Hướng dẫn về Dự báo chuỗi thời gian với ARIMA bằng Python 3
Giới thiệu Chuỗi thời gian cung cấp cơ hội để dự đoán các giá trị trong tương lai. Dựa trên các giá trị trước đó, chuỗi thời gian có thể được sử dụng để dự báo các xu hướng về kinh tế, thời tiết và quy hoạch năng lực, để đặt tên một vài. Các thuộc tính cụ thể của dữ liệu chuỗi thời gian có nghĩa ...
Giới thiệu
Chuỗi thời gian cung cấp cơ hội để dự đoán các giá trị trong tương lai. Dựa trên các giá trị trước đó, chuỗi thời gian có thể được sử dụng để dự báo các xu hướng về kinh tế, thời tiết và quy hoạch năng lực, để đặt tên một vài. Các thuộc tính cụ thể của dữ liệu chuỗi thời gian có nghĩa là các phương pháp thống kê chuyên ngành thường được yêu cầu.
Trong hướng dẫn này, chúng tôi sẽ hướng đến việc tạo ra các dự báo đáng tin cậy về chuỗi thời gian. Chúng ta sẽ bắt đầu bằng cách giới thiệu và thảo luận các khái niệm về tự tương quan, tình trạng chững lại và tính thời vụ, và tiến hành áp dụng một trong những phương pháp được sử dụng phổ biến nhất cho dự báo chuỗi thời gian, được gọi là ARIMA.
Một trong những phương thức có sẵn trong Python để lập mô hình và dự đoán các điểm tương lai của một chuỗi thời gian được gọi là SARIMAX, Viết tắt của Trung bình Di chuyển tích hợp theo mùa AutoRegressive với các biến hồi sinh eXogen. Ở đây, chúng tôi sẽ tập trung chủ yếu vào thành phần ARIMA, được sử dụng để phù hợp với dữ liệu chuỗi thời gian để hiểu rõ hơn và dự báo các điểm trong tương lai trong chuỗi thời gian.
Điều kiện tiên quyết
Hướng dẫn này sẽ bao gồm cách phân tích chuỗi thời gian trên máy tính để bàn cục bộ hoặc máy chủ từ xa. Làm việc với bộ dữ liệu lớn có thể là bộ nhớ chuyên sâu, vì vậy trong cả hai trường hợp, máy tính sẽ cần ít nhất 2GB bộ nhớ để thực hiện một số tính toán trong hướng dẫn này.
Để tận dụng tối đa hướng dẫn này, một số hiểu biết về chuỗi thời gian và thống kê có thể hữu ích.
Đối với hướng dẫn này, chúng tôi sẽ sử dụng Máy tính xách tay Jupyter để làm việc với dữ liệu. Nếu bạn chưa có, bạn nên theo dõi hướng dẫn cài đặt và thiết lập sổ ghi chép Jupyter cho Python 3.
Bước 1 - Cài đặt gói
Để thiết lập môi trường của chúng tôi cho dự báo chuỗi thời gian, trước tiên hãy chuyển sang môi trường lập trình cục bộ hoặc là môi trường lập trình dựa trên máy chủ:
cd environments . my_env/bin/activate
Từ đây, hãy tạo một thư mục mới cho dự án của chúng tôi. Chúng tôi sẽ gọi nó ARIMA và sau đó chuyển vào thư mục. Nếu bạn gọi tên dự án là một tên khác, hãy đảm bảo thay thế tên của bạn ARIMA trong suốt hướng dẫn
mkdir ARIMA cd ARIMA
Hướng dẫn này sẽ yêu cầu warnings, itertools, pandas, numpy, matplotlib và statsmodels thư viện. Các warnings và itertools các thư viện đi kèm với bộ thư viện Python chuẩn nên bạn không cần phải cài đặt chúng.
Giống như các gói Python khác, chúng tôi có thể cài đặt các yêu cầu này pip.
Bây giờ chúng ta có thể cài đặt pandas, statsmodelsvà gói vẽ dữ liệu matplotlib. Phụ thuộc của họ cũng sẽ được cài đặt:
pip install pandas numpy statsmodels matplotlib
Tại thời điểm này, chúng ta đã thiết lập để bắt đầu làm việc với các gói đã cài đặt.
Bước 2 - Nhập gói và tải dữ liệu
Để bắt đầu làm việc với dữ liệu của chúng tôi, chúng tôi sẽ khởi động Máy tính xách tay Jupyter:
jupyter notebook
Để tạo tệp sổ ghi chép mới, hãy chọn Mới > Python 3 từ menu kéo xuống trên cùng bên phải:
Thao tác này sẽ mở một sổ ghi chép.
Như là thực hành tốt nhất, bắt đầu bằng nhập các thư viện bạn sẽ cần ở đầu sổ ghi chép của mình:
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
Chúng tôi cũng đã xác định matplotlib Phong cách của fivethirtyeight cho âm mưu của chúng tôi.
