GraphQL mà tôi thường nghe thấy là thứ gì? (Phần 1)
Bài viết này được dịch từ bài So what’s this GraphQL thing I keep hearing about? của tác giả Sacha Greif. Phần 2: https://viblo.asia/p/graphql-ma-toi-thuong-nghe-thay-la-thu-gi-phan-2-m68Z089zZkG Nếu bạn giống tôi, bạn có thể sẽ trải qua 3 giai đoạn dưới đây khi nghe về một công nghệ ...
Bài viết này được dịch từ bài So what’s this GraphQL thing I keep hearing about? của tác giả Sacha Greif.
Phần 2: https://viblo.asia/p/graphql-ma-toi-thuong-nghe-thay-la-thu-gi-phan-2-m68Z089zZkG
Nếu bạn giống tôi, bạn có thể sẽ trải qua 3 giai đoạn dưới đây khi nghe về một công nghệ mới:
- Lảng tránh
Một thư viện JavaScript mới?! Chỉ cần dùng jQuery là được!
- Có hứng thú
Hừm, có lẽ tôi nên xem thử cái thư viện mới mà tôi hay nghe thấy...
- Hoảng hốt
Giúp với! Tôi cần học thư viện mới này ngay lập tức không thì tôi sẽ lạc hậu mất!
Mẹo để duy trì sự tỉnh táo trong thời buổi thay đổi chóng mặt này là học những thứ mới với trạng thái ở giữa giai đoạn 2 và 3, khi sự hứng thú của bạn đã được khơi gợi nhưng trong khi bạn vẫn còn đang đón đầu xu thế.
Đó là lý do tại sao bây giờ là thời điểm hoàn hảo để tìm hiểu chính xác thì GraphQL mà bạn hay nghe thấy thực sự là thứ gì.
Tóm lại, GraphQL là một cú pháp mô tả cách truy vấn dữ liệu, và thông thường được sử dụng để lấy dữ liệu từ server về cho client. GraphQL có 3 đặc điểm chính:
- Nó cho phép client xác định chính xác dữ liệu nào mà client cần
- Nó giúp cho việc tổng hợp dữ liệu từ nhiều nguồn trở nên dễ dàng hơn
- Nó sử dụng một hệ thống kiểu để mô tả dữ liệu
Vậy GraphQL đã ra đời như thế nào? Trong thực tế thì trông nó ra sao? Và làm thế nào để bạn có thể bắt đầu sử dụng nó? Hay đọc tiếp để tìm ra câu trả lời!

GraphQL ra đời ở Facebook, khi những ứng dụng nhỏ có thể chạm tới những hạn chế của REST API truyền thống.
Ví dụ, tưởng tượng rằng bạn cần hiển thị một danh sách các post, mỗi post chứa một danh sách các like, bao gồm tên người dùng và ảnh đại diện. Dễ dàng rằng, bạn có thể thay đổi API post của mình để nó chứa một mảng các like gồm thông tin của người dùng:

Nhưng đến lúc làm việc với ứng dụng di động của bạn, bạn thấy rằng lấy tất cả dữ liệu sẽ rất chậm. Vậy là bạn cần 2 điểm cung cấp dữ liệu, một chứa các like và một không chứa.
Giờ thì phát sinh thêm một nhân tố nữa: post được lưu ở MySQL, trong khi like được lưu ở Redis! Bạn sẽ làm thế nào đây?!
Mở rộng kịch bản này cho đến khi tương đương với lượng nguồn dữ liệu và API mà Facebook phải quản lý, và bạn có thể thấy được REST API bắt đầu bộc lộ những hạn chế của nó.
Giải pháp của Facebook về mặt khái niệm rất đơn giản: thay vì có nhiều điểm cấp dữ liệu "ngu", một điểm cấp dữ liệu "thông minh" sẽ nhận các truy vấn phức tạp, sau đó nhào nặn dữ liệu để trả ra đúng định dạng mà client yêu cầu.
Về mặt thực tế, tầng GraphQL nằm giữa client và một hoặc nhiều nguồn dữ liệu, nhận request của client và lấy các dữ liệu cần thiết dựa trên các chỉ dẫn của bạn. Cảm thấy rối? Đến lúc ẩn dụ rồi!
Mô hình REST giống như đặt pizza, sau đó gọi chuyển hàng tạp hóa, và rồi gọi cửa hàng giặt khô để lấy quần áo của bạn. Ba cửa hàng, ba cuộc gọi.

