Hướng dẫn sử dụng Webmaster Tool phần 2 - Công cụ hỗ trợ cho SEO
Xin chào các bạn, hôm nay tôi xin tiếp tục trình bày phần 2 của hướng dẫn sử dụng Webmaster Tool. Ở phần một tôi đã giới thiệu tới các bạn làm thể nào để có một tài khoản, cách xác minh chủ sở hữu website hay cách theo dõi sitemap. Các nội dung hướng dẫn sử dụng trong phần này sẽ là crawl ...
Xin chào các bạn, hôm nay tôi xin tiếp tục trình bày phần 2 của hướng dẫn sử dụng Webmaster Tool.
Ở phần một tôi đã giới thiệu tới các bạn làm thể nào để có một tài khoản, cách xác minh chủ sở hữu website hay cách theo dõi sitemap. Các nội dung hướng dẫn sử dụng trong phần này sẽ là crawl statics, crawl errors làm thế nào để fix được các lỗi crawl...
Trước tiên ta phải hiểu về tập tin robot.txt mà không thể thiếu cho bất cứ website nào
1. Crawl và robot.txt
Crawl được hiểu đơn giản là sự viếng thăm nhằm thu thập thông tin của các con bot công cụ tìm kiếm. Các con bot tìm kiếm sẽ lần lượt viếng thăm hết tất cả các link, page trên đường đi của nó trong website của bạn. Toàn bộ thông tin mà nó thu thập được sẽ được gửi về các máy chủ của Search Engine. Các máy chủ này sẽ có nhiệm vụ tổng hợp thông tin, xem xét đánh giá mức độ thứ tự ưu tiên trước khi hiển thị lên cho người dùng. Hiện tại thì có Google Bot, Yahoo Bot, Bing Bot chúng ta nên lưu ý khi làm SEO...
Để các con bot đó có thể đi qua tất cả các đường ngang ngõ hẻm trong website thì tập tin robot.txt sẽ đảm nhiệm vai trò, cấm và cho phép bot có quyền truy cập vào hay không. Webmaster sẽ cho phép chúng ta kiểm tra và thay đổi nội dung file robot.txt như mong muốn

Nội dung trong file robot.txt thường có dạng như sau
User-agent: * Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/cache/ Allow: /wp-admin/admin-ajax.php Allow: /wp-content/themes/ Allow: /wp-content/plugins/ Allow: /wp-content/uploads/ Allow: /wp-includes/css/ Allow: /wp-includes/js/ Allow: /wp-includes/images/ Sitemap: https://example.com/sitemap.xml
Đầu tiên bạn sẽ thấy từ khóa "User-agent" cho phép chỉ định các loại bot nào có thể viếng thăm website. Ví dụ
- Chỉ định cho phép 1 loại bot viếng thăm (Google hoặc Bing): "User-agent: GoogleBot", "User-agent: BingBot"
- Chi định cho tất cả các loại bot: "User-agent:*"
Tiếp sau đó là 1 loạt các quy định cho phép(Allow)/không cho phép(Disallow) cho từng url hoặc thư mục mà bạn mong muốn. Thông thường việc cho phép này nhằm mục đích giúp người dùng internet truy cập được các tài nguyên website. Chính vì thế các bạn nên cân nhắc tài nguyên nào có thể công khai, tài nguyên nào không thể công khai. Ví dụ phần quản trị (Admin) ta không cần thiết phải cho công khai vì nó không phục vụ mục đích thăng hạng, quảng bá cho website.
Ngoài ra ta còn khai báo cả sitemap trong file robots.txt để các bot có thể dễ dàng thu thập thông tin (giống như kiểu mình chỉ đường cho nó vậy và tất nhiên khi có hướng dẫn chỉ đường thì nó sẽ làm việc nhanh và hiệu quả hơn)
Sau khi các con bot viếng thăm website nó sẽ thống kê được số lượng page, thời gian viếng thăm page nhanh hay chậm, số lượng page không thể viếng thăm
2. Crawl Stats
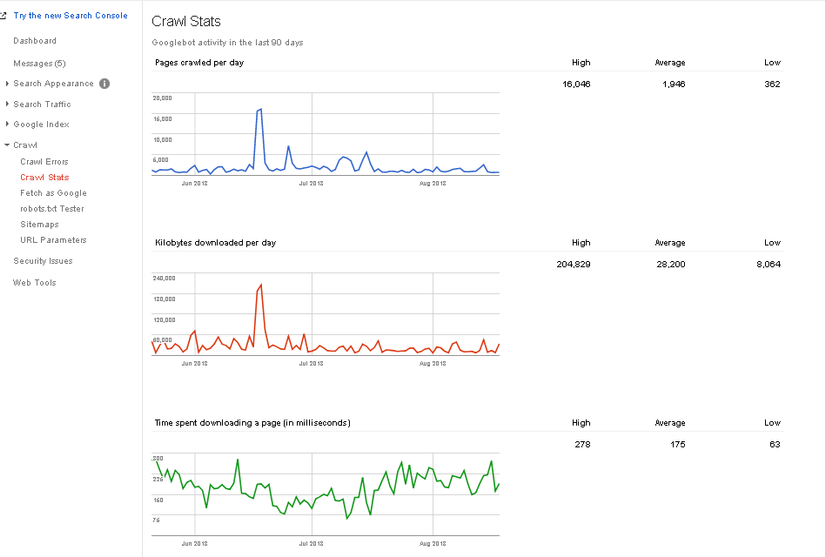
Webmaster cho ta thấy 3 loại thống kê về crawl:
- Thứ nhất là đồ thị thống kê số page được crawl từng ngày: số page được các bot thông kê theo ngày càng tăng thì càng tốt. Nó thể hiện rằng các bot rất quan tâm tới website của chúng ta và thường xuyên viếng thăm, cập nhật các thông tin mới nếu có trên website.
