Hướng dẫn về hiển thị chuỗi thời gian bằng Python 3
Giới thiệu Phân tích chuỗi thời gian thuộc về một nhánh của Thống kê liên quan đến việc nghiên cứu dữ liệu được đặt hàng, thường là thời gian. Khi được áp dụng phù hợp, phân tích chuỗi thời gian có thể tiết lộ các xu hướng không mong muốn, trích xuất các thống kê hữu ích và thậm chí dự báo xu ...
Giới thiệu
Phân tích chuỗi thời gian thuộc về một nhánh của Thống kê liên quan đến việc nghiên cứu dữ liệu được đặt hàng, thường là thời gian. Khi được áp dụng phù hợp, phân tích chuỗi thời gian có thể tiết lộ các xu hướng không mong muốn, trích xuất các thống kê hữu ích và thậm chí dự báo xu hướng trong tương lai. Vì những lý do này, nó được áp dụng trên nhiều lĩnh vực bao gồm kinh tế, dự báo thời tiết, và quy hoạch năng lực, để đặt tên một vài.
Trong hướng dẫn này, chúng tôi sẽ giới thiệu một số kỹ thuật phổ biến được sử dụng trong phân tích chuỗi thời gian và đi qua các bước lặp lại cần thiết để thao tác, trực quan hóa dữ liệu chuỗi thời gian.
Điều kiện tiên quyết
Hướng dẫn này sẽ bao gồm cách phân tích chuỗi thời gian trên máy tính để bàn cục bộ hoặc máy chủ từ xa. Làm việc với bộ dữ liệu lớn có thể là bộ nhớ chuyên sâu, vì vậy trong cả hai trường hợp, máy tính sẽ cần ít nhất 2GB bộ nhớ để thực hiện một số tính toán trong hướng dẫn này.
Đối với hướng dẫn này, chúng tôi sẽ sử dụng Máy tính xách tay Jupyter để làm việc với dữ liệu. Nếu bạn chưa có, bạn nên theo dõi hướng dẫn cài đặt và thiết lập sổ ghi chép Jupyter cho Python 3.
Bước 1 - Cài đặt gói
Chúng tôi sẽ tận dụng pandas thư viện, cung cấp rất nhiều tính linh hoạt khi thao tác dữ liệu và statsmodels thư viện, cho phép chúng tôi thực hiện tính toán thống kê bằng Python. Được sử dụng cùng nhau, hai thư viện này mở rộng Python để cung cấp chức năng lớn hơn và tăng đáng kể bộ công cụ phân tích của chúng tôi.
Giống như các gói Python khác, chúng ta có thể cài đặt pandas và statsmodels với pip. Đầu tiên, hãy chuyển sang môi trường lập trình cục bộ hoặc môi trường lập trình dựa trên máy chủ của chúng tôi:
cd environments . my_env/bin/activate
Từ đây, hãy tạo một thư mục mới cho dự án của chúng tôi. Chúng tôi sẽ gọi nó timeseries và sau đó chuyển vào thư mục. Nếu bạn gọi tên dự án là một tên khác, hãy đảm bảo thay thế tên của bạn timeseries trong suốt hướng dẫn
mkdir timeseries cd timeseries
Bây giờ chúng ta có thể cài đặt pandas, statsmodelsvà gói vẽ dữ liệu matplotlib. Phụ thuộc của họ cũng sẽ được cài đặt:
pip install pandas statsmodels matplotlib
Tại thời điểm này, chúng tôi đã thiết lập để bắt đầu làm việc với pandas và statsmodels.
Bước 2 - Đang tải dữ liệu chuỗi thời gian
Để bắt đầu làm việc với dữ liệu của chúng tôi, chúng tôi sẽ khởi động Máy tính xách tay Jupyter:
jupyter notebook
Để tạo tệp sổ ghi chép mới, hãy chọn Mới > Python 3 từ menu kéo xuống trên cùng bên phải:
Thao tác này sẽ mở một sổ ghi chép cho phép chúng tôi tải các thư viện cần thiết (lưu ý các ký hiệu chuẩn được sử dụng để tham khảo pandas, matplotlib và statsmodels). Ở đầu sổ ghi chép của chúng tôi, chúng ta nên viết như sau:
import pandas as pd import statsmodels.api as sm import matplotlib.pyplot as plt
Sau mỗi khối mã trong hướng dẫn này, bạn nên nhập ALT + ENTER để chạy mã và di chuyển vào một khối mã mới trong sổ ghi chép của bạn.