Trái lại, GraphQL giống như có một trợ lý riêng: một khi bạn đã đưa cho họ địa chỉ của 3 cửa hàng, bạn chỉ cần yêu cầu những gì bạn cần ("giặt khô quần áo, một cái pizza cỡ lớn và 2 tá trứng") và chờ họ trở lại.

Nói cách khác, GraphQL thiết lập một ngôn ngữ chuẩn để giao tiếp với người trợ lý thần kỳ này.

Theo Google thì những người trợ lý thông thường là một người ngoài hành tinh có 8 tay

Trong thực tế, một API GraphQL được tổ chức xung quanh 3 khối chính: sơ đồ (schema), truy vấn (query) và bộ phân giải (resolver).
Yêu cầu bạn gửi đến người trợ lý GraphQL của mình là truy vấn, và nó trông như thế này:
query { stuff }
Chúng ta khai báo truy vấn mới bằng từ khóa query, sau đó yêu cầu một trường tên là stuff. Điều tuyệt vời về truy vấn của GraphQL là nó hỗ trợ các trường lồng nhau, vậy nên chúng ta có thể truy vấn sâu thêm một mức nữa:
query { stuff { eggs shirt pizza } }
Như bạn thấy, client tạo truy vấn không cần quan tâm rằng dữ liệu đến từ "cửa hàng" nào. Chỉ cần yêu cầu thứ bạn cần và để server GraphQL lo phần còn lại.
Cũng đáng đề cập đến rằng các trường được truy vấn có thể trỏ đến mảng. Ví dụ, dưới đây là một mẫu thường thấy khi chúng ta truy vấn danh sách các bài viết:
query { posts { # đây là một mảng title body author { # chúng ta có thể truy vấn sâu hơn nữa! name avatarUrl profileURL } } }
Các trường được truy vấn cũng hỗ trợ tham số. Nếu tôi muốn hiển thị một bài viết cụ thể, tôi có thể thêm tham số id vào trường post:
query { post(id: "123foo") { title body author { name avatarUrl profileURL } } }
Cuối cùng, nếu tôi muốn để tham số id có giá trị động, tôi có thể định nghĩa một biến và sử dụng nó bên trong truy vấn (chú ý là ở đây chúng ta còn đặt tên cho truy vấn):
query getMyPost($id: String) { post(id: $id) { title body author { name avatarUrl profileUrl } } }
Một cách tốt để thực hành các ví dụ này là sử dụng GraphQL API Explorer của GitHub. Ví dụ, hãy thử truy vấn sau:
query { repository(owner: "graphql", name: "graphql-js") { name description } }
 GraphQL autocomplete in action
GraphQL autocomplete in action
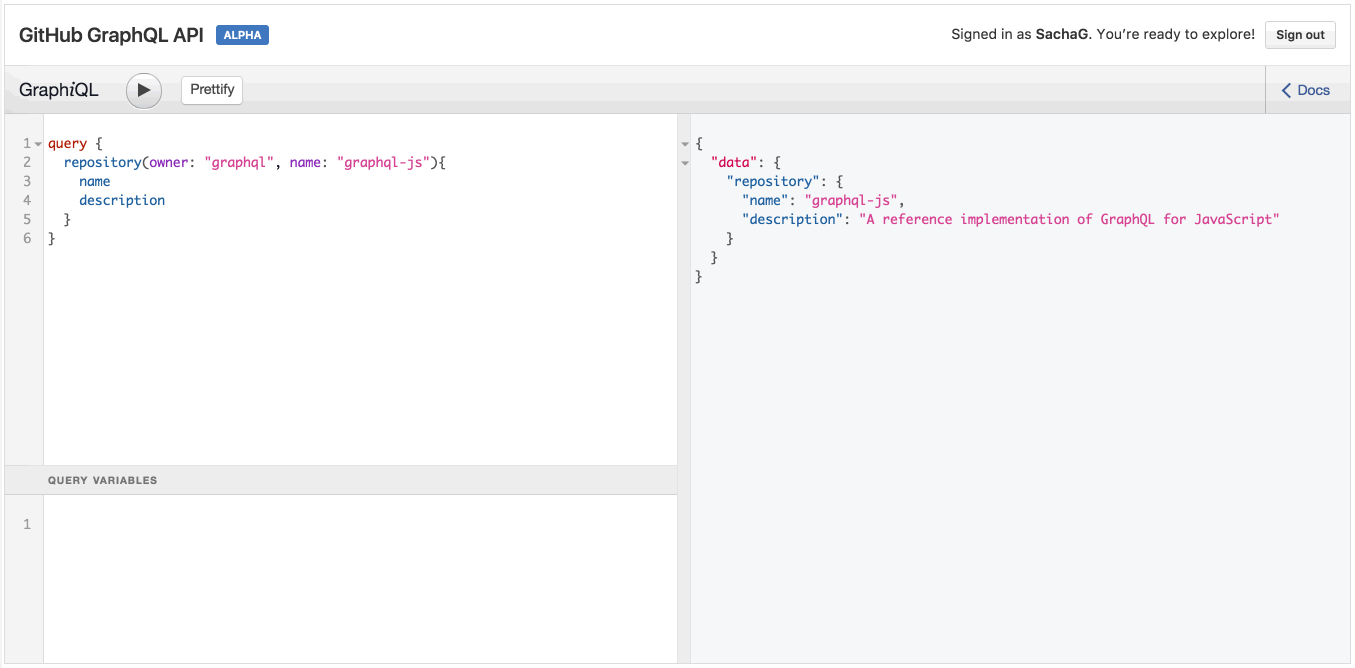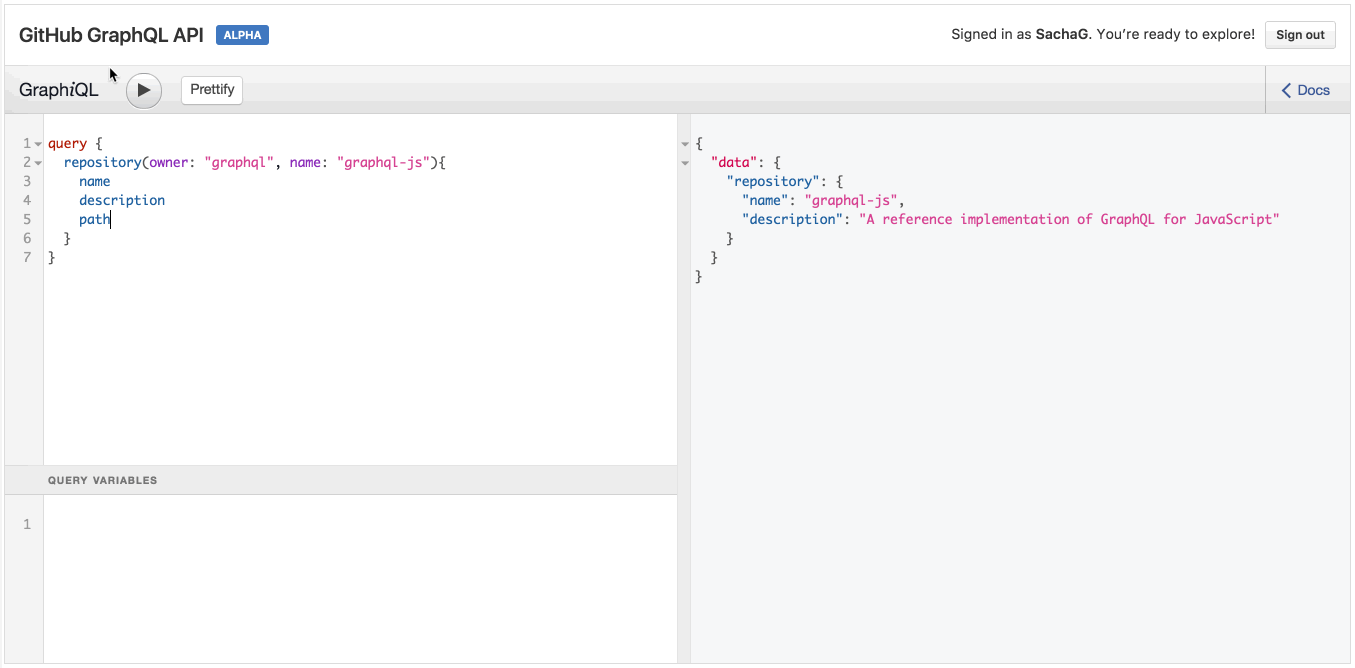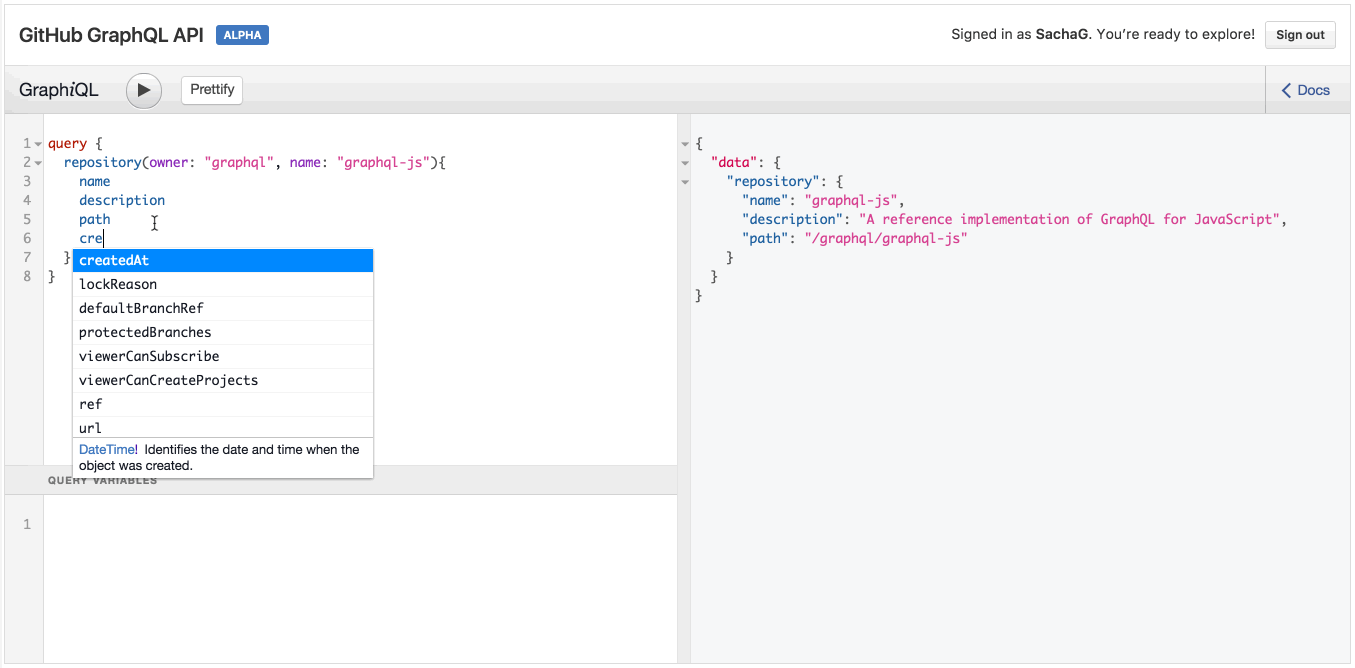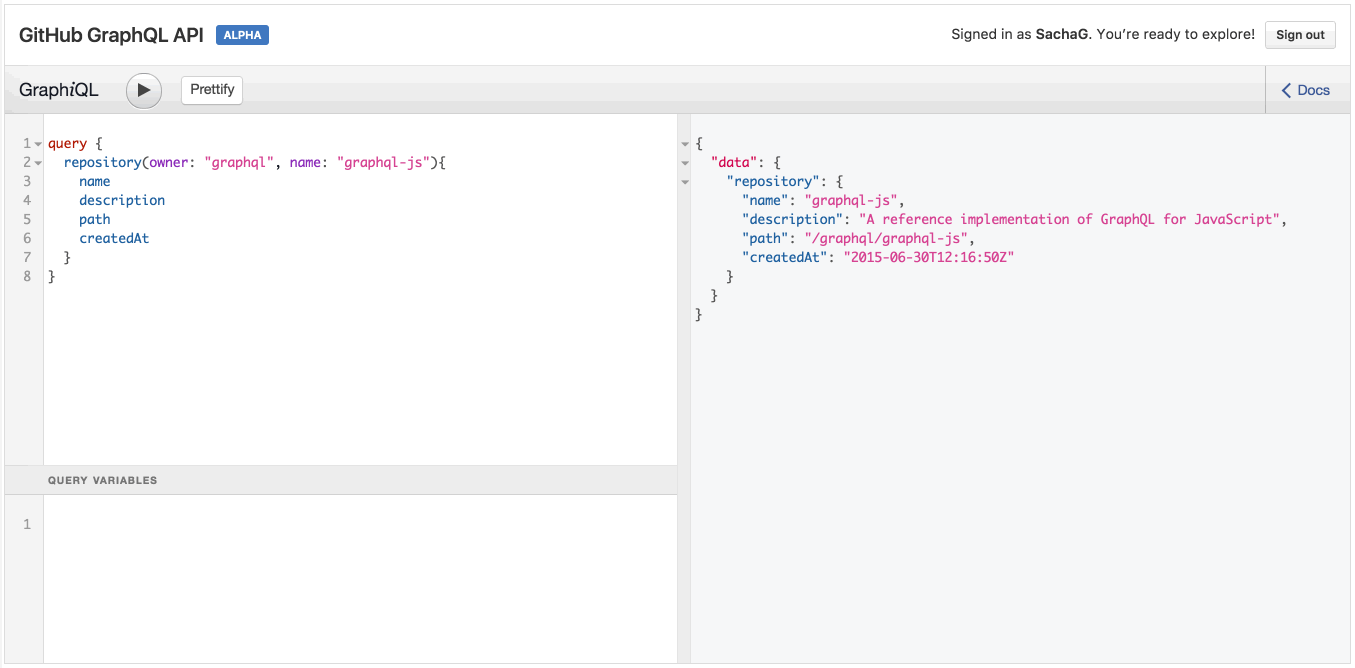