Chúng tôi sẽ làm việc với một tập dữ liệu được gọi là "Khí quyển CO2 từ các mẫu không khí liên tục tại Đài quan sát Mauna Loa, Hawaii, Hoa Kỳ," thu thập các mẫu CO2 từ tháng 3 năm 1958 đến tháng 12 năm 2001. Chúng tôi có thể đưa vào dữ liệu này như sau:
data = sm.datasets.co2.load_pandas() y = data.data
Hãy xử lý trước dữ liệu của chúng tôi một chút trước khi tiến lên phía trước. Dữ liệu hàng tuần có thể phức tạp để làm việc vì đó là khoảng thời gian ngắn hơn, vì vậy, hãy sử dụng trung bình hàng tháng thay thế. Chúng tôi sẽ thực hiện chuyển đổi với resample chức năng. Để đơn giản, chúng tôi cũng có thể sử dụng [fillna() chức năng](https://www.codehub.vn/tim-kiem?q=fillna()%20ch%E1%BB%A9c%20n%C4%83ng&utm_medium=codehub.vn&utm_source=www.digitalocean.com&utm_campaign=guest_content&utm_term=https://www.digitalocean.com/community/tutorials/a-guide-to-time-series-forecasting-with-arima-in-python-3) để đảm bảo rằng chúng tôi không có giá trị thiếu trong chuỗi thời gian của chúng tôi.
# The 'MS' string groups the data in buckets by start of the month
y = y['co2'].resample('MS').mean()
# The term bfill means that we use the value before filling in missing values
y = y.fillna(y.bfill())
print(y)
Outputco2
1958-03-01 316.100000
1958-04-01 317.200000
1958-05-01 317.433333
...
2001-11-01 369.375000
2001-12-01 371.020000
Hãy khám phá chuỗi thời gian này e dưới dạng hình ảnh hóa dữ liệu:
y.plot(figsize=(15, 6)) plt.show()
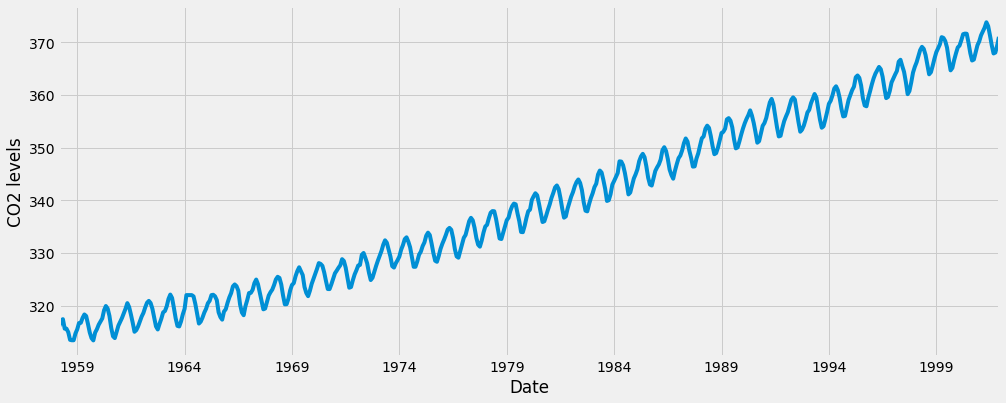
Một số mẫu có thể phân biệt xuất hiện khi chúng tôi vẽ dữ liệu. Chuỗi thời gian có một mô hình thời vụ rõ ràng, cũng như xu hướng tăng tổng thể.
Để tìm hiểu thêm về chuỗi thời gian xử lý trước, vui lòng tham khảo "Hướng dẫn về hiển thị chuỗi thời gian bằng Python 3", nơi các bước ở trên được mô tả chi tiết hơn.
Bây giờ chúng tôi đã chuyển đổi và khám phá dữ liệu của mình, hãy chuyển sang dự báo chuỗi thời gian với ARIMA.
Bước 3 - Mô hình chuỗi thời gian ARIMA
Một trong những phương pháp phổ biến nhất được sử dụng trong dự báo chuỗi thời gian được gọi là mô hình ARIMA, viết tắt của AutoregRtinh ý tôintegrated Moving Average. ARIMA là một mô hình có thể được trang bị cho dữ liệu chuỗi thời gian để hiểu rõ hơn hoặc dự đoán các điểm tương lai trong chuỗi.
Có ba số nguyên riêng biệt (p, d, q) được sử dụng để parametrize mô hình ARIMA. Do đó, các mô hình ARIMA được ký hiệu bằng ký hiệu ARIMA(p, d, q). Cùng với ba thông số này tính đến tính thời vụ, xu hướng và tiếng ồn trong các tập dữ liệu:
- p là tự động thoái lui một phần của mô hình. Nó cho phép chúng tôi kết hợp hiệu ứng của các giá trị trong quá khứ vào mô hình của chúng tôi. Trực giác, điều này sẽ tương tự như nói rằng nó có khả năng được ấm áp vào ngày mai nếu nó đã được ấm áp trong 3 ngày qua.
- d là tích hợp một phần của mô hình. Điều này bao gồm các thuật ngữ trong mô hình kết hợp số lượng chênh lệch (tức là số điểm thời gian trong quá khứ trừ đi giá trị hiện tại) để áp dụng cho chuỗi thời gian. Trực giác, điều này sẽ tương tự như nói rằng nó có khả năng là nhiệt độ tương tự vào ngày mai nếu sự khác biệt về nhiệt độ trong ba ngày qua là rất nhỏ.
- q là di chuyển trung bình một phần của mô hình. Điều này cho phép chúng tôi đặt lỗi của mô hình của chúng tôi dưới dạng kết hợp tuyến tính của các giá trị lỗi được quan sát tại các điểm thời gian trước đó trong quá khứ.