- Thứ hai là đồ thị thống kê số km mà con bot phải di chuyển từ vị trí máy chủ của Search Engine tới website của ta. Thống kê này càng giảm càng tốt, nó thể hiện việc website của bạn có đặt ở những nơi thuận tiện cho việc viếng thăm của bot hay không, nó cũng sẽ ảnh hưởng tới thứ tự tìm kiếm website của bạn. Ví dụ Website của bạn mong muốn hướng tới các khách hàng ở Mỹ, nhưng bạn lại đặt website ở cụm máy chủ Viet Nam. Đương nhiên các bot bên Mỹ sẽ mất nhiều quãng đường để di chuyển tới website, cũng như người dùng internet ở Mỹ sẽ mất nhiều thời gian khi truy cập website của bạn. Giả sử có 1 kết quả tìm kiếm của một site khác tương tự như site của bạn nhưng việc thu thập thông tin từ website kia nhanh hơn, chắc chắn đó là 1 tiêu chí để các Search Engine xem xét, đánh giá. Chính vì vậy bạn cũng nên chú trọng quan tâm tới việc đặt máy chủ của website ở đâu cho hợp lý.
- Thứ ba là đồ thị thống kê thời gian để bot thu thập thông tin xong trong 1 page, thống kê này càng giảm càng tốt. Nó thể hiện website của bạn đã tối ưu On page hay chưa, có nhiều internal, external link hay không? Thống số này cũng giúp chúng ta nhìn nhận để cải thiện dần tốc độ load/tải trang
3. Crawl Errors
Đây là thống kê tất cả các page lỗi trong quá trình bot viếng thăm website, Webmaster sẽ giúp chúng ta cảnh báo và fix những lỗi nếu có. Nếu website bạn có nhiều lỗi đó là điều không tốt cho SEO, cũng giống như người dùng internet trùy cập vào website của bạn, nhưng họ không tìm được thông tin họ mong muốn mà chỉ thấy hiển thị lỗi, chắc chắn họ sẽ ko viếng thăm website lần thứ hai

Có 3 loại lỗi phổ biến đó là 'Server error', 'Soft 404' và lỗi 'Not Found' và được thống kê rõ ràng qua 2 loại device Desktop hay Smartphone. Ngoài ra Webmaster Tool còn chỉ ra chi tiết đối với từng lỗi
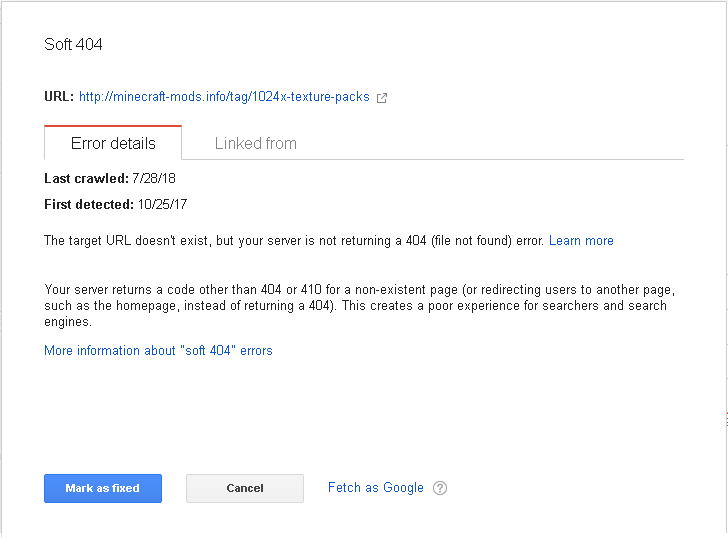
Dựa vào các thông tin mà Tool cung cấp sẽ giúp ta không mấy khó khăn fix được các lỗi này
Như vậy đến đây các bạn đã thấy được tầm quan trọng của Webmaster Tool và cách sử dụng của nó chưa ạ. Ở phần tiếp theo mình sẽ tiếp tục giới thiệu các chức năng còn lại của webmaster. Hy vọng các bạn sẽ follow
