Feature Engineering (Phần 5): Phương pháp nâng cao để xử lý dữ liệu dạng văn bản, phi cấu trúc (1/2)
Xin chào mọi người, trong phần trước của series mình đã giới thiệu với mọi người một số phương pháp xử lý truyền thống với dạng dữ liệu văn bản (Text Data). Trong phần tiếp theo này chúng ta sẽ tiếp tục với series Understanding Feature Engineering của Dipanjan (DJ) Sarkar để tìm hiểu về các phương ...
Xin chào mọi người, trong phần trước của series mình đã giới thiệu với mọi người một số phương pháp xử lý truyền thống với dạng dữ liệu văn bản (Text Data). Trong phần tiếp theo này chúng ta sẽ tiếp tục với series Understanding Feature Engineering của Dipanjan (DJ) Sarkar để tìm hiểu về các phương pháp nâng cao hơn để xử lý dữ liệu văn bản, phi cấu trúc và tìm hiểu cụ thể mô hình CBOW để trích xuất thông tin từ dữ liệu dạng
Giới thiệu
Làm việc với dữ liệu văn bản phi cấu trúc là rất khó, đặc biệt khi bạn mong muốn xây dựng một hệ thống thật sự thông minh và hiểu được ngôn ngữ tự nhiên giống như con người. Vậy nên bạn cần sử dụng các phương pháp xử lý, biến đổi dữ liệu không có cấu trúc thành một số dạng có cấu trúc để làm việc với các thuật toán học máy. Các phương pháp xử lý ngôn ngữ tự nhiên, deep learning hay machine learning đều là những lĩnh vực nhỏ của trí tuệ nhân tạo và là những công cụ hiệu quả trong thương mại nói riêng và trong cuộc sống nói chung. Với những phần trước của series này, một điểm quan trọng chúng ta cần ghi nhớ là bất kỳ thuật toán học máy nào đều dựa trên các nguyên tắc thống kê, hàm số toán học và tối ưu hóa. Do đó các thuật toán học máy không đủ thông minh để xử lý dữ liệu văn bản ở dạng nguyên thủy. Chúng ta đã đề cập đến một số phương pháp truyền thống để trích xuất đặc trưng có ý nghĩa từ dữ liệu văn bản trong phần trước của series. Trong bài viết này, chúng ta sẽ xem xét các phương pháp trích xuất đặc trưng tiên tiến hơn, thường là sử dụng các mô hình deep learning. Cụ thể hơn chúng ta sẽ đề cập đến Word2Vec, GloVe và FastText
Sự cần thiết
Chúng ta đã thảo luận và nhấn mạnh rất nhiều lần rằng các kỹ thuật trích xuất đặc trưng chính là vũ khí tối quan trọng để tạo ra các mô hình học máy hiệu quả và tốt hơn. Bạn cần luôn nhớ rằng, ngay cả với sự ra đời của các kỹ thuật trích xuất đặc trưng tự động bạn vẫn sẽ cần hiểu được các khái niệm cốt lõi đằng sau việc áp dụng các kỹ thuật đó. Nếu không, chúng sẽ chỉ là những mô hình black box mà bạn không thể biết được cách tùy biến, điều chỉnh để phù hợp với bài toán đang cần giải quyết.
Những thiếu sót của các phương pháp xử lý truyền thống
Các phương pháp trích xuất đặc trưng truyền thống (dựa trên số lượng) cho dữ liệu văn bản liên quan đến họ phương pháp rất phổ biến là Bag of Words hay bao gồm cả tần số như TF-IDF, N-gram... Mặc dù chúng đều là các phương pháp hiệu quả để trích xuất đặc trưng từ văn bản, nhưng do bản chất vốn có của các mô hình đó chỉ là xét trên các từ không có cấu trúc, như vậy chúng ta sẽ mất các thông tin bổ sung như ngữ nghĩa, cấu trúc, trình tự và ngữ cảnh xung quanh các từ gần đó mỗi tài liệu văn bản. Điều này chính là động lực để chúng ta khám phá các mô hình phức tạp hơn, các mô hình có thể trích xuất được các thông tin sâu hơn có thể bao quát được cho cả các từ, thường được gọi là word embeddings.