Thuận tiện, statsmodels đi kèm với bộ dữ liệu tích hợp, vì vậy chúng tôi có thể tải tập dữ liệu chuỗi thời gian thẳng vào bộ nhớ.
Chúng tôi sẽ làm việc với một tập dữ liệu được gọi là "Khí quyển CO2 từ các mẫu không khí liên tục tại Đài quan sát Mauna Loa, Hawaii, Hoa Kỳ," thu thập các mẫu CO2 từ tháng 3 năm 1958 đến tháng 12 năm 2001. Chúng tôi có thể đưa vào dữ liệu này như sau:
data = sm.datasets.co2.load_pandas() co2 = data.data
Hãy kiểm tra xem 5 dòng đầu tiên của dữ liệu chuỗi thời gian của chúng ta trông như thế nào:
print(co2.head(5)) Output co2 1958-03-29 316.1 1958-04-05 317.3 1958-04-12 317.6 1958-04-19 317.5 1958-04-26 316.4
Với các gói của chúng tôi đã nhập và bộ dữ liệu CO2 sẵn sàng để đi, chúng tôi có thể chuyển sang lập chỉ mục dữ liệu của mình.
Bước 3 - Lập chỉ mục với dữ liệu chuỗi thời gian
Bạn có thể nhận thấy rằng các ngày đã được đặt làm chỉ mục của pandas Khung dữ liệu. Khi làm việc với dữ liệu chuỗi thời gian bằng Python, chúng ta nên đảm bảo rằng ngày tháng được sử dụng làm chỉ mục, vì vậy hãy đảm bảo luôn kiểm tra điều đó, chúng ta có thể thực hiện bằng cách chạy như sau:
co2.index
OutputDatetimeIndex(['1958-03-29', '1958-04-05', '1958-04-12', '1958-04-19',
'1958-04-26', '1958-05-03', '1958-05-10', '1958-05-17',
'1958-05-24', '1958-05-31',
...
'2001-10-27', '2001-11-03', '2001-11-10', '2001-11-17',
'2001-11-24', '2001-12-01', '2001-12-08', '2001-12-15',
'2001-12-22', '2001-12-29'],
dtype='datetime64[ns]', length=2284, freq='W-SAT')
Các dtype=datetime[ns] trường xác nhận rằng chỉ mục của chúng tôi được tạo từ các đối tượng dấu ngày, trong khi length=2284 và freq='W-SAT' cho chúng tôi biết rằng chúng tôi có 2.284 tem ngày hàng tuần bắt đầu vào thứ Bảy.
Dữ liệu hàng tuần có thể khó thực hiện, vì vậy, hãy sử dụng mức trung bình hàng tháng của chuỗi thời gian của chúng tôi thay thế. Điều này có thể thu được bằng cách sử dụng thuận tiện resample chức năng, cho phép chúng tôi nhóm chuỗi thời gian thành các nhóm (1 tháng), áp dụng chức năng trên mỗi nhóm (trung bình) và kết hợp kết quả (một hàng cho mỗi nhóm).
y = co2['co2'].resample('MS').mean()
Ở đây, thuật ngữ MS có nghĩa là chúng tôi nhóm dữ liệu vào nhóm theo tháng và đảm bảo rằng chúng tôi đang sử dụng phần đầu của mỗi tháng làm dấu thời gian:
y.head(5) Output1958-03-01 316.100 1958-04-01 317.200 1958-05-01 317.120 1958-06-01 315.800 1958-07-01 315.625 Freq: MS, Name: co2, dtype: float64
Một tính năng thú vị của pandas là khả năng xử lý các chỉ mục tem ngày, cho phép chúng tôi nhanh chóng cắt dữ liệu của mình. Ví dụ: chúng tôi có thể chia tập dữ liệu của mình để chỉ truy xuất các điểm dữ liệu sau năm 1990:
y['1990':]
Output1990-01-01 353.650
1990-02-01 354.650
...
2001-11-01 369.375
2001-12-01 371.020
Freq: MS, Name: co2, dtype: float64
Hoặc, chúng tôi có thể cắt tập dữ liệu của mình để chỉ truy xuất điểm dữ liệu trong khoảng tháng 10 1995 và tháng 10 1996:
y['1995-10-01':'1996-10-01'] Output1995-10-01 357.850 1995-11-01 359.475 1995-12-01 360.700 1996-01-01 362.025 1996-02-01 363.175 1996-03-01 364.060 1996-04-01 364.700 1996-05-01 365.325 1996-06-01 364.880 1996-07-01 363.475 1996-08-01 361.320 1996-09-01 359.400 1996-10-01 359.625 Freq: MS, Name: co2, dtype: float64
Với dữ liệu của chúng tôi được lập chỉ mục phù hợp để làm việc với dữ liệu thời gian, chúng tôi có thể di chuyển lên các giá trị xử lý có thể bị thiếu.