Chú ý là khi bạn thử gõ tên một trường ở bên dưới description, IDE sẽ tự động đưa ra tên các trường có thể dùng để tự động điền từ chính API GraphQL. Tuyệt!
 The Anatomy of a GraphQL Query
The Anatomy of a GraphQL Query
Bạn có thể tìm hiểu thêm về truy vấn của GraphQL trong bài viết Anatomy of A GraphQL Query xuất sắc này.
Ngay cả trợ lý riêng tốt nhất trên thế giới cũng không thể đi lấy đồ giặt khô của bạn nếu bạn không đưa cho họ một địa chỉ nào đó.
Tương tự, server GraphQL của bạn sẽ không biết làm gì với một query nếu bạn không bảo nó sử dụng một bộ phân giải.
Một bộ phân giải cho GraphQL biết cách và nơi lấy dữ liệu tương ứng với một trường. Ví dụ, đây là một bộ phân giải dành cho trường post (sử dụng chương trình sinh sơ đồ GraphQL-Tools của Apollo):
Query: { post(root, args) { return Posts.find({id: args.id}); } }
Chúng ta đặt bộ phân giải trong Query vì chúng ta muốn truy vấn post ngay ở tầng gốc. Bạn cũng có thể đặt bộ phân giải cho các trường con, ví dụ như trường author của post:
Query: { post(root, args) { return Posts.find({id: args.id}); } }, Post: { author(post) { return Users.find({id: post.authorId}) } }
