Machine Learning thật thú vị (8): Đánh lừa hệ thống mạng nơron trong Machine Learning
Cứ khi nào một lập trình viên viết một chương trình phần mềm, những hackers luôn cố gắng tìm cách xuyên thủng phần mềm đó. Nhiều hackers còn lợi dụng những lỗi nhỏ nhất trong chương trình để phá hủy hệ thống, đánh cắp dữ liệu hay gây ra tàn phá nói chung. Nhưng liệu hệ thống được xây dựng bởi ...
Cứ khi nào một lập trình viên viết một chương trình phần mềm, những hackers luôn cố gắng tìm cách xuyên thủng phần mềm đó. Nhiều hackers còn lợi dụng những lỗi nhỏ nhất trong chương trình để phá hủy hệ thống, đánh cắp dữ liệu hay gây ra tàn phá nói chung.
 Nhưng liệu hệ thống được xây dựng bởi thuật toán Deep Learning có an toàn hơn trước sự thâm nhập của con người? Liệu hackers có thể vượt qua mạng nơron được đào tạo bởi hàng triệu bytes dữ liệu.
Nhưng liệu hệ thống được xây dựng bởi thuật toán Deep Learning có an toàn hơn trước sự thâm nhập của con người? Liệu hackers có thể vượt qua mạng nơron được đào tạo bởi hàng triệu bytes dữ liệu.
Hóa ra là, thậm chí mạng nơron tân tiến nhất cũng có thể dễ dàng bị đánh lừa. Chỉ cần với một vài thủ thuật, bạn có thể khiến chúng dự đoán bất kể kết quả nào mà bạn muốn.

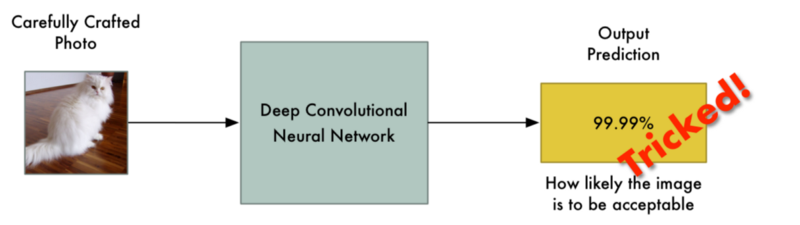
Mô hình nhận diện ảnh Inception v3 dự đoán mèo là chiếc lò nướng bánh
Vì thế, trước khi chạy bất cứ hệ thống mạng nơron deep learning nào, hãy tìm ra điểm yếu của nó, và học cách bảo vệ hệ thống từ những kẻ tấn công.
Mạng nơron như rào chắn bảo vệ
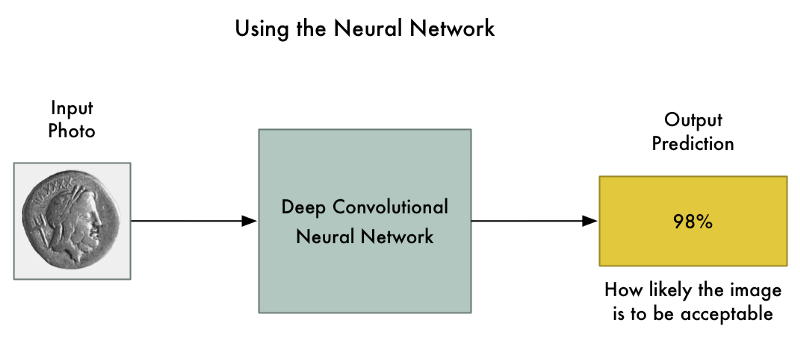
Hãy tưởng tượng chúng ta cho phép đấu giá trên Ebay. Trên website, chúng ta muốn ngăn cản mọi người bán hàng cấm - ví dụ như động vật.
Lọc dữ liệu là rất khó khăn khi bạn có hàng triệu người sử dụng. Chúng ta có thể thuê 100 người để kiểm tra sản phẩm, nhưng sẽ rất tốn kém. Thay vào đó, ta sử dụng mạng deep learning để phân biệt hàng cấm.
Đầu tiên, chúng ta cần tập dữ liệu của hàng ngàn ảnh từ những cuộc đấu giá trong quá khứ. Chúng ta cần ảnh của cả hàng cấm và hàng được cho phép bán.

Để đào tạo mạng nơron, chúng ta sử dụng thuật toán back-propagation (truyền ngược). Đây là thuật toán ta giúp ta tinh chỉnh trọng số từng lớp nơron sao cho khi nhận vào ảnh đào tạo, ta nhận được kết quả mong muốn với độ chính xác cao nhất có thể.
