Giới thiệu về các pre-trained models trong lĩnh vực Computer Vision
1. Introduction Trong những năm gần đây, Artificial Intelligence (AI) hay trí tuệ nhân tạo đang có những sự phát triển mạnh mẽ trên nhiều lĩnh vực. Một trong những lĩnh vực có được sự phát triển thần sầu nhất phải kể đến là Computer Vision. Sự ra đời của Convolution Neural Network ...

1. Introduction
Trong những năm gần đây, Artificial Intelligence (AI) hay trí tuệ nhân tạo đang có những sự phát triển mạnh mẽ trên nhiều lĩnh vực. Một trong những lĩnh vực có được sự phát triển thần sầu nhất phải kể đến là Computer Vision. Sự ra đời của Convolution Neural Network (mạng neuron tich chập) cùng với phát triển mạnh mẽ của Deep Learning đã giúp cho Computer Vision đạt được nhiều bước đột phá đáng kế trong các bài toán: image classification, object detection, video tracking, image restoration, etc. Trong bài viết này mình sẽ giới thiệu với các bạn các CNN pre-trained model nổi tiếng. Bài viết này hướng tới những bạn đã có lý thuyết tốt về Deep Learning nói chung và Convolution Neural Network nói riêng. Trong phần demo mình sẽ sử dụng Python và thư viện Keras.
2. Pre-trained CNN model in Keras VGG-16
Đầu tiên phải kể tới mạng VGG. VGG ra đời năm 2015 và được giới thiệu tại hội thảo ICLR 2015. Kiến trúc của mô hình này có nhiều biến thể khác nhau: 11 layers, 13 layers, 16 layers, và 19 layers, các bạn có thể xem chi tiết trong hình sau: 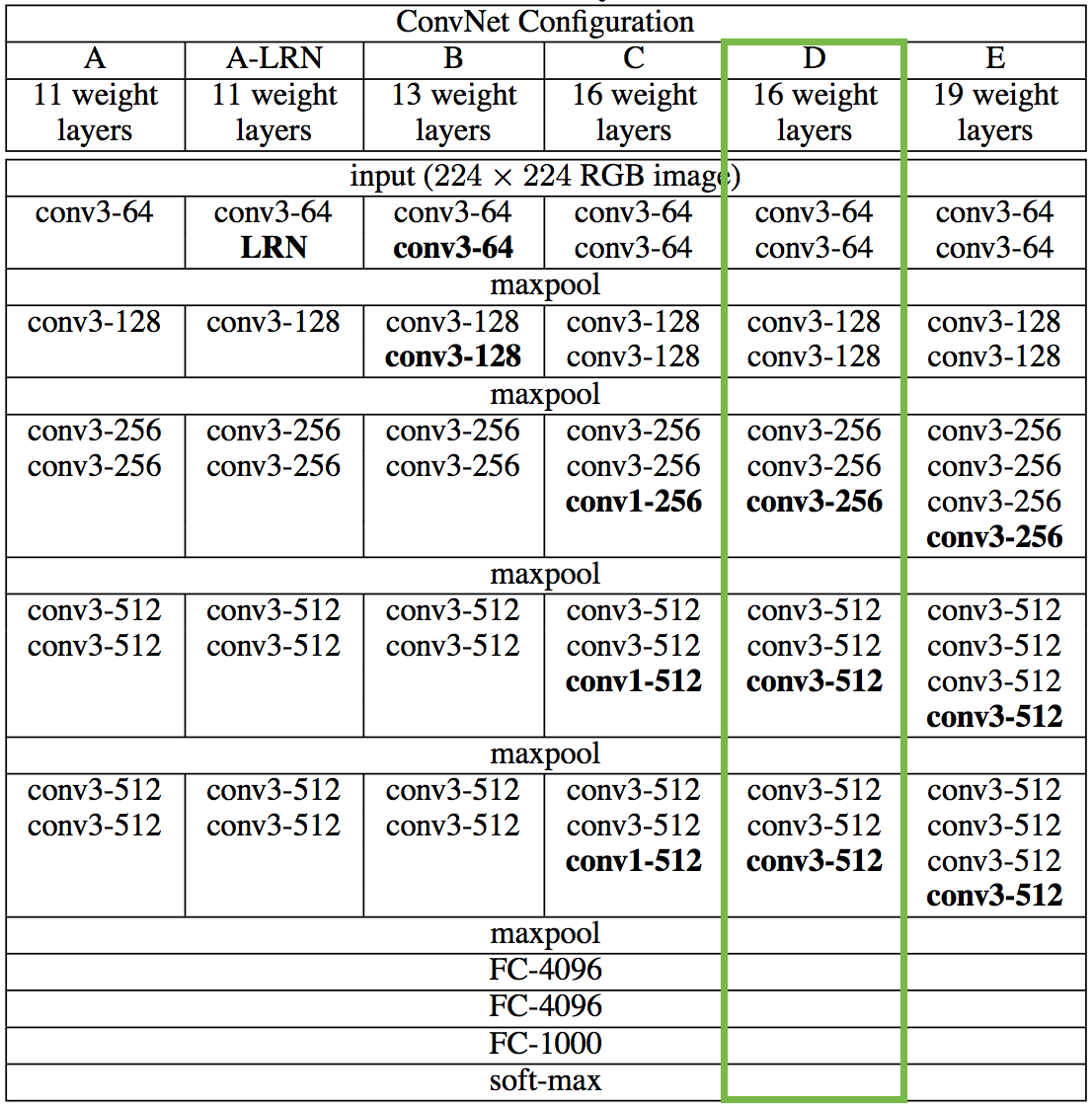 Trong bài viết này mình sẽ đề cập tới VGG-16 – kiến trúc mạng có 16 layers. Nguyên tắc thiết kế của các mạng VGG nói chung rất đơn giản: 2 hoặc 3 layers Convolution (Conv) và tiếp nối sau đó là 1 layer Max Pooling 2D. Ngay sau Conv cuối cùng là 1 Flatten layer để chuyển ma trận 4 chiều của Conv layer về ma trận 2 chiều. Tiếp nối sau đó là các Fully-connected layers và 1 Softmax layer. Do VGG được training trên tập dữ liệu của ImageNet có 1000 class nên ở Fully-connected layer cuối cùng sẽ có 1000 units.
Trong bài viết này mình sẽ đề cập tới VGG-16 – kiến trúc mạng có 16 layers. Nguyên tắc thiết kế của các mạng VGG nói chung rất đơn giản: 2 hoặc 3 layers Convolution (Conv) và tiếp nối sau đó là 1 layer Max Pooling 2D. Ngay sau Conv cuối cùng là 1 Flatten layer để chuyển ma trận 4 chiều của Conv layer về ma trận 2 chiều. Tiếp nối sau đó là các Fully-connected layers và 1 Softmax layer. Do VGG được training trên tập dữ liệu của ImageNet có 1000 class nên ở Fully-connected layer cuối cùng sẽ có 1000 units.
