Introduction of Natural Language Processing
Definition Natural language processing is a field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human languages. As such, NLP is related to the area of human–computer interaction. Many challenges in NLP involve: ...
Definition
Natural language processing is a field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human languages. As such, NLP is related to the area of human–computer interaction. Many challenges in NLP involve: natural language understanding, enabling computers to derive meaning from human or natural language input; and others involve natural language generation. [Wikipedia]
Natural Language Processing is a field that covers computer understanding and manipulation of human language, and it’s ripe with possibilities for newsgathering,” Anthony Pesce said in Natural Language Processing in the kitchen. “You usually hear about it in the context of analyzing large pools of legislation or other document sets, attempting to discover patterns or root out corruption. [Algorithmia]
Natural Language Processing (NLP) refers to AI method of communicating with an intelligent systems using a natural language such as English. [Tutorialspoint]
What is Natural Language Processing?
NLP is a branch of artificial intelligence that deals with the analysis, understanding and generating languages that people use naturally to communicate with computers in spoken and written contexts using natural human language instead of programming languages.
Application Development NLP is challenging because computers generally require people to "speak" to them in a programming language that is accurate, clear and highly structured or possibly through a limited number of clearly announced by voice commands. Human speech is not always accurate - it is often ambiguous and language structure can depend on many complex variables, including slang, regional dialects and social context.
Current approaches to NLP are based on machine learning, a type of artificial intelligence that explores and uses the patterns in the data program to improve their own understanding. Most research is done on natural language processing revolves around the search, especially for enterprise search.
Challenges in Natural Language
Ambiguity in Human Language
Natural language is highly ambiguous and must be simplified. For example:
- The startup founders usually swing for the fence.
- Time flies like an arrow.
- We bowed out the investment opportuninty.

Ambiguity is Ubiquitous
Speech Recognition “recognize speech” vs. “wreck a nice beach” “youth in Asia” vs. “euthanasia”
Syntactic Analysis “I ate spaghetti with chopsticks” vs. “I ate spaghetti with meatballs.”
Semantic Analysis “The dog is in the pen.” vs. “The ink is in the pen.” “I put the plant in the window” vs. “Ford put the plant in Mexico”
Pragmatic Analysis From “The Pink Panther Strikes Again”: Clouseau: Does your dog bite? Hotel Clerk: No. Clouseau: [bowing down to pet the dog] Nice doggie. [Dog barks and bites Clouseau in the hand] Clouseau: I thought you said your dog did not bite! Hotel Clerk: That is not my dog.
Ambiguity is Explosive
Ambiguities compound to generate enormous numbers of possible interpretations. In English, a sentence ending in n prepositional phrases has over 2n syntactic interpretations (cf. Catalan numbers). “I saw the man with the telescope”: 2 parses “I saw the man on the hill with the telescope.”: 5 parses “I saw the man on the hill in Texas with the telescope”: 14 parses “I saw the man on the hill in Texas with the telescope at noon.”: 42 parses “I saw the man on the hill in Texas with the telescope at noon on Monday” 132 parses
Humor and Ambiguity
Many jokes rely on the ambiguity of language: Groucho Marx: One morning I shot an elephant in my pajamas. How he got into my pajamas, I’ll never know. She criticized my apartment, so I knocked her flat. Noah took all of the animals on the ark in pairs. Except the worms, they came in apples. Policeman to little boy: “We are looking for a thief with a bicycle.” Little boy: “Wouldn’t you be better using your eyes.” Why is the teacher wearing sun-glasses. Because the class is so bright.
Why is Language Ambiguous?
Natural language is ambiguous: one phrase often has multiple meanings. That’s the result of many thousands of years of evolution, and it’s actually very efficient. If we had to be always explicit, our phrases and sentences would be much, much longer — and boring. When A says something to B, A makes assumptions on B’s context, common sense,beliefs and knowledge. The verbal message itself just contains the minimum information needed, on top of this pre existing information, in order for B to get it. Language can be seen as a very efficient compression algorithm. The phrase the speaker chooses is the shortest message, given the context of the receiver. In computer science, Natural Language Processing struggles a lot with ambiguity. Trying to have software decide about the meaning of a piece of text or audio, without taking into account the context (and common sense, culture, etc.) is a lost battle. And yet we are fighting this battle everyday!
Major tasks in Natural Language Processing
Processing natural language text involves many various syntactic, semantic and pragmatic tasks in addition to other problems. The following is a list of some of the most commonly researched tasks in NLP. Note that some of these tasks have direct real-world applications, while others more commonly serve as subtasks that are used to aid in solving larger tasks. What distinguishes these tasks from other potential and actual NLP tasks is not only the volume of research devoted to them but the fact that for each one there is typically a well-defined problem setting, a standard metric for evaluating the task, standard corpora on which the task can be evaluated, and competitions devoted to the specific task.
Automatic summarization Automatic summarization is the process of reducing a text document with a computer program to create a summary that preserves the most important points of the original document. The technology, which can cause a comprehensive summary to take into account variables such as length, writing style and syntax.
Coreference resolution Coreference resolution task is to find all terms that relate to the same subject in the text. It is an important step for many NLP higher level tasks that relate to natural language understanding, as document summarization, the question reception and information extraction.
Discourse analysis Discourse analysis or discourse studies, is a general term for a range of approaches to analyzing written, vocal, or subscribe using language or any significant semiotic event.
Machine translation Natural language processing is increasingly being used for machine translation programs, in which one human language is automatically translated into another human language.