Khi xử lý các hiệu ứng theo mùa, chúng tôi sử dụng theo mùa ARIMA, được biểu thị là ARIMA(p,d,q)(P,D,Q)s. Đây, (p, d, q) là các thông số không theo mùa được mô tả ở trên, trong khi (P, D, Q) theo cùng định nghĩa nhưng được áp dụng cho thành phần theo mùa của chuỗi thời gian. Thuật ngữ s là chu kỳ của chuỗi thời gian (4 cho các khoảng thời gian hàng quý, 12 cho các giai đoạn hàng năm, v.v ...).
Phương pháp ARIMA theo mùa có thể xuất hiện khó khăn vì có nhiều tham số điều chỉnh liên quan. Trong phần tiếp theo, chúng tôi sẽ mô tả cách tự động hóa quy trình xác định tập hợp tham số tối ưu cho mô hình chuỗi thời gian ARIMA theo mùa.
Bước 4 - Lựa chọn tham số cho Mô hình chuỗi thời gian ARIMA
Khi tìm kiếm dữ liệu chuỗi thời gian phù hợp với mô hình ARIMA theo mùa, mục tiêu đầu tiên của chúng tôi là tìm các giá trị của ARIMA(p,d,q)(P,D,Q)s tối ưu hóa số liệu quan tâm. Có rất nhiều hướng dẫn và phương pháp hay nhất để đạt được mục tiêu này, nhưng sự tham số chính xác của các mô hình ARIMA có thể là một quá trình thủ công đòi hỏi phải có chuyên môn và thời gian của miền. Các ngôn ngữ lập trình thống kê khác như R cung cấp cách tự động để giải quyết vấn đề này, nhưng vẫn chưa được chuyển sang Python. Trong phần này, chúng tôi sẽ giải quyết vấn đề này bằng cách viết mã Python để lập trình chọn các giá trị tham số tối ưu cho ARIMA(p,d,q)(P,D,Q)s mô hình chuỗi thời gian.
Chúng tôi sẽ sử dụng "tìm kiếm lưới" để tìm kiếm lặp lại các kết hợp khác nhau của các thông số. Đối với mỗi kết hợp tham số, chúng tôi phù hợp với mô hình ARIMA theo mùa mới với SARIMAX() chức năng từ statsmodels và đánh giá chất lượng tổng thể của nó. Khi chúng tôi đã khám phá toàn bộ cảnh quan của các tham số, tập hợp các thông số tối ưu của chúng tôi sẽ là sản phẩm có hiệu suất tốt nhất cho các tiêu chí quan tâm của chúng tôi. Hãy bắt đầu bằng cách tạo ra sự kết hợp khác nhau của các tham số mà chúng tôi muốn đánh giá:
# Define the p, d and q parameters to take any value between 0 and 2
p = d = q = range(0, 2)
# Generate all different combinations of p, q and q triplets
pdq = list(itertools.product(p, d, q))
# Generate all different combinations of seasonal p, q and q triplets
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
OutputExamples of parameter combinations for Seasonal ARIMA...
SARIMAX: (0, 0, 1) x (0, 0, 1, 12)
SARIMAX: (0, 0, 1) x (0, 1, 0, 12)
SARIMAX: (0, 1, 0) x (0, 1, 1, 12)
SARIMAX: (0, 1, 0) x (1, 0, 0, 12)
Bây giờ chúng ta có thể sử dụng ba thông số được định nghĩa ở trên để tự động hóa quá trình đào tạo và đánh giá các mô hình ARIMA trên các kết hợp khác nhau. Trong thống kê và học máy, quá trình này được gọi là tìm kiếm lưới (hoặc tối ưu hóa siêu tham số) để lựa chọn mô hình.
Khi đánh giá và so sánh các mô hình thống kê được trang bị với các thông số khác nhau, mỗi mô hình có thể được xếp hạng với nhau dựa trên mức độ phù hợp của dữ liệu hoặc khả năng dự đoán chính xác các điểm dữ liệu trong tương lai. Chúng tôi sẽ sử dụng AIC (Giá trị tiêu chuẩn thông tin Akaike), được thuận tiện quay trở lại với các mô hình ARIMA được trang bị sử dụng statsmodels. Các AIC đo lường mức độ phù hợp của mô hình trong khi tính đến độ phức tạp tổng thể của mô hình. Một mô hình phù hợp với dữ liệu rất tốt trong khi sử dụng nhiều tính năng sẽ được chỉ định một điểm AIC lớn hơn một mô hình sử dụng ít tính năng hơn để đạt được cùng một mức độ phù hợp. Do đó, chúng tôi quan tâm đến việc tìm kiếm mô hình mang lại mức thấp nhất AIC giá trị.