 Chúng ta lặp lại quá trình này hàng ngàn lần cho tới khi mô hình có độ chính xác chấp nhận được. Hệ thống trọng số cuối cùng giúp ta phân loại ảnh một cách đáng tin cậy.
Chúng ta lặp lại quá trình này hàng ngàn lần cho tới khi mô hình có độ chính xác chấp nhận được. Hệ thống trọng số cuối cùng giúp ta phân loại ảnh một cách đáng tin cậy.
Nhưng mạng nơron không đáng tin như ta tưởng
Mô hình Convolutional Neural Network (CNN - mạng nơron tích chập) là một mô hình mạnh, cân nhắc toàn bộ bức ảnh trước khi phân nhóm. Chúng có thể nhận diện hình dạng và cấu trúc dù chúng xuất hiện ở vị trí nào trong ảnh. Trong nhiều nhiệm vụ nhận diện ảnh, chúng có thể tốt bằng hoặc thậm chí đánh bại được con người.
Với mô hình ưu việt như vậy, thay đổi một vài giá trị pixel giúp ảnh sáng hay tối đi, có thể làm giảm khả năng dự đoán, nhưng không thể nào khiến mạng nơron thay đổi kết quả dự đoán chứ?
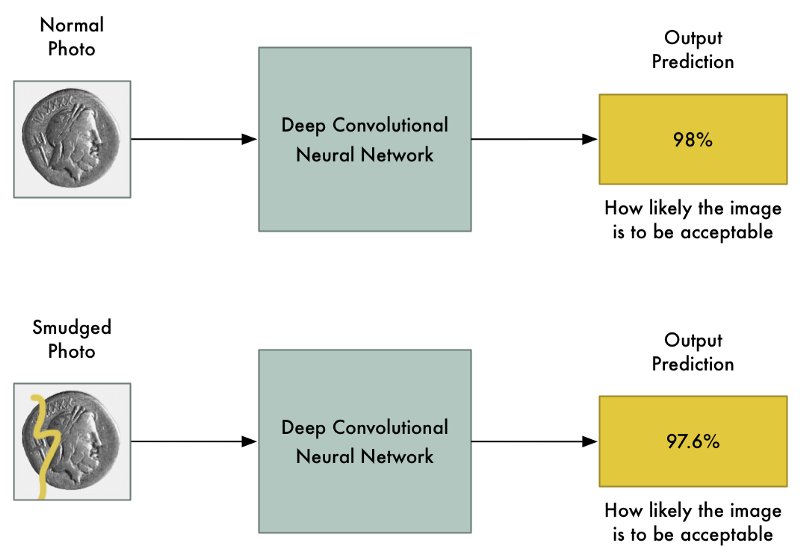
Nhưng một bài báo nổi tiếng năm 2013 gọi là Intriguing properties of neural networks (kích hoạt đặc trưng mạng nơron) đã phát hiện ra rằng điều này không luôn luôn đúng. Nếu bạn thay đổi chính xác một vài pixel ở đúng vị trí và cường độ, bạn có thể khiến mạng nơron đoán ra kết quả hoàn toàn sai, mà ảnh ban đầu không bị thay đổi nhiều.
Điều này có nghĩa là ta có thể tạo ra một ảnh, rõ ràng là hàng cấm nhưng lại vượt qua được mạng nơron và được cho phép đấu giá:
Tại sao lại như vậy? Phân loại học máy luôn cố gắng tìm đường phân chia giữa các nhóm. Dưới đây là hình ảnh đồ họa một phân chia 2 nhóm đơn giản để phân chia hàng cấm và hàng được phép:
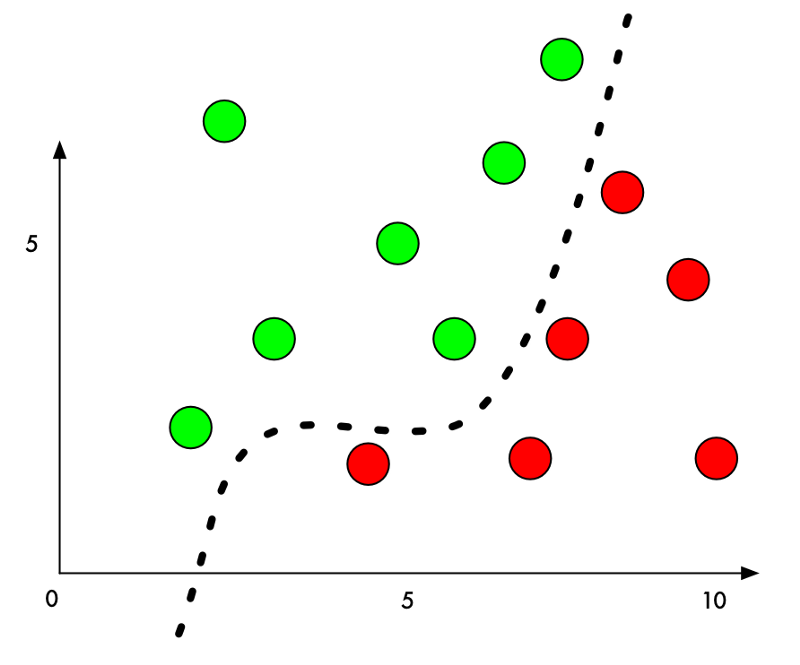
Ngay bây giờ, thuật toán phân nhóm chính xác 100%. Nó đã tìm ra đường chính xác để phân chia 2 nhóm.