Sự cần thiết của Word Embeddings
Đối với các hệ thống nhận dạng giọng nói hoặc hình ảnh, tất cả các thông tin đã có ở dạng vectơ đặc trưng như phổ âm thanh hoặc cường độ màu, độ tương phản của các pixcel. Tuy nhiên, khi nói đến dữ liệu văn bản thô, đặc biệt là các mô hình dựa trên đếm từ như Bag of Words chúng ta đều xử lý các từ riêng lẻ, có thể chúng có ý nghĩa nhất định nhưng không thể nắm bắt được mối quan hệ giữa các từ đó. Điều này dẫn đến các vectơ thu được chỉ là các vectơ riêng biệt của văn bản, vậy nên nếu không có đủ dữ liệu thì cuối cùng chúng ta chỉ có thể thu được mô hình kém hoặc bị overfiting bởi curse of dimensionality
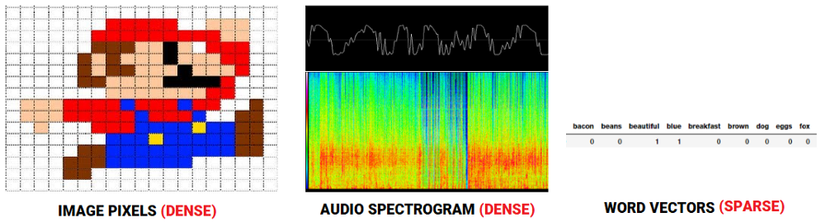
Để khắc phục những thiếu sót của việc mất đi ngữ nghĩa trong việc sử dụng kỹ thuật trích xuất đặc trưng dựa trên đếm từ, chúng ta cần sử dụng Vector Space Models (VSMs) theo cách mà chúng ta có thể "nhúng" các vectơ từ trong không gian vectơ liên tục dựa trên sự tương đồng về mặt ngữ nghĩa, ngữ cảnh. Trong thực tế, phân phối giả thuyết trong ngôn ngữ học (distributional hypothesis) cho chúng ta biết rằng các từ xuất hiện và được sử dụng trong cùng một ngữ cảnh, giống nhau về mặt ngữ nghĩa và có nghĩa tương tự. Nói một cách đơn giản "ngữ nghĩa của một từ được tạo nên bởi ngữ cảnh xung quanh nó". Các bạn có thể tham khảo bài báo Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vector của Baroni et al để tìm hiểu cụ thể hơn về vectơ hóa từ trong ngữ cảnh. Chúng ta sẽ không đi sâu vào vấn đề này, nhưng cơ bản, có hai loại phương pháp chính cho việc vectơ hóa các từ trong ngữ cảnh.
- Phương pháp dựa trên đếm số lượng (Count-based methods) như Latent Semantic Analysis (LSA) có thể được sử dụng để tính toán, thống kê tần suất các từ xuất hiện với các từ lân cận của chúng trong một đoạn văn bản.
- Phương pháp dự đoán (Predictive methods) như Neural Network based language models sẽ cố gắng dự đoán các từ từ các từ lân cận của nó trong khi trainning các chuỗi từ/câu từ tập dữ liệu cho trước. Trong bài viết này chúng ta sẽ tập trung vào phương pháp này.
Các phương pháp trích xuất đặc trưng
Bây giờ chúng ta bắt đầu xemxets một số phương pháp nâng cao để xử lý dữ liệu văn bản và trích xuất các đặc trưng bao gồm ngữ nghĩa để có thể sử dụng trong các thuật toán học máy. Các bạn có thể truy cập toàn bộ source code từ github của tác giả. Đầu tiên chúng ta hãy cùng làm một vài bước chuẩn bị.
import pandas as pd import numpy as np import re import nltk import matplotlib.pyplot as plt pd.options.display.max_colawidth = 200 %matplotlib inline
Tiếp theo chúng ta tải lên một vài đoạn văn bản sẽ sử dụng trong bài viết này. Chúng ta sẽ sử dụng lại tập dữ liệu tương tự ở phần trước của series này.