Đoạn mã dưới đây lặp qua các kết hợp các tham số và sử dụng SARIMAX chức năng từ statsmodels để phù hợp với mô hình ARIMA theo mùa tương ứng. Ở đây, order đối số chỉ định (p, d, q) các thông số, trong khi seasonal_order đối số chỉ định (P, D, Q, S) thành phần theo mùa của mô hình ARIMA theo mùa. Sau khi lắp mỗi SARIMAX()mô hình, mã in ra tương ứng của nó AIC ghi bàn.
warnings.filterwarnings("ignore") # specify to ignore warning messages
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Bởi vì một số kết hợp tham số có thể dẫn đến lỗi chính xác số, chúng tôi đã vô hiệu hóa một cách rõ ràng các thông điệp cảnh báo để tránh tình trạng quá tải các thông báo cảnh báo. Những lỗi chính xác này cũng có thể dẫn đến lỗi và ném ngoại lệ, vì vậy, chúng tôi đảm bảo nắm bắt các ngoại lệ này và bỏ qua các kết hợp tham số gây ra các vấn đề này.
Mã ở trên sẽ mang lại kết quả sau, quá trình này có thể mất một chút thời gian:
OutputSARIMAX(0, 0, 0)x(0, 0, 1, 12) - AIC:6787.3436240402125 SARIMAX(0, 0, 0)x(0, 1, 1, 12) - AIC:1596.711172764114 SARIMAX(0, 0, 0)x(1, 0, 0, 12) - AIC:1058.9388921320026 SARIMAX(0, 0, 0)x(1, 0, 1, 12) - AIC:1056.2878315690562 SARIMAX(0, 0, 0)x(1, 1, 0, 12) - AIC:1361.6578978064144 SARIMAX(0, 0, 0)x(1, 1, 1, 12) - AIC:1044.7647912940095 ... ... ... SARIMAX(1, 1, 1)x(1, 0, 0, 12) - AIC:576.8647112294245 SARIMAX(1, 1, 1)x(1, 0, 1, 12) - AIC:327.9049123596742 SARIMAX(1, 1, 1)x(1, 1, 0, 12) - AIC:444.12436865161305 SARIMAX(1, 1, 1)x(1, 1, 1, 12) - AIC:277.7801413828764
Đầu ra của mã của chúng tôi cho thấy rằng SARIMAX(1, 1, 1)x(1, 1, 1, 12) mang lại mức thấp nhất AIC giá trị 277,78. Do đó, chúng tôi nên xem đây là lựa chọn tối ưu trong tất cả các mô hình mà chúng tôi đã xem xét.
Bước 5 - Lắp một mẫu dòng thời gian ARIMA
Sử dụng tìm kiếm lưới, chúng tôi đã xác định tập hợp các tham số tạo mô hình phù hợp nhất cho dữ liệu chuỗi thời gian của chúng tôi. Chúng ta có thể tiến hành phân tích mô hình cụ thể này sâu hơn.
Chúng ta sẽ bắt đầu bằng cách cắm các giá trị tham số tối ưu vào một giá trị mới SARIMAX mô hình:
mod = sm.tsa.statespace.SARIMAX(y,
order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print(results.summary().tables[1])
Output==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.3182 0.092 3.443 0.001 0.137 0.499
ma.L1 -0.6255 0.077 -8.165 0.000 -0.776 -0.475
ar.S.L12 0.0010 0.001 1.732 0.083 -0.000 0.002
ma.S.L12 -0.8769 0.026 -33.811 0.000 -0.928 -0.826
sigma2 0.0972 0.004 22.634 0.000 0.089 0.106
==============================================================================
Các summary thuộc tính kết quả từ đầu ra của SARIMAX trả lại một lượng thông tin đáng kể, nhưng chúng tôi sẽ tập trung sự chú ý của chúng tôi vào bảng các hệ số. Các coef cột hiển thị trọng số (tức là tầm quan trọng) của mỗi đối tượng và cách mỗi đối tượng tác động đến chuỗi thời gian. Các P>|z| cột thông báo cho chúng tôi về tầm quan trọng của từng trọng lượng của đối tượng địa lý. Ở đây, mỗi trọng số có giá trị p thấp hơn hoặc gần 0.05, vì vậy nó là hợp lý để giữ lại tất cả chúng trong mô hình của chúng tôi.
Khi lắp các mô hình ARIMA theo mùa (và bất kỳ mô hình nào khác cho vấn đề đó), điều quan trọng là chạy chẩn đoán mô hình để đảm bảo rằng không có giả định nào do mô hình thực hiện đã bị vi phạm. Các plot_diagnostics đối tượng cho phép chúng tôi nhanh chóng tạo chẩn đoán mô hình và điều tra bất kỳ hành vi bất thường nào.