Và chú ý là bộ phân giải của bạn không bị giới hạn ở việc chỉ trả về dữ liệu được ghi trong cơ sở dữ liệu. Ví dụ, bạn có thể thêm commentsCount vào trong kiểu Post:
Post: { author(post) { return Users.find({id: post.authorId}) }, commentsCount(post) { return Comments.find({postId: post.id}).count() } }
Khái niệm chính cần được hiểu ở đây là với GraphQL, sơ đồ API và sơ đồ cơ sở dữ liệu của bạn được tách rời. Nói cách khác, có thể không có trường author hay commentsCount nào trong cơ sở dữ liệu của chúng ta, nhưng chúng ta có thể "giả lập" chúng thông qua sức mạnh của bộ phân giải.
Như bạn thấy, bạn có thể viết bất cứ code gì bạn muốn bên trong một bộ phân giải. Điều đó có nghĩa là bạn cũng có thể viết code thay đổi dữ liệu trong cơ sở dữ liệu, bộ phân giải trong trường hợp đó được gọi là bộ phân giải biến đổi (mutation resolver).
Tất cả những thứ tốt đẹp này có được nhờ hệ thống sơ đồ được định kiểu của GraphQL. Mục tiêu ngày hôm nay của tôi là cho bạn một cái nhìn tổng thể hơn là một bài giới thiệu đầy đủ, vậy nên tôi sẽ không đi vào chi tiết ở đây.
Tuy vậy, tôi khuyến khích bạn xem tài liệu của GraphQL nếu bạn muốn tìm hiểu thêm.

(còn tiếp)