Dữ liệu thử nghiệm của chúng ta là một số đoạn văn bản thuộc các chủ đề khác nhau. Ngoài ra có một tập dữ liệu khác mà chúng ta sẽ sử dụng trong vài viết này là "The King James Version of the Bible" có sẵn tại "Project Gutenberg" thông qua module corpus trong nltk. Chúng ta sẽ đề cập đến tập dữ liệu này trong phần sau của bài viết. Và trước khi thực hiện các bước kỹ thuật trích xuất đặc trưng, chúng ta cần các bước tiền xử lý và chuẩn hóa văn bản này.
Tiền xử lý dữ liệu dạng văn bản
Có rất nhiều cách để tiền xử lý và làm sạch dữ liệu dạng văn bản. Các kỹ thuật quan trọng nhất đã được giới thiệu chi tiết trong phần trước của series này. Vì trọng tâm của phần này là về các phương pháp trích xuất đặc trưng nên giống như phần trước, chúng ta sẽ sử dụng lại toàn bộ các bước xử lý văn bản và tập trung vào việc loại bỏ các ký tự đặc biệt, khoảng trắng, chữ số, stopwords...
wpt = nltk.WordPunctTokenizer() stop_words = nltk.corpus.stopwords.words('english') def normalize_document(doc): # lower case and remove special characterswhitespaces doc = re.sub(r'[^a-zA-Zs]', ', doc, re.I|re.A) doc = doc.lower() doc = doc.strip() # tokenize document tokens = wpt.tokenize(doc) # filter stopwords out of document filtered_tokens = [token for token in tokens if token not in stop_words] # re-create document from filtered tokens doc = ' '.join(filtered_tokens) return doc normalize_corpus = np.vectorize(normalize_document)
Sau khi có được method tiền xử lý cơ bản, các bạn hãy áp dụng chúng để xử lý tập dữ liệu.
norm_corpus = normalize_corpus(corpus) norm_corpus Output ------ array(['sky blue beautiful', 'love blue beautiful sky', 'quick brown fox jumps lazy dog', 'kings breakfast sausages ham bacon eggs toast beans', 'love green eggs ham sausages bacon', 'brown fox quick blue dog lazy', 'sky blue sky beautiful today', 'dog lazy brown fox quick'], dtype='<U51')
Bây giờ, hãy suwr dunjg nltk để sử dụng tập dữ liệu "The King James Version of the Bible " và áp dụng tiền xử lý.
from nltk.corpus import gutenberg from string import punctuation bible = gutenberg.sents('bible-kjv.txt') remove_terms = punctuation + '0123456789' norm_bible = [[word.lower() for word in sent if word not in remove_terms] for sent in bible] norm_bible = [' '.join(tok_sent) for tok_sent in norm_bible] norm_bible = filter(None, normalize_corpus(norm_bible)) norm_bible = [tok_sent for tok_sent in norm_bible if len(tok_sent.split()) > 2] print('Total lines:', len(bible)) print(' Sample line:', bible[10]) print(' Processed line:', norm_bible[10])
Output ------ Total lines: 30103 Sample line: ['1', ':', '6', 'And', 'God', 'said', ',', 'Let', 'there', 'be', 'a', 'firmament', 'in', 'the', 'midst', 'of', 'the', 'waters', ',', 'and', 'let', 'it', 'divide', 'the', 'waters', 'from', 'the', 'waters', '.'] Processed line: god said let firmament midst waters let divide waters waters
Từ output các bạn có thể thấy được tổng số dòng của văn bản và kết quả của các bước tiền xử lý. Và tiếp theo chúng ta sẽ đến với phần chính: chích xuất đặc trưng từ những văn bản trên!