results.plot_diagnostics(figsize=(15, 12)) plt.show()
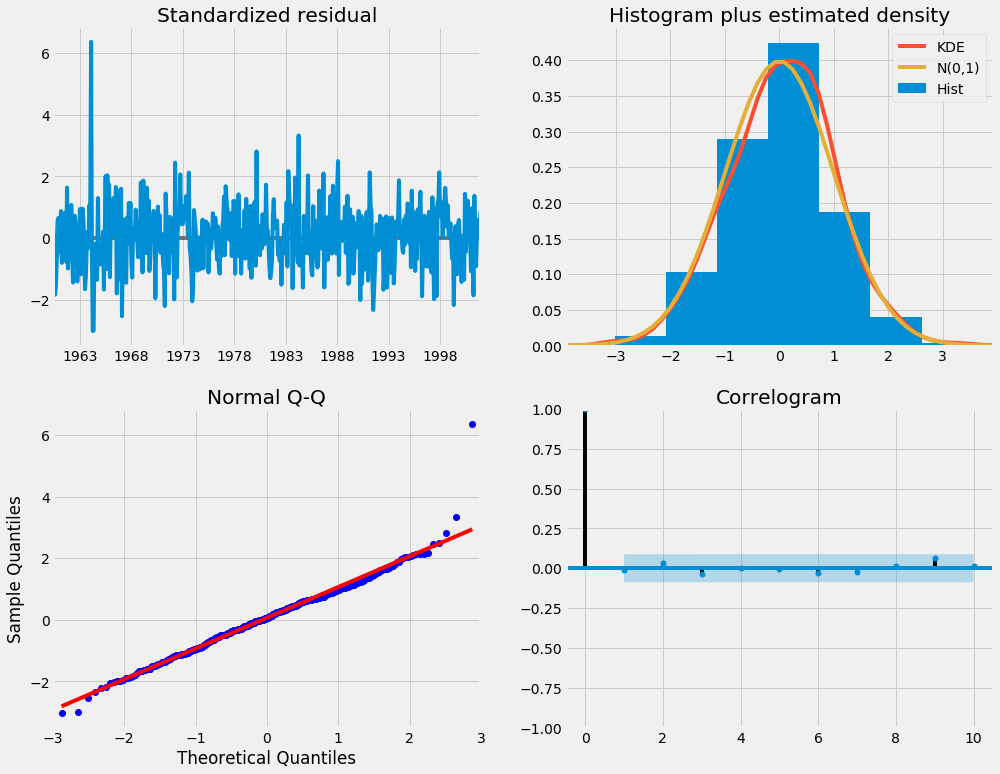
Mối quan tâm chính của chúng tôi là đảm bảo rằng số dư của mô hình của chúng tôi là không tương quan và thường được phân phối với số không trung bình. Nếu mô hình ARIMA theo mùa không đáp ứng các đặc tính này, thì đó là dấu hiệu tốt cho thấy nó có thể được cải thiện hơn nữa.
Trong trường hợp này, chẩn đoán mô hình của chúng tôi cho thấy rằng các số dư mô hình thường được phân phối dựa trên những điều sau:
-
Trong cốt truyện trên cùng bên phải, chúng ta thấy rằng màu đỏ KDE dòng theo sát với N(0,1) dòng (nơi N(0,1)) là ký pháp chuẩn cho phân bố chuẩn với giá trị trung bình 0 và độ lệch chuẩn của 1). Đây là một dấu hiệu tốt cho thấy các số dư thường được phân phối.
-
Các qq-plot ở phía dưới bên trái cho thấy sự phân bố theo thứ tự các số dư (dấu chấm màu xanh) theo xu hướng tuyến tính của các mẫu được lấy từ phân bố chuẩn chuẩn với N(0, 1). Một lần nữa, đây là một dấu hiệu mạnh mẽ rằng các số dư thường được phân phối.
- Các số dư theo thời gian (lô trên cùng bên trái) không hiển thị bất kỳ thời vụ rõ ràng nào và có vẻ là nhiễu trắng. Điều này được xác nhận bởi biểu đồ tự tương quan (tức là biểu đồ tương quan) ở góc dưới bên phải, cho thấy rằng các chuỗi dư thời gian có tương quan thấp với các phiên bản bị trễ.
Những quan sát đó dẫn chúng ta đến kết luận rằng mô hình của chúng tôi tạo ra sự phù hợp thỏa đáng có thể giúp chúng tôi hiểu dữ liệu chuỗi thời gian của mình và dự đoán các giá trị trong tương lai.
Mặc dù chúng tôi có sự phù hợp thỏa đáng, một số thông số của mô hình ARIMA theo mùa của chúng tôi có thể được thay đổi để cải thiện mô hình của chúng tôi phù hợp. Ví dụ: tìm kiếm lưới của chúng tôi chỉ được coi là một tập hợp các kết hợp tham số bị giới hạn, vì vậy chúng tôi có thể tìm thấy các mô hình tốt hơn nếu chúng tôi mở rộng tìm kiếm lưới.
Bước 6 - Dự báo hợp lệ
Chúng tôi đã có được một mô hình cho chuỗi thời gian của chúng tôi mà bây giờ có thể được sử dụng để sản xuất dự báo. Chúng tôi bắt đầu bằng cách so sánh các giá trị được dự đoán với các giá trị thực của chuỗi thời gian, điều này sẽ giúp chúng tôi hiểu tính chính xác của các dự báo của chúng tôi. Các get_prediction() và conf_int() các thuộc tính cho phép chúng tôi lấy các giá trị và khoảng tin cậy liên quan cho dự báo của chuỗi thời gian.
pred = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic=False)
pred_ci = pred.conf_int()
Đoạn mã trên yêu cầu dự báo bắt đầu vào tháng 1 năm 1998.
Các dynamic=False đối số đảm bảo rằng chúng tôi tạo ra các dự báo trước một bước, có nghĩa là dự báo tại mỗi điểm được tạo bằng lịch sử đầy đủ cho đến thời điểm đó.