Bước 4 - Xử lý các giá trị còn thiếu trong dữ liệu chuỗi thời gian
Dữ liệu thế giới thực có xu hướng lộn xộn. Như chúng ta có thể thấy từ cốt truyện, nó không phải là không phổ biến cho dữ liệu chuỗi thời gian để chứa các giá trị bị thiếu. Cách đơn giản nhất để kiểm tra những điều đó là bằng cách trực tiếp vẽ sơ đồ dữ liệu hoặc bằng cách sử dụng lệnh dưới đây sẽ tiết lộ dữ liệu bị thiếu trong ouput:
y.isnull().sum() Output5
Đầu ra này cho chúng ta biết rằng có 5 tháng với các giá trị bị thiếu trong chuỗi thời gian của chúng ta.
Nói chung, chúng ta nên "điền vào" các giá trị bị thiếu nếu chúng không quá nhiều để chúng tôi không có khoảng trống trong dữ liệu. Chúng ta có thể làm điều này trong pandas sử dụng [fillna() chỉ huy](https://www.codehub.vn/tim-kiem?q=fillna()%20ch%E1%BB%89%20huy&utm_medium=codehub.vn&utm_source=www.digitalocean.com&utm_campaign=guest_content&utm_term=https://www.digitalocean.com/community/tutorials/a-guide-to-time-series-visualization-with-python-3). Để đơn giản, chúng ta có thể điền vào các giá trị bị thiếu với giá trị không null gần nhất trong chuỗi thời gian của chúng ta, mặc dù điều quan trọng cần lưu ý là một phương tiện cán đôi khi sẽ thích hợp hơn.
y = y.fillna(y.bfill())
Với các giá trị bị thiếu được điền vào, chúng ta có thể kiểm tra lại xem có tồn tại bất kỳ giá trị null nào để đảm bảo rằng hoạt động của chúng ta đã hoạt động:
y.isnull().sum() Output0
Sau khi thực hiện các hoạt động này, chúng tôi thấy rằng chúng tôi đã điền thành công tất cả các giá trị bị thiếu trong chuỗi thời gian của chúng tôi.
Bước 5 - Hiển thị dữ liệu chuỗi thời gian
Khi làm việc với dữ liệu chuỗi thời gian, rất nhiều dữ liệu có thể được tiết lộ thông qua việc hình dung nó. Một vài điều cần chú ý là:
- tính mùa vụ: dữ liệu có hiển thị một mô hình định kỳ rõ ràng không?
- khuynh hướng: dữ liệu có tuân theo độ dốc lên hoặc xuống không nhất quán không?
- tiếng ồn: có bất kỳ điểm ngoại lệ hoặc giá trị bị thiếu nào không phù hợp với phần còn lại của dữ liệu không?
Chúng ta có thể sử dụng pandas bao bọc xung quanh matplotlib API để hiển thị một lô của tập dữ liệu của chúng tôi:
y.plot(figsize=(15, 6)) plt.show()
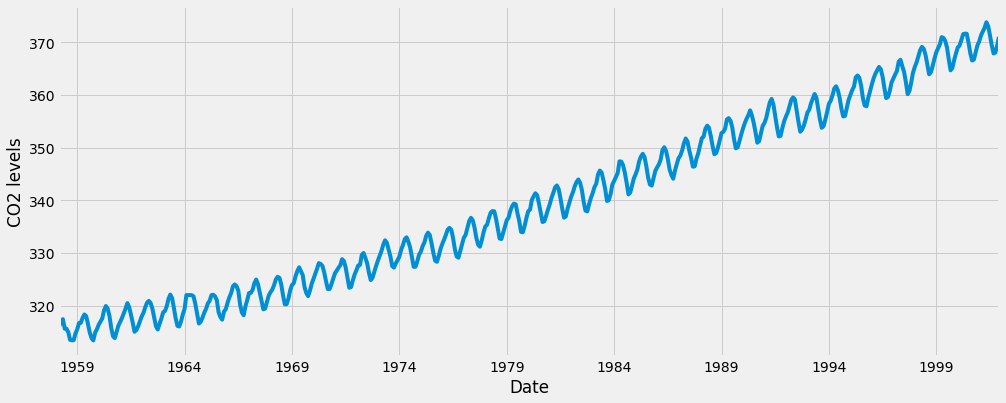
Một số mẫu có thể phân biệt xuất hiện khi chúng tôi vẽ dữ liệu. Chuỗi thời gian có một mô hình thời vụ rõ ràng, cũng như xu hướng tăng tổng thể. Chúng ta cũng có thể hình dung dữ liệu của chúng ta bằng cách sử dụng một phương thức gọi là phân tách chuỗi thời gian. Như tên gọi của nó, phân tách chuỗi thời gian cho phép chúng ta phân hủy chuỗi thời gian của mình thành ba thành phần riêng biệt: xu hướng, tính thời vụ và tiếng ồn.