Mô hình Word2Vec
Mô hình này được Google rạo ra vào năm 2013 và là mô hình sử dụng deep learning để tính toán và tạo ra các vectơ biểu diễn các từ và bao gồm được cả các tương đồng về ngữ cảnh và ngữ nghĩa của từ đó. Về cơ bản, đây là mô hình học không giám sát, có thể áp dụng được cho những tập văn bản lớn, tạo ra vốn từ vựng và tạo ra embedding trong không gian vecto cho mỗi từ vựng đó. Thông thường bạn có thể chỉ định kích thước của vectơ embeddings và tổng số vectơ thường là kích thước của không gian từ vựng. Điều này làm cho số chiều của không gian vectơ này thấp hơn rất nhiều so với không gian vectơ được tạo ra bởi mô hình Bag of Words truyền thống. Có hai kiến trúc khác nhau có thể sử dụng để tạo ra các vectơ embedding này bao gồm:
- Mô hình Continuous Bag of Words (CBOW)
- Mô hình Skip-gram
Các mô hình này ban đầu được giới thiểu Mikolov et al. Các bạn nên đọc lại các bài báo gốc xung quanh các mô hình này để có cái nhìn tốt hơn về các mô hình này "Distributed Representations of Words and Phrases and their Compositionality’ by Mikolov et al" và "Efficient Estimation of Word Representations in Vector Space’ by Mikolov et al".
Mô hình Continuous Bag of Words (CBOW)
Mô hình CBOW sẽ cố gắng dự đoán từ trung tâm (center word hoặc target word) dựa trên ngữ cảnh được tạo ra từ các từ xung quanh nó (surrounding words). Chúng ta hay xem xét một câu đơn giản "the quick brown fox jumps over the lazy dog", chúng ta có thể có các cặp (context_window, target_word) nếu chọn context_window = 2 ta sẽ có ([quick, fox], brown), ([the, brown], quick), ([the, dog], lazy). Như vậy ta có thể dự đoán target_word dựa trên context_window như sau.
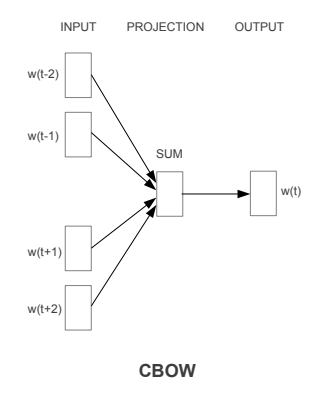
Bởi vì Word2Vec là họ mô hình học không giám sát unsupervised nên bạn có thể đưa vào thuật toán các bộ dữ liệu không cần phải được gán nhãn, thông tin từ trước mà mô hình vẫn có thể đưa ra được vectơ embedding. Nhưng bạn cũng có thể tận dụng việc học giám sát hoặc áp dụng bài toán phân lớp nếu bạn có sẵn những tập dữ liệu như vậy để đưa tạo ra các vectơ embedding. Các bạn có thể xây dựng CBOW như một mô hình phân lớp với đầu vào X là các context_words và output y là target_word. Trong thực tế việc xây dựng mô hình CBOW này sẽ đơn giản hơn mô hình Skip-gram, dạng mô hình mà chúng ta cố gắng dự đoán ngữ cảnh từ target_word
Xây dựng mô hình Continuous Bag of Words (CBOW)
Mặc dù hiện nay Word2Vec được hỗ trợ bởi các frameword như gensim, nhưng trong bài viết này, chúng ta sẽ thử thực hiện các bước từ đầu để mọi người có thể thật sự hiểu được các vấn đề phía sau phương pháp này và cách nó hoạt động. Chúng ta sẽ sử dụng tập dữ liệu Bible corpus từ norm_bible để huấn luyện mô hình. Việc xây dựng mô hình sẽ tập trung vào bốn bước sau.