Chúng tôi có thể vẽ các giá trị thực tế và dự báo của chuỗi thời gian CO2 để đánh giá mức độ hiệu quả của chúng tôi. Lưu ý cách chúng tôi phóng to vào cuối chuỗi thời gian bằng cách cắt chỉ mục ngày.
ax = y['1990':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead Forecast', alpha=.7)
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()
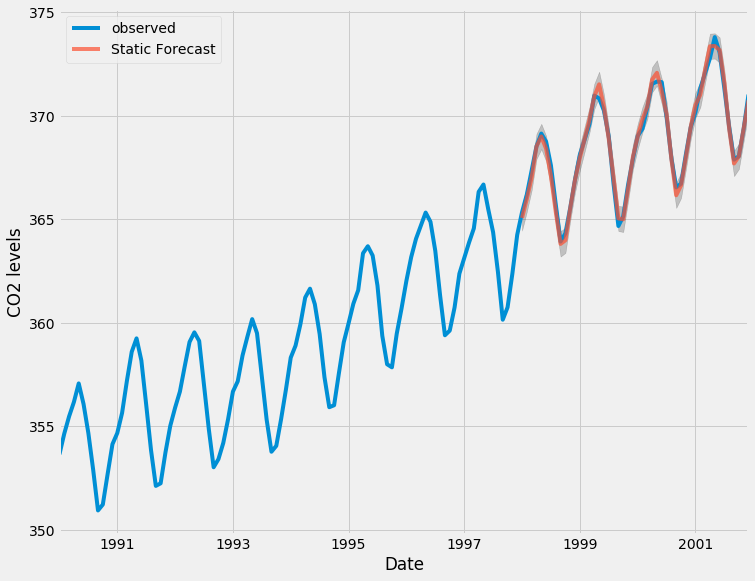
Nhìn chung, các dự báo của chúng tôi phù hợp với các giá trị thực sự rất tốt, cho thấy xu hướng tăng tổng thể.
Nó cũng hữu ích để định lượng tính chính xác của các dự báo của chúng tôi. Chúng tôi sẽ sử dụng MSE (Mean Squared Error), tóm tắt lỗi trung bình của các dự báo của chúng tôi. Đối với mỗi giá trị được dự đoán, chúng tôi tính toán khoảng cách của nó với giá trị thực và căn chỉnh kết quả. Các kết quả cần phải được bình phương sao cho các khác biệt dương / âm không hủy lẫn nhau khi chúng tôi tính trung bình tổng thể.
y_forecasted = pred.predicted_mean
y_truth = y['1998-01-01':]
# Compute the mean square error
mse = ((y_forecasted - y_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))
OutputThe Mean Squared Error of our forecasts is 0.07
MSE của dự báo trước một bước của chúng tôi mang lại giá trị 0.07, đó là rất thấp vì nó gần bằng 0. Một MSE 0 sẽ ước tính dự đoán các quan sát của tham số với độ chính xác hoàn hảo, đó sẽ là một kịch bản lý tưởng nhưng nó không thể xảy ra.
Tuy nhiên, một đại diện tốt hơn về sức mạnh dự báo thực sự của chúng ta có thể thu được bằng cách sử dụng các dự báo động. Trong trường hợp này, chúng tôi chỉ sử dụng thông tin từ chuỗi thời gian đến một điểm nhất định và sau đó, dự báo được tạo bằng cách sử dụng các giá trị từ các điểm thời gian dự báo trước đó.
Trong đoạn mã dưới đây, chúng tôi xác định để bắt đầu tính toán dự báo năng động và khoảng tin cậy từ tháng 1 năm 1998 trở đi.
pred_dynamic = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic=True, full_results=True)
pred_dynamic_ci = pred_dynamic.conf_int()
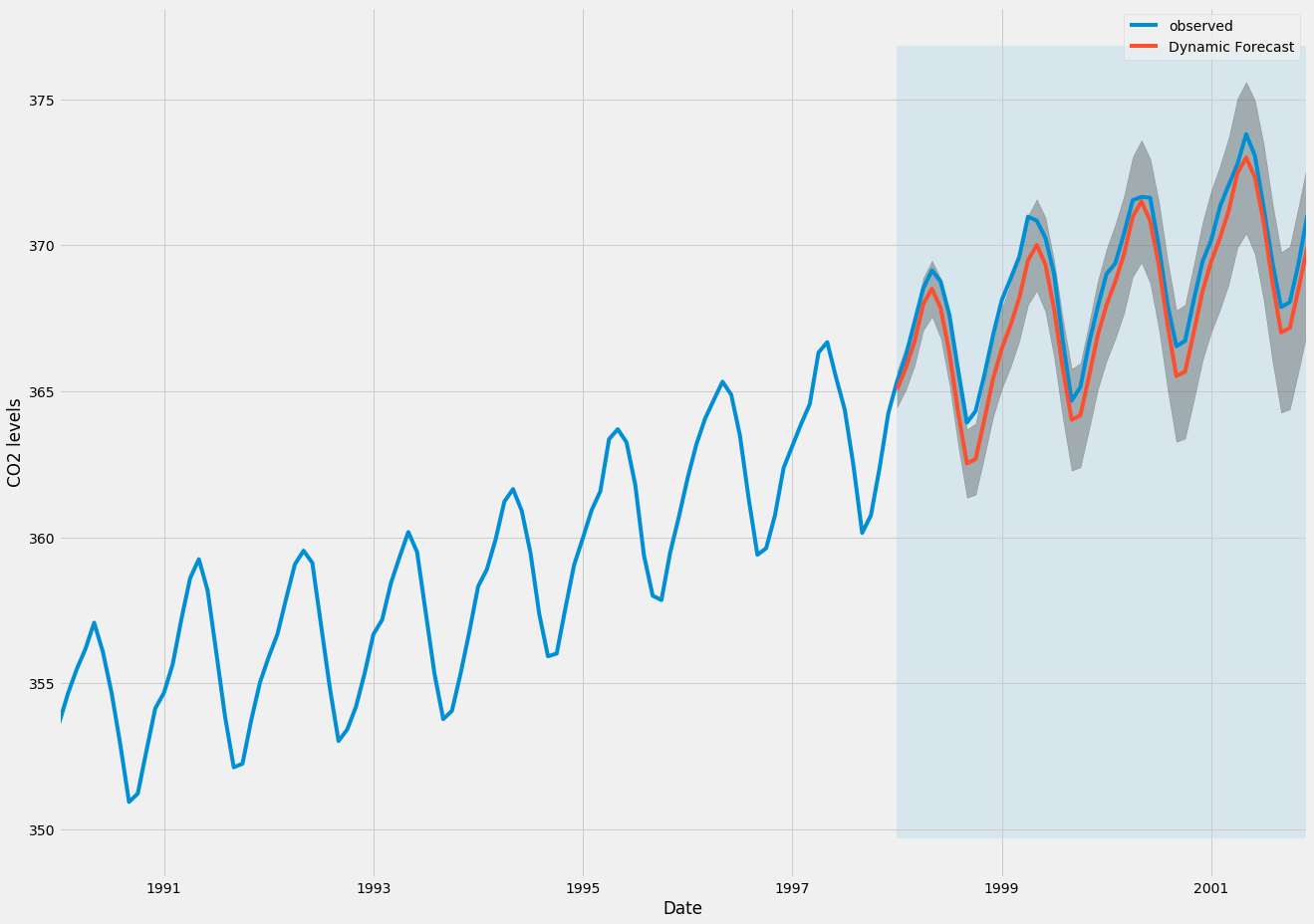