May mắn thay, statsmodels cung cấp tiện lợi seasonal_decompose chức năng để thực hiện phân hủy theo mùa ra khỏi hộp. Nếu bạn quan tâm đến việc tìm hiểu thêm, tham chiếu cho việc thực hiện ban đầu của nó có thể được tìm thấy trong bài viết sau, "STL: Thủ tục phân hủy theo mùa-xu hướng dựa trên sự lo lắng. "
Kịch bản dưới đây cho thấy cách thực hiện phân tích theo chuỗi theo thời gian trong Python. Theo mặc định, seasonal_decompose trả về một con số có kích thước tương đối nhỏ, do đó, hai dòng đầu tiên của đoạn mã này đảm bảo rằng con số đầu ra đủ lớn để chúng ta hình dung.
from pylab import rcParams rcParams['figure.figsize'] = 11, 9 decomposition = sm.tsa.seasonal_decompose(y, model='additive') fig = decomposition.plot() plt.show()
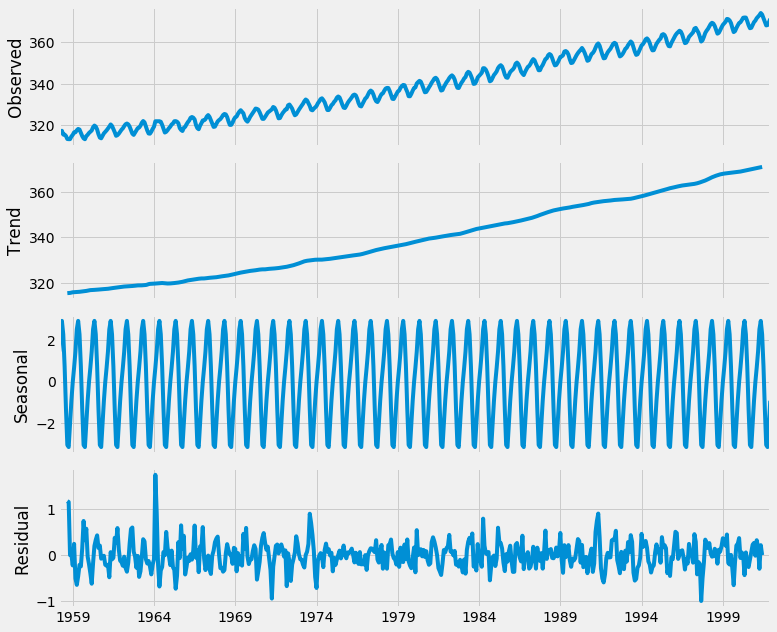
Sử dụng phân tích chuỗi thời gian giúp dễ dàng xác định nhanh hơn giá trị trung bình hoặc biến thể thay đổi trong dữ liệu. Cốt truyện trên rõ ràng cho thấy xu hướng tăng của dữ liệu của chúng tôi, cùng với tính thời vụ hàng năm của nó. Đây có thể được sử dụng để hiểu kết cấu trong chuỗi thời gian của chúng tôi. Trực giác đằng sau phân tách chuỗi thời gian là rất quan trọng, như nhiều phương pháp dự báo xây dựng dựa trên khái niệm phân hủy có cấu trúc này để tạo ra dự báo.
Phần kết luận
Nếu bạn đã làm theo hướng dẫn này, bây giờ bạn có kinh nghiệm trực quan hóa và thao tác dữ liệu chuỗi thời gian bằng Python.
Để cải thiện thêm kỹ năng của bạn, bạn có thể tải trong tập dữ liệu khác và lặp lại tất cả các bước trong hướng dẫn này. Ví dụ: bạn có thể muốn đọc tệp CSV bằng cách sử dụng pandas thư viện hoặc sử dụng sunspots tập dữ liệu được tải sẵn với statsmodels thư viện: data = sm.datasets.sunspots.load_pandas().data.