Nhưng nếu chúng ta muốn ngụy trang một điểm đỏ là điểm xanh thì sao? Chúng ta chỉ cần thêm một lượng nhỏ vào giá trị Y của điểm đỏ, bên cạnh đường biên, để đẩy điểm này vào lãnh thổ điểm xanh.

Vì thế, để đánh lừa thuật toán phân chia, ta chỉ cần biết hướng thay đổi của từng pixel để khiến ảnh vượt qua đường phân chia. Và bởi vì chúng ta không muốn ai phát hiện ra sự thay đổi có chủ đích này, ta cố gắng thay đổi ít nhất có thể.
Hay nói cách khác, chỉ cần một ảnh thật, ta thay đổi rất ít giá trị pixels để đánh lừa mạng nơron. Và ta đã có thể hoàn toàn kiểm soát giá trị đầu ra của mạng.
Làm thế nào để đánh lừa mạng nơron
Trước khi tìm cách đánh lừa màng nơron, chúng ta cùng nhau ôn lại quá trình đào tạo mạng nơron để phân nhóm ảnh:
- Truyền tập ảnh đào tạo vào.
- Kiểm tra dự đoán mạng nơron và xem độ lệch với kết quả chính xác
- Tinh chỉnh trọng số mỗi lớp mạng sử dụng back-propagation (truyền ngược) để có kết quả dự đoán cuối cùng tốt hơn.
- Lặp lại bước 1-3 vài nghìn lần cùng với hàng ngàn ảnh đào tạo khác.
Nhưng nếu thay vì thay đổi trọng số của mỗi lớp nơron ở bước 3, ta tinh chỉnh ảnh đầu vào cho tới khi chúng ta có được kết quả chúng ta muốn thì sao?
Hãy cùng lấy mạng nơron đã được đào tạo và "đào tạo" nó thêm một lần nữa. Nhưng lần này, ta sử dụng back-propagation để thay đổi ảnh đầu vào thay vì trọng số từng nơron.
 Đây là thuật toán mới:
Đây là thuật toán mới:
- Truyền vào ảnh chúng ta muốn hack
- Kiểm tra dự đoán mạng và xem độ lệch với kết quả ta muốn nhận
- Tinh chỉnh ảnh sử dụng back-propagation để có dự đoán cuối cùng gần với kết quả ta mong muốn
- Lặp lại bước 1-3 hàng ngàn lần với cùng tấm ảnh đó cho tới khi mạng cho ta kết quả mong chờ.
Và giờ, ta đã có một bức ảnh đánh lừa được mạng nơron mà không thay đổi bất cứ giá trị nào của mạng.
Vấn đề duy nhất là bằng việc cho phép mỗi pixel được điều chỉnh tùy ý, mỗi tùy chỉnh trong ảnh có thể quá lớn đến nỗi mà bạn nhận ra ngay những điểm ảnh kỳ lạ:

Để hạn chế biến dạng ảnh rõ ràng, chúng ta thêm điều kiện cho thuật toán: mỗi giá trị pixel không được thay đổi nhiều hơn một giá trị rất nhỏ từ ảnh cũ - ví dụ 0.01%. Điều đó buộc thuật toán phải thay đổi tấm ảnh để vừa đánh lừa được mạng nơron, vừa không thay đổi quá khác biệt và đánh lừa được mắt thường. Đây là ảnh với điều kiện ta đã thêm:
 Mặc dầu chúng ta không thấy tấm ảnh khác gì cả, nhưng nó vẫn có thể đánh lừa mạng nơron!
Mặc dầu chúng ta không thấy tấm ảnh khác gì cả, nhưng nó vẫn có thể đánh lừa mạng nơron!