- Xây dựng tập từ vựng
- Xây dựng CBOW generator (bao gồm các cặp [context_window, target_word])
- Xây dựng kiến trúc mô hình CBOW
- Huấn luyện mô hình
- Thu được embedding của các từ
Xây dựng tập từ vựng
Đầu tiên, chúng ta sẽ xây dựng vốn từ vựng, chúng ta sẽ trích xuất từng từ duy nhất từ tập từ vựng sẵn có và ánh xạ một id duy nhất cho nó
from keras.preprocessing import text from keras.utils import np_utils from keras.preprocessing import sequence tokenizer = text.Tokenizer() tokenizer.fit_on_texts(norm_bible) word2id = tokenizer.word_index # build vocabulary of unique words word2id['PAD'] = 0 id2word = {v:k for k, v in word2id.items()} wids = [[word2id[w] for w in text.text_to_word_sequence(doc)] for doc in norm_bible] vocab_size = len(word2id) embed_size = 100 window_size = 2 # context window size print('Vocabulary Size:', vocab_size) print('Vocabulary Sample:', list(word2id.items())[:10])
Output ------ Vocabulary Size: 12425 Vocabulary Sample: [('perceived', 1460), ('flagon', 7287), ('gardener', 11641), ('named', 973), ('remain', 732), ('sticketh', 10622), ('abstinence', 11848), ('rufus', 8190), ('adversary', 2018), ('jehoiachin', 3189)]
Như vậy các bạn thấy rằng chúng ta đã tạo ra một kho từ vựng từ tập văn bản và gán id cho chúng.
Xây dựng CBOW generator
Chúng ta cần xây dựng các cặp bao gồm một target_word và các surrounding context có lenght = 2 * window_size. Trong đó window_size là số từ liền trước và liền sau target_word trong tập dữ liệu. Các bạn hãy xem qua ví dụ dưới đây
def generate_context_word_pairs(corpus, window_size, vocab_size): context_length = window_size*2 for words in corpus: sentence_length = len(words) for index, word in enumerate(words): context_words = [] label_word = [] start = index - window_size end = index + window_size + 1 context_words.append([words[i] for i in range(start, end) if 0 <= i < sentence_length and i != index]) label_word.append(word) x = sequence.pad_sequences(context_words, maxlen=context_length) y = np_utils.to_categorical(label_word, vocab_size) yield (x, y) # Test this out for some samples i = 0 for x, y in generate_context_word_pairs(corpus=wids, window_size=window_size, vocab_size=vocab_size): if 0 not in x[0]: print('Context (X):', [id2word[w] for w in x[0]], '-> Target (Y):', id2word[np.argwhere(y[0])[0][0]]) if i == 10: break i += 1
Context (X): ['old','testament','james','bible'] -> Target (Y): king Context (X): ['first','book','called','genesis'] -> Target(Y): moses Context(X):['beginning','god','heaven','earth'] -> Target(Y):created Context (X):['earth','without','void','darkness'] -> Target(Y): form Context (X): ['without','form','darkness','upon'] -> Target(Y): void Context (X): ['form', 'void', 'upon', 'face'] -> Target(Y): darkness Context (X): ['void', 'darkness', 'face', 'deep'] -> Target(Y): upon Context (X): ['spirit', 'god', 'upon', 'face'] -> Target (Y): moved Context (X): ['god', 'moved', 'face', 'waters'] -> Target (Y): upon Context (X): ['god', 'said', 'light', 'light'] -> Target (Y): let Context (X): ['god', 'saw', 'good', 'god'] -> Target (Y): light
Như output ở trên các bạn có thể có được một số ngữ cảnh (X) khác nhau để dự đoán cho target_word (Y). Ví dụ, nếu văn bản gốc là "in the beginning god created heaven and earth", sau khi các bước tiền xử lý, làm sạch dữ liệu sẽ trở thành "beginning god created heaven earth" và điều chúng ta đang cố gắng thu được là nếu có được ngữ cảnh bao gồm [beginning, god, heaven, earth] thì center_word sẽ là "created"
Xây dựng kiến trúc mô hình CBOW
Tiếp theo chúng ta sẽ sử dụng keras là framework base trên tensorflow để xây dựng kiến trúc deeplearning cho mô hình CBOW. Đầu vào của chúng ta sẽ một embedding layer của các từ trong tập ngữ cảnh thu được từ bước xử lý trên (weights được khởi tạo ngẫu nhiên). Tiếp theo là một lambda layer, layer này sẽ lấy trung bình của của các word embeddings (Sở dĩ được gọi là CBOW vì chúng ta không cần quan tâm đến trình tự các từ trong mỗi ngữ cảnh khi tính trung bình ở layer này) và cuối cùng sẽ là một Dense layer với activation function là softmax để dự đoán center_word. Sau cùng sẽ sử dụng categorical_crossentropy để tính toán loss của mô hình. Nào, hãy xem đoạn source code dưới đây!
