu trong Cassandra sẽ không như trong Mysql. Là nó sẽ không xoá ngay. Mà nó sẽ gắn 1 cái cờ gọi là tombstones đến dữ liệu muốn xoá. Khi query để lấy dữ liệu, nó sẽ check xem dữ liệu có gắn cờ này không và trả về dữ liệu.
Do đó mặc dù channel chỉ có 1 message duy nhất mà phải mất đến 20s để load. Quá là lâu.
Và họ đã giải quyết bằng cách:
- Giảm lifespan của tombstones từ 10 ngày xuống còn 2 ngày. Vì họ thực hiện chạy Cassandra repairs vào mỗi buổi tối để dọn dẹp dữ liệu, tăng tính nhất quán của hệ thống.
Kết luận
Qua bài này chắc các bạn cũng biết được Cassandra nó được sử dụng trong các hệ thống big data như thế nào.
Về Cassandra mình thích nhất là tính dễ mở rộng (càng thêm node thì hiệu năng càng cao) và mức độ chịu lỗi thấp của nó.
Nên nếu bạn nào đang có ý định đưa Cassandra vào hệ thống thì mình thấy có thể sẽ là 1 sự lựa chọn đúng đắn.
Có thể bạn quan tâm:
- MySQL ngoại truyện
- Sql là gì? 6 lý do tại sao bạn nên học SQL
- Tối ưu hoá MySQL sử dụng việc gộp các index
Xem thêm việc làm Software Developers hấp dẫn trên TopDev
TopDev via Nghệ thuật Coding