Lưu ý là sau khi thêm điều kiện, độ tin cậy (% dự đoán mèo là lò nướng bánh có thể bị giảm đi (nhưng vẫn lớn nhất trong các dự đoán còn lại); hoặc nếu điều kiện quá chặt, thậm chí ta không tìm được sự điều chỉnh ảnh phù hợp.
Không chỉ mạng nơron mà con người cũng có rất nhiều lỗi: dễ dàng bị khai thác và đánh lừa. Cùng tìm hiểu về tính phi lý trí của con người
Nếu bạn hiểu về cách dữ liệu đào tạo được đưa vào, bạn hoàn toàn có thể tạo mẫu để vượt qua kiểm duyệt hệ thống mạng nơron. Nguyễn Tử Quảng nói về cách đánh bại nhận diện mặt của IphoneX
Viết chương trình
Để tạo ra đoạn mã, đầu tiên chúng ta cần có một mạng đã được đào tạo trước để đánh lừa. Thay vì đào tạo lại mạng mới từ ban đầu, hay sử dụng mạng được tạo ra bởi Google.
Keras, một nền tảng mạng deep learning nổi tiếng, đì kèm với nhiều mạng nơron được đào tạo sẵn. Chúng ta sẽ sử dụng bản sao chép của mạng nơron Inception v3, được đào tạo để phát hiện 1000 vật thể khác nhau. của Google.
Đây là các dòng mã trong Keras để nhận diện ảnh từ mạng nơron. Bạn có thể chạy chương trình nếu đã cài đặt Python 3 và Keras.
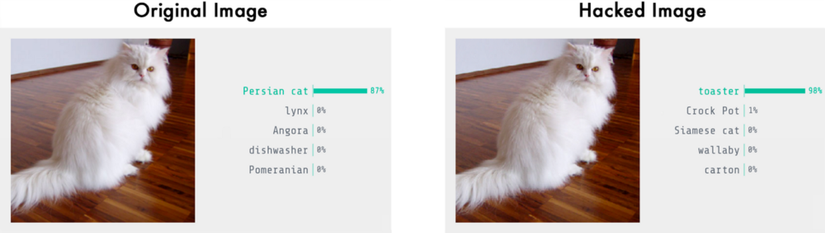
Khi chúng ta chạy, ta có thể nhận diện ảnh đầu vào là mèo Persian:
$ python3 predict.py This is a Persian_cat with 85.7% confidence!
Bây giờ, hãy thử đánh lừa mạng để kết quả cho ra là một toaster (lò nướng bánh mỳ), bằng việc tinh chỉnh giá trị pixel của ảnh. Keras không có hàm viết sẵn cho phép đào tạo để thay đổi ảnh, vì thế tôi đã phải tự tự viết quá trình đào tạo. Đây là đoạn mã:
Khi chúng ta chạy chương trình, cuối cùng chúng ta cũng đã đánh lừa được mạng nơron.
$ python3 generated_hacked_image.py Model`s predicted likelihood that the image is a toaster: 0.00072% [ .... a few thousand lines of training .... ] Model`s predicted likelihood that the image is a toaster: 99.4212%
Dịch: Mô hình dự đoán 0.00072% ảnh là một lò nướng bánh [.... sau một vài ngàn lần đào tạo ....] Mô hình dự đoán 99.4212% ảnh là một lò nướng bánh
Lưu ý: nếu bạn không có GPU, quá trình đào tạo khoảng vài giờ. Nếu bạn có GPU được kết nối với Keras và CUDA, quá trình chạy sẽ khoảng vài phút.
Giờ chúng ta hay cùng kiểm tra lại ảnh đã bị hack với mô hình đầu tiên:
$ python3 predict.py This is a toaster with 98.09% confidence!
Hack ảnh để làm gì?
Quá trình tạo ảnh hack được gọi là generating an adversarial example (sinh mẫu đối kháng - được đề cập trong phần 7). Chúng ta cố tình tạo ra dữ liệu mà mô hình học máy bị nhầm lẫn. Đó là một thủ thuật quan trọng với thế giới thực.
Các nhà nghiên cứu đã chỉ ra rằng ảnh hack có những đặc tính đáng ngạc nhiên:
- Ảnh hack có thể đánh lừa mạng nơron thậm chí khi chúng được in ra. Vì vậy, bạn có thể sử dựng ảnh hack để đánh lừa camera hay máy quét, không chỉ hệ thống yêu cầu tải ảnh lên trực tiếp.