import keras.backend as K from keras.models import Sequential from keras.layers import Dense, Embedding, Lambda # build CBOW architecture cbow = Sequential() cbow.add(Embedding(input_dim=vocab_size, output_dim=embed_size, input_length=window_size*2)) cbow.add(Lambda(lambda x: K.mean(x, axis=1), output_shape=(embed_size,))) cbow.add(Dense(vocab_size, activation='softmax')) cbow.compile(loss='categorical_crossentropy', optimizer='rmsprop') # view model summary print(cbow.summary()) # visualize model structure from IPython.display import SVG from keras.utils.vis_utils import model_to_dot SVG(model_to_dot(cbow, show_shapes=True, show_layer_names=False, rankdir='TB').create(prog='dot', format='svg'))
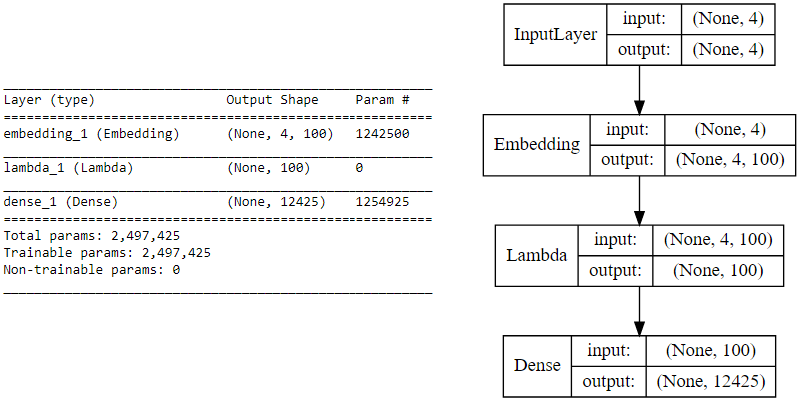
Có lẽ đến đây các bạn vẫn sẽ khó khăn trong việc tưởng tượng ra mô hình deep learning ở trên, các bạn nên đọc kỹ hơn bài báo đã được nhắc tới ở phần trên bài viết này để hiểu sâu hơn về nó. Bây giờ chúng ta sẽ cố gắng tổng hợp lại những điều cốt lõi một cách đơn giản nhất! Các bạn có các ngữ cảnh đầu vào với kích thước là 2 * window_size, chúng ta sẽ cho chúng đi qua một embedding layer có kích thước là vocab_size x embed_size và chúng ta sẽ thu được các dense word embedding có kích thước là 1 * embed_size cho mỗi từ trong tập ngữ cảnh. Tiếp theo sử dụng một lambda layer để lấy ra trung bình của các dense embedding và cuối cùng là dense layer với activation function softmax để dự đoán giá trị của target_word. Chúng ta so sánh giá trị này với giá trị target_word thực tế để tính toán loss và thực hiện việc điều chỉnh trọng số. Mô hình dưới đây sẽ mô tả các bước trên.
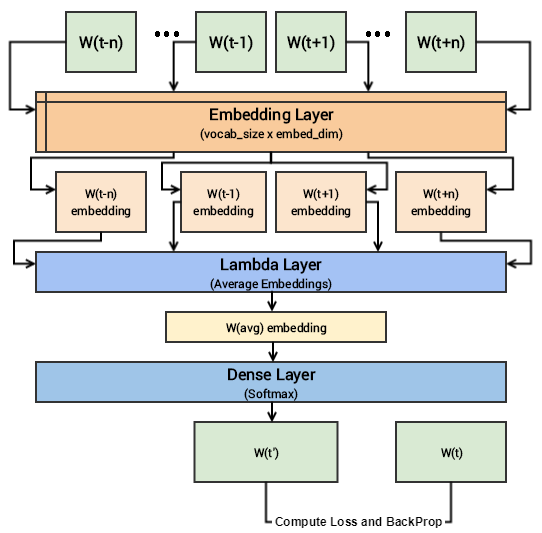
Bây giờ tất cả đã sẵn sàng để huấn luyện mô hình này trên tập dữ liệu **(context, target_word) **.
