How to parse HTML file in iOS
Chắc các bạn không còn xa lạ với khái niệm crawler dữ liệu, trên mạng có những trang web chuyên đi lấy dữ liệu của các trang web khác về làm dữ liệu cho trang web của mình, những trang này không tự tạo content mà chuyên đi chôm content từ các trang khác về thành content của trang mình. Cách làm của ...
Chắc các bạn không còn xa lạ với khái niệm crawler dữ liệu, trên mạng có những trang web chuyên đi lấy dữ liệu của các trang web khác về làm dữ liệu cho trang web của mình, những trang này không tự tạo content mà chuyên đi chôm content từ các trang khác về thành content của trang mình. Cách làm của nó là nó sẽ đặt lịch bao lâu sẽ chạy request tới 1 số trang web xác định, lấy dữ liệu HTML sau đó đọc phân tích dữ liệu HTML này lấy thông tin cần thiết về cho trang web của mình. Các trang web này do có cấu trúc xác định nên sẽ lấy được thông tin thông qua việc parse HTML, tuy nhiên nếu cấu trúc HTML của trang đó mà thay đổi thì trang crawler cũng tèo theo. Trước đây cái thời mà appstore còn mới mẻ, các ứng dụng chưa nhiều đã từng có ứng dụng nghe nhạc đình đám chuyên lấy dữ liệu từ trang mp3.zing.vn về làm content cho app đó thông qua cách này. Thỉnh thoảng trang zing thay đổi cấu trúc là app lại tèo, phải cập nhật lại bản mới. Do cấu trúc HTML dễ thay đổi nên việc parse theo regular expression sẽ rất phức tạp, ở bài này tôi sẽ hướng dẫn các bạn parse dữ liệu html thành 1 object, cụ thể là convert để làm việc với XML và truy vấn theo XPath. Ví dụ ta có 1 đoạn html sau:
<html>
<head>
<title>Some webpage</title>
</head>
<body>
<p class=”normal”>This is the first paragraph</p>
<p class=”special”>This is the second paragraph. <b>This is in bold.</b></p>
</body>
</html>
Phân tích thành cây thư mục sẽ có dạng:
 Nếu bạn muốn truy cập đến title của html thì bạn có thể sử dụng XPath expression như sau:
Nếu bạn muốn truy cập đến title của html thì bạn có thể sử dụng XPath expression như sau:
/html/head/title
Kết quả sẽ là "Some Webpage" Tương tự, nếu bận muốn truy cập đến dữ liệu thẻ p với class = special để lấy "second paragraph", bạn cũng có thể sử dụng expression như sau:
/html/body/p[@class='special']
Bạn đã sử dụng cú pháp [@class='special'] để chỉ ra cái node mà mình muốn tìm là html->body->p trong đó thẻ p có class = special. Nếu có nhiều thẻ p mà cùng có class = special thì expression này sẽ trả về một mảng node thoả mãn. Với iOS thì bạn có thể sử dụng Libxml2 và Hpple để parse html Libxml2 là thư viện của apple cung cấp, nhưng để sử dụng Libxml2 thì rất khó sử dụng, thế nên có một thư việc khá nổi tiếng của The Topfunky Corporation là Hpple (https://github.com/topfunky/hpple), Hpple được viết lại (wraps) trên libxml2, tạo ra một cấu trúc XML và truy vẫn như XPath.
Tạo 1 project mới:
 Download thư viện Hpple tại https://github.com/topfunky/hpple và add vào project:
Download thư viện Hpple tại https://github.com/topfunky/hpple và add vào project:
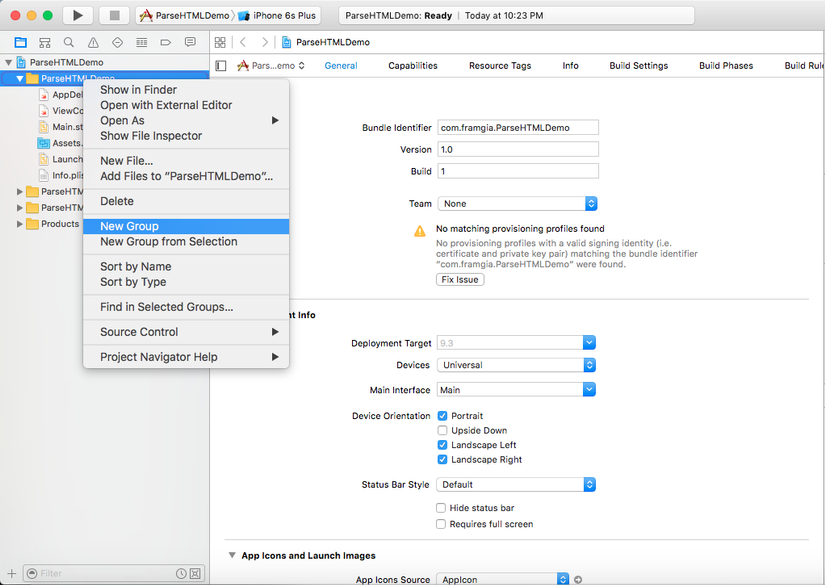
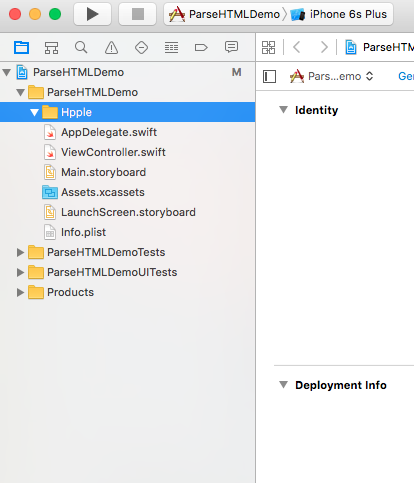 Kéo thả 6 files đã download vào project:
Kéo thả 6 files đã download vào project:
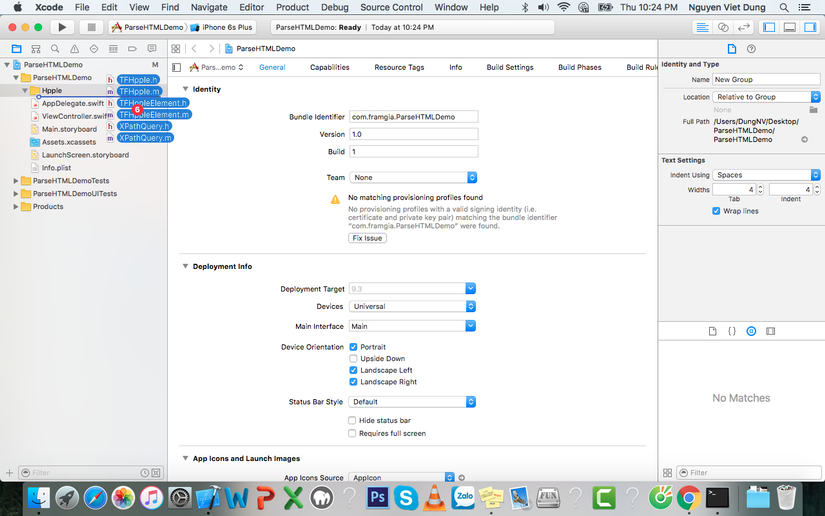 Add libxml2
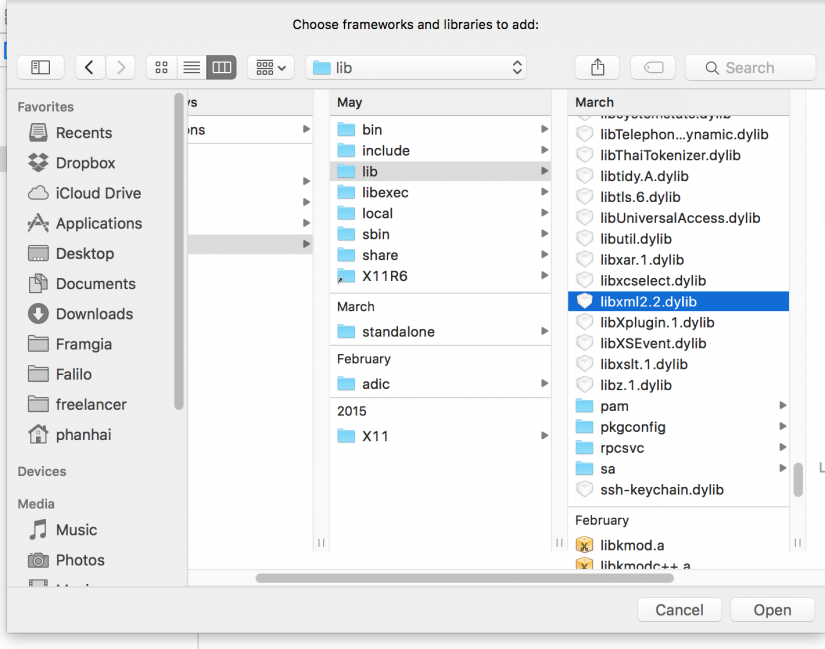
Vào Build Phases > Link Binary With Libraries > + > Add Other > chọn đến thư mục đường dẫn sau "/usr/lib/" > chọn libxml2.2.dylib > add
Add libxml2
Vào Build Phases > Link Binary With Libraries > + > Add Other > chọn đến thư mục đường dẫn sau "/usr/lib/" > chọn libxml2.2.dylib > add
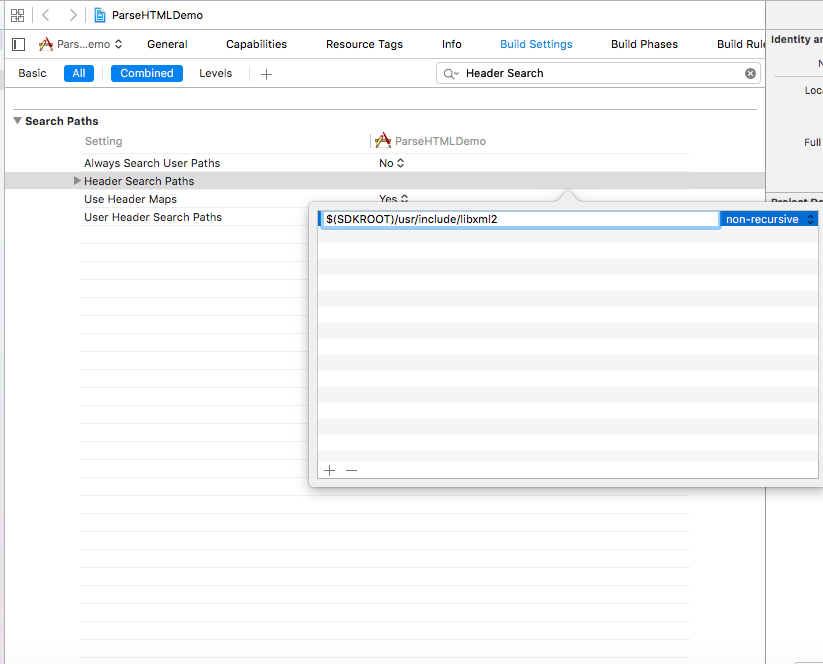
 Build Setting > Header Search Paths > nhập $$SDKROOT)/usr/include/libxml2
Build Setting > Header Search Paths > nhập $$SDKROOT)/usr/include/libxml2
Ta sẽ đọc thông tin HTML của trang https://www.raywenderlich.com lấy tiêu đề các bài viết trang này.