- Ảnh đánh lừa được một mạng nơron có thể đánh lừa mạng nơron khác nếu chúng được huấn luyện trong cùng một tập dữ liệu.
Vì thế, chúng ta có thể làm nhiều điều với những tấm ảnh hack này!
Tuy vậy, vẫn có 1 giới hạn rất lớn trong cách chúng ta tạo ảnh: ta cần phải có truy cập trực tiếp vào hệ thống mạng nơron!!? Bởi vì chúng ta "đào tạo" dựa trên mạng nơron này, nên ta cần có bản sao chép của nó. Trên thực tế, không một công ty nào cho phép bạn tải về mã nơron đã được huấn luyện của họ, khiến công việc hack ảnh không có khả năng.
Khoan! Gần đây, một nhóm nghiên cứu đã chỉ ra rằng bạn có thể tự đào tạo mạng thay thế để bắt chước mạng cần hack bằng cách nghiên cứu cách nó phân nhóm dữ liệu. Và sau đó, bạn có thể sử dụng mạng thay thế này để tạo ra ảnh hack vẫn lừa được mạng nơron gốc. Đây gọi là back-box attack (tấn công hộp đen).
Hack và chống hack là quá trình phát triển liên tục của mọi lĩnh vực trong cuộc sống. Cuộc đấu tranh giữa goods và evils cũng chính là động lức phát triển của cuộc sống. Trong quá trình đó, cả 2 bên cũng sẽ tốt lên. Đây cũng chính là nguyên lý giúp học máy tự tạo ra hình ảnh trong bài 6 mà ta đã học
Ứng dụng của black-box attacks là vô giới hạn. Đây là một vài khả năng:
- Đánh lừa xe tự lái dừng trước đèn xanh và đi trước đèn đó - khủng bố xe hơi
- Lừa hệ thống kiểm tra chấp nhận hàng cấm
- Lừa máy quét ATM nghĩ rằng giá trị cần rút từ tấm séc viết tay cao hơn so với thực tế (ai đó đưa ta tấm séc và ta rút hết sạch tài khoản của họ)
Và phương pháp tấn công này không chỉ áp dụng với ảnh. Bạn có thể sử dụng cùng phương pháp để đánh lừa thuật toán phân loại trên mọi loại dữ liệu. Ví dụ: lừa máy đánh giá virus là mẫu virus trong cơ thể bạn an toàn.
Làm thế nào để tự bảo vệ?
Giờ đây, chúng ta đã biết cách để đánh lừa mạng nơron (và những mô hình khác nữa), làm thế nào để phòng ngừa?
Câu trả lời ngắn gọn là không một ai chắc chắn cả. Ngăn chặn những loại tấn công này vẫn đang trong quá trình nghiên cứu. Cách tốt nhất là luôn cập nhật công nghệ mới bằng cách đọc trang blogs cleverhans của Ian Goodfellow và Nicolas Papernot, 2 nhà nghiên cứu có ảnh hưởng nhất trong lĩnh vực này.
Dưới đây là một số cách chúng ta có thể làm:
- Nếu bạn tạo rất nhiều ảnh hack và truyền chúng vào trong tập đào tạo, điều đó sẽ khiến mạng của bạn chống chịu tốt hơn trước những cuộc tấn công. Đây gọi là Adversarial Training (Đào tạo đối kháng) và có thể là cách phòng chống hợp lý nhất được áp dụng hiện nay.
- Một nghiên cứu hiệu quả khác là Defensive Distillation, giảm khả năng tạo mẫu đối kháng với mạng nơron thành công từ 95% xuống 0.5%. Do phương pháp này buộc gradients sử dụng trong tạo mẫu đối kháng giảm 1030 10^{30} 1030 lần (khiến việc tinh chỉnh trọng số mạng nơron diễn ra rất chậm) và số đặc trưng trong mạng đối kháng cần phải tăng lên 8 lần.
- Hầu hết các phương pháp khác đều thất bại trong phòng chống các cuộc tấn công.
Vì chúng ta chưa có câu trả lời cuối cùng, ta cần nghĩ về phương pháp sử dụng mạng nơron giảm thiểu rủi ro bị tấn công. Ví dụ, bên cạnh hệ thống phòng thủ bằng máy, ta còn có thêm kiểm chứng của con người. Trong khi hệ thống máy sẽ giúp giảm thiểu số lượng công việc cần kiểm chứng, con người sẽ giúp hệ thống tăng độ chính xác, giảm thiểu khả năng bị hack.
Nguồn:
Bài gốc: https://medium.com/@ageitgey/machine-learning-is-fun-part-8-how-to-intentionally-trick-neural-networks-b55da32b7196