Morphological segmentation Separate words into individual morphemes and identify the class of the morphemes. The difficulty of this task depends greatly on the complexity of the morphology (i.e. the structure of words) of the language being considered. English has fairly simple morphology, especially inflectional morphology, and thus it is often possible to ignore this task entirely and simply model all possible forms of a word (e.g. "open, opens, opened, opening") as separate words. In languages such as Turkish or Meitei,[6] a highly agglutinated Indian language, however, such an approach is not possible, as each dictionary entry has thousands of possible word forms.
Named entity recognition (NER) In data mining, named entity definition is a phrase or word that uniquely identifies an item from a number of other items that have similar properties. Examples include name, age, geographic location, addresses, phone numbers, email addresses, company names, etc. named entity extraction, sometimes also called named entity recognition, data mining easier.
Natural language understanding Convert chunks of text into more formal representations such as first-order logic structures that are easier for computer programs to manipulate. Natural language understanding involves the identification of the intended semantic from the multiple possible semantics which can be derived from a natural language expression which usually takes the form of organized notations of natural languages concepts. Introduction and creation of language metamodel and ontology are efficient however empirical solutions. An explicit formalization of natural languages semantics without confusions with implicit assumptions such as closed-world assumption (CWA) vs. open-world assumption, or subjective Yes/No vs. objective True/False is expected for the construction of a basis of semantics formalization.
Optical character recognition (OCR) The image representing the printed text determmine corresponding text.
Part-of-speech tagging Since the sentence determined part of speech for each word. Many words, particularly those common, can serve as several parts of speech. For example, "book" can be a noun ( "The book on the table") or a verb ( "book a flight"); "Set" can be a noun, verb or adjective; and "out" can be any of at least five different parts of speech. Some languages have a greater ambiguity than others. Languages with little inflectional morphology, such as English are particularly susceptible to such an ambiguity.
Parsing In the context of natural language processing, parsing can be defined as the process of assigning structural descriptions of sequences of words in natural language (or sequence of symbols derived from the sequence of words).
Question answering Given a human-language question, determine its answer. Typical questions have a specific right answer (such as "What is the capital of Canada?"), but sometimes open-ended questions are also considered (such as "What is the meaning of life?"). Recent works have looked at even more complex questions.
Relationship extraction Given a chunk of text, identify the relationships among named entities (e.g. who is married to whom). Sentence breaking (also known as sentence boundary disambiguation). Given a chunk of text, find the sentence boundaries. Sentence boundaries are often marked by periods or other punctuation marks, but these same characters can serve other purposes (e.g. marking abbreviations).
Sentiment analysis Sentiment analysis (also known as opinion mining) refers to the use of natural language processing, text analysis and computational linguistics to identify and extract subjective information starting materials.
Speech recognition Speech recognition is the inter-disciplinary sub-field of computational linguistics that develops methodologies and technologies that enables the recognition and translation of spoken language into text by computers.
Speech segmentation Given a sound clip of a person or people speaking, separate it into words. A subtask of speech recognition and typically grouped with it. Topic segmentation and recognition. Given a chunk of text, separate it into segments each of which is devoted to a topic, and identify the topic of the segment.
Text segmentation Text segmentation is the process of dividing written text into meaningful units, such as words, phrases, or topics. The term refers to mental processes used in humans to read the text and artificial processes implemented in computers that are subject to natural language processing.
Word sense disambiguation Many words have more than one meaning; we have to select the meaning which makes the most sense in context. For this problem, we are typically given a list of words and associated word senses, e.g. from a dictionary or from an online resource such as WordNet. In some cases, sets of related tasks are grouped into subfields of NLP that are often considered separately from NLP as a whole.
Information retrieval (IR) This is concerned with storing, searching and retrieving information. It is a separate field within computer science (closer to databases), but IR relies on some NLP methods (for example, stemming). Some current research and applications seek to bridge the gap between IR and NLP.
Information extraction (IE) This is concerned in general with the extraction of semantic information from text. This covers tasks such as named entity recognition, Coreference resolution, relationship extraction, etc.
Speech processing This covers speech recognition, text-to-speech and related tasks.
Five steps procedure of NLP
Lexical Analysis − Lexicon language is a collection of words and phrases in the language. This includes identifying and analyzing the structure of words. Lexical analysis divides the whole piece of text into paragraphs, sentences and words. Syntactic Analysis (Parsing) − This includes the analysis of the words in the sentence grammar and for arranging the words in a manner which shows the relationship between words. A sentence such as "School goes to the boy" is rejected by English parser.
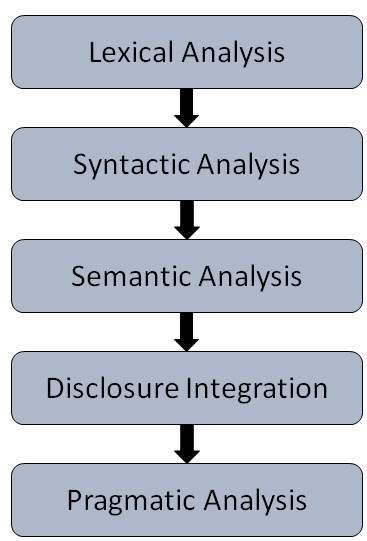
Semantic Analysis −It relies on the exact meaning or dictionary meaning of the text. Text is checked meaningfulness. This is done by mapping syntactic structures and objects in the domain tasks. Semantic Analyzer does not comply with phrases like "hot ice cream."
Discourse Integration − The significance of any test depends on the meaning of the sentence just before it. In addition, it entails a sense of directly following sentence.
Pragmatic Analysis − During what has been said it is re-interpreted what it really means. It is a derivation of those aspects of language that require real world knowledge.