Vẽ các giá trị được quan sát và dự đoán của chuỗi thời gian, chúng tôi thấy rằng dự báo tổng thể là chính xác ngay cả khi sử dụng dự báo động. Tất cả các giá trị được dự báo (đường màu đỏ) phù hợp chặt chẽ với sự thật mặt đất (đường màu xanh) và nằm trong khoảng tin cậy của dự báo của chúng tôi.
ax = y['1990':].plot(label='observed', figsize=(20, 15))
pred_dynamic.predicted_mean.plot(label='Dynamic Forecast', ax=ax)
ax.fill_between(pred_dynamic_ci.index,
pred_dynamic_ci.iloc[:, 0],
pred_dynamic_ci.iloc[:, 1], color='k', alpha=.25)
ax.fill_betweenx(ax.get_ylim(), pd.to_datetime('1998-01-01'), y.index[-1],
alpha=.1, zorder=-1)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()
Một lần nữa, chúng tôi định lượng hiệu suất dự báo của các dự báo của chúng tôi bằng cách tính toán MSE:
# Extract the predicted and true values of our time series
y_forecasted = pred_dynamic.predicted_mean
y_truth = y['1998-01-01':]
# Compute the mean square error
mse = ((y_forecasted - y_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))
OutputThe Mean Squared Error of our forecasts is 1.01
Các giá trị dự đoán thu được từ các dự báo động mang lại một MSE là 1,01. Con số này cao hơn một chút so với trước một bước, được dự đoán là chúng tôi dựa vào dữ liệu ít lịch sử hơn từ chuỗi thời gian.
Cả dự đoán một bước và dự báo động đều xác nhận rằng mô hình chuỗi thời gian này là hợp lệ. Tuy nhiên, phần lớn sự quan tâm xung quanh chuỗi thời gian dự báo là khả năng dự báo giá trị tương lai trước thời hạn.
Bước 7 - Sản xuất và hình dung dự báo
Trong bước cuối cùng của hướng dẫn này, chúng tôi mô tả cách tận dụng mô hình chuỗi thời gian ARIMA theo mùa của chúng tôi để dự báo các giá trị trong tương lai. Các get_forecast() thuộc tính của đối tượng chuỗi thời gian của chúng tôi có thể tính toán các giá trị được dự báo cho một số bước được chỉ định phía trước.
# Get forecast 500 steps ahead in future pred_uc = results.get_forecast(steps=500) # Get confidence intervals of forecasts pred_ci = pred_uc.conf_int()
Chúng ta có thể sử dụng đầu ra của mã này để vẽ chuỗi thời gian và dự báo các giá trị tương lai của nó.
