Khám phá hệ thống nhận dạng lời nói tự động _ Automatic Speech Recognition (ASR)
Trong xử lý ngôn ngữ tự nhiên, bài toán trong việc tương tác giữa người và máy móc luôn được quan tâm đặc biệt. Một hệ thống đối thoại qua lời nói (Spoken Dialog System) là một hệ thống máy tính có khả năng giao tiếp với một người qua giọng nói. SDS có 2 thành phần chính mà không có trong một hệ ...
Trong xử lý ngôn ngữ tự nhiên, bài toán trong việc tương tác giữa người và máy móc luôn được quan tâm đặc biệt. Một hệ thống đối thoại qua lời nói (Spoken Dialog System) là một hệ thống máy tính có khả năng giao tiếp với một người qua giọng nói. SDS có 2 thành phần chính mà không có trong một hệ thống đối thoại qua văn bản:
- Một bộ nhận dạng lời nói.
- Một mô-đun chuyển từ văn bản đến lời nói.
Một trong những thách thức quan trọng nhất phải đối mặt trong SDS là vấn đề hiểu được lời nói. Khi đó, hệ thống nhận dạng lời nói tự động (ASR) sẽ tham gia vào dịch tín hiệu lời nói thành một tập những lệnh mà hệ thống có thể hiểu được.
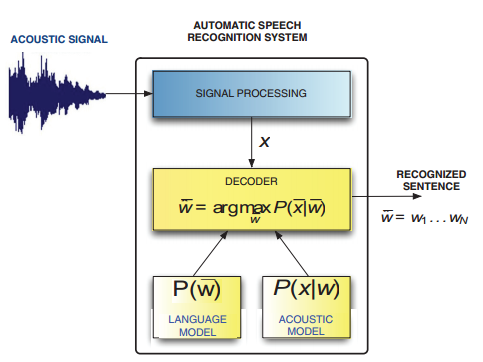
Mục đích của hệ thống ASR là để thu được thứ tự từ khả dĩ nhất được cho bởi tín hiệu âm thanh phát ra từ người nói. Sơ đồ cơ bản của hệ thống được cho ở trên. Đầu tiên, tín hiệu âm thanh được xử lý bằng việc trích xuất thông tin liên quan và nhận một chuỗi những quan sát âm thanh x ̅ = x1, x2, ..., xT với t từ 1 đến T. Tiếp theo, bộ giải mã có được những chuỗi từ liên kết với các đại diện âm thanh được cung cấp. Quá trình giải mã được thực hiện bởi quy tắc quyết định của Bayes , đưa ra trong phương trình (1):
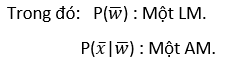
Hệ thống ASR dùng mô hình ngôn ngữ (Language Model _ LM) để nắm bắt cách kết hợp của theo từ trong một ngôn ngữ cụ thể. Ngày nay, những mô hình ngôn ngữ thống kê được sử dụng rộng rãi trong những hệ thống ASR; những mô hình ngôn ngữ n-gram theo từ là phương pháp được sử dụng rộng rãi nhất bởi vì hiệu quả trong việc giảm Tỷ lệ lỗi từ (WER). Tuy nhiên, khi làm việc với ứng dụng hạn chế về số lượng tài liệu đào tạo có sẵn như những nhiệm vụ cụ thể trong những hệ thống đối thoại, sự khan hiếm của dữ liệu trở thành một vấn đề và khi đó một phương pháp thay thế, như một mô hình ngôn ngữ n-gram theo lớp có thể được sử dụng. Hơn nữa, ví dụ một ứng dụng hệ thống đối thoại được cài đặt trong 1 robot, luôn có vốn những từ vựng miền ràng buộc phù hợp cho việc phân loại. Đây là loại mô hình có thể được mở rộng từ mô hình ngôn ngữ dựa trên cụm từ. Chúng ta đề xuất sử dụng một mô hình ngôn ngữ mở rộng cụ thể trong phân loại ngữ nghĩa để cải thiện nhận biết lời nói và tỷ lệ hiểu.
Mặt khác, những hệ thống ASR được quản lý để đạt hiệu suất tốt khi trong một môi trường sử dụng được kiểm soát và với một người dùng hợp tác. Tuy nhiên, tỷ lệ chính xác của chúng giảm khi bỏ những điều kiện này hoặc có sự không phù hợp âm thanh giữa dữ liệu thử nghiệm và dữ liệu đào tạo. Đây là trường hợp với một robot được cung cấp một hệ thống đối thoại để tương tác với con người. Nó có thể sẽ làm việc trong một môi trường ồn ào nơi những người dùng cố gắng lấy thông tin về một số vấn đề. Để giải quyết những vấn đề này, sử dụng AM có thể giảm các biến đổi trong tín hiệu tiếng nói và thu được một tập những mô hình và kỹ thuật cho tất cả các nguồn biến đổi trong lời nói. Khám phá việc sử dụng một chiến lược thích ứng với người nói trong hiệu năng của hệ thống ASR, thích ứng người nói được mong muốn đặc biệt trong trường hợp có rất nhiều những tương tác lời nói được lặp lại với một số lượng những người dùng giới hạn, ví dụ một hệ thống hoặc robot giúp việc nhà. Phần tiếp theo của bài viết sẽ đưa chúng ta đến khái niệm về Mô hình ngôn ngữ (LM) và đưa ra một số thí nghiệm cho thấy những cải tiến liên quan tới việc sử dụng các mô hình này trong hệ thống ASR.
Reference: Improving Language Models in Speech-Based Human-Machine Interaction