Trước khi parse HTML ta cần phân tích source HTML của trang này trước. Vào trang web bằng chrome sau đó dùng inspect để view source code trang này, hoặc có thể dùng firefox thêm addon firebug:
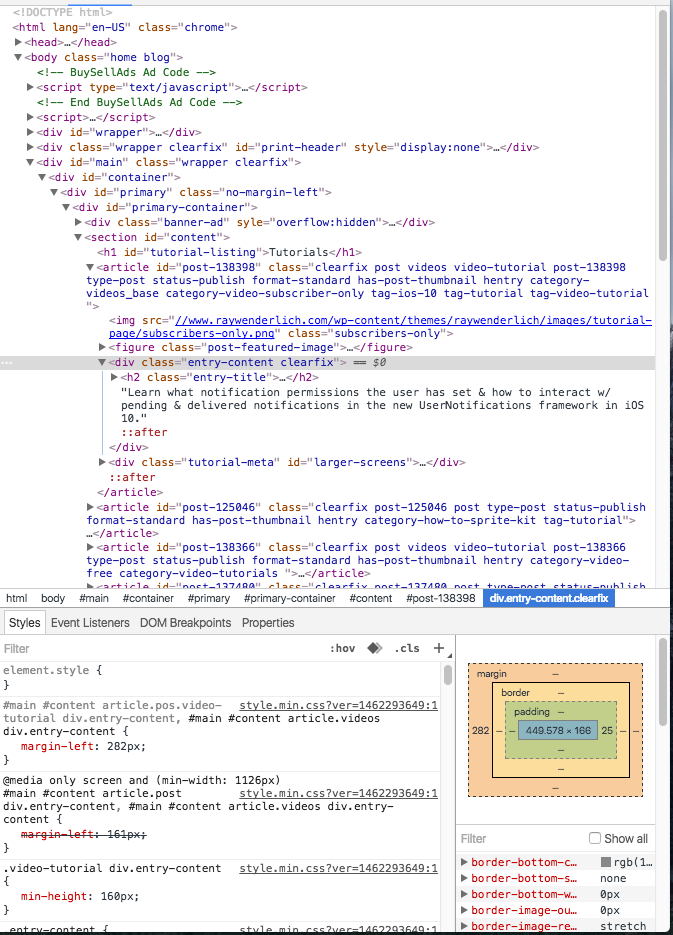 Nhìn vào source code html ta có thể lấy được title thông qua path sau:
//div[@class='item-info']/a
Ta dùng đoạn code bằng Swift như sau để lấy các thông tin này:
Nhìn vào source code html ta có thể lấy được title thông qua path sau:
//div[@class='item-info']/a
Ta dùng đoạn code bằng Swift như sau để lấy các thông tin này:
class ViewController: UIViewController {
override func viewDidLoad() {
super.viewDidLoad()
self.startParsing()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
func startParsing() {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_BACKGROUND, 0), {
let urlLoad = NSURL(string: "https://www.raywenderlich.com")
let data = NSData(contentsOfURL: urlLoad!)
let parser = TFHpple(HTMLData: data)
let xpathQueryContent = "//div[@class='entry-content clearfix']/h2"
let listElements = parser.searchWithXPathQuery(xpathQueryContent)
for k in 0 ..< listElements.count {
let title = listElements[k].content!
print("--->>title : (title)")
}
dispatch_async(dispatch_get_main_queue(), { () -> Void in
})
})
}
}
Kết quả:

- Ở trên ta đã lấy được các title của các bài tutorial của trang rawenderlick.com, sử dụng cách này ta hoàn toàn có thể lấy được title các bài viết từ viblo, nội dung của chúng, sau đó đưa về làm content của mình.