ax = y.plot(label='observed', figsize=(20, 15))
pred_uc.predicted_mean.plot(ax=ax, label='Forecast')
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.25)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()
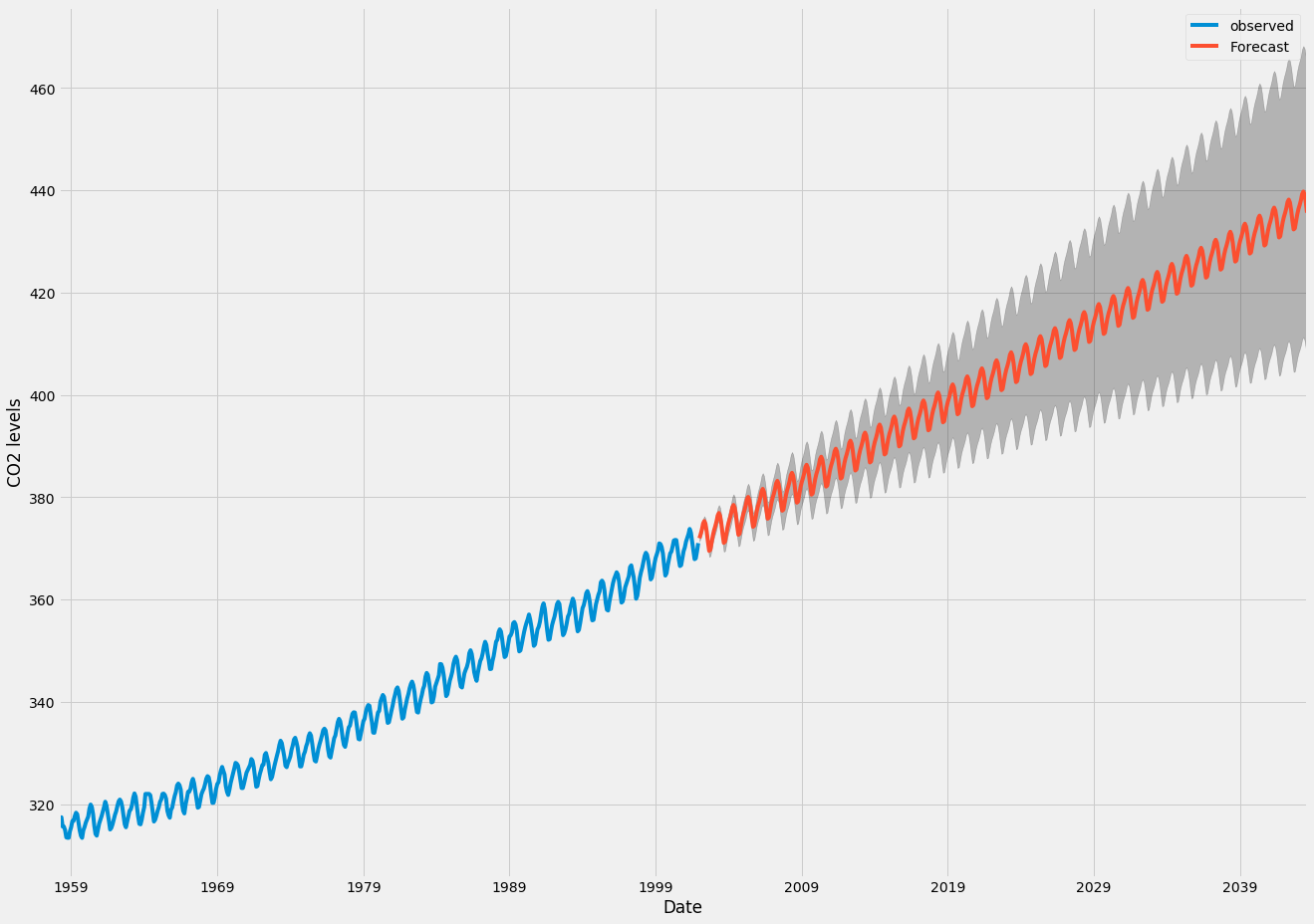
Cả dự báo và khoảng tin cậy liên quan mà chúng tôi đã tạo giờ đây có thể được sử dụng để hiểu rõ hơn về chuỗi thời gian và thấy trước những gì mong đợi. Dự báo của chúng tôi cho thấy rằng chuỗi thời gian dự kiến sẽ tiếp tục tăng với tốc độ ổn định.
Như chúng tôi dự báo xa hơn trong tương lai, chúng tôi tự nhiên trở nên kém tự tin hơn trong các giá trị của mình. Điều này được phản ánh bởi các khoảng tin cậy do mô hình của chúng tôi tạo ra, chúng tăng trưởng lớn hơn khi chúng tôi tiến xa hơn trong tương lai.
Phần kết luận
Trong hướng dẫn này, chúng tôi đã mô tả cách triển khai mô hình ARIMA theo mùa trong Python. Chúng tôi đã sử dụng rộng rãi pandas và statsmodels các thư viện và cho thấy cách chạy chẩn đoán mô hình, cũng như cách tạo dự báo về chuỗi thời gian CO2.
Dưới đây là một vài điều khác bạn có thể thử:
- Thay đổi ngày bắt đầu dự báo động của bạn để xem điều này ảnh hưởng như thế nào đến chất lượng tổng thể của dự báo của bạn.
- Hãy thử kết hợp nhiều thông số hơn để xem liệu bạn có thể cải thiện mức độ phù hợp của mô hình của mình hay không.
- Chọn một chỉ số khác để chọn mô hình tốt nhất. Ví dụ: chúng tôi đã sử dụng AIC để tìm mô hình tốt nhất, nhưng thay vào đó, bạn có thể tìm cách tối ưu hóa sai số trung bình ngoài mẫu.
Để thực hành thêm, bạn cũng có thể thử tải một tập dữ liệu chuỗi thời gian khác để tạo dự đoán của riêng mình.