Trong Keras hiện tại có hỗ trợ 2 pre-trained model của VGG: VGG-16 và VGG 19. Có 2 params chính các bạn cần lưu ý là include_top (True / False): có sử dụng các Fully-connected layer hay không và weights (‘imagenet’ / None): có sử dụng pre-trained weights của ImageNet hay không.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<span class="token comment"># VGG 16</span> <span class="token keyword">from</span> keras<span class="token punctuation">.</span>applications<span class="token punctuation">.</span>vgg16 <span class="token keyword">import</span> VGG16 <span class="token comment"># Sử dụng pre-trained weight từ ImageNet và không sử dụng các Fully-connected layer ở cuối</span> pretrained_model <span class="token operator">=</span> VGG16<span class="token punctuation">(</span>include_top<span class="token operator">=</span><span class="token boolean">False</span><span class="token punctuation">,</span> weights<span class="token operator">=</span><span class="token string">'imagenet'</span><span class="token punctuation">)</span> <span class="token comment"># VGG 19</span> <span class="token keyword">from</span> keras<span class="token punctuation">.</span>applications<span class="token punctuation">.</span>vgg19 <span class="token keyword">import</span> VGG19 <span class="token comment"># Không sử dụng pre-trained weight từ ImageNet và không sử dụng các Fully-connected layer ở cuối</span> pretrained_model <span class="token operator">=</span> VGG19<span class="token punctuation">(</span>include_top<span class="token operator">=</span><span class="token boolean">False</span><span class="token punctuation">,</span> weights<span class="token operator">=</span><span class="token boolean">None</span><span class="token punctuation">)</span> |
InceptionNet
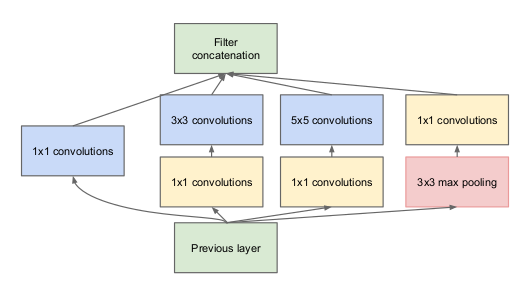
Với các mạng CNN thông thường, khi thiết kế ta bắt buộc phải xác định trước các tham số của 1 Conv layer như: kernel_size, padding, strides, etc. Và thường thì rất khó để ta có thể nói trước được tham số nào là phù hợp, kernel_size = (1, 1) hay (3, 3) hay (5, 5) sẽ tốt hơn. Mạng Inception ra đời để giải quyết vấn đề đó, yếu tố quan trọng nhất trong mạng Inception là Inception module, một mạng Inception hoàn chỉnh bao gồm nhiều module Inception nhỏ ghép lại với nhau. Các bạn có thể xem hình minh họa dưới đây để hiểu rõ hơn. Ý tưởng của Inception module rất đơn giản, thay vì sử dụng 1 Conv layer với tham số kernel_size cố định, ta hoàn toàn có thể sử dụng cùng lúc nhiều Conv layer với các tham số kernel_size khác nhau (1, 3, 5, 7, etc) và sau đó concatenate các output lại với nhau. Để không bị lỗi về chiều của ma trận khi concatenate, tất cả các Conv layer đều có chung strides=(1, 1) và padding=’same’. Ở thời điểm hiện tại, có 3 phiên bản của mạng Inception, các version sau thường có 1 vài điểm cải tiến so với phiên bản trước để cải thiện độ chính xác. Keras hiện tại hỗ trợ pre-trained model Inception version 3.
|
1 2 3 4 5 6 7 |
<span class="token keyword">from</span> keras<span class="token punctuation">.</span>applications<span class="token punctuation">.</span>inception_v3 <span class="token keyword">import</span> InceptionV3 <span class="token comment"># các tham số include_top và weights các bạn có thể tùy chỉnh</span> <span class="token comment"># theo ý muốn để phù hợp với bài toán của riêng mình.</span> pretrained_model <span class="token operator">=</span> InceptionV3<span class="token punctuation">(</span>include_top<span class="token operator">=</span><span class="token boolean">False</span><span class="token punctuation">,</span> weights<span class="token operator">=</span><span class="token string">'imagenet'</span><span class="token punctuation">)</span> |
ResNet
Mô hình CNN tiếp theo mình muốn giới thiệu với các bạn là ResNet hay Residual Network. Khi train các mô hình Deep CNN (số lượng layers lớn, số lượng param lớn, etc) ta thường gặp phải vấn đề về vanishing gradient hoặc exploding gradient. Thực tế cho thấy khi số lượng layer trong CNN model tăng, độ chính xác của mô hình cũng tăng theo, tuy nhiên khi tăng số layers quá lớn (>50 layers) thì độ chính xác lại bị giảm đi.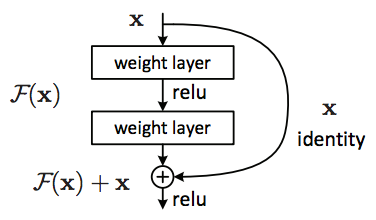
Residual block ra đời nhằm giải quyết vấn đề trên, với Residual block, ta hoàn toàn có thể train các mô hình CNN có kích thước và độ phức tạp “khủng” hơn mà không lo bị exploding/vanishing gradient. Mấu chốt của Residual block là cứ sau 2 layer, ta cộng input với output: F(x) + x. Resnet là một mạng CNN bao gồm nhiều Residual block nhỏ tạo thành. Hiện tại trong Keras có pre-trained model của ResNet50 với weight được train trên tập ImageNet với 1000 clas.