Huấn luyện mô hình
Việc huấn luyện mô hình hoàn chỉnh sẽ mất một chút thời gian, vậy nên chúng ta sẽ thử nghiệm với 5 epoch. Các bạn có thể tham khảo đoạn source code dưới đây và tăng thêm số lượng epoch nếu thấy cần thiết
for epoch in range(1, 6): loss = 0. i = 0 for x, y in generate_context_word_pairs(corpus=wids, window_size=window_size, vocab_size=vocab_size): i += 1 loss += cbow.train_on_batch(x, y) if i % 100000 == 0: print('Processed {} (context, word) pairs'.format(i)) print('Epoch:', epoch, ' Loss:', loss) print()
Epoch: 1 Loss: 4257900.60084 Epoch: 2 Loss: 4256209.59646 Epoch: 3 Loss: 4247990.90456 Epoch: 4 Loss: 4225663.18927 Epoch: 5 Loss: 4104501.48929
Note: Việc huấn luyện mô hình cần rất nhiều tài nguyên cho việc tính toán và sẽ hoạt động tốt hơn nếu sử dụng GPU. Trong bài viết này tác gỉa đã sử dụng phiên bản AWS p2.x với GPU Tesla K80 để huân luyện 5 epoch trong 1.5 giờ
Thu được embedding của các từ
Để lấy ra được embedding của các từ, các bạn có thể làm theo đoạn source code dưới đây.
weights = cbow.get_weights()[0] weights = weights[1:] print(weights.shape) pd.DataFrame(weights, index=list(id2word.values())[1:]).head()
Các bạn có thể thấy một cách khá rõ ràng, với mỗi từ ta sẽ có một vectơ embedding kích thước 1 * 100 đúng với mô tả output trước đó. Bây giờ hãy thử tìm kiếm một số từ có ngữ cảnh tương tự nhau với một vài từ cho trước dựa trên các vectơ embedding này. Để làm được điều đó, chúng ta sẽ xây dựng một ma trận khoảng cách theo từng cặp từ trong tập hợp từ vựng đã có sau đó tìm ra k "hàng xóm" gần nhất của từ đó dựa trên khoảng cách euclidean.
from sklearn.metrics.pairwise import euclidean_distances # compute pairwise distance matrix distance_matrix = euclidean_distances(weights) print(distance_matrix.shape) # view contextually similar words similar_words = {search_term: [id2word[idx] for idx in distance_matrix[word2id[search_term]-1].argsort()[1:6]+1] for search_term in ['god', 'jesus', 'noah', 'egypt', 'john', 'gospel', 'moses','famine']} similar_words
(12424, 12424)
{'egypt': ['destroy', 'none', 'whole', 'jacob', 'sea'],
'famine': ['wickedness', 'sore', 'countries', 'cease', 'portion'],
'god': ['therefore', 'heard', 'may', 'behold', 'heaven'],
'gospel': ['church', 'fowls', 'churches', 'preached', 'doctrine'],
'jesus': ['law', 'heard', 'world', 'many', 'dead'],
'john': ['dream', 'bones', 'held', 'present', 'alive'],
'moses': ['pharaoh', 'gate', 'jews', 'departed', 'lifted'],
'noah': ['abram', 'plagues', 'hananiah', 'korah', 'sarah']}
Với kết quả thu được các bạn sẽ thấy một trong số chúng có sự tương đồng thật sự theo ngữ cảnh, ví dụ như (god, heaven), (gospel, church) tuy nhiên một số khác thì không. Trong thực tế, huấn luyện mô hình với số lượng epoch lớn hơn chúng ta sẽ thu được kết quả tốt hơn!
Như vậy trong bài viết này các bạn đã có được cái nhìn tổng quát về việc áp dụng các mô hình học sâu vào việc xử lý dữ liệu dạng văn bản bao gồm cả ngữ nghĩa, cũng như phương pháp cơ bản nhất thường được sử dụng là CBOW, trong phần tiếp theo chúng ta sẽ làm quen nốt với các phương pháp còn lại.