|
1 2 3 4 5 |
<span class="token keyword">from</span> keras<span class="token punctuation">.</span>applications<span class="token punctuation">.</span>resnet50 <span class="token keyword">import</span> ResNet50 pretrained_model <span class="token operator">=</span> ResNet50<span class="token punctuation">(</span>include_top<span class="token operator">=</span><span class="token boolean">False</span><span class="token punctuation">,</span> weights<span class="token operator">=</span><span class="token string">'imagenet'</span><span class="token punctuation">)</span> |
InceptionResNet
Nghe tên mô hình chắc các bạn cũng đoán ra được cấu hình của mạng rồi. InceptionResNet là mô hình được xây dựng dựa trên nhưng ưu điểm của Inception và Residual block. Với sự kết hợp này InceptionResNet đạt được đô chính xác rất đáng kinh ngạc. Trên tập dữ liệu ImageNet, InceptionResNet đạt 80.3% top 1 accuray trong khi con số này của Inception V3 và ResNet50 lần lượt là: 77.9% và 74.9%. Để sử dụng pre-trained InceptionResNet trong Keras chúng tac cũng làm tương tự như các pre-trained model khác.
|
1 2 3 4 5 |
<span class="token keyword">from</span> keras<span class="token punctuation">.</span>applications<span class="token punctuation">.</span>inception_resnet_v2 <span class="token keyword">import</span> InceptionResNetV2 pretrained_model <span class="token operator">=</span> InceptionResNetV2<span class="token punctuation">(</span>include_top<span class="token operator">=</span><span class="token boolean">True</span><span class="token punctuation">,</span> weights<span class="token operator">=</span><span class="token string">'imgaenet'</span><span class="token punctuation">)</span> |
MobileNet
Các mô hình CNN vừa được giới thiệu, tuy có độ chính xác cao, nhưng chúng đều có một điểm hạn chế chung đó là không phù hợp với các ứng dụng trên mobile hay các hệ thống nhúng có khả năng tính toán thấp. Nếu muốn deploy các mô hình trên cho các ứng dụng real time, ta cần phải có cấu hình cực kì mạnh mẽ (GPU / TPU) còn đối với các hệ thống nhúng (Raspberry Pi, Nano pc, etc) hay các ứng dụng chạy trên smart phone, ta cần có một mô hình “nhẹ” hơn. Dưới đây benchmark các mô hình trên cùng tập dữ liệu ImageNet, ta có thể thấy MobileNetV2 có độ chính xác không hề thua kém các mô hình khác như VGG16, VGG19 trong khi lượng parameters chỉ vỏn vẹn 3.5M (khoảng 1/40 số tham số của VGG16).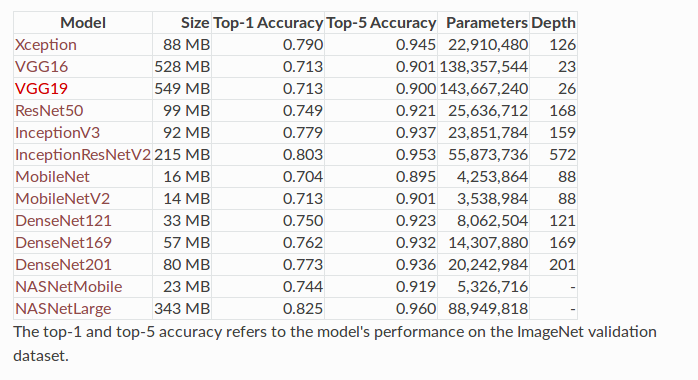
Yếu tố chính giúp MobileNet có được độ chính xác cao trong khi thời gian tính toán thấp nằm ở sự cải tiến Conv layer bình thường. Trong MobileNet có 2 Covn layer được sử dụng là: SeparableConv và DepthwiseConv. Thay vì thực hiện phép tích chập như thông thường, SeparableConv sẽ tiến hành phép tích chập depthwise spatial (mình cũng không biết dịch ntn luôn
